Decoupling Data Layouts from Bounding Volume Hierarchies
Pith reviewed 2026-05-17 21:19 UTC · model grok-4.3
The pith
Scion decouples bounding volume hierarchy data layouts from traversal algorithms via a domain-specific language and compiler.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
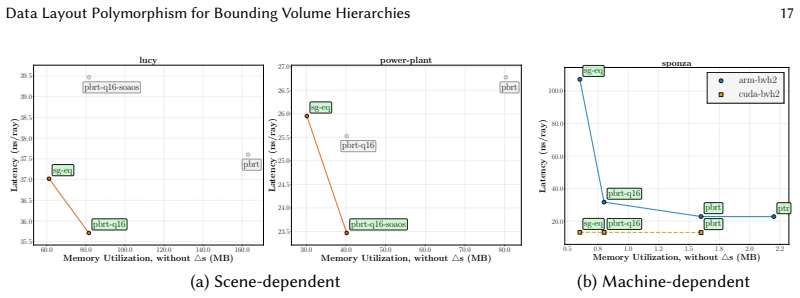
The central claim is that a domain-specific language called Scion, together with its compiler, can specify bounding volume hierarchy data layouts independently of tree traversal algorithms, express a wide range of high-performance computing layout optimizations in an architecture-agnostic manner, and through systematic design exploration identify Pareto-optimal layouts that vary by algorithm, architecture, and workload together with a novel ray-tracing layout that achieves optimality across diverse architectures and scenes.
What carries the argument
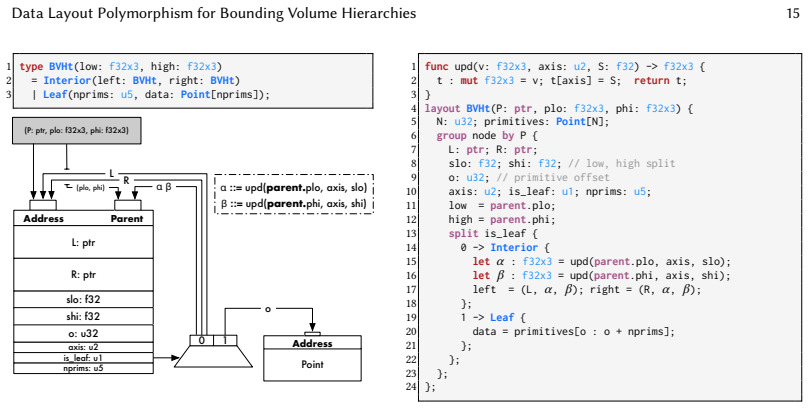
Scion, a domain-specific language and compiler that lets users describe BVH data layouts separately from traversal logic.
If this is right
- Developers can tune data layouts and traversal algorithms separately for different contexts without rewriting either.
- The single best layout is not universal; Pareto-optimal choices shift with algorithm, machine, and input data.
- A new hybrid layout that merges techniques from earlier work delivers strong performance and modest memory use across many architectures and scenes.
Where Pith is reading between the lines
- The same separation of layout specification from control logic could be applied to other hierarchical data structures used in simulation and analytics.
- Systematic layout exploration becomes feasible once the description language is decoupled from any one traversal, potentially surfacing additional hybrid arrangements for specialized workloads.
- Compilers for general-purpose languages might eventually adopt similar declarative layout primitives to improve data-structure performance without manual rewriting.
Load-bearing premise
That a compiler can turn high-level layout descriptions into efficient, architecture-agnostic code without adding overhead that erases the gains from the chosen layouts.
What would settle it
A side-by-side benchmark in which Scion-generated code for an otherwise identical layout runs measurably slower or uses more memory than equivalent hand-written code on the same hardware.
