Adaptive Stepsizing for Stochastic Gradient Langevin Dynamics in Bayesian Neural Networks
Pith reviewed 2026-05-17 23:01 UTC · model grok-4.3
The pith
SA-SGLD adapts stepsizes via time rescaling on gradient norms to sample BNN posteriors more accurately without bias
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By importing the time-rescaling idea from the SamAdams framework and tying the rescaling factor to the instantaneous gradient norm, SA-SGLD produces an adaptive-step SGLD sampler whose invariant measure remains exactly the desired posterior; the adaptation therefore improves mixing and stability while leaving the long-run distribution unchanged.
What carries the argument
Time rescaling of the SGLD dynamics driven by the local gradient norm, taken from the SamAdams timestep-adaptation framework.
If this is right
- SA-SGLD yields lower error in posterior means and variances than fixed-step SGLD on high-curvature problems.
- The method improves both numerical stability and effective sample size when sampling Bayesian neural network weights under sharp priors.
- No divergence-correction term is needed, so the per-iteration cost stays comparable to standard SGLD.
- The same rescaling rule can be applied to other stochastic-gradient MCMC algorithms that share the underlying Langevin structure.
Where Pith is reading between the lines
- Manual step-size tuning may become less critical when the sampler itself reacts to local curvature.
- The approach could be combined with existing preconditioning techniques to further accelerate mixing in very high-dimensional parameter spaces.
- Because the adaptation is local and cheap, it may scale to larger image or language models where fixed-step SGLD currently struggles with stability.
Load-bearing premise
That monitoring the gradient norm and rescaling time accordingly leaves the invariant measure of the SGLD process exactly the same, without any extra correction terms.
What would settle it
