A New Framework for Convex Clustering in Kernel Spaces: Finite Sample Bounds, Consistency and Performance Insights
Pith reviewed 2026-05-18 00:29 UTC · model grok-4.3
The pith
Mapping data to a kernel Hilbert space lets convex clustering succeed on non-convex shapes while supplying finite-sample bounds and convergence guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By embedding the data in an RKHS via a feature map, convex clustering can be carried out in the transformed space to produce an embedding in finite dimensions; the procedure converges algorithmically and admits finite-sample performance bounds, with experiments indicating better results than existing clustering methods on both synthetic and real data.
What carries the argument
The feature map that projects points into a reproducing kernel Hilbert space, allowing convex clustering operations to remain valid on originally non-convex data.
If this is right
- No pre-specified number of clusters is required for the procedure to run.
- Finite-sample bounds apply directly to the quality of the recovered centroids and assignments.
- The algorithm is guaranteed to converge for any fixed kernel and regularization parameter.
- Empirical results show gains over state-of-the-art methods on non-linear synthetic and real datasets.
Where Pith is reading between the lines
- The same lifting idea could be applied to other centroid-style methods that currently struggle with non-convex data.
- Automatic kernel selection or multiple-kernel combinations might reduce the burden of manual kernel choice in practice.
- The finite-dimensional embedding produced by the method could serve as a preprocessing step for downstream supervised tasks.
Load-bearing premise
There exists a kernel whose feature map turns the original non-convex data into a space where convex clustering produces meaningful clusters without excessive distortion.
What would settle it
On a benchmark dataset with known non-convex clusters, if the kernelized method recovers partitions no better than ordinary convex clustering or k-means, the claimed advantage would be refuted.
Figures






read the original abstract
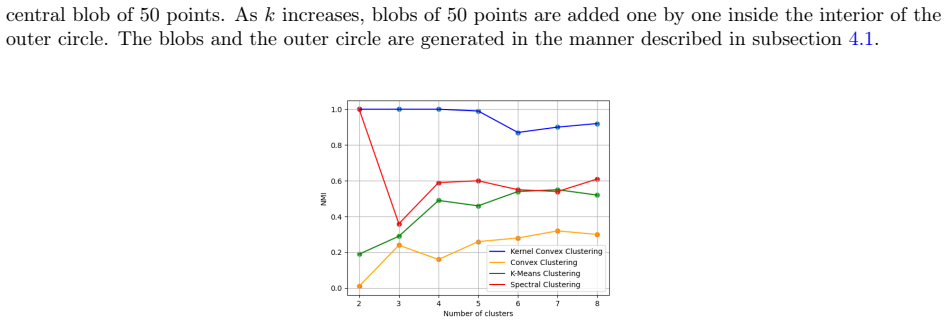
Convex clustering is a well-regarded clustering method, resembling the similar centroid-based approach of Lloyd's $k$-means, without requiring a predefined cluster count. It starts with each data point as its centroid and iteratively merges them. Despite its advantages, this method can fail when dealing with data exhibiting linearly non-separable or non-convex structures. To mitigate the limitations, we propose a kernelized extension of the convex clustering method. This approach projects the data points into a Reproducing Kernel Hilbert Space (RKHS) using a feature map, enabling convex clustering in this transformed space. This kernelization not only allows for better handling of complex data distributions but also produces an embedding in a finite-dimensional vector space. We provide a comprehensive theoretical underpinning for our kernelized approach, proving algorithmic convergence and establishing finite sample bounds for our estimates. The effectiveness of our method is demonstrated through extensive experiments on both synthetic and real-world datasets, showing superior performance compared to state-of-the-art clustering techniques. This work marks a significant advancement in the field, offering an effective solution for clustering in non-linear and non-convex data scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a kernelized extension of convex clustering by mapping data points into a Reproducing Kernel Hilbert Space (RKHS) via a feature map. This is intended to handle linearly non-separable and non-convex data structures. The authors claim that the kernelization produces a finite-dimensional embedding, prove algorithmic convergence together with finite-sample bounds and consistency, and report superior empirical performance versus state-of-the-art clustering methods on synthetic and real-world datasets.
Significance. A correctly derived set of finite-sample bounds and consistency results for kernelized convex clustering would constitute a useful theoretical contribution, extending a convex-optimization-based method to nonlinear settings while retaining interpretability. The empirical claims, if supported by reproducible controls and error bars, would indicate practical value; however, the significance is currently limited by the unresolved tension between the finite-dimensional claim and standard infinite-dimensional RKHS constructions.
major comments (2)
- [Abstract] Abstract: the assertion that kernelization 'produces an embedding in a finite-dimensional vector space' is not generally true for nonlinear kernels (e.g., Gaussian) whose RKHS is infinite-dimensional. If the convergence and finite-sample bound proofs (presumably in the theoretical sections) operate directly in this space without explicit finite-rank restriction, random-feature approximation, or truncation-error terms, the bounds cannot hold uniformly and the central theoretical claim is undermined.
- [Theoretical development] Theoretical development (likely §3–4): the finite-sample bounds and consistency statements must explicitly account for the approximation error incurred when moving from the (possibly infinite) feature map to the finite-dimensional setting used in both the analysis and the reported experiments. Without such terms the bounds are not valid for the kernels that enable non-convex separation.
minor comments (2)
- [Experiments] Experiments section: include error bars, explicit data-exclusion rules, and the precise kernel and bandwidth choices used; without these the superiority claims cannot be fully assessed.
