AVATAAR: Agentic Video Answering via Temporal Adaptive Alignment and Reasoning
Pith reviewed 2026-05-17 20:14 UTC · model grok-4.3
The pith
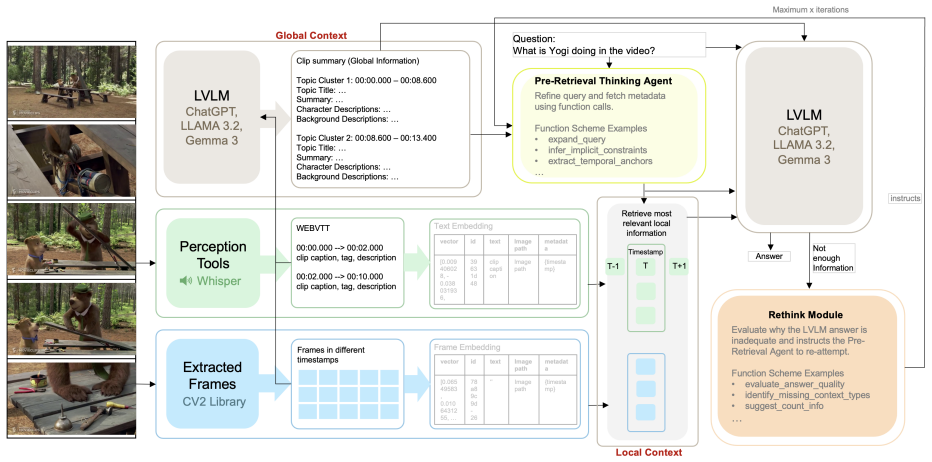
AVATAAR uses a feedback loop between a Pre Retrieval Thinking Agent and Rethink Module to refine video retrieval and enable iterative reasoning for long-form QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
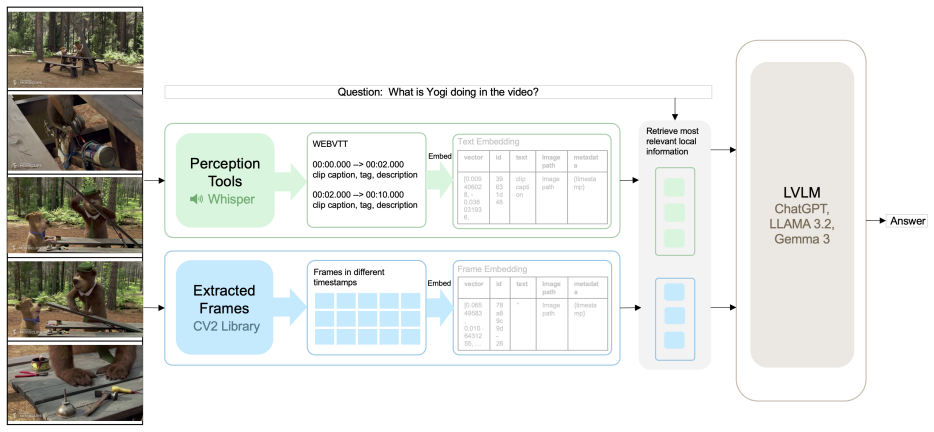
AVATAAR creates a persistent global summary of a video and connects a Pre Retrieval Thinking Agent with a Rethink Module through a feedback loop; the loop lets the system revise its retrieval approach from partial answers and thereby replicate human-like iterative reasoning for long-form video question answering.
What carries the argument
The feedback loop between the Rethink Module and the Pre Retrieval Thinking Agent, which refines retrieval strategies from partial answers.
If this is right
- Relative gains of 5.6 percent in temporal reasoning on CinePile.
- Relative gains of 5 percent in technical queries, 8 percent in theme-based questions, and 8.2 percent in narrative comprehension.
- Each module contributes positively, and the feedback loop is required for adaptability.
- The design supplies a scalable route to long-form video QA that keeps accuracy, interpretability, and extensibility.
