V²-SAM: Marrying SAM2 with Multi-Prompt Experts for Cross-View Object Correspondence
Pith reviewed 2026-05-17 04:04 UTC · model grok-4.3
The pith
V2-SAM adapts SAM2 for cross-view object correspondence by combining two prompt generators with a cyclic consistency selector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that SAM2 can be repurposed for cross-view object correspondence by feeding it outputs from a Cross-View Anchor Prompt Generator that supplies geometry-aware, coordinate-based prompts from DINOv3 features and a Cross-View Visual Prompt Generator that supplies appearance-aligned prompts, then routing the pair through a multi-expert setup whose Post-hoc Cyclic Consistency Selector chooses the more reliable result.
What carries the argument
The Post-hoc Cyclic Consistency Selector (PCCS), which chooses between the two prompt experts by verifying that a predicted correspondence remains consistent when checked in the reverse view direction.
If this is right
- The framework sets new state-of-the-art numbers on the Ego-Exo4D benchmark for ego-exo object correspondence.
- The same pipeline improves results on the DAVIS-2017 video object tracking benchmark.
- The method also reaches leading performance on the HANDAL-X robotic cross-view correspondence benchmark.
- Coordinate-based prompting becomes usable inside SAM2 for the first time in cross-view settings.
Where Pith is reading between the lines
- The cyclic selector could be tested as a plug-in module on other prompt-driven models to improve reliability when multiple cue sources are available.
- The geometry-plus-appearance prompt pairing may transfer to multi-camera setups in autonomous driving or surveillance without viewpoint-specific retraining.
- Cyclic consistency checks might serve as a lightweight way to rank outputs from any pair of correspondence methods before final fusion.
Load-bearing premise
The two prompt generators produce reliable cues despite large viewpoint and appearance changes, and cyclic consistency selects the better expert without introducing bias.
What would settle it
Removing the cyclic consistency selector and observing no performance drop or a performance increase on the Ego-Exo4D ego-exo correspondence benchmark would indicate that the selector is not performing the claimed adaptive selection.
Figures












read the original abstract
Cross-view object correspondence, exemplified by the representative task of ego-exo object correspondence, aims to establish consistent associations of the same object across different viewpoints (e.g., egocentric and exocentric). This task poses significant challenges due to drastic viewpoint and appearance variations, making existing segmentation models, such as SAM2, difficult to apply directly. To address this, we present V2-SAM, a unified cross-view object correspondence framework that adapts SAM2 from single-view segmentation to cross-view correspondence through two complementary prompt generators. Specifically, the Cross-View Anchor Prompt Generator (V2-Anchor), built upon DINOv3 features, establishes geometry-aware correspondences and, for the first time, enables coordinate-based prompting for SAM2 in cross-view scenarios, while the Cross-View Visual Prompt Generator (V2-Visual) enhances appearance-guided cues via a novel visual prompt matcher that aligns ego-exo representations from both feature and structural perspectives. To effectively exploit the strengths of both prompts, we further adopt a multi-expert design and introduce a Post-hoc Cyclic Consistency Selector (PCCS) that adaptively selects the most reliable expert based on cyclic consistency. Extensive experiments validate the effectiveness of V2-SAM, achieving new state-of-the-art performance on Ego-Exo4D (ego-exo object correspondence), DAVIS-2017 (video object tracking), and HANDAL-X (robotic-ready cross-view correspondence).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes V²-SAM, a unified framework adapting SAM2 from single-view segmentation to cross-view object correspondence. It introduces two complementary prompt generators: the Cross-View Anchor Prompt Generator (V2-Anchor) built on DINOv3 features for geometry-aware correspondences and coordinate-based prompting, and the Cross-View Visual Prompt Generator (V2-Visual) that aligns ego-exo representations via a novel visual prompt matcher from feature and structural perspectives. A multi-expert design is used together with the Post-hoc Cyclic Consistency Selector (PCCS) to adaptively choose the most reliable expert. The work claims new state-of-the-art performance on Ego-Exo4D (ego-exo object correspondence), DAVIS-2017 (video object tracking), and HANDAL-X (robotic-ready cross-view correspondence).
