GRLoc: Geometric Representation Regression for Visual Localization
Pith reviewed 2026-05-21 18:03 UTC · model grok-4.3
The pith
The paper reformulates absolute pose regression as regressing disentangled world-coordinate raymaps and pointmaps from images, then recovering pose via a differentiable solver, claiming SOTA results on 7-Scenes and Cambridge Landmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
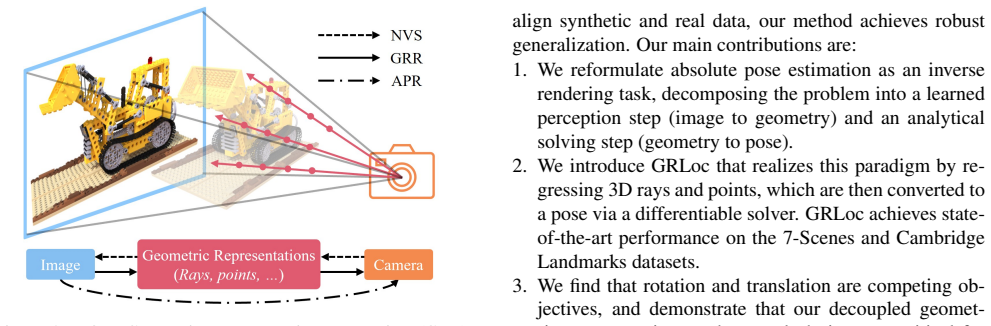
Modeling the inverse rendering process by explicitly regressing disentangled geometric representations (raymap directions for rotation and pointmap for translation) in world coordinates, followed by a differentiable deterministic solver, yields more robust and generalizable absolute pose estimation than direct black-box regression.
Load-bearing premise
The network's predicted raymap and pointmap are sufficiently accurate and consistent with each other that the deterministic solver can recover a correct pose without the prediction errors dominating the final result; this is stated in the abstract as the benefit of separating the visual-to-geometry mapping from the pose calculation.
Figures




read the original abstract
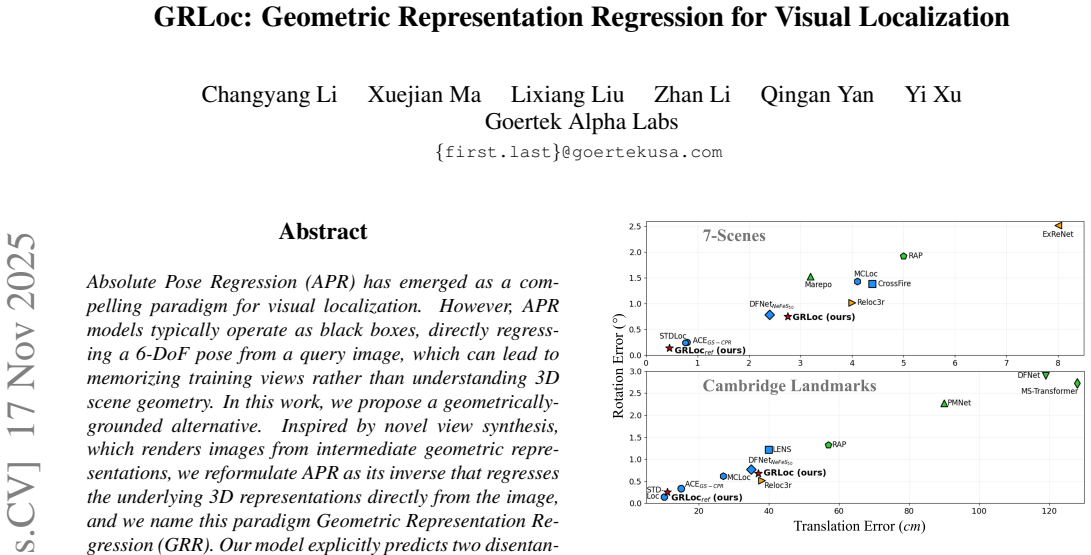
Absolute Pose Regression (APR) has emerged as a compelling paradigm for visual localization. However, APR models typically operate as black boxes, directly regressing a 6-DoF pose from a query image, which can lead to memorizing training views rather than understanding 3D scene geometry. In this work, we propose a geometrically-grounded alternative. Inspired by novel view synthesis, which renders images from intermediate geometric representations, we reformulate APR as its inverse that regresses the underlying 3D representations directly from the image, and we name this paradigm Geometric Representation Regression (GRR). Our model explicitly predicts two disentangled geometric representations in the world coordinate system: (1) a raymap's directions to estimate camera rotation, and (2) a corresponding pointmap to estimate camera translation. The final camera pose is then recovered from these geometric components using a differentiable deterministic solver. This disentangled approach, which separates the learned visual-to-geometry mapping from the final pose calculation, introduces a strong geometric prior into the network. We find that the explicit decoupling of rotation and translation predictions measurably boosts performance. We demonstrate state-of-the-art performance on 7-Scenes and Cambridge Landmarks datasets, validating that modeling the inverse rendering process is a more robust path toward generalizable absolute pose estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GRLoc for absolute pose regression by reformulating the task as geometric representation regression. From a query image it explicitly regresses two disentangled world-coordinate representations—a raymap whose directions encode camera rotation and a pointmap that encodes translation—then recovers the 6-DoF pose with a differentiable deterministic solver. The authors claim that separating the learned visual-to-geometry mapping from the final pose calculation injects a strong geometric prior, yielding better generalization than direct black-box 6-DoF regression, and report state-of-the-art results on the 7-Scenes and Cambridge Landmarks benchmarks.