Run both SA-SGLD and ordinary SGLD on a two-dimensional Gaussian mixture whose true posterior is known, then compare the empirical histograms or kernel-density estimates; a statistically significant mismatch between the SA-SGLD histogram and the true density would falsify the claim that the invariant measure is preserved.
Figures
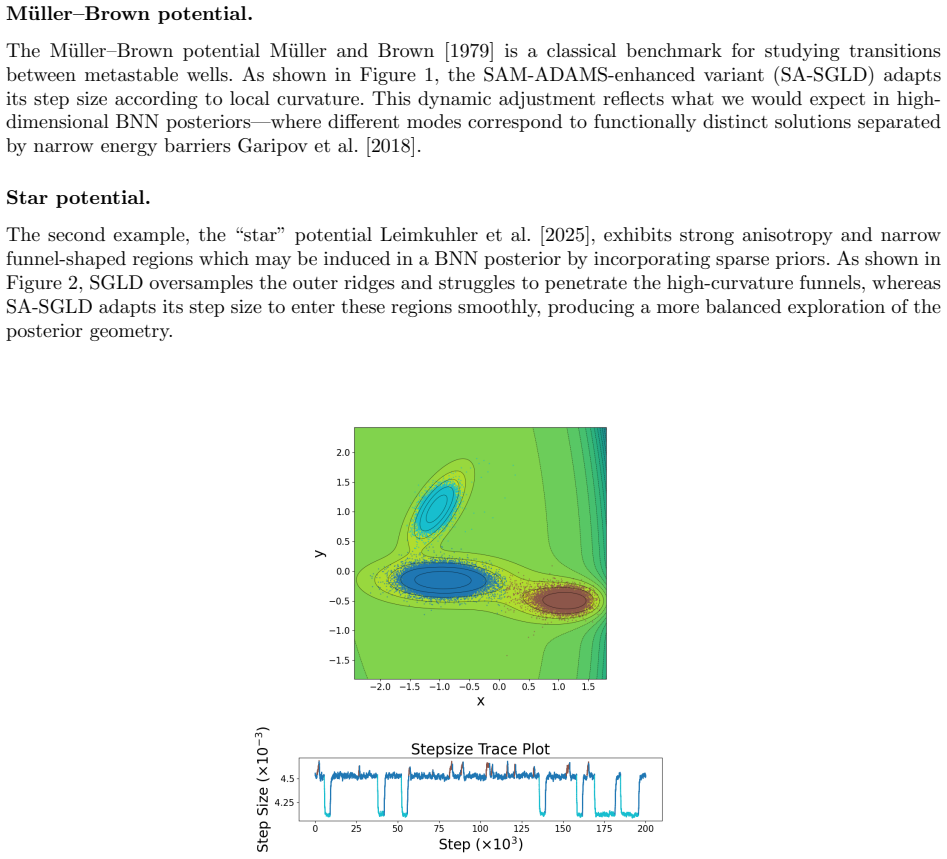
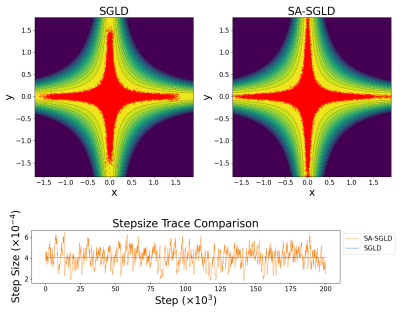
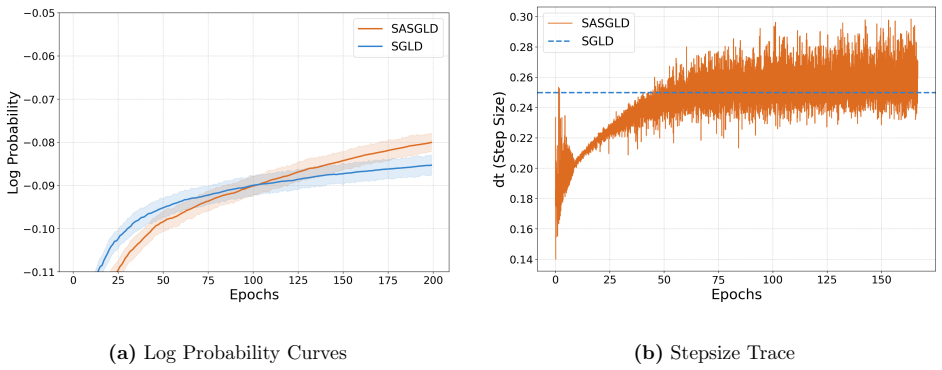
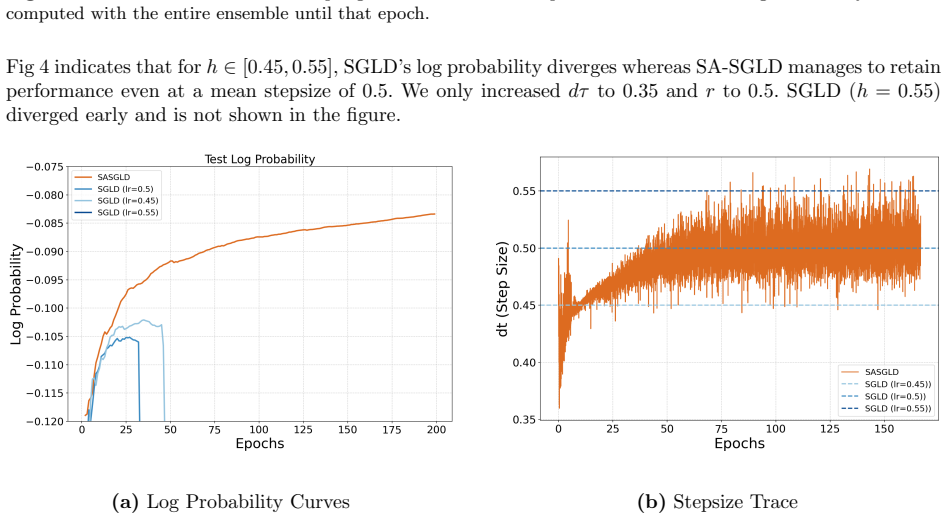
read the original abstract
Bayesian neural networks (BNNs) require scalable sampling algorithms to approximate posterior distributions over parameters. Existing stochastic gradient Markov Chain Monte Carlo (SGMCMC) methods are highly sensitive to the choice of stepsize and adaptive variants such as pSGLD typically fail to sample the correct invariant measure without addition of a costly divergence correction term. In this work, we build on the recently proposed `SamAdams' framework for timestep adaptation (Leimkuhler, Lohmann, and Whalley 2025), introducing an adaptive scheme: SA-SGLD, which employs time rescaling to modulate the stepsize according to a monitored quantity (typically the local gradient norm). SA-SGLD can automatically shrink stepsizes in regions of high curvature and expand them in flatter regions, improving both stability and mixing without introducing bias. We show that our method can achieve more accurate posterior sampling than SGLD on high-curvature 2D toy examples and in image classification with BNNs using sharp priors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SA-SGLD, an adaptive stepsize scheme for Stochastic Gradient Langevin Dynamics (SGLD) in Bayesian neural networks. Building on the SamAdams framework, it uses time rescaling driven by the local gradient norm to automatically adjust stepsizes—shrinking in high-curvature regions and expanding in flatter ones—claiming improved stability and mixing without bias or the need for divergence corrections. Results are presented on 2D toy examples and BNN image classification tasks with sharp priors, asserting more accurate posterior sampling compared to standard SGLD.
