Comparing SAM 2 and SAM 3 for Zero-Shot Segmentation of 3D Medical Data
Pith reviewed 2026-05-17 04:33 UTC · model grok-4.3
The pith
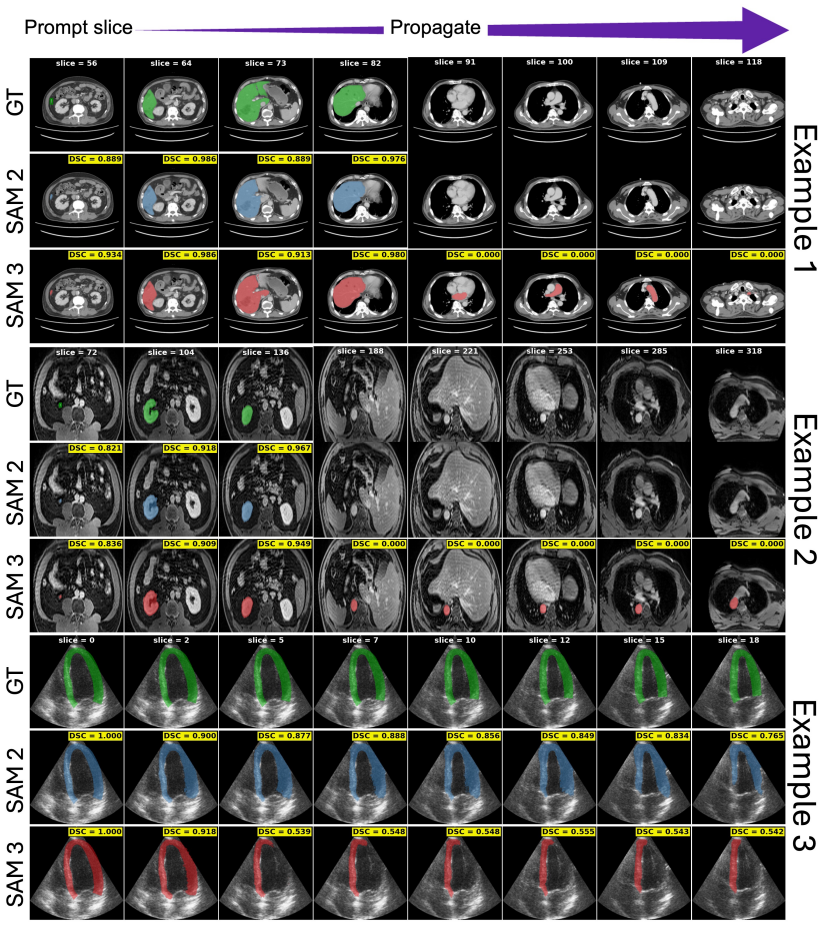
SAM 3 outperforms SAM 2 under click prompts and serves as the stronger default for zero-shot segmentation of 3D medical data across modalities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAM 3 is consistently stronger under click prompting across modalities, with fewer prompt-frame over-segmentation failures and slower prediction retention decay compared to SAM 2. Under bounding-box and mask prompts, performance gaps narrow in few structures of CT/MR and the models trade off termination behavior, while SAM 3 remains stronger on ultrasound and endoscopy sequences. The overall results position SAM 3 as the superior default choice for most medical segmentation tasks, while clarifying when SAM 2 remains a preferable propagator.
What carries the argument
A controlled benchmark of SAM 2 versus SAM 3 in Promptable Visual Segmentation (PVS) mode that measures performance and three defined failure modes on 16 public 3D medical datasets.
If this is right
- Medical annotation tools can default to SAM 3 when users supply click prompts to reduce over-segmentation errors.
- For bounding-box or mask prompts on CT and MR volumes, either model can be selected based on the desired balance of termination behavior.
- Ultrasound and endoscopy sequences gain the clearest benefit from switching to SAM 3.
- Annotation pipelines that rely on temporal propagation can expect slower decay of accurate predictions with SAM 3.
Where Pith is reading between the lines
- Wider clinical adoption of SAM 3 could shorten the time needed to produce 3D segmentations for diagnosis or surgical planning.
- The quantified failure modes point to specific directions for refining future promptable models in medical imaging.