Significance. If the central claim holds, the work is significant because it replaces end-to-end black-box regression with an explicit inverse-rendering formulation that keeps rotation and translation predictions disentangled and delegates pose recovery to a non-learned solver. The deterministic solver is a clear methodological strength: it removes the risk that the network simply memorizes pose-to-image mappings and supplies a concrete geometric prior that future APR methods can build upon.
major comments (2)
- [§3.3] §3.3 (Loss function): the objective optimizes raymap direction error and pointmap position error separately; no term penalizes inconsistency between the rotation implied by the raymap and the translation implied by the pointmap. Because the solver is applied after the fact, any such inconsistency directly undermines the claim that the geometric prior prevents error accumulation.
- [§4.2, Table 3] §4.2 and Table 3: the reported ablations compare full GRLoc against direct regression baselines but do not isolate the effect of removing the deterministic solver or of injecting controlled noise into the predicted raymap/pointmap. Without this test the robustness argument remains unverified.
minor comments (2)
- [Figure 2] Figure 2: the diagram of the raymap and pointmap heads would be clearer if it explicitly showed the world-coordinate frame and the subsequent solver block.
- [§4.1] §4.1: the description of the differentiable solver would benefit from a short derivation or pseudocode showing how the two representations are combined into a single pose.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Loss function): the objective optimizes raymap direction error and pointmap position error separately; no term penalizes inconsistency between the rotation implied by the raymap and the translation implied by the pointmap. Because the solver is applied after the fact, any such inconsistency directly undermines the claim that the geometric prior prevents error accumulation.
Authors: We thank the referee for this observation. The loss is deliberately applied to the disentangled representations to encourage accurate geometric predictions in world coordinates. The differentiable solver then recovers a consistent pose by construction. We nevertheless agree that an explicit consistency term would provide an additional training signal. In the revised manuscript we will augment the objective in §3.3 with a term that penalizes the discrepancy between the rotation implied by the predicted raymap and the translation implied by the pointmap. revision: yes
-
Referee: [§4.2, Table 3] §4.2 and Table 3: the reported ablations compare full GRLoc against direct regression baselines but do not isolate the effect of removing the deterministic solver or of injecting controlled noise into the predicted raymap/pointmap. Without this test the robustness argument remains unverified.
