SciPostLayoutTree: A Dataset for Structural Analysis of Scientific Posters
Pith reviewed 2026-05-17 06:01 UTC · model grok-4.3
The pith
A new dataset of about 8000 posters with reading order and parent-child annotations, paired with a Layout Tree Decoder, improves accuracy on spatially challenging relations like upward and long-distance ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
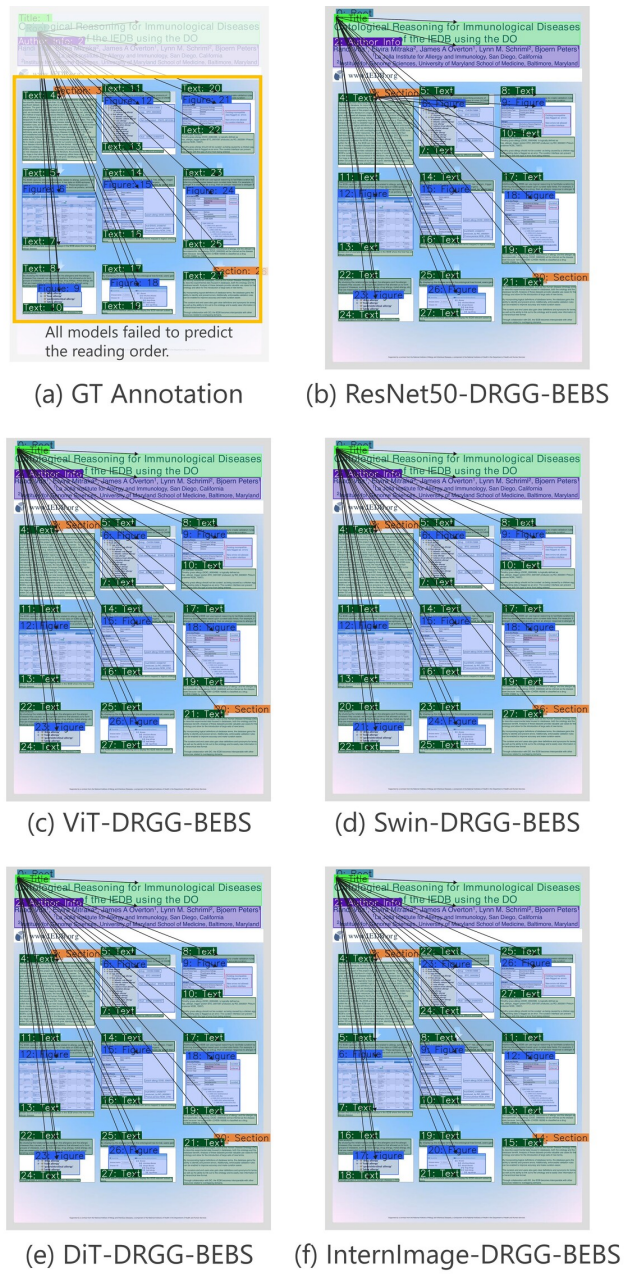
The central claim is that SciPostLayoutTree supplies a large collection of posters with reading order and parent-child annotations that feature more spatially challenging relations than earlier datasets, and that the Layout Tree Decoder, by integrating visual features with bounding box position and category details plus beam search, raises prediction accuracy for those relations and supplies a working baseline for poster structure analysis.
What carries the argument
Layout Tree Decoder that fuses visual features with bounding box position and category information and applies beam search to select relation sequences with overall plausibility.
If this is right
- More accurate extraction of logical structure from posters that use non-standard layouts.
- Support for interfaces that present poster content in the correct sequence for readers.
- A measurable baseline against which future models for poster parsing can be compared.
Where Pith is reading between the lines
- The dataset could enable automatic conversion of posters into accessible text or audio summaries that respect original reading order.
- Similar annotation schemes and decoding methods might transfer to analyzing conference slides or scientific infographics.
- Standardized structural labels could help train models that compare how different researchers visually organize the same findings.
Load-bearing premise
The human annotations for reading order and parent-child relations are consistent across posters and correctly capture the intended structure.
What would settle it
A replication study in which independent annotators relabel a subset of the posters and show low agreement on reading order or parent-child links, or in which the proposed decoder fails to outperform simpler baselines on the subset of upward, horizontal, and long-distance relations.
