PRADA: Probability-Ratio-Based Attribution and Detection of Autoregressive-Generated Images
Pith reviewed 2026-05-17 04:50 UTC · model grok-4.3
The pith
The ratio of conditional to unconditional token probabilities uniquely marks images generated by a specific autoregressive model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
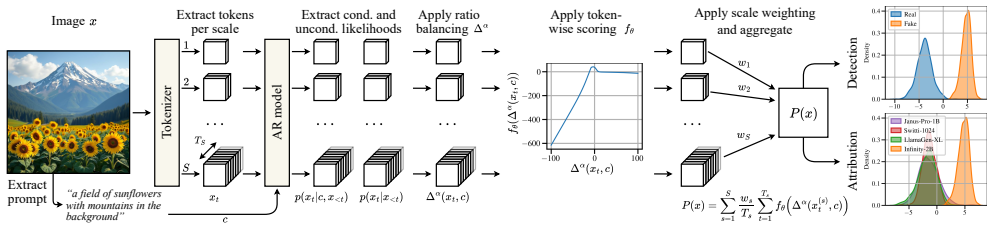
Whenever an image is generated by a particular autoregressive model, its probability ratio shows unique characteristics which are not present for images generated by other models or real images. These characteristics are exploited for threshold-based attribution and detection by calibrating a simple, model-specific score function based on the ratio of the model's conditional and unconditional probability for the autoregressive token sequence representing the given image.
What carries the argument
The ratio of a model's conditional probability to its unconditional probability for the autoregressive token sequence of the image.
If this is right
- A single probability-ratio calculation per image enables attribution to one of several known autoregressive models without retraining complex classifiers.
- The same ratio signal separates autoregressive-generated images from real images using model-specific thresholds.
- The approach applies uniformly to both class-to-image and text-to-image autoregressive generators after per-model calibration.
- Because the signal comes from the model's native probability estimates, it provides a direct link to the generation process itself.
Where Pith is reading between the lines
- The same probability-ratio idea could be tested on sequential generators in other domains such as audio or video to see whether analogous signatures appear.
- If the ratio patterns persist across model versions, they might serve as a lightweight fingerprint for tracing model families without full access to training data.
- Pairing the ratio score with existing visual or statistical detectors could yield hybrid systems that remain effective when one cue is adversarially suppressed.
Load-bearing premise
The probability-ratio characteristics are sufficiently unique to each source model and stable enough across images to support reliable threshold-based detection and attribution even for unseen images and models.
What would settle it
If the calibrated score distributions for images from different autoregressive models overlap substantially or if scores for images from a new model fall into the range of a different model or of real images, the threshold-based attribution and detection would fail.
Figures















read the original abstract
Autoregressive (AR) image generation has recently emerged as a powerful paradigm for image synthesis. Leveraging the generation principle of large language models, they allow for efficiently generating deceptively real-looking images, further increasing the need for reliable detection methods. However, to date there is a lack of work specifically targeting the detection of images generated by AR image generators. In this work, we present PRADA (Probability-Ratio-Based Attribution and Detection of Autoregressive-Generated Images), a simple and interpretable approach that can reliably detect AR-generated images and attribute them to their respective source model. The key idea is to inspect the ratio of a model's conditional and unconditional probability for the autoregressive token sequence representing a given image. Whenever an image is generated by a particular model, its probability ratio shows unique characteristics which are not present for images generated by other models or real images. We exploit these characteristics for threshold-based attribution and detection by calibrating a simple, model-specific score function. Our experimental evaluation shows that PRADA is highly effective against eight class-to-image and four text-to-image models. We release our code and data at github.com/jonasricker/prada.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRADA, a method for detecting and attributing images generated by autoregressive (AR) models. It computes the ratio of a model's conditional probability to its unconditional probability over the token sequence of a given image and uses model-specific thresholds on this ratio for detection and source attribution. The central claim is that these ratios exhibit unique, stable characteristics for images from a particular AR generator that are absent in real images or outputs from other models. Experiments are reported on eight class-to-image and four text-to-image AR models, with code and data released.