Significance. If the empirical results hold, the contribution would be significant for extending foundation models such as SAM2 and DINOv3 to cross-view settings that involve large viewpoint and appearance changes. The multi-prompt expert architecture combined with cyclic-consistency selection offers a practical mechanism for exploiting complementary cues, which could benefit downstream tasks in egocentric vision, robotics, and multi-camera tracking. The explicit coordinate prompting enabled by V2-Anchor is a distinctive technical step that may generalize beyond the reported benchmarks.
major comments (1)
- Abstract: The central claim that 'extensive experiments validate the effectiveness of V2-SAM, achieving new state-of-the-art performance on Ego-Exo4D, DAVIS-2017, and HANDAL-X' is load-bearing for the paper's contribution, yet the abstract supplies no information on experimental protocols, baselines, metrics, ablations, statistical significance, or data splits. Without these details it is impossible to determine whether the reported gains are attributable to V2-Anchor, V2-Visual, or PCCS.
minor comments (2)
- Abstract: The title employs the notation V$^{2}$-SAM while the body text uses V2-SAM; a single consistent notation should be adopted throughout.
- Abstract: The phrase 'for the first time' regarding coordinate-based prompting for SAM2 in cross-view scenarios would benefit from a brief supporting reference or clarification once the full manuscript is available.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and will revise the abstract accordingly to improve informativeness while preserving conciseness.
read point-by-point responses
-
Referee: [—] Abstract: The central claim that 'extensive experiments validate the effectiveness of V2-SAM, achieving new state-of-the-art performance on Ego-Exo4D, DAVIS-2017, and HANDAL-X' is load-bearing for the paper's contribution, yet the abstract supplies no information on experimental protocols, baselines, metrics, ablations, statistical significance, or data splits. Without these details it is impossible to determine whether the reported gains are attributable to V2-Anchor, V2-Visual, or PCCS.
Authors: We agree that the abstract could better contextualize the experimental claims. While full protocols, data splits (standard train/val/test partitions for each benchmark), metrics (J&F for DAVIS-2017, correspondence accuracy and mIoU for Ego-Exo4D and HANDAL-X), baselines (SAM2 variants, prior cross-view methods, and recent foundation-model adaptations), and component ablations appear in Section 4, we will revise the abstract to add a concise clause noting the primary metrics, that results are compared against strong baselines, and that ablations isolate the contributions of V2-Anchor, V2-Visual, and PCCS. Statistical significance is supported by consistent gains and reported variance across runs in the experiments section. This targeted expansion directly addresses the referee's concern. revision: yes
Circularity Check
No significant circularity; derivation self-contained on external foundations
full rationale
Only the abstract is available, which outlines a high-level framework adapting the external SAM2 model and DINOv3 features via newly introduced components (V2-Anchor for geometry-aware coordinate prompting, V2-Visual for appearance alignment, and PCCS for expert selection via cyclic consistency). No equations, training procedures, fitted parameters, or self-citations appear in the text. The central claims rest on algorithmic novelty built atop independent prior models rather than reducing to self-definition, renamed inputs, or load-bearing self-references. This is the most common honest non-finding for abstracts lacking internal derivations.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
EgoSound: Benchmarking Sound Understanding in Egocentric Videos
EgoSound is a new benchmark with 7315 QA pairs across seven tasks to evaluate egocentric sound understanding in multimodal large language models.