Figures


















read the original abstract
Bounding volume hierarchies are ubiquitous acceleration structures in graphics, scientific computing, and data analytics. Their performance depends critically on data layout choices that affect cache utilization, memory bandwidth, and vectorization -- increasingly dominant factors in modern computing. Yet, in most programming systems, these layout choices are hopelessly entangled with the traversal logic. This entanglement prevents developers from independently optimizing data layouts and algorithms across different contexts, perpetuating a false dichotomy between performance and portability. We introduce Scion, a domain-specific language and compiler for specifying the data layouts of bounding volume hierarchies independent of tree traversal algorithms. We show that Scion can express a broad spectrum of layout optimizations used in high-performance computing while remaining architecture-agnostic. We demonstrate empirically that Pareto-optimal layouts (along performance and memory footprint axes) vary across algorithms, architectures, and workload characteristics. Through systematic design exploration, we also identify a novel ray tracing layout that combines optimization techniques from prior work, achieving Pareto-optimality across diverse architectures and scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Scion, a domain-specific language and compiler for specifying data layouts of bounding volume hierarchies independently of traversal algorithms. It claims that Scion can express a broad spectrum of high-performance computing layout optimizations while remaining architecture-agnostic, empirically demonstrates that Pareto-optimal layouts vary across algorithms, architectures, and workload characteristics, and identifies a novel ray-tracing layout that combines prior techniques to achieve Pareto-optimality across diverse architectures and scenes.
Significance. If the empirical results and compiler overhead claims hold, this work would meaningfully advance the state of the art by separating layout and traversal concerns that are currently entangled in graphics and scientific computing systems. The systematic design exploration and identification of a novel layout represent concrete contributions; the architecture-agnostic property, if achieved without prohibitive runtime cost, would be particularly valuable for portable high-performance code.
major comments (2)
- [§5.2] §5.2, performance tables: the reported speedups for Scion-generated layouts versus baseline implementations do not include a direct measurement of accessor overhead (e.g., extra indirection or missed prefetch opportunities) relative to equivalent hand-tuned code for the same layout; this measurement is load-bearing for the central claim that decoupling does not negate net performance gains.
- [§4.1] §4.1, language semantics: the formal description of how layout descriptors are lowered to traversal-compatible accessors does not specify preservation of cache-line packing or vectorization opportunities that hand-tuned code exploits; without this, the architecture-agnostic guarantee risks becoming a performance tax in hot paths.
minor comments (2)
- [Figure 3] Figure 3 caption: the legend for the novel layout is difficult to distinguish from the 'combined' baseline; a clearer visual encoding would improve readability.
- [§6] §6: the discussion of limitations mentions only a subset of traversal algorithms; adding a brief note on compatibility with non-recursive or GPU-specific traversals would strengthen the decoupling claim.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the feedback on the performance evaluation and language semantics. We respond to each major comment below.
read point-by-point responses
-
Referee: [§5.2] §5.2, performance tables: the reported speedups for Scion-generated layouts versus baseline implementations do not include a direct measurement of accessor overhead (e.g., extra indirection or missed prefetch opportunities) relative to equivalent hand-tuned code for the same layout; this measurement is load-bearing for the central claim that decoupling does not negate net performance gains.
Authors: We agree that isolating the overhead introduced by the generated accessors compared to hand-tuned equivalents for the same layout would provide stronger evidence for the claim. In the revised version, we will add experiments that directly compare the performance of Scion-generated accessors against hand-written code implementing the identical data layout. This will quantify any indirection or prefetching differences and confirm that net gains are preserved. revision: yes
-
Referee: [§4.1] §4.1, language semantics: the formal description of how layout descriptors are lowered to traversal-compatible accessors does not specify preservation of cache-line packing or vectorization opportunities that hand-tuned code exploits; without this, the architecture-agnostic guarantee risks becoming a performance tax in hot paths.
Authors: The Scion compiler's lowering rules are constructed to maintain the specified cache-line packing and vectorization properties through explicit layout descriptors that control alignment and access patterns. To address the concern about the formal description, we will update §4.1 to include explicit invariants stating that the lowering preserves cache-line boundaries and vector-friendly access sequences as defined in the layout specification. This will clarify that the architecture-agnostic aspect does not introduce a performance tax beyond what the chosen layout permits. revision: yes
Circularity Check
No circularity: new DSL introduction with independent empirical validation
full rationale
The paper presents Scion as a new DSL and compiler for decoupling BVH data layouts from traversal algorithms. No equations, fitted parameters, or predictive derivations are described that could reduce to inputs by construction. Claims rest on the system's ability to express existing optimizations and on empirical Pareto curves across algorithms, architectures, and workloads. These demonstrations are self-contained and do not rely on self-citation chains, ansatzes smuggled from prior author work, or renaming of known results as novel derivations. The central contribution is the introduction and evaluation of a new system rather than any closed-form reduction to prior fitted quantities.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Scion
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Scion, a domain-specific language and compiler for specifying the data layouts of bounding volume hierarchies independent of tree traversal algorithms.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The layout language expresses two complementary pieces of information: (1) the concrete type that encodes an ADT reference... (2) the interpretation of that representation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Root, Andrew Adams, Shoaib Kamil, and Alvin Cheung
Maaz Bin Safeer Ahmad, Alexander J. Root, Andrew Adams, Shoaib Kamil, and Alvin Cheung. 2022. Vector instruction selection for digital signal processors using program synthesis. InProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems(Lausanne, Switzerland)(ASPLOS ’22). Association for...