Authors: We agree that isolating the solver’s contribution and testing sensitivity to noise would strengthen the robustness claims. In the revised §4.2 and Table 3 we will add two new ablations: (i) replacing the deterministic solver with a small learned head that regresses pose directly from the raymap and pointmap, and (ii) injecting controlled Gaussian noise into the predicted representations before the solver and measuring the resulting pose error. These experiments will directly quantify the benefit of the non-learned solver. revision: yes
Circularity Check
No significant circularity; derivation introduces independent geometric components and solver
full rationale
The paper proposes regressing disentangled world-coordinate raymap directions and pointmap from images, then recovering pose via a deterministic differentiable solver. This explicitly separates visual-to-geometry mapping from pose calculation and is presented as an alternative to direct 6-DoF regression. No equations or steps in the abstract reduce the final pose or performance claims to the inputs by construction, self-definition, or fitted parameters renamed as predictions. The geometric prior is added by design rather than assumed from the target result. Claims are supported by empirical evaluation on standard external benchmarks (7-Scenes, Cambridge Landmarks), with no load-bearing self-citations or uniqueness theorems invoked in the provided text. The derivation remains self-contained against external validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single RGB image contains sufficient information to regress accurate world-coordinate ray directions and point locations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our model explicitly predicts two disentangled geometric representations in the world coordinate system: (1) a raymap's directions to estimate camera rotation, and (2) a corresponding pointmap to estimate camera translation. The final camera pose is then recovered from these geometric components using a differentiable deterministic solver.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decoupling the predictions for rotation and translation is key to improving performance... rotation and translation are competing objectives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Distill- pose: Lightweight camera localization using auxiliary learn- ing
Yehya Abouelnaga, Mai Bui, and Slobodan Ilic. Distill- pose: Lightweight camera localization using auxiliary learn- ing. In2021 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 7919–7924. IEEE,
-
[2]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Dani- yar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. In European Conference on Computer Vision, pages 690–708. Springer, 2022. 6
work page 2022
-
[3]
Reloc- net: Continuous metric learning relocalisation using neural nets
Vassileios Balntas, Shuda Li, and Victor Prisacariu. Reloc- net: Continuous metric learning relocalisation using neural nets. InProceedings of the European conference on com- puter vision (ECCV), pages 751–767, 2018. 2
work page 2018
-
[4]
Eric Brachmann and Carsten Rother. Visual camera re- localization from rgb and rgb-d images using dsac.IEEE transactions on pattern analysis and machine intelligence, 44(9):5847–5865, 2021. 2, 8
work page 2021
-
[5]
Dsac-differentiable ransac for camera localization
Eric Brachmann, Alexander Krull, Sebastian Nowozin, Jamie Shotton, Frank Michel, Stefan Gumhold, and Carsten Rother. Dsac-differentiable ransac for camera localization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6684–6692, 2017. 2
work page 2017
-
[6]
On the limits of pseudo ground truth in vi- sual camera re-localisation
Eric Brachmann, Martin Humenberger, Carsten Rother, and Torsten Sattler. On the limits of pseudo ground truth in vi- sual camera re-localisation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6218– 6228, 2021. 6
work page 2021
-
[7]
Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses
Eric Brachmann, Tommaso Cavallari, and Victor Adrian Prisacariu. Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5044–5053, 2023. 2, 8
work page 2023
-
[8]
Geometry-aware learning of maps for cam- era localization
Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, and Jan Kautz. Geometry-aware learning of maps for cam- era localization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2616–2625,
-
[9]
Direct- posenet: Absolute pose regression with photometric consis- tency
