FinCriticalED: A Visual Benchmark for Financial Fact-Level OCR
Pith reviewed 2026-05-17 20:16 UTC · model grok-4.3
The pith
Financial OCR models often fail to preserve critical facts like numbers and monetary units despite high lexical accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Strong OCR performance on lexical metrics does not guarantee faithful preservation of decision-critical evidence in financial documents, where small visual errors induce discrete shifts in meaning for numerical values, monetary units, temporal data, reporting entities, and financial concepts.
What carries the argument
The Deterministic-Rule-Guided LLM-as-Judge protocol for structured OCR with fact-level verification that assesses contextual preservation of expert-annotated facts.
If this is right
- Lexical similarity alone is insufficient for evaluating factual reliability in financial OCR.
- Numerical values and monetary units emerge as the most error-prone fact types.
- Critical errors concentrate in visually complex, mixed-layout documents.
- Different model families display distinct patterns of factual distortion.
Where Pith is reading between the lines
- Training objectives that explicitly penalize distortion of numerical and monetary facts could narrow the observed gap.
- The fact-centric evaluation method could transfer to other high-stakes domains such as medical or legal records.
- Finance practitioners may require supplementary verification layers when using current OCR outputs for decisions.
Load-bearing premise
Expert annotations correctly identify all decision-critical facts and the rule-guided LLM judge measures preservation without introducing systematic bias or missing context-dependent errors.
What would settle it
Re-running the full benchmark suite on a fresh collection of financial pages whose critical facts have been independently verified by multiple domain experts and confirming whether the lexical-versus-factual gap persists at similar magnitudes.
Figures




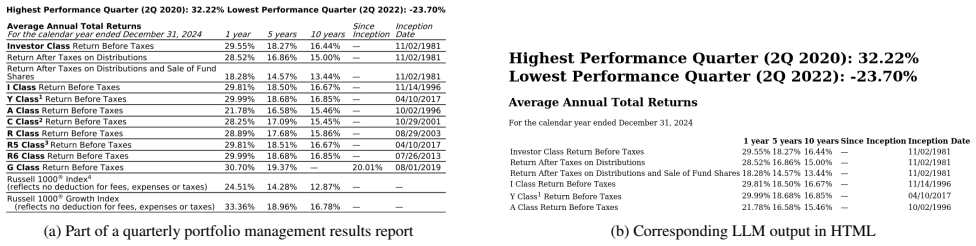
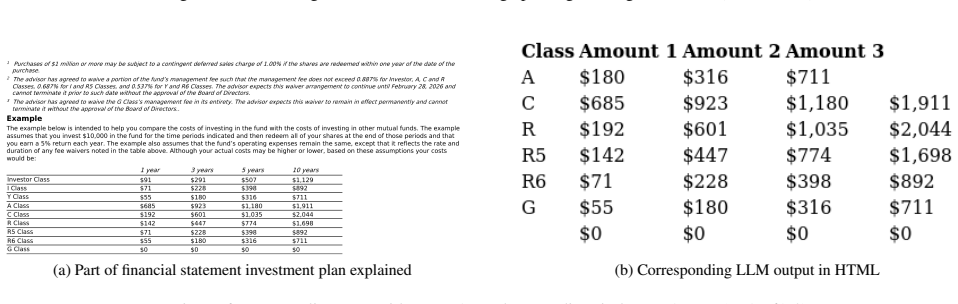
read the original abstract
Recent progress in multimodal large language models (MLLMs) has substantially improved document understanding, yet strong optical character recognition (OCR) performance on surface metrics does not guarantee faithful preservation of decision-critical evidence. This limitation is especially consequential in financial documents, where small visual errors can induce discrete shifts in meaning. To study this gap, we introduce FinCriticalED (Financial Critical Error Detection), a fact-centric visual benchmark for evaluating whether OCR and vision-language systems preserve financially critical evidence beyond lexical similarity. FinCriticalED contains 859 real-world financial document pages with 9,481 expert-annotated facts spanning five critical field types: numeric, temporal, monetary unit, reporting entity, and financial concept. We formulate the task as structured OCR with fact-level verification, and develop a Deterministic-Rule-Guided LLM-as-Judge protocol to assess whether model outputs preserve annotated facts in context. We benchmark 13 systems spanning OCR pipelines, specialized OCR VLMs, open-source MLLMs, and proprietary MLLMs. Results reveal a clear gap between lexical accuracy and factual reliability, with numerical values and monetary units emerging as the most vulnerable fact types, and critical errors concentrating in visually complex, mixed-layout documents with distinct failure patterns across model families. Overall, FinCriticalED provides a rigorous benchmark for trustworthy financial OCR and a practical testbed for evidence fidelity in high-stakes multimodal document understanding. Benchmark and dataset