Understanding New-Knowledge-Induced Factual Hallucinations in LLMs: Analysis and Interpretation
Pith reviewed 2026-05-18 01:20 UTC · model grok-4.3
The pith
Fine-tuning on new knowledge weakens LLMs' attention to key question entities and raises factual hallucination risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
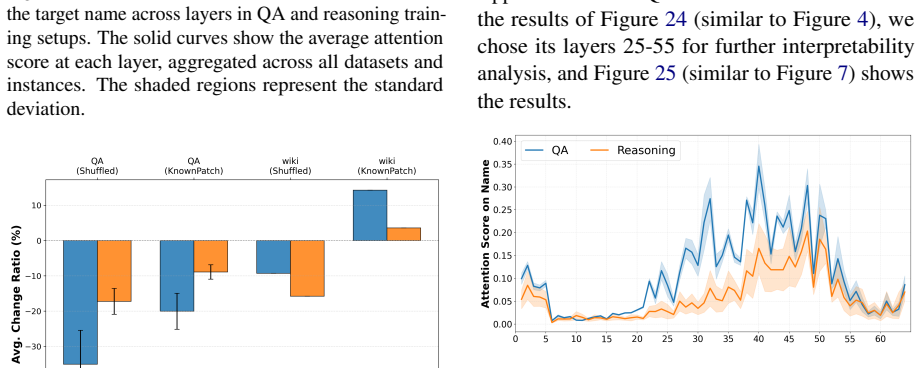
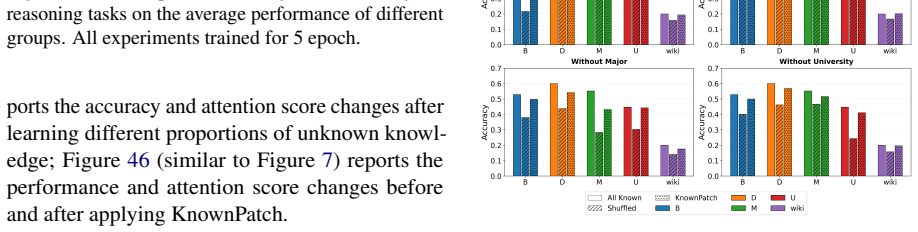
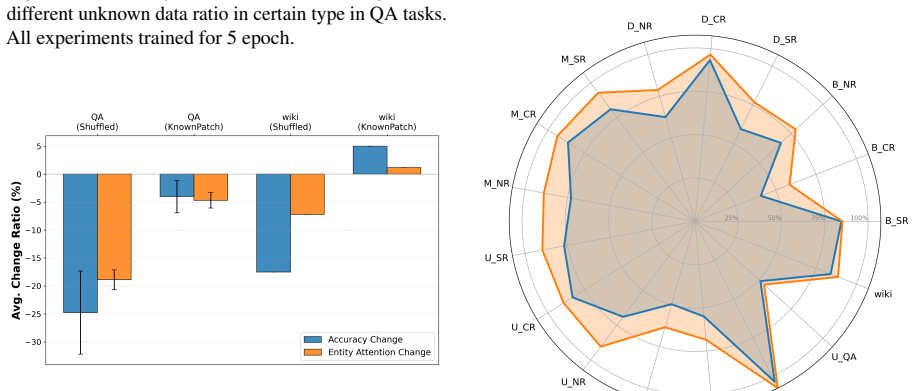
When LLMs are fine-tuned on datasets where a knowledge type consists entirely of new facts, attention to the main entities in the input question drops. This leads the model to rely more on surrounding context and produce more factual errors even on information it previously handled correctly. The effect appears across both QA and reasoning tasks and extends to evaluation items outside the new knowledge. Reintroducing a small share of known facts during the final training phase brings attention back to the key entities and cuts the hallucination rate. The same attention disruption spreads to lexically similar contexts, allowing hallucinations to propagate beyond the original task.
What carries the argument
Attention weight shifts to key entities in the input question, tracked via interpretability analysis during fine-tuning on new versus mixed knowledge.
If this is right
- Hallucinations appear on tasks with new knowledge and also spread to other evaluation tasks.