Shuai Chen, Zirui Wang, and Victor Prisacariu. Direct- posenet: Absolute pose regression with photometric consis- tency. In2021 International Conference on 3D Vision (3DV), pages 1175–1185. IEEE, 2021
work page 2021
-
[10]
Dfnet: Enhance absolute pose regression with direct feature matching
Shuai Chen, Xinghui Li, Zirui Wang, and Victor A Prisacariu. Dfnet: Enhance absolute pose regression with direct feature matching. InEuropean Conference on Com- puter Vision, pages 1–17. Springer, 2022. 1, 2, 3, 5, 6, 8
work page 2022
-
[11]
Neural refine- ment for absolute pose regression with feature synthesis
Shuai Chen, Yash Bhalgat, Xinghui Li, Jia-Wang Bian, Kejie Li, Zirui Wang, and Victor Adrian Prisacariu. Neural refine- ment for absolute pose regression with feature synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 20987–20996, 2024. 3, 8
work page 2024
-
[12]
Map-relative pose regression for visual re-localization
Shuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu, and Eric Brachmann. Map-relative pose regression for visual re-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20665– 20674, 2024. 2, 6, 8
work page 2024
-
[13]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 6
work page 2009
-
[14]
Camnet: Coarse-to-fine retrieval for camera re- localization
Mingyu Ding, Zhe Wang, Jiankai Sun, Jianping Shi, and Ping Luo. Camnet: Coarse-to-fine retrieval for camera re- localization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2871–2880, 2019. 2
work page 2019
-
[15]
Siyan Dong, Shuzhe Wang, Shaohui Liu, Lulu Cai, Qingnan Fan, Juho Kannala, and Yanchao Yang. Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual localization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16739–16752, 2025. 2, 8
work page 2025
-
[16]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
D2- net: A trainable cnn for joint description and detection of local features
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2- net: A trainable cnn for joint description and detection of local features. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 8092–8101,
-
[18]
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. 2
work page 1981
-
[19]
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pas- cal Germain, Hugo Larochelle, Franc ¸ois Laviolette, Mario March, and Victor Lempitsky. Domain-adversarial training of neural networks.Journal of machine learning research, 17(59):1–35, 2016. 5, 6
work page 2016
-
[20]
Xiao-Shan Gao, Xiao-Rong Hou, Jianliang Tang, and Hang-Fei Cheng. Complete solution classification for the perspective-three-point problem.IEEE transactions on pattern analysis and machine intelligence, 25(8):930–943,
-
[21]
Feature query networks: Neural surface description for camera pose refinement
Hugo Germain, Daniel DeTone, Geoffrey Pascoe, Tan- ner Schmidt, David Novotny, Richard Newcombe, Chris Sweeney, Richard Szeliski, and Vasileios Balntas. Feature query networks: Neural surface description for camera pose refinement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5071– 5081, 2022. 3, 8
work page 2022
-
[22]
Learning to produce semi-dense correspondences for visual localization
Khang Truong Giang, Soohwan Song, and Sungho Jo. Learning to produce semi-dense correspondences for visual localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19468– 19478, 2024. 2
work page 2024
-
[23]
Zhiwei Huang, Hailin Yu, Yichun Shentu, Jin Yuan, and Guofeng Zhang. From sparse to dense: Camera relocaliza- tion with scene-specific detector from feature gaussian splat- ting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27059–27069, 2025. 3, 7, 8
work page 2025
-
[24]
Martin Humenberger, Yohann Cabon, Nicolas Guerin, Julien Morat, Vincent Leroy, J´erˆome Revaud, Philippe Rerole, No´e Pion, Cesar De Souza, and Gabriela Csurka. Robust im- age retrieval-based visual localization using kapture.arXiv preprint arXiv:2007.13867, 2020. 2
-
[25]
R-score: Revisiting scene coordinate regression for robust large-scale visual localization
Xudong Jiang, Fangjinhua Wang, Silvano Galliani, Christoph V ogel, and Marc Pollefeys. R-score: Revisiting scene coordinate regression for robust large-scale visual localization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11536–11546, 2025. 2
work page 2025
-
[26]
Wolfgang Kabsch. A solution for the best rotation to relate two sets of vectors.Foundations of Crystallography, 32(5): 922–923, 1976. 5
work page 1976
-