details available at https://the-finai.github.io/FinCriticalED/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FinCriticalED, a fact-centric visual benchmark for financial OCR consisting of 859 real-world document pages annotated with 9,481 expert-labeled facts across five types (numeric, temporal, monetary unit, reporting entity, financial concept). It evaluates 13 systems spanning OCR pipelines, specialized VLMs, open-source MLLMs, and proprietary models via a Deterministic-Rule-Guided LLM-as-Judge protocol, reporting a gap between lexical accuracy and factual reliability with particular vulnerabilities for numerical/monetary facts in complex mixed-layout documents.
Significance. If the annotations and judge protocol prove reliable, the benchmark is significant for exposing limitations of surface-level OCR metrics in high-stakes financial settings and for supplying a reproducible testbed focused on evidence fidelity. The public dataset release and detailed construction guidelines are strengths that support further work on trustworthy multimodal document understanding.
major comments (2)
- [§3] §3 (Annotation and Dataset Construction): Inter-annotator agreement statistics (e.g., Cohen’s kappa or raw agreement percentages) are not reported for the 9,481 facts. This directly affects confidence in the ground-truth labels that support the central claim of a lexical-vs-factual performance gap.
- [§4.3] §4.3 (LLM-as-Judge Validation): The Deterministic-Rule-Guided protocol is described with prompt templates, but no quantitative validation against human judgments on a held-out subset is provided. This leaves open the possibility of systematic bias in fact-preservation scoring for context-dependent monetary or entity facts.
minor comments (2)
- [Table 2] Table 2 and Figure 4: Axis labels and legend entries could more explicitly distinguish lexical OCR metrics from the fact-level F1 scores to avoid reader confusion when comparing the reported gaps.
- [§5] §5 (Results Discussion): The concentration of errors in “visually complex, mixed-layout documents” is stated qualitatively; adding a quantitative breakdown by layout complexity metric would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. The comments on annotation reliability and judge validation are helpful for increasing transparency. We address each major comment below and indicate the changes we will make.
read point-by-point responses
-
Referee: [§3] §3 (Annotation and Dataset Construction): Inter-annotator agreement statistics (e.g., Cohen’s kappa or raw agreement percentages) are not reported for the 9,481 facts. This directly affects confidence in the ground-truth labels that support the central claim of a lexical-vs-factual performance gap.
Authors: We agree that explicit inter-annotator agreement metrics would increase confidence in the ground-truth labels. The 9,481 facts were annotated by domain experts using detailed guidelines, with a second expert reviewing a random 20% sample for consistency and resolving any differences through discussion. Although we did not include quantitative agreement statistics in the original submission, we have now computed raw agreement on an overlapping subset of 850 facts labeled independently by two experts, yielding 93% agreement. We will add these statistics, along with a description of the annotation workflow and guidelines, to the revised §3. revision: yes
-
Referee: [§4.3] §4.3 (LLM-as-Judge Validation): The Deterministic-Rule-Guided protocol is described with prompt templates, but no quantitative validation against human judgments on a held-out subset is provided. This leaves open the possibility of systematic bias in fact-preservation scoring for context-dependent monetary or entity facts.