Reference graph
Works this paper leans on
-
[1]
Self-supervised cross-view correspondence with predictive cycle consistency
Alan Baade and Changan Chen. Self-supervised cross-view correspondence with predictive cycle consistency. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 16753–16763, 2025. 2, 6, 7
work page 2025
-
[2]
Virefsam: Visual reference-guided segment anything model for remote sensing segmentation
Hanbo Bi, Yulong Xu, Ya Li, Yongqiang Mao, Boyuan Tong, Chongyang Li, Chunbo Lang, Wenhui Diao, Hongqi Wang, Yingchao Feng, et al. Virefsam: Visual reference-guided segment anything model for remote sensing segmentation. arXiv preprint arXiv:2507.02294, 2025. 2, 3
-
[3]
Walter R. Boot, Daniel P. Blakely, and Daniel J. Simons. Do action video games improve perception and cognition?Fron- tiers in Psychology, volume 2 - 2011, 2011. 1
work page 2011
-
[4]
Gnn-film: Graph neural networks with feature-wise linear modulation
Marc Brockschmidt. Gnn-film: Graph neural networks with feature-wise linear modulation. InInternational Conference on Machine Learning, pages 1144–1152. PMLR, 2020. 5
work page 2020
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, 2021. 6
work page 2021
-
[6]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022. 6
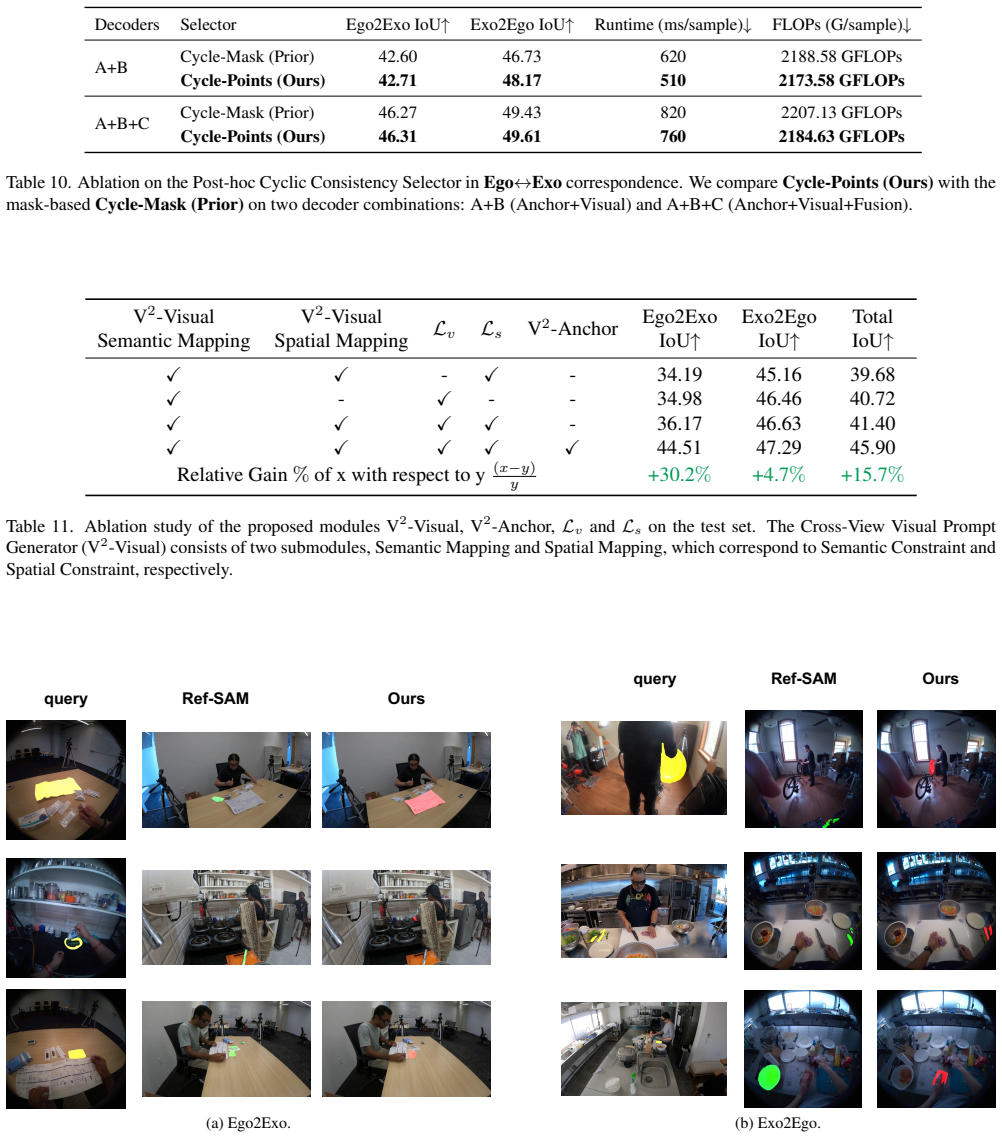
work page 2022
-
[7]
Vision transformers need registers, 2024
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers, 2024. 6
work page 2024
-
[8]
Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. A survey of embodied ai: From simulators to research tasks.IEEE Transactions on Emerging Topics in Computational Intelligence, 6(2):230–244, 2022. 1
work page 2022
-
[9]
Pmq-ve: Progressive multi-frame quantization for video enhancement,
ZhanFeng Feng, Long Peng, Xin Di, Yong Guo, Wenbo Li, Yulun Zhang, Renjing Pei, Yang Wang, Yang Cao, and Zheng-Jun Zha. Pmq-ve: Progressive multi-frame quantization for video enhancement.arXiv preprint arXiv:2505.12266, 2025. 1
-
[10]
Depth guided adaptive meta-fusion network for few- shot video recognition
Yuqian Fu, Li Zhang, Junke Wang, Yanwei Fu, and Yu-Gang Jiang. Depth guided adaptive meta-fusion network for few- shot video recognition. InProceedings of the 28th ACM international conference on multimedia, pages 1142–1151,
-
[11]
Yuqian Fu, Runze Wang, Yanwei Fu, Danda Pani Paudel, Xuanjing Huang, and Luc Van Gool. Objectrelator: Enabling cross-view object relation understanding in ego-centric and exo-centric videos.arXiv preprint arXiv:2411.19083, 2024. 1, 2, 6, 7
-
[12]
Cross-view multi-modal segmentation@ ego- exo4d challenges 2025.arXiv preprint arXiv:2506.05856,
Yuqian Fu, Runze Wang, Yanwei Fu, Danda Pani Paudel, and Luc Van Gool. Cross-view multi-modal segmentation@ ego- exo4d challenges 2025.arXiv preprint arXiv:2506.05856,
-
[13]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
work page 2024
-
[14]
Andrew Guo, Bowen Wen, Jianhe Yuan, Jonathan Tremblay, Stephen Tyree, Jeffrey Smith, and Stan Birchfield. Handal: A dataset of real-world manipulable object categories with pose annotations, affordances, and reconstructions. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11428–11435. IEEE, 2023. 6
work page 2023
-
[15]
Agrim Gupta, Jiajun Wu, Jia Deng, and Fei-Fei Li. Siamese masked autoencoders. InAdvances in Neural Information Processing Systems, pages 40676–40693. Curran Associates, Inc., 2023. 6
work page 2023