- Direct comparison on private hospital data with real-time user interactions would test whether the public-dataset patterns hold in practice.
Load-bearing premise
The chosen prompting strategies, failure-mode definitions, and 16 public datasets sufficiently represent real clinical variability and user behavior in 3D medical workflows.
What would settle it
A replication on additional clinical 3D datasets that uses natural user prompts and finds SAM 2 producing fewer failures or higher accuracy than SAM 3 across the same modalities.
Figures




read the original abstract
Foundation models, such as the Segment Anything Model (SAM), have heightened interest in promptable zero-shot segmentation. Although these models perform strongly on natural images, their behavior on medical data remains insufficiently characterized. While SAM 2 has been widely adopted for annotation in 3D medical workflows, the recently released SAM 3 introduces a new architecture that may change how visual prompts are interpreted and propagated. Therefore, to assess whether SAM 3 can serve as an out-of-the-box replacement for SAM 2 for zero-shot segmentation of 3D medical data, we present the first controlled comparison of both models by evaluating SAM 3 in its Promptable Visual Segmentation (PVS) mode using a variety of prompting strategies. We benchmark on 16 public datasets (CT, MRI, Ultrasound, endoscopy) covering 54 anatomical structures, pathologies, and surgical instruments. We further quantify three failure modes: prompt-frame over-segmentation, over-propagation after object disappearance, and temporal retention of well-initialized predictions. Our results show that SAM 3 is consistently stronger under click prompting across modalities, with fewer prompt-frame over-segmentation failures and slower prediction retention decay compared to SAM 2. Under bounding-box and mask prompts, performance gaps narrow in few structures of CT/MR and the models trade off termination behavior, while SAM 3 remains stronger on ultrasound and endoscopy sequences. The overall results position SAM 3 as the superior default choice for most medical segmentation tasks, while clarifying when SAM 2 remains a preferable propagator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first controlled empirical comparison of SAM 2 and SAM 3 for promptable zero-shot segmentation of 3D medical data. It evaluates both models across 16 public datasets (CT, MRI, ultrasound, endoscopy) covering 54 anatomical structures, pathologies, and instruments, using click, bounding-box, and mask prompts. Performance is assessed alongside three quantified failure modes (prompt-frame over-segmentation, over-propagation after disappearance, and temporal retention), leading to the conclusion that SAM 3 is the stronger default choice for most tasks while identifying limited cases where SAM 2 may be preferable as a propagator.
Significance. If the empirical results hold, the work supplies timely, practical guidance for practitioners selecting foundation models in medical annotation pipelines. Its strengths include systematic coverage of four modalities and 54 structures on external public data with no fitted parameters or self-referential derivations, plus explicit quantification of failure modes that go beyond aggregate metrics. This positions the paper as a useful reference for zero-shot medical segmentation workflows.
major comments (1)
- [Abstract and Results] Abstract and §Results: The central recommendation that SAM 3 should serve as the 'superior default choice for most medical segmentation tasks' is grounded in performance advantages observed on the 16 public datasets. However, the manuscript does not provide a concrete discussion or supplementary analysis of how these datasets capture real clinical variability in acquisition parameters, image quality, anatomical diversity, and user prompting behavior. A direct test would be to add performance numbers on at least one additional dataset containing documented clinical artifacts (e.g., motion or low-contrast) and report whether the SAM 3 advantage persists.
minor comments (2)
- [Methods] Methods: Exact definitions of the quantitative metrics (Dice, failure rates) and the precise implementation of the three prompting strategies (including prompt placement rules and propagation parameters) are not fully specified in the provided text; adding these details would improve reproducibility.
- [Results] Tables/Figures: The manuscript would benefit from a summary table that directly contrasts the three failure-mode rates for SAM 2 versus SAM 3 across modalities rather than distributing the numbers across multiple figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address the major comment below with a point-by-point response.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and §Results: The central recommendation that SAM 3 should serve as the 'superior default choice for most medical segmentation tasks' is grounded in performance advantages observed on the 16 public datasets. However, the manuscript does not provide a concrete discussion or supplementary analysis of how these datasets capture real clinical variability in acquisition parameters, image quality, anatomical diversity, and user prompting behavior. A direct test would be to add performance numbers on at least one additional dataset containing documented clinical artifacts (e.g., motion or low-contrast) and report whether the SAM 3 advantage persists.