- Unfamiliarity concentrated in one knowledge type produces stronger hallucination effects than a uniform mix of new knowledge.
- Disrupted attention patterns transfer to lexically similar contexts and extend hallucination behavior.
Where Pith is reading between the lines
- Interleaving small amounts of known facts throughout training could serve as a practical way to limit attention shifts.
- The same attention-reduction pattern might appear when fine-tuning on new material in domains such as code or mathematics.
- Monitoring attention to key entities during training could become a simple early-warning signal for rising hallucination risk.
Load-bearing premise
The Biography-Reasoning dataset and its knowledge-type partitions isolate the effect of new knowledge without confounding shifts in overall data distribution or task difficulty.
What would settle it
Measuring no drop in attention weights on key entities after new-knowledge fine-tuning, or observing that reintroducing known knowledge fails to reduce hallucinations on familiar facts.
Figures

































read the original abstract
Prior works have shown that fine-tuning on new knowledge can induce factual hallucinations in large language models (LLMs), leading to incorrect outputs when evaluated on previously known information. However, the specific manifestations of such hallucination and its underlying mechanisms remain insufficiently understood. Our work addresses this gap by designing a controlled dataset \textit{Biography-Reasoning}, and conducting a fine-grained analysis across multiple knowledge types and two task types, including knowledge question answering (QA) and knowledge reasoning tasks. We find that hallucinations not only severely affect tasks involving newly introduced knowledge, but also propagate to other evaluation tasks. Moreover, when fine-tuning on a dataset in which a specific knowledge type consists entirely of new knowledge, LLMs exhibit elevated hallucination tendencies. This suggests that the degree of unfamiliarity within a particular knowledge type, rather than the overall proportion of new knowledge, is a stronger driver of hallucinations. Through interpretability analysis, we show that learning new knowledge weakens the model's attention to key entities in the input question, leading to an over-reliance on surrounding context and a higher risk of hallucination. Conversely, reintroducing a small amount of known knowledge during the later stages of training restores attention to key entities and substantially mitigates hallucination behavior. Finally, we demonstrate that disrupted attention patterns can propagate across lexically similar contexts, facilitating the spread of hallucinations beyond the original task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines how fine-tuning LLMs on new knowledge induces factual hallucinations on previously known facts. Using a custom Biography-Reasoning dataset, the authors perform fine-grained experiments across knowledge-type partitions and two task types (knowledge QA and reasoning). They report that hallucinations affect new-knowledge tasks and propagate to other evaluations; that the degree of unfamiliarity within a specific knowledge type is a stronger driver than overall new-knowledge proportion; that new-knowledge training weakens attention to key input entities (increasing context reliance); and that reintroducing small amounts of known knowledge later in training restores attention and reduces hallucinations. Disrupted attention patterns are also shown to propagate across lexically similar contexts.
Significance. If the mechanistic account holds, the work supplies a concrete, testable link between new-knowledge fine-tuning, attention redistribution, and hallucination propagation, together with a practical mitigation strategy. The controlled dataset construction and cross-task, cross-type analysis are positive features; the attention-based interpretability results, if quantitatively supported, would constitute a falsifiable prediction about training dynamics that could inform future alignment and continual-learning methods.
major comments (2)
- [§3] §3 (Biography-Reasoning Dataset): The claim that the dataset isolates the effect of novelty rests on controlled construction and knowledge-type partitions, yet the manuscript provides no explicit verification that lexical overlap, entity frequency, or reasoning depth are balanced across new-knowledge versus known-knowledge splits. Without these controls, observed attention shifts and hallucination rates could be driven by distributional differences rather than unfamiliarity per se; this is load-bearing for the central causal interpretation.
- [§5] §5 (Interpretability Analysis): The key mechanistic claim—that learning new knowledge weakens attention to key entities—is supported only by qualitative attention-map observations. No quantitative effect sizes, average attention scores with standard errors, or statistical tests comparing conditions are reported, nor are ablation controls shown to rule out confounding changes in token distribution or task difficulty. This weakens the evidential basis for the attention-weakening account and the subsequent mitigation result.
minor comments (2)
- [Abstract and §4] The abstract and results sections would benefit from explicit reporting of effect sizes, confidence intervals, and the number of runs for all hallucination-rate comparisons.