-
[16]
R. Hadsell, S. Chopra, and Y . LeCun. Dimensionality reduc- tion by learning an invariant mapping. In2006 IEEE Com- puter Society Conference on Computer Vision and Pattern Recognition (CVPR’06), pages 1735–1742, 2006. 5
work page 2006
-
[17]
Fastmoe: A fast mixture-of-expert train- ing system, 2021
Jiaao He, Jiezhong Qiu, Aohan Zeng, Zhilin Yang, Jidong Zhai, and Jie Tang. Fastmoe: A fast mixture-of-expert train- ing system, 2021. 2, 12
work page 2021
-
[18]
Robust ego-exo correspondence with long-term memory.arXiv preprint arXiv:2510.11417,
Yijun Hu, Bing Fan, Xin Gu, Haiqing Ren, Dongfang Liu, Heng Fan, and Libo Zhang. Robust ego-exo correspondence with long-term memory.arXiv preprint arXiv:2510.11417,
-
[19]
Multi-view pointnet for 3d scene understanding
Maximilian Jaritz, Jiayuan Gu, and Hao Su. Multi-view pointnet for 3d scene understanding. InProceedings of the IEEE/CVF international conference on computer vision workshops, pages 0–0, 2019. 1
work page 2019
-
[20]
Locate then segment: A strong pipeline for refer- ring image segmentation
Ya Jing, Tao Kong, Wei Wang, Liang Wang, Lei Li, and Tie- niu Tan. Locate then segment: A strong pipeline for refer- ring image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9858–9867, 2021. 2
work page 2021
-
[21]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 3
work page 2023
-
[22]
Kailing Li, Qi’ao Xu, Tianwen Qian, Yuqian Fu, Yang Jiao, and Xiaoling Wang. Clivis: Unleashing cognitive map through linguistic-visual synergy for embodied visual rea- soning.arXiv preprint arXiv:2506.17629, 2025. 1
-
[23]
Wenxin Li, Kunyu Peng, Di Wen, Ruiping Liu, Mengfei Duan, Kai Luo, and Kailun Yang. Segment-to-act: Label- noise-robust action-prompted video segmentation towards embodied intelligence.arXiv preprint arXiv:2509.16677,
-
[24]
Yuxuan Li, Xiang Li, Yunheng Li, Yicheng Zhang, Yimian Dai, Qibin Hou, Ming-Ming Cheng, and Jian Yang. Sm3det: A unified model for multi-modal remote sensing object de- tection.arXiv preprint arXiv:2412.20665, 2024. 13
-
[25]
Jitong Liao, Yulu Gao, Shaofei Huang, Jialin Gao, Jie Lei, Ronghua Liang, and Si Liu. Domr: Establishing cross- view segmentation via dense object matching.arXiv preprint arXiv:2508.04050, 2025. 1, 2
-
[26]
Wei Liu, Xiyan Fu, and Michael Strube. Modeling struc- tural similarities between documents for coherence assess- ment with graph convolutional networks.arXiv preprint arXiv:2306.06472, 2023. 4 9
-
[27]
Xianzhu Liu, Xin Sun, Haozhe Xie, Zonglin Li, Ru Li, and Shengping Zhang. Multi-view consistent 3d panoptic scene understanding.Proceedings of the AAAI Conference on Ar- tificial Intelligence, 39(6):5613–5621, 2025. 1
work page 2025
-
[28]
Yanxing Liu, Jiancheng Pan, Jianwei Yang, Tiancheng Chen, Peiling Zhou, and Bingchen Zhang. Diverse instance gen- eration via diffusion models for enhanced few-shot object detection in remote sensing images.IEEE Geoscience and Remote Sensing Letters, 2025. 12
work page 2025
-
[29]
Yanxing Liu, Jiancheng Pan, and Bingchen Zhang. Con- trol copy-paste: Controllable diffusion-based augmentation method for remote sensing few-shot object detection.arXiv preprint arXiv:2507.21816, 2025. 12
-
[30]
Qing Ma, Jiancheng Pan, and Cong Bai. Direction- oriented visual–semantic embedding model for remote sens- ing image–text retrieval.IEEE Transactions on Geoscience and Remote Sensing, 62:1–14, 2024. 13
work page 2024
-