Significance. Should the method indeed preserve the invariant measure as claimed, it would represent a significant advance in adaptive SGMCMC by avoiding costly corrections, enabling better sampling in complex posteriors typical of BNNs with sharp priors. The approach leverages existing framework strengths for practical gains in stability and mixing.
major comments (1)
- Abstract: The central claim that SamAdams time rescaling driven by local gradient norm preserves the correct invariant measure for SGLD without additional divergence or Itô correction terms is load-bearing for the unbiased sampling assertion, yet the manuscript provides no derivation showing that the stochastic-gradient noise term remains compatible with the rescaled Fokker-Planck operator, particularly under the sharp priors used in the BNN experiments.
minor comments (2)
- The abstract reports improvements on 2D toy examples and BNN image classification but supplies no quantitative details, error bars, or full experimental protocol, which limits evaluation of the claimed gains in posterior accuracy.
- Clarify the precise definition of the monitored quantity (e.g., gradient norm) and the exact form of the time-rescaling rule to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the major comment below and will revise the paper accordingly to strengthen the theoretical support for our claims.
read point-by-point responses
-
Referee: [—] Abstract: The central claim that SamAdams time rescaling driven by local gradient norm preserves the correct invariant measure for SGLD without additional divergence or Itô correction terms is load-bearing for the unbiased sampling assertion, yet the manuscript provides no derivation showing that the stochastic-gradient noise term remains compatible with the rescaled Fokker-Planck operator, particularly under the sharp priors used in the BNN experiments.
Authors: We agree that an explicit derivation is essential to rigorously support the claim that SA-SGLD preserves the correct invariant measure. The SamAdams framework provides the continuous-time foundation for gradient-norm-based time rescaling, but the manuscript does not detail its extension to the stochastic-gradient setting. In the revised manuscript we will add a dedicated theoretical section (or appendix) deriving the Fokker-Planck equation for the rescaled SGLD process. This derivation will demonstrate that the additive stochastic-gradient noise remains compatible with the rescaled operator and that no additional Itô or divergence corrections are required to recover the target posterior. The analysis will explicitly address the sharp-prior regime used in the BNN experiments, where the gradient norm varies substantially across high- and low-curvature regions. We believe this addition will fully resolve the concern while preserving the practical advantages of the method. revision: yes
Circularity Check
No-bias guarantee for SA-SGLD rests on self-cited SamAdams framework with author overlap
specific steps
-
self citation load bearing
[Abstract]
"we build on the recently proposed `SamAdams' framework for timestep adaptation (Leimkuhler, Lohmann, and Whalley 2025), introducing an adaptive scheme: SA-SGLD, which employs time rescaling to modulate the stepsize according to a monitored quantity (typically the local gradient norm). SA-SGLD can automatically shrink stepsizes in regions of high curvature and expand them in flatter regions, improving both stability and mixing without introducing bias."