Significance. If the probability-ratio signatures prove unique and stable, the work offers a lightweight, interpretable detection approach for the emerging class of AR image generators, addressing a gap left by methods focused on GANs or diffusion models. The open release of code and data is a clear strength for reproducibility.
major comments (2)
- [Experimental Evaluation] The central claim that probability ratios produce non-overlapping, model-specific statistics rests on thresholds calibrated on a finite training set of images. No analysis is provided of how these distributions shift under changes in sampling temperature, prompt distribution, or architectural variants, which directly threatens the reliability of threshold-based attribution and detection for unseen images and models.
- [Method] The method defines a model-specific score function via simple thresholds on the probability ratio, yet the manuscript does not report sensitivity analysis or cross-validation details for threshold selection. This leaves open whether the reported effectiveness on the eight class-to-image and four text-to-image models generalizes beyond the calibration set.
minor comments (2)
- [Method] Notation for conditional versus unconditional probabilities should be introduced with an explicit equation early in the method section for clarity.
- [Figures] Figure captions could more explicitly state the number of images and models used in each panel to aid quick interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the robustness of our threshold-based detection and attribution approach. We address each major comment below and describe planned revisions to improve the manuscript's rigor while preserving the core contributions of PRADA.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central claim that probability ratios produce non-overlapping, model-specific statistics rests on thresholds calibrated on a finite training set of images. No analysis is provided of how these distributions shift under changes in sampling temperature, prompt distribution, or architectural variants, which directly threatens the reliability of threshold-based attribution and detection for unseen images and models.
Authors: We agree this is a substantive limitation in the current evaluation. While our experiments cover eight class-to-image and four text-to-image models with diverse architectures, we did not systematically vary sampling temperature, prompt distributions, or test architectural variants beyond those reported. The probability ratio is derived directly from each model's conditional and unconditional token probabilities, which we expect to reflect model-specific characteristics, but additional validation is warranted. In the revised manuscript we will add a sensitivity analysis section that includes experiments with multiple sampling temperatures on a subset of models and a discussion of how prompt variations affect the ratio distributions. We will also explicitly note the scope of generalization to unseen models as a limitation. revision: partial
-
Referee: [Method] The method defines a model-specific score function via simple thresholds on the probability ratio, yet the manuscript does not report sensitivity analysis or cross-validation details for threshold selection. This leaves open whether the reported effectiveness on the eight class-to-image and four text-to-image models generalizes beyond the calibration set.
Authors: Thresholds were selected on a calibration set of generated and real images to achieve high true-positive rates with low false positives on real data, as described in the experimental protocol. We did not include a formal sensitivity study or cross-validation procedure in the original submission. We will revise the method and experimental sections to provide explicit details on the calibration process, report performance across a range of threshold values, and include a sensitivity analysis showing how detection and attribution metrics vary with threshold choice. This will clarify the stability of the reported results. revision: yes
Circularity Check
No significant circularity in PRADA's probability-ratio method
full rationale
The paper computes the ratio of conditional to unconditional token probabilities directly from the AR model on a given image sequence and treats observed distributional differences versus real images or other generators as an empirical finding. Threshold calibration for detection/attribution is performed on held-out samples from the source models in a standard supervised manner. No step reduces the claimed uniqueness or detection performance to a self-definitional loop, a fitted parameter renamed as prediction, or a load-bearing self-citation. The derivation chain remains independent of its own outputs and is evaluated against external distributions (real images and alternate generators).