[31]
Mohammad Mahdi, Yuqian Fu, Nedko Savov, Jiancheng Pan, Danda Pani Paudel, and Luc Van Gool. Exo2egosyn: Unlocking foundation video generation models for exocentric-to-egocentric video synthesis. 2025. 2
work page 2025
-
[32]
Cross-entropy loss functions: Theoretical analysis and applications
Anqi Mao, Mehryar Mohri, and Yutao Zhong. Cross-entropy loss functions: Theoretical analysis and applications. InIn- ternational conference on Machine learning, pages 23803– 23828. pmlr, 2023. 5
work page 2023
-
[33]
Wolfram Martens, Yannick Poffet, Pablo Ram ´on Soria, Robert Fitch, and Salah Sukkarieh. Geometric priors for gaussian process implicit surfaces.IEEE Robotics and Au- tomation Letters, 2(2):373–380, 2016. 5
work page 2016
-
[34]
V olumetric semantically consistent 3d panoptic mapping,
Yang Miao, Iro Armeni, Marc Pollefeys, and Daniel Barath. V olumetric semantically consistent 3d panoptic mapping,
-
[35]
Scene- graphloc: Cross-modal coarse visual localization on 3d scene graphs, 2024
Yang Miao, Francis Engelmann, Olga Vysotska, Federico Tombari, Marc Pollefeys, and D ´aniel B ´ela Bar ´ath. Scene- graphloc: Cross-modal coarse visual localization on 3d scene graphs, 2024. 1
work page 2024
-
[36]
Langhops: Lan- guage grounded hierarchical open-vocabulary part segmen- tation, 2025
Yang Miao, Jan-Nico Zaech, Xi Wang, Fabien Despinoy, Danda Pani Paudel, and Luc Van Gool. Langhops: Lan- guage grounded hierarchical open-vocabulary part segmen- tation, 2025. 3
work page 2025
-
[37]
O-mama: Learning object mask matching between egocentric and exocentric views
Lorenzo Mur-Labadia, Maria Santos-Villafranca, Jesus Bermudez-Cameo, Alejandro Perez-Yus, Ruben Martinez- Cantin, and Jose J Guerrero. O-mama: Learning object mask matching between egocentric and exocentric views. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6892–6903, 2025. 1, 2, 6, 7
work page 2025
-
[38]
A prior instruc- tion representation framework for remote sensing image-text retrieval
Jiancheng Pan, Qing Ma, and Cong Bai. A prior instruc- tion representation framework for remote sensing image-text retrieval. InProceedings of the 31st ACM International Con- ference on Multimedia, pages 611–620, 2023. 5
work page 2023
-
[39]
Jiancheng Pan, Qing Ma, and Cong Bai. Reducing seman- tic confusion: Scene-aware aggregation network for remote sensing cross-modal retrieval. InProceedings of the 2023 ACM International Conference on Multimedia Retrieval, pages 398–406, 2023. 13
work page 2023
-
[40]
Jiancheng Pan, Muyuan Ma, Qing Ma, Cong Bai, and Shengyong Chen. Pir: Remote sensing image-text retrieval with prior instruction representation learning.arXiv preprint arXiv:2405.10160, 2024. 5
-
[41]
Locate anything on earth: Advancing open-vocabulary ob- ject detection for remote sensing community
Jiancheng Pan, Yanxing Liu, Yuqian Fu, Muyuan Ma, Jiahao Li, Danda Pani Paudel, Luc Van Gool, and Xiaomeng Huang. Locate anything on earth: Advancing open-vocabulary ob- ject detection for remote sensing community. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 6281–6289, 2025. 13
work page 2025
-
[42]
Jiancheng Pan, Yanxing Liu, Xiao He, Long Peng, Jiahao Li, Yuze Sun, and Xiaomeng Huang. Enhance then search: An augmentation-search strategy with foundation models for cross-domain few-shot object detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1548–1556, 2025. 12
work page 2025
-
[43]