Authors: We acknowledge the value of empirical validation for the Deterministic-Rule-Guided LLM-as-Judge protocol. The protocol uses explicit deterministic rules per fact type to reduce subjectivity, yet we agree that direct comparison to human judgments is necessary to quantify any residual bias, especially for monetary units and entities. We have performed such a validation on a held-out subset of 250 facts, obtaining 90% agreement between the LLM judge and majority vote of two human experts (with lower agreement on a small number of context-dependent entity facts). We will add a new subsection to §4.3 reporting the validation methodology, results, and error analysis. revision: yes
Circularity Check
No significant circularity
full rationale
This is a benchmark-creation and empirical-evaluation paper rather than a derivation. The central claims rest on expert-annotated facts, dataset construction details, and a rule-guided LLM judge protocol whose prompts and guidelines are supplied in the manuscript. No equations, fitted parameters, or predictions are defined in terms of the reported gap or factual-reliability metrics; the evaluation protocol is explicitly constructed and documented rather than reduced to self-referential inputs. No load-bearing self-citations or uniqueness theorems appear in the provided text. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert annotations accurately capture all decision-critical facts in the selected pages
- domain assumption The Deterministic-Rule-Guided LLM-as-Judge protocol produces unbiased assessments of fact preservation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate the task as structured OCR with fact-level verification, and develop a Deterministic-Rule-Guided LLM-as-Judge protocol to assess whether model outputs preserve annotated facts in context.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Results reveal a clear gap between lexical accuracy and factual reliability, with numerical values and monetary units emerging as the most vulnerable fact types
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Onechart: Purify the chart structural extrac- tion via one auxiliary token
Jinyue Chen, Lingyu Kong, Haoran Wei, Chenglong Liu, Zheng Ge, Liang Zhao, Jianjian Sun, Chunrui Han, and Xi- angyu Zhang. Onechart: Purify the chart structural extrac- tion via one auxiliary token. InProceedings of the 32nd ACM International Conference on Multimedia, pages 147– 155, 2024. 2
work page 2024
-
[2]
A coefficient of agreement for nominal scales
Jacob Cohen. A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20(1):37–46,
-
[3]
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, Yue Zhang, Yubo Zhang, Handong Zheng, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Paddleocr-vl: Boosting multilingual document parsing via a 0.9b ultra-compact vision-language model.arXiv preprint arXiv:2510.14528, 2025. 2
-
[4]
PaddleOCR 3.0 Technical Report
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Paddleocr 3.0 technical report.arXiv preprint arXiv:2507.05595, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Joseph L. Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382, 1971. 3
work page 1971
-
[6]
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Zhang Li, Guozhi Tang, Bin Shan, Chunhui Lin, Qi Liu, Binghong Wu, Hao Feng, Hao Liu, Can Huang, Jingqun Tang, Wei Chen, Lianwen Jin, Yuliang Liu, and Xiang Bai. Ocrbench v2: An improved benchmark for evaluating large multimodal models on vis...
work page internal anchor Pith review arXiv 2025
-
[7]
Mme-finance: A multi- modal finance benchmark for expert-level understanding and reasoning
Ziliang Gan, Dong Zhang, Haohan Li, Yang Wu, Xueyuan Lin, Ji Liu, Haipang Wu, Chaoyou Fu, Zenglin Xu, Rongjunchen Zhang, and Yong Dai. Mme-finance: A multi- modal finance benchmark for expert-level understanding and reasoning. InProceedings of the 33rd ACM International Conference on Multimedia, page 12867–12874, New York, NY , USA, 2025. Association for ...