Axiom & Free-Parameter Ledger
free parameters (1)
- model-specific detection thresholds
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The key idea is to inspect the ratio of a model's conditional and unconditional probability for the autoregressive token sequence... We exploit these characteristics for threshold-based attribution and detection by calibrating a simple, model-specific score function.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Source generator attribution via inversion
Michael Albright and Scott McCloskey. Source generator attribution via inversion. InCVPRW, 2019. 3
work page 2019
-
[2]
Quentin Bammey. Synthbuster: Towards detection of diffu- sion model generated images.IEEE Open Journal of Signal Processing, 2023. 6, 5
work page 2023
-
[3]
A geometric and photo- metric exploration of GAN and diffusion synthesized faces
Maty ´aˇs Boh ´aˇcek and Hany Farid. A geometric and photo- metric exploration of GAN and diffusion synthesized faces. InCVPRW, 2023. 2
work page 2023
-
[4]
George Cazenavette, Avneesh Sud, Thomas Leung, and Ben Usman. FakeInversion: Learning to detect images from un- seen text-to-image models by inverting Stable Diffusion. In CVPR, 2024. 2
work page 2024
-
[5]
What makes fake images detectable? Understanding prop- erties that generalize
Lucy Chai, David Bau, Ser-Nam Lim, and Phillip Isola. What makes fake images detectable? Understanding prop- erties that generalize. InECCV, 2020. 2
work page 2020
-
[6]
Baoying Chen, Jishen Zeng, Jianquan Yang, and Rui Yang. DRCT: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images. InICML,
-
[7]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv Preprint, 2025. 3, 6, 1
work page 2025
-
[8]
Sungik Choi, Sungwoo Park, Jaehoon Lee, Seunghyun Kim, Stanley Jungkyu Choi, and Moontae Lee. HFI: A unified framework for training-free detection and implicit water- marking of latent diffusion model generated images.arXiv Preprint, 2024. 2
work page 2024
-
[9]
FIRE: Robust detection of diffusion- generated images via frequency-guided reconstruction error
Beilin Chu, Xuan Xu, Xin Wang, Yufei Zhang, Weike You, and Linna Zhou. FIRE: Robust detection of diffusion- generated images via frequency-guided reconstruction error. InCVPR, 2025. 2
work page 2025
-
[10]
Word association norms, mutual information, and lexicography.Computa- tional linguistics, 1990
Kenneth Church and Patrick Hanks. Word association norms, mutual information, and lexicography.Computa- tional linguistics, 1990. 4
work page 1990
-
[11]
Fast and accurate deep network learning by exponential linear units (elus)
Djork-Arn ´e Clevert, Thomas Unterthiner, and Sepp Hochre- iter. Fast and accurate deep network learning by exponential linear units (elus). InICLR, 2016. 4
work page 2016
-
[12]
Riccardo Corvi, Davide Cozzolino, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. Intriguing properties of syn- thetic images: From generative adversarial networks to dif- fusion models. InCVPRW, 2023. 2
work page 2023
-
[13]
Towards universal GAN image detection
Davide Cozzolino, Diego Gragnaniello, Giovanni Poggi, and Luisa Verdoliva. Towards universal GAN image detection. In VCIP, 2021. 2
work page 2021
-
[14]
Raising the bar of AI-generated image detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nießner, and Luisa Verdoliva. Raising the bar of AI-generated image detection with CLIP. InCVPRW, 2024. 2
work page 2024
-
[15]
Zero-shot detection of AI-generated im- ages
Davide Cozzolino, Giovanni Poggi, Matthias Nießner, and Luisa Verdoliva. Zero-shot detection of AI-generated im- ages. InECCV, 2024. 2
work page 2024
-
[16]
RAISE: A raw images dataset for dig- ital image forensics
Duc-Tien Dang-Nguyen, Cecilia Pasquini, Valentina Conot- ter, and Giulia Boato. RAISE: A raw images dataset for dig- ital image forensics. InMMSYS, 2015. 6
work page 2015
-
[17]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InCVPR, 2009. 6
work page 2009
-
[18]
Diffusion models beat GANs on image synthesis.NeurIPS, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis.NeurIPS, 2021. 3
work page 2021
-
[19]
Ricard Durall, Margret Keuper, and Janis Keuper. Watch your up-convolution: CNN based generative deep neural networks are failing to reproduce spectral distributions. In CVPR, 2020. 2