Referring atomic video ac- tion recognition
Kunyu Peng, Jia Fu, Kailun Yang, Di Wen, Yufan Chen, Ruiping Liu, Junwei Zheng, Jiaming Zhang, M Saquib Sar- fraz, Rainer Stiefelhagen, et al. Referring atomic video ac- tion recognition. InECCV, 2024. 1
work page 2024
-
[44]
Towards video-based acti- vated muscle group estimation in the wild
Kunyu Peng, David Schneider, Alina Roitberg, Kailun Yang, Jiaming Zhang, Chen Deng, Kaiyu Zhang, M Saquib Sar- fraz, and Rainer Stiefelhagen. Towards video-based acti- vated muscle group estimation in the wild. InACM Multi- media, 2024. 1
work page 2024
-
[45]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Sam 2: Segment anything in images and videos,
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos,
-
[47]
Kosuke Sakurai, Ryotaro Shimizu, and Masayuki Goto. Vi- sion and language reference prompt into sam for few-shot segmentation.arXiv preprint arXiv:2502.00719, 2025. 3
-
[48]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. 1
work page 2019
-
[49]
Generalised dice overlap as a deep learning loss function for highly unbalanced seg- mentations
Carole H Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M Jorge Cardoso. Generalised dice overlap as a deep learning loss function for highly unbalanced seg- mentations. InInternational Workshop on Deep Learning in Medical Image Analysis, pages 240–248. Springer, 2017. 5
work page 2017
-
[50]
Vrp-sam: Sam with visual reference prompt
Yanpeng Sun, Jiahui Chen, Shan Zhang, Xinyu Zhang, Qiang Chen, Gang Zhang, Errui Ding, Jingdong Wang, and Zechao Li. Vrp-sam: Sam with visual reference prompt. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 23565–23574, 2024. 2, 3
work page 2024
-
[51]
What you have is what 10 you track: Adaptive and robust multimodal tracking
Yuedong Tan, Jiawei Shao, Eduard Zamfir, Ruanjun Li, Zhaochong An, Chao Ma, Danda Paudel, Luc Van Gool, Radu Timofte, and Zongwei Wu. What you have is what 10 you track: Adaptive and robust multimodal tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3455–3465, 2025. 12
work page 2025
-
[52]
Xtrack: Multimodal train- ing boosts rgb-x video object trackers
Yuedong Tan, Zongwei Wu, Yuqian Fu, Zhuyun Zhou, Guolei Sun, Eduard Zamfir, Chao Ma, Danda Paudel, Luc Van Gool, and Radu Timofte. Xtrack: Multimodal train- ing boosts rgb-x video object trackers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5734–5744, 2025. 13
work page 2025
-
[53]
Anirudh Thatipelli, Shao-Yuan Lo, and Amit K Roy- Chowdhury. Egocentric and exocentric methods: A short survey.Computer Vision and Image Understanding, page 104371, 2025. 2
work page 2025
-
[54]
Probabilistic warp consistency for weakly- supervised semantic correspondences
Prune Truong, Martin Danelljan, Fisher Yu, and Luc Van Gool. Probabilistic warp consistency for weakly- supervised semantic correspondences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8708–8718, 2022. 6
work page 2022
-
[55]
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Yujin Han, Zhekai Chen, Jiayu Wang, Difan Zou, Xihui Liu, Yingya Zhang, Yu Liu, et al. Routing matters in moe: Scaling diffusion transformers with explicit routing guidance.arXiv preprint arXiv:2510.24711, 2025. 13
-
[56]
Croco v2: Improved cross-view completion pre- training for stereo matching and optical flow