- [§3 and §4] Notation for knowledge-type partitions (e.g., “entirely new knowledge” vs. mixed) should be defined once in a table or equation and used consistently to avoid ambiguity when discussing propagation effects.
Simulated Author's Rebuttal
We thank the referee for their detailed and insightful comments on our manuscript. We address each major comment point-by-point below. Where the concerns identify opportunities to strengthen the evidential basis, we have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Biography-Reasoning Dataset): The claim that the dataset isolates the effect of novelty rests on controlled construction and knowledge-type partitions, yet the manuscript provides no explicit verification that lexical overlap, entity frequency, or reasoning depth are balanced across new-knowledge versus known-knowledge splits. Without these controls, observed attention shifts and hallucination rates could be driven by distributional differences rather than unfamiliarity per se; this is load-bearing for the central causal interpretation.
Authors: We thank the referee for this observation. The Biography-Reasoning dataset was constructed by partitioning knowledge types and selecting entities and reasoning chains to isolate novelty effects, with explicit efforts to maintain comparable entity selection and reasoning structures across splits. Nevertheless, we agree that making balance explicit would better support the causal interpretation. In the revised manuscript we will add quantitative verification, including n-gram overlap statistics for lexical similarity, histograms of entity frequencies, and counts of reasoning steps or dependency depth, all compared across new-knowledge and known-knowledge partitions. These additions will be placed in a new subsection of §3 and the corresponding appendix. revision: yes
-
Referee: [§5] §5 (Interpretability Analysis): The key mechanistic claim—that learning new knowledge weakens attention to key entities—is supported only by qualitative attention-map observations. No quantitative effect sizes, average attention scores with standard errors, or statistical tests comparing conditions are reported, nor are ablation controls shown to rule out confounding changes in token distribution or task difficulty. This weakens the evidential basis for the attention-weakening account and the subsequent mitigation result.
Authors: The referee correctly identifies that the current interpretability results are presented qualitatively. To address this, the revised manuscript will augment §5 with quantitative support: we will report mean attention weights on key entities (with standard errors) for models trained on new-knowledge versus known-knowledge conditions, together with statistical comparisons (paired t-tests or non-parametric equivalents). We will also add ablation experiments that hold token distributions and task difficulty constant while varying only the novelty of the fine-tuning data. These quantitative results and controls will be included to provide a stronger, falsifiable basis for the attention-weakening mechanism and the mitigation findings. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper conducts an empirical analysis on a controlled Biography-Reasoning dataset with fine-grained partitions across knowledge types and tasks, reporting direct observations of attention map changes and hallucination rates. The central mechanism (new knowledge weakening attention to key entities, mitigated by reintroducing known knowledge) is presented as a measured outcome rather than a definitional or fitted result that presupposes itself. No equations, self-citations, or ansatzes are shown to reduce the reported findings to inputs by construction, and the work remains self-contained against external benchmarks without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Attention weights in transformer layers reflect the model's focus on input entities during generation.
- domain assumption The Biography-Reasoning dataset partitions knowledge types without introducing unintended distributional shifts.
Reference graph
Works this paper leans on
-
[1]
Allen-Zhu, Z.; and Li, Y. 2024. Physics of Language Models: Part 3.1, Knowledge Storage and Extraction. In Forty-first International Conference on Machine Learning
work page 2024
-
[2]
Allen-Zhu , Z.; and Li, Y. 2025. Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws . In Proceedings of the 13th International Conference on Learning Representations, ICLR '25. Full version available at https://ssrn.com/abstract=5250617
work page 2025
-
[3]
Asai, A.; Wu, Z.; Wang, Y.; Sil, A.; and Hajishirzi, H. 2024. Self- RAG : Learning to Retrieve, Generate, and Critique through Self-Reflection. In The Twelfth International Conference on Learning Representations
work page 2024
- [4]
- [5]
- [6]
- [7]
- [8]
-
[9]
Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; et al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [10]
- [11]
- [12]
-
[13]
Lin, S.-C.; Gao, L.; Oguz, B.; Xiong, W.; Lin, J.; Yih, W.-t.; and Chen, X. 2024. Flame: Factuality-aware alignment for large language models. Advances in Neural Information Processing Systems, 37: 115588--115614
work page 2024
-
[14]
Lin, X. V.; Chen, X.; Chen, M.; Shi, W.; Lomeli, M.; James, R.; Rodriguez, P.; Kahn, J.; Szilvasy, G.; Lewis, M.; et al. 2023. Ra-dit: Retrieval-augmented dual instruction tuning. In The Twelfth International Conference on Learning Representations
work page 2023
- [15]
-
[16]
Lu, Y.; Bartolo, M.; Moore, A.; Riedel, S.; and Stenetorp, P. 2022. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. In Muresan, S.; Nakov, P.; and Villavicencio, A., eds., Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 8086--8098. Dublin, ...