work page 2020
-
[20]
Fourier spectrum discrepancies in deep network generated images
Tarik Dzanic, Karan Shah, and Freddie Witherden. Fourier spectrum discrepancies in deep network generated images. InNeurIPS, 2020. 2
work page 2020
-
[21]
Lighting (in)consistency of paint by text.arXiv Preprint, 2022
Hany Farid. Lighting (in)consistency of paint by text.arXiv Preprint, 2022. 2
work page 2022
-
[22]
Perspective (in)consistency of paint by text
Hany Farid. Perspective (in)consistency of paint by text. arXiv Preprint, 2022. 2
work page 2022
-
[23]
Federal Bureau of Investigation. Criminals use generative artificial intelligence to facilitate financial fraud.https: //www.ic3.gov/PSA/2024/PSA241203, 2024. 1
work page 2024
-
[24]
Leveraging fre- quency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Sch ¨onherr, Asja Fis- cher, Dorothea Kolossa, and Thorsten Holz. Leveraging fre- quency analysis for deep fake image recognition. InICML,
-
[25]
A representative study on human detection of artificially generated media across countries
Joel Frank, Franziska Herbert, Jonas Ricker, Lea Sch ¨onherr, Thorsten Eisenhofer, Asja Fischer, Markus D ¨urmuth, and Thorsten Holz. A representative study on human detection of artificially generated media across countries. InIEEE Sym- posium on Security and Privacy (S&P), 2024. 1
work page 2024
-
[26]
Towards discovery and attribution of open-world GAN generated images
Sharath Girish, Saksham Suri, Sai Saketh Rambhatla, and Abhinav Shrivastava. Towards discovery and attribution of open-world GAN generated images. InICCV, 2021. 3
work page 2021
-
[27]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InNeurIPS,
-
[28]
D. Gragnaniello, D. Cozzolino, F. Marra, G. Poggi, and L. Verdoliva. Are GAN generated images easy to detect? A critical analysis of the state-of-the-art. InICME, 2021. 2
work page 2021
-
[29]
A bias-free training paradigm for more general AI-generated image de- tection
Fabrizio Guillaro, Giada Zingarini, Ben Usman, Avneesh Sud, Davide Cozzolino, and Luisa Verdoliva. A bias-free training paradigm for more general AI-generated image de- tection. InCVPR, 2025. 2
work page 2025
-
[30]
Eyes tell all: Irregular pupil shapes reveal GAN- generated faces
Hui Guo, Shu Hu, Xin Wang, Ming-Ching Chang, and Si- wei Lyu. Eyes tell all: Irregular pupil shapes reveal GAN- generated faces. InICASSP, 2022. 2
work page 2022
-
[31]
Infinity: Scaling bit- wise autoregressive modeling for high-resolution image syn- thesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bit- wise autoregressive modeling for high-resolution image syn- thesis. InCVPR, 2025. 3, 4, 6, 1
work page 2025
-
[32]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR,
-
[33]
Zhiyuan He, Pin-Yu Chen, and Tsung-Yi Ho. RIGID: A training-free and model-agnostic framework for robust ai- generated image detection.arXiv Preprint, 2024. 2, 6, 1
work page 2024
-
[34]
Syou Hirofumi, Kazuto Fukuchi, Yohei Akimoto, and Jun Sakuma. Did you use my GAN to generate fake? Post-hoc 9 attribution of GAN generated images via latent recovery. In IJCNN, 2022. 3
work page 2022
-
[35]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. 3
work page 2021
-
[36]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 1
work page 2020
-
[37]
Tiffany Hsu and Steven Lee Myers. Can we no longer be- lieve anything we see?The New York Times, 2023.https: //www.nytimes.com/2023/04/08/business/ media/ai-generated-images.html. 1
work page 2023
-
[38]
Exposing GAN- Generated faces using inconsistent corneal specular high- lights
Shu Hu, Yuezun Li, and Siwei Lyu. Exposing GAN- Generated faces using inconsistent corneal specular high- lights. InICASSP, 2021. 2
work page 2021
-
[39]
Generalized image- based deepfake detection through foundation model adapta- tion
Tai-Ming Huang, Yue-Hua Han, Ernie Chu, Shu-Tzu Lo, Kai-Lung Hua, and Jun-Cheng Chen. Generalized image- based deepfake detection through foundation model adapta- tion. InICPR, 2025. 2
work page 2025
-
[40]
Leveraging rep- resentations from intermediate encoder-blocks for synthetic image detection
Christos Koutlis and Symeon Papadopoulos. Leveraging rep- resentations from intermediate encoder-blocks for synthetic image detection. InECCV, 2025. 2