-
[2]
Timo Aila and Samuli Laine. 2009. Understanding the efficiency of ray traversal on GPUs. InProceedings of the conference on high performance graphics 2009. 145–149
work page 2009
-
[3]
Anastassia Ailamaki, David J. DeWitt, and Mark D. Hill. 2002. Data page layouts for relational databases on deep memory hierarchies.The VLDB Journal11, 3 (Nov. 2002), 198–215. doi:10.1007/s00778-002-0074-9
-
[4]
Ciprian Apetrei. 2014. Fast and simple agglomerative LBVH construction. (2014)
work page 2014
-
[5]
Wilhem Barbier and Mathias Paulin. 2025. Fused Collapsing for Wide BVH Construction. InComputer Graphics Forum. Wiley Online Library, e70213
work page 2025
-
[6]
Thaïs Baudon, Gabriel Radanne, and Laure Gonnord. 2023. Bit-Stealing Made Legal: Compilation for Custom Memory Representations of Algebraic Data Types.Proc. ACM Program. Lang.7, ICFP, Article 216 (Aug. 2023), 34 pages. doi:10.1145/3607858
-
[7]
Pablo Bauszat, Martin Eisemann, and Marcus A Magnor. 2010. The Minimal Bounding Volume Hierarchy.. InVMV. 227–234
work page 2010
-
[8]
Carsten Benthin, Daniel Meister, Joshua Barczak, Rohan Mehalwal, John Tsakok, and Andrew Kensler. 2024. H-PLOC: Hierarchical Parallel Locally-Ordered Clustering for Bounding Volume Hierarchy Construction.Proceedings of the ACM on Computer Graphics and Interactive Techniques7, 3 (2024), 1–14
work page 2024
-
[9]
Carsten Benthin, Karthik Vaidyanathan, and Sven Woop. 2021. Ray Tracing Lossy Compressed Grid Primitives.. In Eurographics (Short Papers). 1–4
work page 2021
-
[10]
Carsten Benthin, Ingo Wald, Sven Woop, and Attila T. Áfra. 2018. Compressed-leaf bounding volume hierarchies. InProceedings of the Conference on High-Performance Graphics(Vancouver, British Columbia, Canada)(HPG ’18). Association for Computing Machinery, New York, NY, USA, Article 6, 4 pages. doi:10.1145/3231578.3231581
-
[11]
Carsten Benthin, Sven Woop, Ingo Wald, and Attila T Áfra. 2017. Improved two-level BVHs using partial re-braiding. InProceedings of High Performance Graphics. 1–8
work page 2017
-
[12]
Dylan Lacewell, Joe Kniss, Jan Kautz, Peter Shirley, and Ingo Wald
Solomon Boulos, Dave Edwards, J. Dylan Lacewell, Joe Kniss, Jan Kautz, Peter Shirley, and Ingo Wald. 2007. Packet- based whitted and distribution ray tracing. InProceedings of Graphics Interface 2007(Montreal, Canada)(GI ’07). Association for Computing Machinery, New York, NY, USA, 177–184. doi:10.1145/1268517.1268547
-
[13]
Yishen Chen, Charith Mendis, Michael Carbin, and Saman Amarasinghe. 2021. VeGen: a vectorizer generator for SIMD and beyond. InProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems(Virtual, USA)(ASPLOS ’21). Association for Computing Machinery, New York, NY, USA, 902–914. doi:10.1145/...