work page 2025
-
[8]
google/gemma-3n-E4B-it: Gemma 3N Instruction- Tuned Model, 2025
Google. google/gemma-3n-E4B-it: Gemma 3N Instruction- Tuned Model, 2025. 7
work page 2025
-
[9]
Chartqa- x: Generating explanations for visual chart reasoning.arXiv preprint arXiv:2504.13275, 2025
Shamanthak Hegde, Pooyan Fazli, and Hasti Seifi. Chartqa- x: Generating explanations for visual chart reasoning.arXiv preprint arXiv:2504.13275, 2025. 2, 3
-
[10]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Yichao Jin, Yushuo Wang, Qishuai Zhong, Kent Chiu Jin- Chun, Kenneth Zhu Ke, and Donald MacDonald. Multi- stage field extraction of financial documents with ocr and compact vision-language models.arXiv preprint arXiv:2510.23066, 2025. 1
-
[12]
Vladimir I. Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals.Soviet physics. Doklady, 10:707–710, 1965. 2
work page 1965
-
[13]
Bohao Li, Yuying Ge, Yi Chen, Yixiao Ge, Ruimao Zhang, and Ying Shan. Seed-bench-2-plus: Benchmarking multi- modal large language models with text-rich visual compre- hension.arXiv preprint arXiv:2404.16790, 2024. 2, 3
-
[14]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004. 2
work page 2004
-
[15]
arXiv preprint arXiv:2405.14295 (2024) 4, 8, 9, 10 17
Chenglong Liu, Haoran Wei, Jinyue Chen, Lingyu Kong, Zheng Ge, Zining Zhu, Liang Zhao, Jianjian Sun, Chun- rui Han, and Xiangyu Zhang. Focus anywhere for fine- grained multi-page document understanding.arXiv preprint arXiv:2405.14295, 2024. 2, 3
-
[16]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12), 2024. 2, 3
work page 2024
-
[17]
Junyu Luo, Zhizhuo Kou, Liming Yang, Xiao Luo, Jinsheng Huang, Zhiping Xiao, Jingshu Peng, Chengzhong Liu, Ji- aming Ji, Xuanzhe Liu, Sirui Han, Ming Zhang, and Yike Guo. Finmme: Benchmark dataset for financial multi-modal reasoning evaluation.arXiv preprint arXiv:2505.24714,
-
[18]
Id- pleaderboard: A unified leaderboard for intelligent document processing tasks, 2025
Souvik Mandal, Nayancy Gupta, Ashish Talewar, Paras Ahuja, Prathamesh Juvatkar, and Gourinath Banda. Id- pleaderboard: A unified leaderboard for intelligent document processing tasks, 2025. 1
work page 2025
-
[19]
Ahmed Masry and Amir Hajian. Longfin: A multimodal document understanding model for long financial domain documents.arXiv preprint arXiv:2401.15050, 2024. 2, 3
-
[20]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, R Manmatha, and CV Jawahar. Docvqa: A dataset for vqa on docu- ment images. corr abs/2007.00398 (2020).arXiv preprint arXiv:2007.00398, 2020. 2
-
[21]
Ocr-vqa: Visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In2019 International Confer- ence on Document Analysis and Recognition (ICDAR), pages 947–952, 2019. 2, 3
work page 2019
-
[22]
Dolfin – document-level financial test set for machine translation
Mariam Nakhl ´e, Marco Dinarelli, Raheel Qader, Em- manuelle Esperanc ¸a-Rodier, and Herv´e Blanchon. Dolfin – document-level financial test set for machine translation. arXiv preprint arXiv:2502.03053, 2025. 2
-
[23]
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Junbo Niu, Zheng Liu, Zhuangcheng Gu, Bin Wang, Linke Ouyang, Zhiyuan Zhao, Tao Chu, Tianyao He, Fan Wu, Qin- tong Zhang, Zhenjiang Jin, Guang Liang, Rui Zhang, Wen- zheng Zhang, Yuan Qu, Zhifei Ren, Yuefeng Sun, Yuan- hong Zheng, Dongsheng Ma, Zirui Tang, Boyu Niu, Ziyang Miao, Hejun Dong, Siyi Qian, Junyuan Zhang, Jingzhou Chen, Fangdong Wang, Xiaomeng ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [24]
-
[25]
Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations,
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, Jin Shi, Fan Wu, Pei Chu, Minghao Liu, Zhenxiang Li, Chao Xu, Bo Zhang, Botian Shi, Zhongy- ing Tu, and Conghui He. Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annota- tions.arXiv preprint arXiv:2412.0762...