work page 2025
-
[41]
Privacy attacks on image AutoRegressive models
Antoni Kowalczuk, Jan Dubi ´nski, Franziska Boenisch, and Adam Dziedzic. Privacy attacks on image AutoRegressive models. InICML, 2025. 1, 4, 8
work page 2025
-
[42]
HMAR: Efficient hierarchical masked autoregressive image generation
Hermann Kumbong, Xian Liu, Tsung-Yi Lin, Xihui Liu, Zi- wei Liu, Daniel Y Fu, Ming-Yu Liu, Christopher Re, and David W Romero. HMAR: Efficient hierarchical masked autoregressive image generation. InCVPR, 2025. 3, 6, 1
work page 2025
-
[43]
Single-model attribution of generative models through final-layer inversion
Mike Laszkiewicz, Jonas Ricker, Johannes Lederer, and Asja Fischer. Single-model attribution of generative models through final-layer inversion. InICML, 2024. 3
work page 2024
-
[44]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML,
-
[45]
Detecting generated images by real images
Bo Liu, Fan Yang, Xiuli Bi, Bin Xiao, Weisheng Li, and Xinbo Gao. Detecting generated images by real images. In ECCV, 2022. 2
work page 2022
-
[46]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 5
work page 2019
-
[47]
LaREˆ2: Latent reconstruction error based method for diffusion-generated image detection
Yunpeng Luo, Junlong Du, Ke Yan, and Shouhong Ding. LaREˆ2: Latent reconstruction error based method for diffusion-generated image detection. InCVPR, 2024. 2
work page 2024
-
[48]
Do GANs leave artificial fingerprints? In MIPR, 2019
Francesco Marra, Diego Gragnaniello, Luisa Verdoliva, and Giovanni Poggi. Do GANs leave artificial fingerprints? In MIPR, 2019. 3
work page 2019
-
[49]
Ex- ploiting visual artifacts to expose deepfakes and face manip- ulations
Falko Matern, Christian Riess, and Marc Stamminger. Ex- ploiting visual artifacts to expose deepfakes and face manip- ulations. InWACVW, 2019. 2
work page 2019
-
[50]
Detecting GAN- generated imagery using saturation cues
Scott McCloskey and Michael Albright. Detecting GAN- generated imagery using saturation cues. InICIP, 2019. 2
work page 2019
-
[51]
Do deep generative models know what they don’t know? InICLR, 2019
E Nalisnick, A Matsukawa, Y Teh, D Gorur, and B Laksh- minarayanan. Do deep generative models know what they don’t know? InICLR, 2019. 1
work page 2019
-
[52]
Lakshmanan Nataraj, Tajuddin Manhar Mohammed, B. S. Manjunath, Shivkumar Chandrasekaran, Arjuna Flenner, Jawadul H. Bappy, and Amit K. Roy-Chowdhury. Detecting GAN generated fake images using co-occurrence matrices. Electronic Imaging, 2019. 2
work page 2019
-
[53]
Towards uni- versal fake image detectors that generalize across generative models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards uni- versal fake image detectors that generalize across generative models. InCVPR, 2023. 2
work page 2023
-
[54]
The creativity of text-to-image gener- ation
Jonas Oppenlaender. The creativity of text-to-image gener- ation. InProceedings of the 25th International Academic Mindtrek Conference, 2022. 1
work page 2022
-
[55]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021. 3
work page 2021
-
[56]
On the effectiveness of dataset alignment for fake image detection
Anirudh Sundara Rajan, Utkarsh Ojha, Jedidiah Schloesser, and Yong Jae Lee. On the effectiveness of dataset alignment for fake image detection. InICLR, 2025. 2
work page 2025
-
[57]
Hierarchical text-conditional image gener- ation with CLIP latents.arXiv Preprint, 2022
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with CLIP latents.arXiv Preprint, 2022. 1
work page 2022
-
[58]
Likelihood ratios for out-of-distribution detec- tion.NeurIPS, 2019
Jie Ren, Peter J Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark Depristo, Joshua Dillon, and Balaji Lakshmi- narayanan. Likelihood ratios for out-of-distribution detec- tion.NeurIPS, 2019. 1
work page 2019
-
[59]
Towards the detection of diffusion model deepfakes
Jonas Ricker, Simon Damm, Thorsten Holz, and Asja Fis- cher. Towards the detection of diffusion model deepfakes. In VISIGRAPP, 2024. 2
work page 2024
-
[60]
Jonas Ricker, Denis Lukovnikov, and Asja Fischer. AER- OBLADE: Training-free detection of latent diffusion images using autoencoder reconstruction error. InCVPR, 2024. 2, 6