-
[14]
Zilin Chen, Ambroise Lafont, Liam O’Connor, Gabriele Keller, Craig McLaughlin, Vincent Jackson, and Christine Rizkallah. 2023. Dargent: A Silver Bullet for Verified Data Layout Refinement.Proc. ACM Program. Lang.7, POPL, Article 47 (Jan. 2023), 27 pages. doi:10.1145/3571240
-
[15]
Floyd M Chitalu, Christophe Dubach, and Taku Komura. 2020. Binary Ostensibly-Implicit Trees for Fast Collision Detection. InComputer Graphics Forum, Vol. 39. Wiley Online Library, 509–521
work page 2020
-
[16]
Stephen Chou, Fredrik Kjolstad, and Saman Amarasinghe. 2018. Format abstraction for sparse tensor algebra compilers.Proc. ACM Program. Lang.2, OOPSLA, Article 123 (Oct. 2018), 30 pages. doi:10.1145/3276493
-
[17]
Per Christensen, Julian Fong, Charlie Kilpatrick, Francisco González, Srinath Ravichandran, Akshay Shah, Ethan Jaszewski, Stephen Friedman, James Burgess, Trina M Roy, et al . 2025. RenderMan XPU: A Hybrid CPU+ GPU Renderer for Interactive and Final-frame Rendering. InCOMPUTER GRAPHICS forum, Vol. 44
work page 2025
-
[18]
David Cline, Kevin Steele, and Parris Egbert. 2006. Lightweight bounding volumes for ray tracing.Journal of Graphics Tools11, 4 (2006), 61–71
work page 2006
-
[19]
E. F. Codd. 1970. A relational model of data for large shared data banks.Commun. ACM13, 6 (June 1970), 377–387. doi:10.1145/362384.362685
-
[20]
Jonathan D Cohen, Ming C Lin, Dinesh Manocha, and Madhav Ponamgi. 1995. I-collide: An interactive and exact collision detection system for large-scale environments. InProceedings of the 1995 symposium on Interactive 3D graphics. 189–ff
work page 1995
-
[21]
Simon Colin, Rodolphe Lepigre, and Gabriel Scherer. 2018. Unboxing Mutually Recursive Type Definitions in OCaml. arXiv preprint arXiv:1811.02300(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Daniel S Coming and Oliver G Staadt. 2007. Velocity-aligned discrete oriented polytopes for dynamic collision detection.IEEE Transactions on Visualization and Computer Graphics14, 1 (2007), 1–12
work page 2007
-
[23]
Holger Dammertz, Johannes Hanika, and Alexander Keller. 2008. Shallow bounding volume hierarchies for fast SIMD ray tracing of incoherent rays. InComputer Graphics Forum, Vol. 27. Wiley Online Library, 1225–1233. Data Layout Polymorphism for Bounding Volume Hierarchies 23
work page 2008
-
[24]
David Eberly. 2002. Dynamic collision detection using oriented bounding boxes.Geometric Tools, Inc(2002)
work page 2002
-
[25]
Martin Eisemann, Pablo Bauszat, and Marcus Magnor. 2012. Implicit object space partitioning: The no-memory BVH. Comput. Graph. Braunsch.(2012)
work page 2012
-
[26]
Martin Eisemann, Christian Woizischke, and Marcus A Magnor. 2008. Ray Tracing with the Single Slab Hierarchy.. InVMV. 373–381
work page 2008
-
[27]
2004.Real-Time Collision Detection
Christer Ericson. 2004.Real-Time Collision Detection. CRC Press, Inc., USA
work page 2004
-
[28]
Manfred Ernst and Gunther Greiner. 2008. Multi bounding volume hierarchies. In2008 IEEE Symposium on Interactive Ray Tracing. 35–40. doi:10.1109/RT.2008.4634618
-
[29]
Jeffrey Goldsmith and John Salmon. 1987. Automatic creation of object hierarchies for ray tracing.IEEE Computer Graphics and Applications7, 5 (1987), 14–20
work page 1987
-
[30]
Stefan Gottschalk, Ming C Lin, and Dinesh Manocha. 1996. OBBTree: A hierarchical structure for rapid interference detection. InProceedings of the 23rd annual conference on Computer graphics and interactive techniques. 171–180
work page 1996
-
[31]
Yan Gu, Yong He, Kayvon Fatahalian, and Guy Blelloch. 2013. Efficient BVH construction via approximate agglomer- ative clustering. InProceedings of the 5th High-Performance Graphics Conference. 81–88