- [Notation] Notation and formulation: clarify how the convex clustering objective is rewritten in the RKHS and whether the feature map is assumed to be explicitly computable or only accessed via the kernel trick.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review. The comments highlight an important precision issue in our presentation of the kernelized framework. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that kernelization 'produces an embedding in a finite-dimensional vector space' is not generally true for nonlinear kernels (e.g., Gaussian) whose RKHS is infinite-dimensional. If the convergence and finite-sample bound proofs (presumably in the theoretical sections) operate directly in this space without explicit finite-rank restriction, random-feature approximation, or truncation-error terms, the bounds cannot hold uniformly and the central theoretical claim is undermined.
Authors: We agree that the abstract statement is imprecise for kernels whose RKHS is infinite-dimensional. Our theoretical analysis and finite-sample bounds are derived under an explicit finite-dimensional feature map (corresponding to finite-degree polynomial kernels or other finite-rank constructions). For infinite-dimensional kernels the stated bounds would indeed require additional approximation-error terms. We will revise the abstract to remove the unqualified claim of a finite-dimensional embedding and instead state that the method operates in a finite-dimensional RKHS or via finite-dimensional approximations. revision: yes
-
Referee: [Theoretical development] Theoretical development (likely §3–4): the finite-sample bounds and consistency statements must explicitly account for the approximation error incurred when moving from the (possibly infinite) feature map to the finite-dimensional setting used in both the analysis and the reported experiments. Without such terms the bounds are not valid for the kernels that enable non-convex separation.
Authors: We concur that a fully general treatment for arbitrary infinite-dimensional RKHS would necessitate explicit approximation-error terms. The current proofs are developed directly inside a finite-dimensional feature space, where no truncation or random-feature error arises. To address the referee’s concern we will add a dedicated subsection (in §4) that (i) states the finite-dimensional assumption clearly, (ii) sketches how the bounds extend to infinite-dimensional kernels via random Fourier features or Nyström approximation, and (iii) supplies the corresponding additive error terms. These additions will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained.
full rationale
The paper starts from the standard convex clustering objective, introduces a kernel feature map to RKHS, and states that this yields a finite-dimensional embedding along with new proofs of convergence and finite-sample bounds. These theoretical results are presented as derived from the kernelized formulation rather than presupposed by it. No equation reduces to a self-definition of its own output, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests solely on a self-citation chain. The finite-dimensional claim is asserted as a direct consequence of the chosen feature map rather than derived circularly from the bounds. The overall chain is therefore independent of its target results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This observation turns out to be helpful, as we can just substitute ϕ⊤αi for every ui ... Cholesky decomposition of the kernel matrix K = Z⊤Z aids us in reducing KCC to the well-known convex clustering problem.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ISSN 2167-3888. doi: 10.1561/2400000003. URLhttp://dx.doi.org/10.1561/2400000003. Saptarshi Chakraborty and Jason Xu. Biconvex clustering.Journal of Computational and Graphical Statistics, 32(4):1524–1536, 2023. doi: 10.1080/10618600.2023.2197474. URLhttps://doi.org/10.1080/10618600. 2023.2197474. Xiaohui Chen and Yun Yang. Hanson–wright inequality in hil...
-
[2]
−2 exp[−Cmin( σ4 log(n) L4∥Γ∥2 HS , σ2√ log(n) L2∥Γ∥2 op )]for some constantC. Proof. Recall the matrixD defined such that the row ofD corresponding to the(i, j)th pair is Dij = ei −e j, where ei is the canonical basis element ofRn whose ith entry is 1, and the remaining entries are all 0. Since e1 −e 2,e 2 −e 3, . . . ,en−1 −e n span the rows ofD and the...
-
[3]
So, P[ϵ⊤atat ⊤ϵ≥(1 +δ 0)σ2∥at∥2]≤ 2 n 2 2 Letz 2 0 = maxt=1,...,( n 2)(1 +δ 0)σ2∥at∥2
It is easy to see thatδ0 >0. So, P[ϵ⊤atat ⊤ϵ≥(1 +δ 0)σ2∥at∥2]≤ 2 n 2 2 Letz 2 0 = maxt=1,...,( n 2)(1 +δ 0)σ2∥at∥2. Then, for anyt∈ {1, . . . , n 2 }, ϵ⊤atat ⊤ϵ≥z 2 0 ≥(1 +δ 0)σ2∥at∥2 and hence, P[ϵ⊤atat ⊤ϵ≥z 2 0]≤P[ϵ ⊤atat ⊤ϵ ≥(1 +δ 0)σ2∥at∥2]≤ 2 n 2 2 Also, by union bound P[ max t=1,...,( n 2) ∥at ⊤ϵ∥2 ≥z 2 0]≤ ( n 2)X t=1 P[∥at ⊤ϵ∥2 ≥z 2 0] ≤ 2n 2 Ifγ ...
-
[4]
−2 exp[−Cmin( σ4 logn L4∥Γ∥2 HS , σ2√logn L2∥Γ∥2 op )] We finally use the fact thatwmin < w ij for all pairsi, j to get thewij terms inside the summation. That is, γ ′ wmin 2 ( n 2)X t=1 ∥At∗(β− ˆβ)∥ ≤ γ ′ 2 X i<j wij∥Aij∗(β− ˆβ)∥ Triangle inequality can finally be employed to get the final result as mentioned in the main paper. C Sensitivity Analysis of ...
-
[5]
This process is repeated for all three remaining hyperparameters
To check the variation with respect to a particular hyperparameter, sayσ1, we select various other triplets corresponding to( σ2, ρ, γ); now for each such triplet we varyσ1, get the centroids, construct the elbow plots and finally the number of clusters, which turns out to be 5. This process is repeated for all three remaining hyperparameters. The number ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.