Authors: We appreciate the referee highlighting the need for greater transparency on dataset representativeness. The 16 public datasets were deliberately chosen to span four modalities (CT, MRI, ultrasound, endoscopy) and 54 structures drawn from multiple institutions and scanners, thereby incorporating natural variations in acquisition parameters, contrast, resolution, and anatomical presentation. Our evaluation further includes three distinct prompt types (click, bounding-box, mask) that reflect different user interaction styles. We acknowledge, however, that the manuscript does not explicitly quantify performance under extreme clinical artifacts such as motion blur or severe low-contrast cases. Adding an entirely new dataset and re-running all experiments would require substantial additional curation and compute that falls outside the scope of this controlled benchmark study on established public data. In the revised manuscript we will therefore (i) expand the Results and Discussion sections with a concrete paragraph describing the range of acquisition variability present in the 16 datasets and (ii) add an explicit Limitations subsection that notes the absence of targeted artifact-specific testing and flags it as future work. This revision clarifies the grounding of our recommendation without altering the core empirical contribution. revision: partial
Circularity Check
No circularity: pure empirical benchmarking on external datasets
full rationale
The paper conducts a controlled empirical comparison of SAM 2 and SAM 3 on 16 independent public datasets (CT, MRI, Ultrasound, endoscopy) covering 54 structures, using direct performance metrics and failure-mode counts under various prompting strategies. No derivations, equations, fitted parameters, or self-referential constructions appear; all claims rest on observed results from external benchmarks rather than any reduction to the paper's own inputs or prior author results. This is self-contained against external data with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Public benchmark datasets adequately represent clinical 3D medical imaging variability
Reference graph
Works this paper leans on
-
[1]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Loet al., “Segment anything,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4015–4026
work page 2023
-
[2]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V. Gabeur, Y.-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson et al., “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y.-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V. Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. Rädle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y. Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Dollár, N. Ravi, K. Saenko...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” inEuropean conference on computer vision. Springer, 2020, pp. 213–229
work page 2020
-
[5]
Is sam 2 better than sam in medical image segmentation?
S. Sengupta, S. Chakrabarty, and R. Soni, “Is sam 2 better than sam in medical image segmentation?” inMedical Imaging 2025: Image Processing, vol. 13406. SPIE, 2025, pp. 666–672
work page 2025
-
[6]
arXiv preprint arXiv:2408.00756 (2024)
H. Dong, H. Gu, Y. Chen, J. Yang, Y. Chen, and M. A. Mazurowski, “Segment anything model 2: an application to 2d and 3d medical images,”arXiv preprint arXiv:2408.00756, 2024
-
[7]
Segment anything in medical images and videos: Benchmark and deployment,
J. Ma, S. Kim, F. Li, M. Baharoon, R. Asakereh, H. Lyu, and B. Wang, “Segment anything in medical images and videos: Benchmark and deployment,”arXiv preprint arXiv:2408.03322, 2024
-
[8]
Hiera: A hierarchical vision transformer without the bells-and-whistles,
C. Ryali, Y.-T. Hu, D. Bolya, C. Wei, H. Fan, P.-Y. Huang, V. Aggarwal, A. Chowdhury, O. Pour- saeed, J. Hoffmanet al., “Hiera: A hierarchical vision transformer without the bells-and-whistles,” in International conference on machine learning. PMLR, 2023, pp. 29441–29454
work page 2023
-
[9]
Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation,