Philippe Weinzaepfel, Thomas Lucas, Vincent Leroy, Yohann Cabon, Vaibhav Arora, Romain Br ´egier, Gabriela Csurka, Leonid Antsfeld, Boris Chidlovskii, and Jerome Revaud. Croco v2: Improved cross-view completion pre- training for stereo matching and optical flow. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 1796...
work page 2023
-
[57]
Deep geomet- ric prior for surface reconstruction
Francis Williams, Teseo Schneider, Claudio Silva, Denis Zorin, Joan Bruna, and Daniele Panozzo. Deep geomet- ric prior for surface reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10130–10139, 2019. 5
work page 2019
-
[58]
Timeexpert: An expert-guided video llm for video temporal grounding
Zuhao Yang, Yingchen Yu, Yunqing Zhao, Shijian Lu, and Song Bai. Timeexpert: An expert-guided video llm for video temporal grounding. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 24286–24296, 2025. 12
work page 2025
-
[59]
Inst3d-lmm: Instance-aware 3d scene under- standing with multi-modal instruction tuning
Hanxun Yu, Wentong Li, Song Wang, Junbo Chen, and Jianke Zhu. Inst3d-lmm: Instance-aware 3d scene under- standing with multi-modal instruction tuning. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 14147–14157, 2025. 1
work page 2025
-
[60]
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, and Ming-Hsuan Yang. Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos.arXiv preprint arXiv:2501.04001, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Seniha Esen Yuksel, Joseph N. Wilson, and Paul D. Gader. Twenty years of mixture of experts.IEEE Transactions on Neural Networks and Learning Systems, 23(8):1177–1193,
-
[62]
Egonight: Towards egocentric vision understanding at night with a challenging benchmark
Deheng Zhang, Yuqian Fu, Runyi Yang, Yang Miao, Tian- wen Qian, Xu Zheng, Guolei Sun, Ajad Chhatkuli, Xuanjing Huang, Yu-Gang Jiang, et al. Egonight: Towards egocentric vision understanding at night with a challenging benchmark. arXiv preprint arXiv:2510.06218, 2025. 1
-
[63]
Jiaming Zhang, Huayao Liu, Kailun Yang, Xinxin Hu, Ruip- ing Liu, and Rainer Stiefelhagen. Cmx: Cross-modal fusion for rgb-x semantic segmentation with transformers.IEEE Transactions on intelligent transportation systems, 24(12): 14679–14694, 2023. 6
work page 2023
-
[64]
Shulian Zhang, Yong Guo, Long Peng, Ziyang Wang, Ye Chen, Wenbo Li, Xiao Zhang, Yulun Zhang, and Jian Chen. Vividface: High-quality and efficient one-step diffusion for video face enhancement.arXiv preprint arXiv:2509.23584,
-
[65]
Psalm: Pixelwise segmentation with large multi-modal model
Zheng Zhang, Yeyao Ma, Enming Zhang, and Xiang Bai. Psalm: Pixelwise segmentation with large multi-modal model. InEuropean Conference on Computer Vision, pages 74–91. Springer, 2024. 6
work page 2024
-
[66]
Psalm: Pixelwise segmentation with large multi-modal model, 2024
Zheng Zhang, Yeyao Ma, Enming Zhang, and Xiang Bai. Psalm: Pixelwise segmentation with large multi-modal model, 2024. 6
work page 2024
-
[67]
Yijie Zheng, Weijie Wu, Qingyun Li, Xuehui Wang, Xu Zhou, Aiai Ren, Jun Shen, Long Zhao, Guoqing Li, and Xue Yang. Instructsam: A training-free framework for instruction-oriented remote sensing object recognition.arXiv preprint arXiv:2505.15818, 2025. 12
-
[68]
Nan Zhou, Ke Zou, Kai Ren, Mengting Luo, Linchao He, Meng Wang, Yidi Chen, Yi Zhang, Hu Chen, and Huazhu Fu. Medsam-u: Uncertainty-guided auto multi-prompt adap- tation for reliable medsam.IEEE Transactions on Circuits and Systems for Video Technology, 2025. 12