work page 2013
- [32]
-
[33]
Cordelia Hall, Simon L Peyton Jones, and Patrick M Sansom. 1994. Unboxing using specialisation. InFunctional Programming, Glasgow 1994: Proceedings of the 1994 Glasgow Workshop on Functional Programming, A yr, Scotland, 12–14 September 1994. Springer, 96–110
work page 1994
-
[34]
Vlastimil Havran, Robert Herzog, and Hans-peter Seidel. 2006. On the Fast Construction of Spatial Hierarchies for Ray Tracing. In2006 IEEE Symposium on Interactive Ray Tracing. 71–80. doi:10.1109/RT.2006.280217
-
[35]
Michael P Howard, Joshua A Anderson, Arash Nikoubashman, Sharon C Glotzer, and Athanassios Z Panagiotopoulos
-
[36]
Computer Physics Communications203 (2016), 45–52
Efficient neighbor list calculation for molecular simulation of colloidal systems using graphics processing units. Computer Physics Communications203 (2016), 45–52
work page 2016
-
[37]
Michael P Howard, Antonia Statt, Felix Madutsa, Thomas M Truskett, and Athanassios Z Panagiotopoulos. 2019. Quantized bounding volume hierarchies for neighbor search in molecular simulations on graphics processing units. Computational Materials Science164 (2019), 139–146
work page 2019
-
[38]
Yuanming Hu, Tzu-Mao Li, Luke Anderson, Jonathan Ragan-Kelley, and Frédo Durand. 2019. Taichi: a language for high-performance computation on spatially sparse data structures.ACM Transactions on Graphics (TOG)38, 6 (2019), 1–16
work page 2019
-
[39]
Yuanming Hu, Jiafeng Liu, Xuanda Yang, Mingkuan Xu, Ye Kuang, Weiwei Xu, Qiang Dai, William T Freeman, and Frédo Durand. 2021. Quantaichi: a compiler for quantized simulations.ACM Transactions on Graphics (TOG)40, 4 (2021), 1–16
work page 2021
-
[40]
Yen-Chieh Huang, Chen-Pin Yang, and Tsung Tai Yeh. 2025. AQB8: Energy-Efficient Ray Tracing Accelerator through Multi-Level Quantization. InProceedings of the 52nd Annual International Symposium on Computer Architecture. 374–387
work page 2025
-
[41]
Philip Martyn Hubbard. 2002. Collision detection for interactive graphics applications.IEEE Transactions on Visualization and Computer Graphics1, 3 (2002), 218–230
work page 2002
-
[42]
Yuka Ikarashi, Gilbert Louis Bernstein, Alex Reinking, Hasan Genc, and Jonathan Ragan-Kelley. 2022. Exocompilation for productive programming of hardware accelerators. InProceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation(San Diego, CA, USA)(PLDI 2022). Association for Computing Machinery, New Yor...
-
[43]
Simon L Peyton Jones and John Launchbury. 1991. Unboxed values as first class citizens in a non-strict functional language. InConference on Functional Programming Languages and Computer Architecture. Springer, 636–666
work page 1991
-
[44]
Martin Káčerik and Jiří Bittner. 2024. SAH-Optimized k-DOP Hierarchies for Ray Tracing.Proceedings of the ACM on Computer Graphics and Interactive Techniques7, 3 (2024), 1–16
work page 2024
-
[45]
M Káčerik and Jirí Bittner. 2025. SOBB: Skewed Oriented Bounding Boxes for Ray Tracing. InComputer Graphics Forum. Wiley Online Library, e70062
work page 2025
-
[46]
Tero Karras. 2012. Maximizing parallelism in the construction of BVHs, octrees, and k-d trees. InProceedings of the Fourth ACM SIGGRAPH/Eurographics Conference on High-Performance Graphics. 33–37
work page 2012
-
[47]
Timothy L Kay and James T Kajiya. 1986. Ray tracing complex scenes.ACM SIGGRAPH computer graphics20, 4 (1986), 269–278
work page 1986
-
[48]
Timothy L. Kay and James T. Kajiya. 1986. Ray Tracing Complex Scenes. InProceedings of the 13th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’86). 269–278. doi:10.1145/15922.15916
-
[49]