Y. Ji, H. Bai, C. Ge, J. Yang, Y. Zhu, R. Zhang, Z. Li, L. Zhanng, W. Ma, X. Wanet al., “Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation,”Advances in neural information processing systems, vol. 35, pp. 36722–36732, 2022
work page 2022
-
[10]
Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge,
B. Landman, Z. Xu, J. Igelsias, M. Styner, T. Langerak, and A. Klein, “Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge,” inProc. MICCAI multi-atlas labeling beyond cranial vault—workshop challenge, vol. 5. Munich, Germany, 2015, p. 12
work page 2015
-
[11]
J. Ma, Y. Zhang, S. Gu, C. Ge, S. Mae, A. Young, C. Zhu, X. Yang, K. Meng, Z. Huanget al., “Unleashing the strengths of unlabelled data in deep learning-assisted pan-cancer abdominal organ quantification: the flare22 challenge,”The Lancet Digital Health, vol. 6, no. 11, pp. e815–e826, 2024
work page 2024
-
[12]
The medical segmentation decathlon,
M. Antonelli, A. Reinke, S. Bakas, K. Farahani, A. Kopp-Schneider, B. A. Landman, G. Litjens, B. Menze, O. Ronneberger, R. M. Summerset al., “The medical segmentation decathlon,”Nature communications, vol. 13, no. 1, p. 4128, 2022
work page 2022
-
[13]
A. L. Simpson, M. Antonelli, S. Bakas, M. Bilello, K. Farahani, B. Van Ginneken, A. Kopp-Schneider, B. A. Landman, G. Litjens, B. Menzeet al., “A large annotated medical image dataset for the development and evaluation of segmentation algorithms,”arXiv preprint arXiv:1902.09063, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[14]
Totalsegmentator: robust segmentation of 104 anatomic structures in ct images,
J. Wasserthal, H.-C. Breit, M. T. Meyer, M. Pradella, D. Hinck, A. W. Sauter, T. Heye, D. T. Boll, J. Cyriac, S. Yanget al., “Totalsegmentator: robust segmentation of 104 anatomic structures in ct images,”Radiology: Artificial Intelligence, vol. 5, no. 5, 2023
work page 2023
-
[15]
O. Bernard, A. Lalande, C. Zotti, F. Cervenansky, X. Yang, P.-A. Heng, I. Cetin, K. Lekadir, O. Camara, M. A. G. Ballesteret al., “Deep learning techniques for automatic mri cardiac multi- structures segmentation and diagnosis: is the problem solved?”IEEE transactions on medical imaging, vol. 37, no. 11, pp. 2514–2525, 2018
work page 2018
-
[16]
T. A. D’Antonoli, L. K. Berger, A. K. Indrakanti, N. Vishwanathan, J. Weiß, M. Jung, Z. Berkarda, A. Rau, M. Reisert, T. Küstneret al., “Totalsegmentator mri: Sequence-independent segmentation of 59 anatomical structures in mr images,”arXiv preprint arXiv:2405.19492, 2024
-
[17]
Deep learning for segmentation using an open large-scale dataset in 2d echocardiog- raphy,
S. Leclercet al., “Deep learning for segmentation using an open large-scale dataset in 2d echocardiog- raphy,”IEEE transactions on medical imaging, vol. 38, no. 9, pp. 2198–2210, 2019
work page 2019
-
[18]
M. Krönke, C. Eilers, D. Dimova, M. Köhler, G. Buschner, L. Schweiger, L. Konstantinidou, M. Makowski, J. Nagarajah, N. Navabet al., “Tracked 3d ultrasound and deep neural network- based thyroid segmentation reduce interobserver variability in thyroid volumetry,”Plos one, vol. 17, no. 7, p. e0268550, 2022
work page 2022
-
[19]
Cholecseg8k: a semantic segmen- tation dataset for laparoscopic cholecystectomy based on cholec80
W.-Y. Hong, C.-L. Kao, Y.-H. Kuo, J.-R. Wang, W.-L. Chang, and C.-S. Shih, “Cholecseg8k: a semantic segmentation dataset for laparoscopic cholecystectomy based on cholec80,”arXiv preprint arXiv:2012.12453, 2020
-
[20]
Endonet: a deep architecture for recognition tasks on laparoscopic videos,
A. P. Twinanda, S. Shehata, D. Mutter, J. Marescaux, M. De Mathelin, and N. Padoy, “Endonet: a deep architecture for recognition tasks on laparoscopic videos,”IEEE transactions on medical imaging, vol. 36, no. 1, pp. 86–97, 2016
work page 2016
-
[21]
Data13, 10.1038/ s41597-025-06343-4 (2025)
M. Rokuss, M. Langenberg, Y. Kirchhoff, F. Isensee, B. Hamm, C. Ulrich, S. Regnery, L. Bauer, E. Katsigiannopulos, T. Norajitraet al., “Voxtell: Free-text promptable universal 3d medical image segmentation,”arXiv preprint arXiv:2511.11450, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.