-
[26]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting on Association for Computational Linguistics, page 311–318, USA, 2002. Association for Computational Linguistics. 2
work page 2002
-
[27]
The carbon foot- print of machine learning training will plateau, then shrink
David Patterson, Joseph Gonzalez, Urs H ¨olzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. The carbon foot- print of machine learning training will plateau, then shrink. arXiv preprint arXiv:2204.05149, 2022. 6, 7
-
[28]
Xueqing Peng, Lingfei Qian, Yan Wang, Ruoyu Xiang, Yueru He, Yang Ren, Mingyang Jiang, Vincent Jim Zhang, Yuqing Guo, Jeff Zhao, Huan He, Yi Han, Yun Feng, Yuechen Jiang, Yupeng Cao, Haohang Li, Yangyang Yu, Xiaoyu Wang, Penglei Gao, Shengyuan Lin, Keyi Wang, Shanshan Yang, Yilun Zhao, Zhiwei Liu, Peng Lu, Jerry Huang, Suyuchen Wang, Triantafillos Papadop...
-
[29]
Exploring ocr capabilities of gpt-4v(ision) : A quantitative and in-depth evaluation, 2023
Yongxin Shi, Dezhi Peng, Wenhui Liao, Zening Lin, Xin- hong Chen, Chongyu Liu, Yuyi Zhang, and Lianwen Jin. Exploring ocr capabilities of gpt-4v(ision) : A quantitative and in-depth evaluation, 2023. 1
work page 2023
- [30]
-
[31]
Rohan Wadhawan, Hritik Bansal, Kai-Wei Chang, and Nanyun Peng. Contextual: Evaluating context-sensitive text- rich visual reasoning in large multimodal models.arXiv preprint arXiv:2401.13311, 2024. 2, 3
-
[32]
Vary: Scaling up the vision vocabulary for large vision-language models
Haoran Wei, Lingyu Kong, Jinyue Chen, Liang Zhao, Zheng Ge, Jinrong Yang, Jianjian Sun, Chunrui Han, and Xiangyu Zhang. Vary: Scaling up the vision vocabulary for large vision-language models.arXiv preprint arXiv:2312.06109,
-
[33]
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, et al. General ocr theory: Towards ocr-2.0 via a unified end-to-end model.arXiv preprint arXiv:2409.01704,
work page internal anchor Pith review arXiv
-
[34]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek- ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025. 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Slow perception: Let’s perceive geometric figures step-by-step.arXiv preprint arXiv:2412.20631, 2025
Haoran Wei, Youyang Yin, Yumeng Li, Jia Wang, Liang Zhao, Jianjian Sun, Zheng Ge, Xiangyu Zhang, and Daxin Jiang. Slow perception: Let’s perceive geometric figures step-by-step.arXiv preprint arXiv:2412.20631, 2025. 2
-
[36]
Zhibo Yang, Jun Tang, Zhaohai Li, Pengfei Wang, Jianqiang Wan, Humen Zhong, Xuejing Liu, Mingkun Yang, Peng Wang, Shuai Bai, LianWen Jin, and Junyang Lin. Cc-ocr: A comprehensive and challenging ocr benchmark for eval- uating large multimodal models in literacy.arXiv preprint arXiv:2412.02210, 2024. 2, 3
-
[37]
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Ren- liang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understand- ing and reasoning benchmark for...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neu- big. MMMU-pro: A more robust multi-discipline multi- modal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pa...
work page 2025
-
[39]
Ground truth HTML that contains special entity tags such as <Number>...</Number> and <Date>...</Date>
-
[40]
Number" * <Date> ... </Date>→entity type =
Model-generated HTML that was produced from the same image but does not contain those tags. Your goal is to judge how correct the generated HTML is compared with the ground truth HTML. Follow all steps carefully and output only one JSON object as the final result. # Step 1: Normalize the ground truth structure The ground truth HTML contains entity tags th...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.