Where Pith is reading between the lines
- The modular structure could be plugged into newer vision-language models without retraining the entire system.
- Persistent global summaries may lower the cost of processing very long videos compared with single-pass methods.
- Similar agent-plus-feedback patterns could be tested on other sequential data such as audio or multi-turn text dialogues.
Load-bearing premise
The Pre Retrieval Thinking Agent, Rethink Module, and their feedback loop each add distinct value to performance and produce human-like iterative reasoning.
What would settle it
An ablation experiment that removes the feedback loop or one of the modules and measures the resulting drop on CinePile benchmark scores would show whether those components are responsible for the reported gains.
Figures

read the original abstract
With the increasing prevalence of video content, effectively understanding and answering questions about long form videos has become essential for numerous applications. Although large vision language models (LVLMs) have enhanced performance, they often face challenges with nuanced queries that demand both a comprehensive understanding and detailed analysis. To overcome these obstacles, we introduce AVATAAR, a modular and interpretable framework that combines global and local video context, along with a Pre Retrieval Thinking Agent and a Rethink Module. AVATAAR creates a persistent global summary and establishes a feedback loop between the Rethink Module and the Pre Retrieval Thinking Agent, allowing the system to refine its retrieval strategies based on partial answers and replicate human-like iterative reasoning. On the CinePile benchmark, AVATAAR demonstrates significant improvements over a baseline, achieving relative gains of +5.6% in temporal reasoning, +5% in technical queries, +8% in theme-based questions, and +8.2% in narrative comprehension. Our experiments confirm that each module contributes positively to the overall performance, with the feedback loop being crucial for adaptability. These findings highlight AVATAAR's effectiveness in enhancing video understanding capabilities. Ultimately, AVATAAR presents a scalable solution for long-form Video Question Answering (QA), merging accuracy, interpretability, and extensibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AVATAAR, a modular and interpretable framework for long-form video question answering. It integrates global and local video context via a Pre Retrieval Thinking Agent and a Rethink Module that form a feedback loop to enable iterative, human-like reasoning and refinement of retrieval strategies. On the CinePile benchmark, the work reports relative gains over a baseline of +5.6% in temporal reasoning, +5% in technical queries, +8% in theme-based questions, and +8.2% in narrative comprehension, asserting that each module contributes positively and that the feedback loop is crucial for adaptability.
Significance. If the claimed gains can be substantiated with quantitative ablations, absolute scores, and proper baselines, AVATAAR would provide a useful example of an extensible, interpretable agentic architecture for video QA that addresses limitations of standard LVLMs on nuanced long-form queries. The emphasis on modularity and feedback-driven adaptability aligns with growing interest in agentic systems and could support future extensions.
major comments (2)
- [Abstract] Abstract: The central claim that 'experiments confirm that each module contributes positively to the overall performance' and that the feedback loop is 'crucial for adaptability' is unsupported because no ablation studies, component-removal results, or error analyses are supplied to isolate the effects of the Pre Retrieval Thinking Agent, Rethink Module, or their iterative loop. The reported relative gains (+5.6%, +5%, +8%, +8.2%) therefore cannot be confidently attributed to these elements rather than to unmentioned factors such as the base LVLM or prompting choices.
- [Abstract] Abstract / Experiments: Benchmark results are given only as relative percentage gains on CinePile without absolute accuracy numbers, baseline model specification, number of evaluated questions, variance estimates, or statistical significance tests. This prevents assessment of whether the improvements are robust or practically meaningful.
minor comments (2)
- [Abstract] The description of the 'persistent global summary' is introduced at a high level without specifying its construction method, update mechanism, or how it interacts with local context retrieval.
- Consider expanding the related-work discussion to include recent agentic or iterative reasoning frameworks in vision-language models for clearer positioning of the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions made to improve clarity, transparency, and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experiments confirm that each module contributes positively to the overall performance' and that the feedback loop is 'crucial for adaptability' is unsupported because no ablation studies, component-removal results, or error analyses are supplied to isolate the effects of the Pre Retrieval Thinking Agent, Rethink Module, or their iterative loop. The reported relative gains (+5.6%, +5%, +8%, +8.2%) therefore cannot be confidently attributed to these elements rather than to unmentioned factors such as the base LVLM or prompting choices.