The load-bearing assertion that the method preserves the correct invariant measure and introduces no bias is supported solely by reference to the SamAdams framework whose authors overlap with the present paper. No independent derivation or divergence-term analysis for the stochastic-gradient SGLD case is exhibited in the abstract or described method.
full rationale
The paper presents SA-SGLD as a new application of the SamAdams time-rescaling framework to SGLD, with empirical validation on 2D toys and BNN image classification. The central theoretical claim of unbiased posterior sampling (no divergence correction needed) is justified by citation to Leimkuhler et al. 2025, which shares an author. This is a moderate self-citation load but does not reduce the derivation to a tautology or fitted input; the adaptation rule and experimental results supply independent content. No self-definitional equations or renamings of known results appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The SamAdams time-rescaling framework preserves the correct invariant measure when applied to SGLD dynamics.
- domain assumption Local gradient norm is a suitable monitored quantity for detecting high-curvature regions in parameter space.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SA-SGLD employs time rescaling to modulate the stepsize according to a monitored quantity (typically the local gradient norm)... preserves the correct invariant distribution while avoiding the expensive divergence corrections.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The invariant measure e^{-β(U(θ)+½p^T p)} is preserved as time is only rescaled.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL http://dx.doi.org/10.1137/090770527
doi: 10.1137/090770527. URL http://dx.doi.org/10.1137/090770527. Sean Meyn, Richard L. Tweedie, and Peter W. Glynn.Convergence, pages 311–312. Cambridge Mathematical Library. Cambridge University Press, Cambridge, 2009. Klaus M¨ uller and Leo D. Brown. Location of saddle points and minimum energy paths by a constrained simplex optimization procedure.Theor...
-
[2]
Ruqi Zhang, Chunyuan Li, Jianyi Zhang, Changyou Chen, and Andrew Gordon Wilson
URL https://openreview.net/forum?id=dXAuvo6CGI. Ruqi Zhang, Chunyuan Li, Jianyi Zhang, Changyou Chen, and Andrew Gordon Wilson. Cyclical stochastic gradient mcmc for bayesian deep learning. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=rkeS1RVtPS. A Experimental Details M¨ uller–Brown potential.The M¨ ul...
work page 2020
-
[3]
The Sundman step is fixed:∆τ n ≡h >0
-
[4]
The monitor usesg(θ n) =∥G n∥2 +δ, so that ζn+1 =ρζ n + 1−ρ α ∥Gn∥2, ρ=e −αh
-
[5]
The adaptive time step is∆t n+1 =ψ(ζ n+1)h, whereψis bounded and globally Lipschitz: 0< m≤ψ(ζ)≤M <∞, |ψ(x)−ψ(y)| ≤L ψ|x−y|. forζ≥ (1−ρ)δ α
-
[6]
The potentialUisL-smooth and dissipative: ∥∇U(θ)− ∇U(θ ′)∥ ≤L∥θ−θ ′∥, ⟨θ,∇U(θ)⟩ ≥a∥θ∥ 2 −b, forL >0,a >0,b≥0. 10
-
[7]
The stochastic gradients satisfy, for someσ <∞: E[∥Gn − ∇U(θ n)∥2|Fn]≤σ 2(1 +∥θ n∥2), whereF n =σ(θ 0, ζ0, ε1, . . . , εn, G0, . . . , Gn−1). Define the constants: C1 := 2L2 + 2σ2, C2 := 2∥∇U(0)∥ 2 + 2σ2, C3 := 2β−1d. Ifh >0is small enough that γ(h) := 2amh−C 1M 2h2 −2σM h >0,(10) then the iterates of θn+1 =θ n −∆t n+1Gn + p 2β−1∆tn+1 εn+1,(11) εn+1 ∼ N(0...
-
[8]
4.(θ n, ζn)is ergodic Markov with invariant measureeπ h
Forp >0large:sup n≥0 E∥θn∥p <∞, 3.E[∥G n − ∇U(θ n)∥4|Fn]≤σ 2 4(1 +∥θ n∥4). 4.(θ n, ζn)is ergodic Markov with invariant measureeπ h. 5.U∈C 4(Rd)with bounded derivatives,∇ULipschitz. Letf:R d →Rsuch that Lϕ=f−π(f),L=−∇U· ∇+β −1∆, admitsϕ∈C 4(Rd)with polynomial-growth derivatives: sup θ ∥Djϕ(θ)∥ 1 +∥θ∥ q ≤A j, j= 0,1,2,3,4. Define the weighted time-average: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.