work page 2022
-
[17]
Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 27730--27744
work page 2022
- [18]
-
[19]
Language Models as Knowledge Bases?
Petroni, F.; Rockt \"a schel, T.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A. H.; and Riedel, S. 2019. Language models as knowledge bases? arXiv preprint arXiv:1909.01066
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
Rafailov, R.; Sharma, A.; Mitchell, E.; Manning, C. D.; Ermon, S.; and Finn, C. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36: 53728--53741
work page 2023
-
[21]
Sciavolino, C.; Zhong, Z.; Lee, J.; and Chen, D. 2021. Simple Entity-Centric Questions Challenge Dense Retrievers. In Moens, M.-F.; Huang, X.; Specia, L.; and Yih, S. W.-t., eds., Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 6138--6148. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics
work page 2021
- [22]
-
[23]
A.; Vladymyrov, M.; Rueckert, U.; Kim, B.; and Sandler, M
Sun, C.; Aksitov, R.; Zhmoginov, A.; Miller, N. A.; Vladymyrov, M.; Rueckert, U.; Kim, B.; and Sandler, M. 2025. How new data permeates LLM knowledge and how to dilute it. arXiv preprint arXiv:2504.09522
- [24]
-
[25]
Team, Q. 2024. Qwen2.5: A Party of Foundation Models
work page 2024
-
[26]
Team, Q. 2025. Qwen3 Technical Report. arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Vrande c i\' c , D.; and Kr\" o tzsch, M. 2014. Wikidata: a free collaborative knowledgebase. Commun. ACM, 57(10): 78–85
work page 2014
-
[28]
Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q. V.; Zhou, D.; et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 24824--24837
work page 2022
-
[29]
Wendler, C.; Veselovsky, V.; Monea, G.; and West, R. 2024. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. In Ku, L.-W.; Martins, A.; and Srikumar, V., eds., Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 15366--15394. Bangkok, Thailand: Association for Comp...
work page 2024
-
[30]
Mitigating LLM hallucinations via conformal abstention, 4 2024
Yadkori, Y. A.; Kuzborskij, I.; Stutz, D.; Gy \"o rgy, A.; Fisch, A.; Doucet, A.; Beloshapka, I.; Weng, W.-H.; Yang, Y.-Y.; Szepesv \'a ri, C.; et al. 2024. Mitigating llm hallucinations via conformal abstention. arXiv preprint arXiv:2405.01563
-
[31]
Zhao, Y.; Zhang, W.; Chen, G.; Kawaguchi, K.; and Bing, L. 2024. How do Large Language Models Handle Multilingualism? In Advances in Neural Information Processing Systems (NeurIPS)
work page 2024
-
[32]
Zhao, Z.; Wallace, E.; Feng, S.; Klein, D.; and Singh, S. 2021. Calibrate Before Use: Improving Few-shot Performance of Language Models. In Meila, M.; and Zhang, T., eds., Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, 12697--12706. PMLR
work page 2021
-
[33]
Zheng, J.; Cai, X.; Qiu, S.; and Ma, Q. 2025. Spurious Forgetting in Continual Learning of Language Models. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[34]
Zheng, Y.; Zhang, R.; Zhang, J.; Ye, Y.; Luo, Z.; Feng, Z.; and Ma, Y. 2024. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Bangkok, Thailand: Association for Computational Linguistics
work page 2024
- [35]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.