Authors: We acknowledge the referee's point that stronger isolation of module contributions would better support the abstract claims. The manuscript presents comparative results across configurations that show incremental gains when adding the Pre Retrieval Thinking Agent, Rethink Module, and feedback loop. To directly address this concern and enable clearer attribution, we have added a dedicated ablation subsection in the Experiments section. This includes component-removal experiments (with and without each module and the iterative loop) and a brief error analysis highlighting cases where the feedback mechanism improves retrieval and reasoning. revision: yes
-
Referee: [Abstract] Abstract / Experiments: Benchmark results are given only as relative percentage gains on CinePile without absolute accuracy numbers, baseline model specification, number of evaluated questions, variance estimates, or statistical significance tests. This prevents assessment of whether the improvements are robust or practically meaningful.
Authors: We agree that absolute scores and supporting details are necessary for a complete evaluation. The revised manuscript now reports absolute accuracy numbers for both AVATAAR and the baseline on each CinePile category in the abstract and results tables. We explicitly name the base LVLM, state the number of questions evaluated from the benchmark, include variance estimates (standard deviation across runs), and add paired statistical significance tests to demonstrate that the reported relative gains are robust. revision: yes
Circularity Check
No circularity: empirical claims rest on reported benchmark gains
full rationale
The paper introduces the AVATAAR framework as a modular architecture combining global/local video context, a Pre Retrieval Thinking Agent, and a Rethink Module with a feedback loop. It reports relative gains on CinePile (+5.6% temporal reasoning, +5% technical, +8% theme-based, +8.2% narrative) and states that experiments confirm positive module contributions. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided text. The central claims are empirical attributions to the described components rather than any reduction of outputs to inputs by construction, self-citation load-bearing, or ansatz smuggling. The derivation chain is therefore self-contained with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large vision language models often face challenges with nuanced queries that demand both comprehensive understanding and detailed analysis of long videos.
invented entities (2)
-
Pre Retrieval Thinking Agent
no independent evidence
-
Rethink Module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A comprehensive study of deep video action recognition,
Y . Zhu, X. Li, C. Liu, M. Zolfaghari, Y . Xiong, C. Wu, Z. Zhang, J. Tighe, R. Manmatha, and M. Li, “A comprehensive study of deep video action recognition,” 2020. [Online]. Available: https://arxiv.org/abs/2012.06567
-
[2]
Videomultiagents: A multi-agent framework for video question answering,
N. Kugo, X. Li, Z. Li, and A. G. et al., “Videomultiagents: A multi-agent framework for video question answering,” 2025. [Online]. Available: https://arxiv.org/abs/2504.20091
-
[3]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, L. Marris, S. Petulla, C. Gaffney, A. Aharoni, N. Lintz, T. C. Pais, H. Jacobsson, I. Szpektor, N.-J. Jiang, K. Haridasan, A. Omran, N. Saunshi, D. Bahri, G. Mishra, E. Chu, T. Boyd, B. Hekman, A. Parisi, C. Zhang, K. Kawintiranon, T. Bed...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, and R. A. et al., “On the opportunities and risks of foundation models,” 2022. [Online]. Available: https://arxiv.org/abs/2108.07258
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
R. Rawal, K. Saifullah, R. Basri, D. Jacobs, G. Somepalli, and T. Goldstein, “Cinepile: A long video question answering dataset and benchmark,”arXiv preprint arXiv:2405.08813, 2024
-
[6]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacyet al., “Learning transferable visual models from natural language supervision,” inICML, 2021
work page 2021
-
[7]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. Le, Y .-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 4904–4916
work page 2021
-
[8]
Bridgetower: Building bridges between encoders in vision-language representation learning,
H. Xu, Z. Gan, Y . Chenet al., “Bridgetower: Building bridges between encoders in vision-language representation learning,” inNeurIPS, 2022
work page 2022
-