Figures
















read the original abstract
Scientific posters play a vital role in academic communication by presenting ideas through visual summaries. Analyzing reading order and parent-child relations of posters is essential for building structure-aware interfaces that facilitate clear and accurate understanding of research content. Despite their prevalence in academic communication, posters remain underexplored in structural analysis research, which has primarily focused on papers. To address this gap, we constructed SciPostLayoutTree, a dataset of approximately 8,000 posters annotated with reading order and parent-child relations. Compared to an existing structural analysis dataset, SciPostLayoutTree contains more instances of spatially challenging relations, including upward, horizontal, and long-distance relations. As a solution to these challenges, we develop Layout Tree Decoder, which incorporates visual features as well as bounding box features including position and category information. The model also uses beam search to predict relations while capturing sequence-level plausibility. Experimental results demonstrate that our model improves the prediction accuracy for spatially challenging relations and establishes a solid baseline for poster structure analysis. The dataset is publicly available at https://huggingface.co/datasets/omron-sinicx/scipostlayouttree. The code is also publicly available at https://github.com/omron-sinicx/scipostlayouttree.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SciPostLayoutTree, a dataset of approximately 8,000 scientific posters annotated with reading order and parent-child relations. It emphasizes that this dataset features more spatially challenging relations (upward, horizontal, and long-distance) compared to existing structural analysis datasets primarily focused on papers. The authors introduce the Layout Tree Decoder model, which integrates visual features along with bounding box features including position and category information, and employs beam search to predict relations while accounting for sequence-level plausibility. Experimental results are reported to demonstrate improved prediction accuracy for these challenging relations, establishing a baseline for poster structure analysis. The dataset and code are made publicly available.
Significance. This contribution addresses an important gap in computer vision and document analysis research by focusing on the structural analysis of scientific posters, an area that has received less attention than paper layout analysis. The public release of the dataset and code supports reproducibility and enables future work on structure-aware interfaces for academic communication. The approach of using beam search to capture global consistency in relation predictions is a sensible way to handle the complexities of poster layouts. If the annotations are shown to be reliable, the dataset could become a standard benchmark for this task.
major comments (2)
- [Abstract] The abstract states that 'Experimental results demonstrate that our model improves the prediction accuracy for spatially challenging relations' but provides no specific numeric metrics, details on baselines, or error analysis. This makes it challenging to evaluate the practical significance of the claimed improvements.
- [Dataset Construction] The section on dataset construction does not provide details on the annotation protocol, guidelines given to annotators, or any inter-annotator agreement metrics for the reading order and parent-child relations. Given that the central claims rely on the accuracy of these human annotations as ground truth—particularly for ambiguous spatial layouts in posters—this omission is load-bearing and requires clarification to substantiate the evaluation results.
minor comments (1)
- [Introduction] The introduction could benefit from additional citations to recent works on document layout analysis to strengthen the motivation for focusing on posters.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive assessment of the significance of SciPostLayoutTree. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] The abstract states that 'Experimental results demonstrate that our model improves the prediction accuracy for spatially challenging relations' but provides no specific numeric metrics, details on baselines, or error analysis. This makes it challenging to evaluate the practical significance of the claimed improvements.
Authors: We agree that the abstract would be strengthened by including concrete quantitative results. In the revised version, we will update the abstract to report specific accuracy improvements on upward, horizontal, and long-distance relations relative to the baselines, along with a concise reference to the evaluation protocol. revision: yes
-
Referee: [Dataset Construction] The section on dataset construction does not provide details on the annotation protocol, guidelines given to annotators, or any inter-annotator agreement metrics for the reading order and parent-child relations. Given that the central claims rely on the accuracy of these human annotations as ground truth—particularly for ambiguous spatial layouts in posters—this omission is load-bearing and requires clarification to substantiate the evaluation results.