work page 2024
-
[61]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 1
work page 2022
-
[62]
Tate Ryan-Mosley. How generative AI is boosting the spread of disinformation and propaganda.MIT Technology Re- view, 2023.https : / / www . technologyreview . com / 2023 / 10 / 04 / 1080801 / generative - ai - boosting- disinformation- and- propaganda- freedom-house/. 1
work page 2023
-
[63]
Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022. 1
work page 2022
-
[64]
Ayush Sarkar, Hanlin Mai, Amitabh Mahapatra, Svetlana Lazebnik, D. A. Forsyth, and Anand Bhattad. Shadows don’t lie and lines can’t bend! Generative models don’t know pro- jective geometry...for now. InCVPR, 2024. 2
work page 2024
-
[65]
DE- FAKE: Detection and attribution of fake images generated by text-to-image generation models
Zeyang Sha, Zheng Li, Ning Yu, and Yang Zhang. DE- FAKE: Detection and attribution of fake images generated by text-to-image generation models. InCCS, 2023. 2
work page 2023
-
[66]
Detecting pretraining data from large language mod- els
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettle- moyer. Detecting pretraining data from large language mod- els. InICLR, 2024. 4 10
work page 2024
-
[67]
Generative modeling by es- timating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by es- timating gradients of the data distribution. InNeurIPS, 2019. 1
work page 2019
-
[68]
Autoregressive model beats diffusion: Llama for scalable image generation.arXiv Preprint, 2024
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv Preprint, 2024. 1, 3, 6
work page 2024
-
[69]
Diangarti Tariang, Riccardo Corvi, Davide Cozzolino, Gio- vanni Poggi, Koki Nagano, and Luisa Verdoliva. Synthetic image verification in the era of generative artificial intelli- gence: What works and what isn’t there yet.IEEE Security & Privacy, 2024. 2
work page 2024
-
[70]
Visual autoregressive modeling: Scalable image generation via next-scale prediction
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Li- wei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction. InNeurIPS, 2024. 1, 3, 4, 6
work page 2024
-
[71]
Pixel recurrent neural networks
A ¨aron van den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. InICML,
-
[72]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InNeurIPS, 2017. 3
work page 2017
-
[73]
Switti: Design- ing scale-wise transformers for text-to-image synthesis
Anton V oronov, Denis Kuznedelev, Mikhail Khoroshikh, Valentin Khrulkov, and Dmitry Baranchuk. Switti: Design- ing scale-wise transformers for text-to-image synthesis. In CVPR, 2025. 3, 6, 1
work page 2025
-
[74]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. CNN-generated images are surprisingly easy to spot... for now. InCVPR, 2020. 2
work page 2020
-
[75]
DIRE for diffusion-generated image detection
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. DIRE for diffusion-generated image detection. InICCV, 2023. 2
work page 2023
-
[76]
Where did I come from? Origin attribution of AI-generated images.NeurIPS, 2023
Zhenting Wang, Chen Chen, Yi Zeng, Lingjuan Lyu, and Shiqing Ma. Where did I come from? Origin attribution of AI-generated images.NeurIPS, 2023. 3
work page 2023
-
[77]
Zhenting Wang, Vikash Sehwag, Chen Chen, Lingjuan Lyu, Dimitris N. Metaxas, and Shiqing Ma. How to trace latent generative model generated images without artificial water- mark? InICML, 2024. 3
work page 2024
-
[78]
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and Ping Luo. Janus: Decoupling visual encoding for unified multimodal understanding and genera- tion.arXiv Preprint, 2024. 3
work page 2024
-
[79]
Learning to disentangle GAN fingerprint for fake image attribution.arXiv Preprint, 2021
Tianyun Yang, Juan Cao, Qiang Sheng, Lei Li, Jiaqi Ji, Xirong Li, and Sheng Tang. Learning to disentangle GAN fingerprint for fake image attribution.arXiv Preprint, 2021. 3
work page 2021
-
[80]
Icas: Detecting training data from autoregressive image gen- erative models
Hongyao Yu, Yixiang Qiu, Yiheng Yang, Hao Fang, Tianqu Zhuang, Jiaxin Hong, Bin Chen, Hao Wu, and Shu-Tao Xia. Icas: Detecting training data from autoregressive image gen- erative models. InACM MM, 2025. 1, 4, 8, 7
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.