[27]
Posenet: A convolutional network for real-time 6-dof cam- era relocalization
Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof cam- era relocalization. InProceedings of the IEEE international conference on computer vision, pages 2938–2946, 2015. 1, 2, 6, 7, 8
work page 2015
-
[28]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[29]
3d gaussian splat- ting as markov chain monte carlo
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Wei- wei Sun, Yang-Che Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3d gaussian splat- ting as markov chain monte carlo. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. Spotlight Presentation. 6
work page 2024
-
[30]
Unleashing the power of data synthesis in visual localization.arXiv preprint arXiv:2412.00138, 2024
Sihang Li, Siqi Tan, Bowen Chang, Jing Zhang, Chen Feng, and Yiming Li. Unleashing the power of data synthesis in visual localization.arXiv preprint arXiv:2412.00138, 2024. 1, 2, 3, 5, 6, 7, 8
-
[31]
Learning neural volumetric pose features for camera localization
Jingyu Lin, Jiaqi Gu, Bojian Wu, Lubin Fan, Renjie Chen, Ligang Liu, and Jieping Ye. Learning neural volumetric pose features for camera localization. InEuropean Conference on Computer Vision, pages 198–214. Springer, 2024. 1, 2, 3, 5, 6, 8
work page 2024
-
[32]
Lightglue: Local feature matching at light speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Polle- feys. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF international conference on computer vision, pages 17627–17638, 2023. 2
work page 2023
-
[33]
Changkun Liu, Shuai Chen, Yash Bhalgat, Siyan Hu, Ming Cheng, Zirui Wang, Victor Adrian Prisacariu, and Tristan Braud. Gs-cpr: Efficient camera pose refinement via 3d gaussian splatting.arXiv preprint arXiv:2408.11085, 2024. 3, 6, 8
-
[34]
Changkun Liu, Shuai Chen, Yukun Zhao, Huajian Huang, Victor Prisacariu, and Tristan Braud. Hr-apr: Apr-agnostic framework with uncertainty estimation and hierarchical re- finement for camera relocalisation. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 8544–8550. IEEE, 2024. 3, 8
work page 2024
-
[35]
Efficient global 2d-3d matching for camera localization in a large-scale 3d map
Liu Liu, Hongdong Li, and Yuchao Dai. Efficient global 2d-3d matching for camera localization in a large-scale 3d map. InProceedings of the IEEE International Conference on Computer Vision, pages 2372–2381, 2017. 2
work page 2017
-
[36]
Swin transformer v2: Scaling up capacity and resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 12009–12019, 2022. 6
work page 2022
-
[37]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 1, 3
work page 2021
-
[38]
Lens: Localization enhanced by nerf synthesis
Arthur Moreau, Nathan Piasco, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. Lens: Localization enhanced by nerf synthesis. InConference on Robot Learn- ing, pages 1347–1356. PMLR, 2022. 1, 3, 5, 8
work page 2022
-
[39]
Crossfire: Camera relocalization on self-supervised features from an implicit representation
Arthur Moreau, Nathan Piasco, Moussab Bennehar, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. Crossfire: Camera relocalization on self-supervised features from an implicit representation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 252–262, 2023. 3, 8
work page 2023
-
[40]
From coarse to fine: Robust hierarchical localization at large scale
Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. From coarse to fine: Robust hierarchical localization at large scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12716–12725, 2019. 2
work page 2019
-
[41]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020
work page 2020
-
[42]
Back to the feature: Learning robust camera localization from pixels to pose
Paul-Edouard Sarlin, Ajaykumar Unagar, Mans Larsson, Hugo Germain, Carl Toft, Viktor Larsson, Marc Pollefeys, Vincent Lepetit, Lars Hammarstrand, Fredrik Kahl, et al. Back to the feature: Learning robust camera localization from pixels to pose. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 3247–3257, 2021
work page 2021
-
[43]
Fast image- based localization using direct 2d-to-3d matching
Torsten Sattler, Bastian Leibe, and Leif Kobbelt. Fast image- based localization using direct 2d-to-3d matching. In2011 International Conference on Computer Vision, pages 667–
-
[44]
Torsten Sattler, Bastian Leibe, and Leif Kobbelt. Efficient & effective prioritized matching for large-scale image-based localization.IEEE transactions on pattern analysis and ma- chine intelligence, 39(9):1744–1756, 2016. 2