work page 2025
-
[69]
Mixture-of-experts with expert choice routing
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, zhifeng Chen, Quoc V Le, and James Laudon. Mixture-of-experts with expert choice routing. InAdvances in Neural Information Processing Sys- tems, pages 7103–7114. Curran Associates, Inc., 2022. 2
work page 2022
-
[70]
Chenyang Zhu, Bin Xiao, Lin Shi, Shoukun Xu, and Xu Zheng. Customize segment anything model for multi-modal semantic segmentation with mixture of lora experts.arXiv preprint arXiv:2412.04220, 2024. 12
-
[71]
Segment everything everywhere all at once
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. InAd- vances in Neural Information Processing Systems, pages 19769–19782. Curran Associates, Inc., 2023. 6 11 V2-SAM: Marrying SAM2 with Multi-Prompt Experts for Cross-View Object Correspondence Su...
work page 2023
-
[72]
More Related Work 12 1.1. Segment Anything Model . . . . . . . . . . 12 1.2. Mixture-of-Experts in Vision . . . . . . . . . 12
-
[73]
Challenges in Cross-View Object Correspondence 13
-
[74]
More Implementation Details 13 3.1. Dataset Settings . . . . . . . . . . . . . . . 13 3.2. Training Hyperparameters . . . . . . . . . . 13 3.3. Model settings . . . . . . . . . . . . . . . . 14
-
[75]
More Experiments 14 4.1. Ablation on Submodule . . . . . . . . . . . 14 4.2. Ablation on V2-Anchor . . . . . . . . . . . 14 4.3. Ablation on the PCCS . . . . . . . . . . . . 14 4.4. More Visual Analytics. . . . . . . . . . . . . 15
-
[76]
More Related Work 1.1. Segment Anything Model The Segment Anything Model (SAM) is a prompt-driven foundation model for universal image localization [28, 29, 42] and segmentation, capable of producing high-quality masks from simple inputs like points or bounding boxes. It has inspired domain-specific extensions such as Med- SAM [68] for medical imaging, In...
-
[77]
aCross-View Visual Prompt Generator (V 2-Visual)that leverages object appearance cues and refines them through a learnable mapping between views; 3) aMulti-Expert Train- ingmechanism that jointly learns spatial, visual, and fused experts for complementary reasoning; and 4) aPost-hoc Cyclic Consistency Selector (PCCS)that adaptively selects the most reliab...
-
[78]
Challenges in Cross-View Object Corre- spondence Cross-view object correspondence in real-world environ- ments remains highly challenging due to substantial intra- scene variations and visual ambiguity across viewpoints, as shown in Fig. 7. First,cluttered sceneswith numerous over- lapping objects introduce significant distractors, making it difficult to ...
-
[79]
More Implementation Details 3.1. Dataset Settings Tab. 6 provides a quantitative overview of the datasets used in our experiments. Our primary supervision comes from Ego-Exo4D, where we leverage two directional splits: Ego2ExoandExo2Ego. Each direction includes both training and testing sets, totaling over 320K pairs and 1.5M masks across roughly 30 seman...
work page 2017
-
[80]
More Experiments 4.1. Ablation on Submodule Tab. 11 presents the ablation results of the proposed compo- nents, including the two submodules of V2-Visual (Seman- tic Mapping and Spatial Mapping), the associated lossesLv andL s, and the V 2-Anchor. Each component contributes positively to overall performance, while V 2-Anchor yields the greatest improvemen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.