Authors: We acknowledge this gap. The revised manuscript will expand the Dataset Construction section with a detailed account of the annotation protocol, the specific guidelines provided to annotators for handling spatial ambiguities, and inter-annotator agreement metrics for both reading order and parent-child relations to support the reliability of the ground-truth annotations. revision: yes
Circularity Check
No circularity: standard dataset construction and model evaluation on released data
full rationale
The paper constructs SciPostLayoutTree (~8k annotated posters) and evaluates a Layout Tree Decoder on it. Claims rest on empirical accuracy improvements for challenging relations using standard train-test protocols on the public dataset. No equations, fitted parameters renamed as predictions, or self-citation chains reduce the results to inputs by construction. Annotation consistency is an external validity concern, not a circularity issue per the defined patterns. Derivation chain is self-contained against the released benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Posters possess consistent hierarchical parent-child relations and a linear reading order that can be annotated reliably by humans.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We develop Layout Tree Decoder, which incorporates visual features as well as bounding box features including position and category information. The model also uses beam search to predict relations while capturing sequence-level plausibility.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experimental results demonstrate that our model improves the prediction accuracy for spatially challenging relations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scibert: A pre- trained language model for scientific text, 2019
Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pre- trained language model for scientific text, 2019. 15
work page 2019
-
[2]
Graph-based document structure analysis, 2025
Yufan Chen, Ruiping Liu, Junwei Zheng, Di Wen, Kunyu Peng, Jiaming Zhang, and Rainer Stiefelhagen. Graph-based document structure analysis, 2025. 1, 2, 4
work page 2025
-
[3]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. 4, 6, 14
work page 2021
-
[4]
Dolphin: Doc- ument image parsing via heterogeneous anchor prompting,
Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, Jingqun Tang, Hao Liu, and Can Huang. Dolphin: Doc- ument image parsing via heterogeneous anchor prompting,
-
[5]
Beam search strate- gies for neural machine translation
Markus Freitag and Yaser Al-Onaizan. Beam search strate- gies for neural machine translation. InProceedings of the First Workshop on Neural Machine Translation. Association for Computational Linguistics, 2017. 5
work page 2017
-
[6]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. 4, 6, 14
work page 2015
-
[7]
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn, 2018. 4
work page 2018
-
[8]
Mathreader : Text-to-speech for mathe- matical documents, 2025
Sieun Hyeon, Kyudan Jung, Nam-Joon Kim, Hyun Gon Ryu, and Jaeyoung Do. Mathreader : Text-to-speech for mathe- matical documents, 2025. 1
work page 2025
-
[9]
Document understanding dataset and evaluation (dude), 2023
Jordy Van Landeghem, Rub ´en Tito, Łukasz Borchmann, Michał Pietruszka, Paweł J´oziak, Rafał Powalski, Dawid Ju- rkiewicz, Micka ¨el Coustaty, Bertrand Ackaert, Ernest Val- veny, Matthew Blaschko, Sien Moens, and Tomasz Sta- nisławek. Document understanding dataset and evaluation (dude), 2023. 1
work page 2023
-
[10]
A diversity-promoting objective function for neural conversation models, 2016
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A diversity-promoting objective function for neural conversation models, 2016. 5
work page 2016
-
[11]
Dit: Self-supervised pre-training for docu- ment image transformer, 2022
Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, and Furu Wei. Dit: Self-supervised pre-training for docu- ment image transformer, 2022. 6, 14
work page 2022
-
[12]
Structure-aware language model pretraining improves dense retrieval on structured data, 2023
Xinze Li, Zhenghao Liu, Chenyan Xiong, Shi Yu, Yu Gu, Zhiyuan Liu, and Ge Yu. Structure-aware language model pretraining improves dense retrieval on structured data, 2023. 1
work page 2023
-
[13]
Feature pyramid networks for object detection, 2017
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection, 2017. 4
work page 2017
-
[14]
Swin trans- former: Hierarchical vision transformer using shifted win- dows, 2021
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin trans- former: Hierarchical vision transformer using shifted win- dows, 2021. 6, 14
work page 2021
-
[15]
Sgdr: Stochastic gradient descent with warm restarts, 2017
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts, 2017. 14
work page 2017
-
[16]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. 14
work page 2019
-
[17]
Hrdoc: Dataset and base- line method toward hierarchical reconstruction of document structures, 2023
Jiefeng Ma, Jun Du, Pengfei Hu, Zhenrong Zhang, Jianshu Zhang, Huihui Zhu, and Cong Liu. Hrdoc: Dataset and base- line method toward hierarchical reconstruction of document structures, 2023. 2, 6