Dong Jin Kim, Leonidas J Guibas, and Sung Yong Shin. 1997. Fast collision detection among multiple moving spheres. InProceedings of the thirteenth annual symposium on Computational geometry. 373–375
work page 1997
-
[50]
Tae-Joon Kim, Bochang Moon, Duksu Kim, and Sung-Eui Yoon. 2010. RACBVHs: Random-Accessible Compressed Bounding Volume Hierarchies.IEEE Transactions on Visualization and Computer Graphics16, 2 (2010), 273–286. 24 Gyurgyik et al. doi:10.1109/TVCG.2009.71
-
[51]
Fredrik Kjolstad, Shoaib Kamil, Stephen Chou, David Lugato, and Saman Amarasinghe. 2017. The tensor algebra compiler.Proceedings of the ACM on Programming Languages1, OOPSLA (2017), 1–29
work page 2017
-
[52]
James T Klosowski, Martin Held, Joseph SB Mitchell, Henry Sowizral, and Karel Zikan. 1998. Efficient collision detection using bounding volume hierarchies of k-DOPs.IEEE transactions on Visualization and Computer Graphics4, 1 (1998), 21–36
work page 1998
-
[53]
Sergey Kosarevsky, Roman Kuznetsov, and Alexey Medvedev. 2025. Ray Tracing with Bindless Vulkan on Mobile Devices, a Case Study: Performance. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Talks (SIGGRAPH Talks ’25). Association for Computing Machinery, New York, NY, USA, Article 11, 2 pages. doi:10....
-
[54]
Samuli Laine, Tero Karras, and Timo Aila. 2013. Megakernels considered harmful: Wavefront path tracing on GPUs. InProceedings of the 5th High-Performance Graphics Conference. 137–143
work page 2013
-
[55]
Thomas Larsson and Tomas Akenine-Möller. 2009. Bounding volume hierarchies of slab cut balls. InComputer Graphics Forum, Vol. 28. Wiley Online Library, 2379–2395
work page 2009
-
[56]
Christian Lauterbach, Michael Garland, Shubhabrata Sengupta, David Luebke, and Dinesh Manocha. 2009. Fast BVH construction on GPUs. InComputer Graphics Forum, Vol. 28. Wiley Online Library, 375–384
work page 2009
-
[57]
Christian Lauterbach, Sung-eui Yoon, Ming Tang, and Dinesh Manocha. 2008. ReduceM: Interactive and memory efficient ray tracing of large models. InComputer Graphics Forum, Vol. 27. Wiley Online Library, 1313–1321
work page 2008
-
[58]
Won-Jong Lee, Youngsam Shin, Jaedon Lee, Jin-Woo Kim, Jae-Ho Nah, Seokyoon Jung, Shihwa Lee, Hyun-Sang Park, and Tack-Don Han. 2013. SGRT: a mobile GPU architecture for real-time ray tracing. InProceedings of the 5th High-Performance Graphics Conference(Anaheim, California)(HPG ’13). Association for Computing Machinery, New York, NY, USA, 109–119. doi:10....
-
[59]
Xavier Leroy. 1992. Unboxed objects and polymorphic typing. InProceedings of the 19th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages(Albuquerque, New Mexico, USA)(POPL ’92). Association for Computing Machinery, New York, NY, USA, 177–188. doi:10.1145/143165.143205
-
[60]
Gábor Liktor and Karthikeyan Vaidyanathan. 2016. Bandwidth-efficient BVH layout for incremental hardware traversal.. InHigh Performance Graphics. 51–61
work page 2016
-
[61]
Daqi Lin, Elena Vasiou, Cem Yuksel, Daniel Kopta, and Erik Brunvand. 2020. Hardware-accelerated dual-split trees. Proceedings of the ACM on Computer Graphics and Interactive Techniques3, 2 (2020), 1–21
work page 2020
-
[62]
Jie Liu, Zhongyuan Zhao, Zijian Ding, Benjamin Brock, Hongbo Rong, and Zhiru Zhang. 2024. UniSparse: An Intermediate Language for General Sparse Format Customization.Proc. ACM Program. Lang.8, OOPSLA1, Article 99 (April 2024), 29 pages. doi:10.1145/3649816
-
[63]
Lufei Liu, Mohammadreza Saed, Yuan Hsi Chou, Davit Grigoryan, Tyler Nowicki, and Tor M Aamodt. 2023. LumiBench: A benchmark suite for hardware ray tracing. In2023 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 1–14
work page 2023
-
[64]