work page 2016
-
[45]
Understanding the limitations of cnn-based absolute camera pose regression
Torsten Sattler, Qunjie Zhou, Marc Pollefeys, and Laura Leal-Taixe. Understanding the limitations of cnn-based absolute camera pose regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3302–3312, 2019. 1
work page 2019
-
[46]
Camera pose auto-encoders for improving pose regression
Yoli Shavit and Yosi Keller. Camera pose auto-encoders for improving pose regression. InEuropean Conference on Computer Vision, pages 140–157. Springer, 2022. 2, 8
work page 2022
-
[47]
Learning multi- scene absolute pose regression with transformers
Yoli Shavit, Ron Ferens, and Yosi Keller. Learning multi- scene absolute pose regression with transformers. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 2733–2742, 2021. 1, 2, 8
work page 2021
-
[48]
Scene co- ordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene co- ordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013. 1, 6, 7, 8
work page 2013
-
[49]
Inloc: Indoor visual localization with dense matching and view synthesis
Hajime Taira, Masatoshi Okutomi, Torsten Sattler, Mircea Cimpoi, Marc Pollefeys, Josef Sivic, Tomas Pajdla, and Ak- ihiko Torii. Inloc: Indoor visual localization with dense matching and view synthesis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7199–7209, 2018. 2
work page 2018
-
[50]
Learning camera localization via dense scene matching
Shitao Tang, Chengzhou Tang, Rui Huang, Siyu Zhu, and Ping Tan. Learning camera localization via dense scene matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1831– 1841, 2021. 2
work page 2021
-
[51]
The unreasonable effectiveness of pre- trained features for camera pose refinement
Gabriele Trivigno, Carlo Masone, Barbara Caputo, and Torsten Sattler. The unreasonable effectiveness of pre- trained features for camera pose refinement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 12786–12798, 2024. 3, 8
work page 2024
-
[52]
Adversarial discriminative domain adaptation
Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 7167–7176, 2017. 5
work page 2017
-
[53]
Glace: Global local accelerated coordinate encoding
Fangjinhua Wang, Xudong Jiang, Silvano Galliani, Christoph V ogel, and Marc Pollefeys. Glace: Global local accelerated coordinate encoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21562–21571, 2024. 2, 8
work page 2024
-
[54]
Learning to localize in new environments from syn- thetic training data
Dominik Winkelbauer, Maximilian Denninger, and Rudolph Triebel. Learning to localize in new environments from syn- thetic training data. In2021 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 5840–5846. IEEE, 2021. 2, 8
work page 2021
-
[55]
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, et al. gsplat: An open-source library for gaussian splatting.Journal of Machine Learning Research, 26(34):1–17, 2025. 6
work page 2025
-
[56]
inerf: Inverting neural radiance fields for pose estimation
Lin Yen-Chen, Pete Florence, Jonathan T Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin. inerf: Inverting neural radiance fields for pose estimation. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1323–1330. IEEE, 2021. 2
work page 2021
-
[57]
Camera pose voting for large-scale image-based localization
Bernhard Zeisl, Torsten Sattler, and Marc Pollefeys. Camera pose voting for large-scale image-based localization. InPro- ceedings of the IEEE International Conference on Computer Vision, pages 2704–2712, 2015. 2
work page 2015
-
[58]
Semantic-guided camera ray regression for visual localization
Yesheng Zhang and Xu Zhao. Semantic-guided camera ray regression for visual localization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25639–25648, 2025. 3
work page 2025
-
[59]
Pnerfloc: Visual localization with point- based neural radiance fields
Boming Zhao, Luwei Yang, Mao Mao, Hujun Bao, and Zhaopeng Cui. Pnerfloc: Visual localization with point- based neural radiance fields. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7450–7459,
-
[60]
The nerfect match: Exploring nerf features for visual localization
Qunjie Zhou, Maxim Maximov, Or Litany, and Laura Leal- Taix´e. The nerfect match: Exploring nerf features for visual localization. InEuropean Conference on Computer Vision, pages 108–127. Springer, 2024. 3, 8
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.