work page 2023
-
[18]
Efficient computa- tion of the tree edit distance.ACM Trans
Mateusz Pawlik and Nikolaus Augsten. Efficient computa- tion of the tree edit distance.ACM Trans. Database Syst., 40 (1), 2015. 6
work page 2015
-
[19]
Tree edit distance: Robust and memory-efficient.Information Systems, 56:157– 173, 2016
Mateusz Pawlik and Nikolaus Augsten. Tree edit distance: Robust and memory-efficient.Information Systems, 56:157– 173, 2016. 6
work page 2016
-
[20]
Yu-Ting Qiang, Yan-Wei Fu, Xiao Yu, Yan-Wen Guo, Zhi- Hua Zhou, and Leonid Sigal. Learning to Generate Posters of Scientific Papers by Probabilistic Graphical Models.Journal of Computer Science and Technology, 34(1):155–169, 2019. 2
work page 2019
-
[21]
Docparser: Hierarchical structure parsing of document renderings, 2021
Johannes Rausch, Octavio Martinez, Fabian Bissig, Ce Zhang, and Stefan Feuerriegel. Docparser: Hierarchical structure parsing of document renderings, 2021. 2
work page 2021
-
[22]
Faster r-cnn: Towards real-time object detection with region proposal networks, 2016
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks, 2016. 4
work page 2016
-
[23]
Abigail See, Peter J. Liu, and Christopher D. Manning. Get to the point: Summarization with pointer-generator net- works, 2017. 5
work page 2017
-
[24]
R. Smith. An overview of the tesseract ocr engine. InNinth International Conference on Document Analysis and Recog- nition (ICDAR 2007), pages 629–633, 2007. 15
work page 2007
-
[25]
P2p: Automated paper-to-poster gen- eration and fine-grained benchmark, 2025
Tao Sun, Enhao Pan, Zhengkai Yang, Kaixin Sui, Jiajun Shi, Xianfu Cheng, Tongliang Li, Wenhao Huang, Ge Zhang, Jian Yang, and Zhoujun Li. P2p: Automated paper-to-poster gen- eration and fine-grained benchmark, 2025. 2
work page 2025
-
[26]
Scipost- layout: A dataset for layout analysis and layout generation of scientific posters
Shohei Tanaka, Hao Wang, and Yoshitaka Ushiku. Scipost- layout: A dataset for layout analysis and layout generation of scientific posters. In35th British Machine Vision Con- ference 2024, BMVC 2024, Glasgow, UK, November 25-28,
work page 2024
- [27]
-
[28]
Hi- erarchical multimodal transformers for multi-page docvqa,
Rub `en Tito, Dimosthenis Karatzas, and Ernest Valveny. Hi- erarchical multimodal transformers for multi-page docvqa,
-
[29]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. 5, 14
work page 2023
-
[30]
Show and tell: A neural image caption gen- erator, 2015
Oriol Vinyals, Alexander Toshev, Samy Bengio, and Du- mitru Erhan. Show and tell: A neural image caption gen- erator, 2015. 5
work page 2015
-
[31]
Jiawei Wang, Kai Hu, Zhuoyao Zhong, Lei Sun, and Qiang Huo. Detect-order-construct: A tree construction based ap- proach for hierarchical document structure analysis, 2024. 1, 2, 5, 6
work page 2024
-
[32]
Unihdsa: A unified relation prediction approach for hierarchical document struc- ture analysis, 2025
Jiawei Wang, Kai Hu, and Qiang Huo. Unihdsa: A unified relation prediction approach for hierarchical document struc- ture analysis, 2025. 5
work page 2025
-
[33]
Internim- age: Exploring large-scale vision foundation models with deformable convolutions, 2023
Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, Xiaogang Wang, and Yu Qiao. Internim- age: Exploring large-scale vision foundation models with deformable convolutions, 2023. 4, 6, 14
work page 2023
-
[34]
Layoutreader: Pre-training of text and layout for read- ing order detection, 2021
Zilong Wang, Yiheng Xu, Lei Cui, Jingbo Shang, and Furu Wei. Layoutreader: Pre-training of text and layout for read- ing order detection, 2021. 2
work page 2021
-
[35]
Yujia Xiao, Shaofei Zhang, Xi Wang, Xu Tan, Lei He, Sheng Zhao, Frank K. Soong, and Tan Lee. Contextspeech: Ex- pressive and efficient text-to-speech for paragraph reading. InINTERSPEECH 2023, page 4883–4887. ISCA, 2023. 1
work page 2023
-
[36]
DocHieNet: A large and diverse dataset for document hierarchy parsing
Hangdi Xing, Changxu Cheng, Feiyu Gao, Zirui Shao, Zhi Yu, Jiajun Bu, Qi Zheng, and Cong Yao. DocHieNet: A large and diverse dataset for document hierarchy parsing. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1129–1142, Miami, Florida, USA, 2024. Association for Computational Linguis- tics. 2, 3, 11
work page 2024
-
[37]
Neural Content Extraction for Poster Generation of Scientific Papers, 2021
Sheng Xu and Xiaojun Wan. Neural Content Extraction for Poster Generation of Scientific Papers, 2021. 2
work page 2021
-
[38]
Chong Zhang, Ya Guo, Yi Tu, Huan Chen, Jinyang Tang, Huijia Zhu, Qi Zhang, and Tao Gui. Reading order matters: Information extraction from visually-rich documents by to- ken path prediction, 2023. 5
work page 2023
-
[39]
Modeling layout reading order as ordering rela- tions for visually-rich document understanding
Chong Zhang, Yi Tu, Yixi Zhao, Chenshu Yuan, Huan Chen, Yue Zhang, Mingxu Chai, Ya Guo, Huijia Zhu, Qi Zhang, and Tao Gui. Modeling layout reading order as ordering rela- tions for visually-rich document understanding. InProceed- ings of the 2024 Conference on Empirical Methods in Natu- ral Language Processing, pages 9658–9678, Miami, Florida, USA, 2024. ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.