Jeffrey Mahovsky and Brian Wyvill. 2006. Memory-conserving bounding volume hierarchies with coherent raytracing. InComputer Graphics Forum, Vol. 25. Wiley Online Library, 173–182
work page 2006
-
[65]
2005.Ray tracing with reduced-precision bounding volume hierarchies
Jeffrey A Mahovsky. 2005.Ray tracing with reduced-precision bounding volume hierarchies. Ph. D. Dissertation. University of Calgary
work page 2005
-
[66]
Morgan McGuire. 2017. Computer Graphics Archive. https://casual-effects.com/data
work page 2017
-
[67]
Daniel Meister and Jiří Bittner. 2017. Parallel locally-ordered clustering for bounding volume hierarchy construction. IEEE transactions on visualization and computer graphics24, 3 (2017), 1345–1353
work page 2017
-
[68]
Daniel Meister, Jakub Boksansky, Michael Guthe, and Jiri Bittner. 2020. On Ray Reordering Techniques for Faster GPU Ray Tracing. InSymposium on Interactive 3D Graphics and Games(San Francisco, CA, USA)(I3D ’20). Association for Computing Machinery, New York, NY, USA, Article 13, 9 pages. doi:10.1145/3384382.3384534
-
[69]
Daniel Meister, Shinji Ogaki, Carsten Benthin, Michael J Doyle, Michael Guthe, and Jiří Bittner. 2021. A survey on bounding volume hierarchies for ray tracing. InComputer Graphics Forum, Vol. 40. Wiley Online Library, 683–712
work page 2021
-
[70]
Tomas Möller and Ben Trumbore. 1997. Fast, Minimum Storage Ray/Triangle Intersection.Journal of Graphics Tools 2, 1 (1997), 21–28. doi:10.1080/10867651.1997.10487468
-
[71]
Benjamin Mora. 2011. Naive ray-tracing: A divide-and-conquer approach.ACM Trans. Graph.30, 5, Article 117 (Oct. 2011), 12 pages. doi:10.1145/2019627.2019636
-
[72]
Jae-Ho Nah, Hyuck-Joo Kwon, Dong-Seok Kim, Cheol-Ho Jeong, Jinhong Park, Tack-Don Han, Dinesh Manocha, and Woo-Chan Park. 2014. RayCore: A Ray-Tracing Hardware Architecture for Mobile Devices.ACM Trans. Graph. 33, 5, Article 162 (Sept. 2014), 15 pages. doi:10.1145/2629634
-
[73]
Ian J. Palmer and Richard L. Grimsdale. 1995. Collision detection for animation using sphere-trees. InComputer Graphics Forum, Vol. 14. Wiley Online Library, 105–116. Data Layout Polymorphism for Bounding Volume Hierarchies 25
work page 1995
-
[74]
Jia Pan, Sachin Chitta, and Dinesh Manocha. 2012. FCL: A general purpose library for collision and proximity queries. In2012 IEEE International Conference on Robotics and Automation. 3859–3866. doi:10.1109/ICRA.2012.6225337
-
[75]
Jacopo Pantaleoni and David Luebke. 2010. HLBVH: Hierarchical LBVH construction for real-time ray tracing of dynamic geometry. InProceedings of the Conference on High Performance Graphics. 87–95
work page 2010
-
[76]
2023.Physically based rendering: From theory to implementation
Matt Pharr, Wenzel Jakob, and Greg Humphreys. 2023.Physically based rendering: From theory to implementation. MIT Press
work page 2023
-
[77]
Matt Pharr and William R. Mark. 2012. ispc: A SPMD compiler for high-performance CPU programming. In2012 Innovative Parallel Computing (InPar). 1–13. doi:10.1109/InPar.2012.6339601
-
[78]
Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe
-
[79]
Halide: a language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines. InProceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation (Seattle, Washington, USA)(PLDI ’13). Association for Computing Machinery, New York, NY, USA, 519–530. doi:10. 1145/2491956.2462176
-
[80]
Alexander J Root, Christophe Gyurgyik, Purvi Goel, Kayvon Fatahalian, Jonathan Ragan-Kelley, Andrew Adams, and Fredrik Kjolstad. 2025. Compiling Set Queries into Work-Efficient Tree Traversals. arXiv:2511.15000 [cs.PL] https://arxiv.org/abs/2511.15000
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.