[9]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyalet al., “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[10]
Flamingo: a Visual Language Model for Few-Shot Learning
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, and I. B. et al., “Flamingo: a visual language model for few-shot learning,” 2022. [Online]. Available: https://arxiv.org/abs/2204.14198
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Internvideo: General video foundation models via generative and discriminative learning,
W. Wang, Y . Lin, X. Zhanget al., “Internvideo: General video foundation models via generative and discriminative learning,” inCVPR, 2024
work page 2024
-
[13]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
S. Zhaoet al., “Video-llama: An instruction-tuned audio-visual language model for video understanding,”arXiv preprint arXiv:2306.02858, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
H. Zhanget al., “Video-llava: Learning united visual representation for video understanding with llms,”arXiv preprint arXiv:2311.16502, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, A. M ˛ adry, A. Baker-Whitcomb, and A. Beutel, “Gpt-4o system card,” 2024. [Online]. Available: https://arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Anthropic, “Claude 3 model card,” 2024, accessed: 2025-08-01. [Online]. Available: https://www.anthropic.com/news/claude-3-model-card
work page 2024
-
[17]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, and A. Al-Dahle, “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Chameleon: Mixed-modal early-fusion foundation models,
Chameleon, “Chameleon: Mixed-modal early-fusion foundation models,”
-
[19]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
[Online]. Available: https://arxiv.org/abs/2405.09818
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,” inAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[21]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
work page 2020
-
[22]
Reflexion: Language Agents with Verbal Reinforcement Learning
M. Shinn, E. Wallace, J. Ling, D. Dohan, E. Akyürek, J. Austin, T. Brown, D. Zhou, W. W. Cohen, and K. Guu, “Reflexion: Language agents with verbal reinforcement learning,”arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
A survey on agentic retrieval-augmented generation,
A. Singh, A. Xuet al., “A survey on agentic retrieval-augmented generation,”arXiv preprint arXiv:2401.10536, 2025
-
[24]
Canal – cyber activity news alerting language model: Empirical approach vs. expensive LLM,
U. Patel, F. Yeh, and C. Gondhalekar, “Canal – cyber activity news alerting language model: Empirical approach vs. expensive LLM,”arXiv preprint arXiv:2405.06772, 2024
-
[25]
Fanal – financial activity news alerting language modeling framework,
U. Patel, F. Yeh, C. Gondhalekar, and H. Nalluri, “Fanal – financial activity news alerting language modeling framework,”arXiv preprint arXiv:2412.03527, 2024
-
[26]
C. Gondhalekar, U. Patel, and F. Yeh, “MultiFinRAG: An optimized mul- timodal retrieval-augmented generation (RAG) framework for financial question answering,”arXiv preprint arXiv:2506.20821, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Videorag: Retrieval-augmented video question answering at scale,
L. Chenet al., “Videorag: Retrieval-augmented video question answering at scale,”arXiv preprint arXiv:2402.02267, 2024
-
[28]
Dig into multi-modal cues for video retrieval with hierarchical alignment,
W. Wang, M. Zhang, R. Chen, and G. C. et al., “Dig into multi-modal cues for video retrieval with hierarchical alignment,” in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21), 2021, pp. 1110–1116. [Online]. Available: https://www.ijcai.org/proceedings/2021/0154.pdf
work page 2021
-
[29]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” arXiv preprint arXiv:2212.04356, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
ActivityNet-QA: A Dataset for Understanding Complex Web Videos via Question Answering
Z. Yu, D. Xu, J. Yu, T. Yu, Z. Zhao, Y . Zhuang, and D. Tao, “Activitynet- qa: A dataset for understanding complex web videos via question answering,” 2019. [Online]. Available: https://arxiv.org/abs/1906.02467
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Next-qa: Next phase of question-answering to explaining temporal actions,
J. Xiao, X. Shang, A. Yao, and T.-S. Chua, “Next-qa: Next phase of question-answering to explaining temporal actions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 9777–9786
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.