Aquas: Enhancing Domain Specialization through Holistic Hardware-Software Co-Optimization based on MLIR
Pith reviewed 2026-05-17 05:04 UTC · model grok-4.3
The pith
Aquas offers a MLIR-based co-design framework that models memory interfaces with cache awareness and uses e-graph compilation to automate custom instruction offloading for RISC-V ASIPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
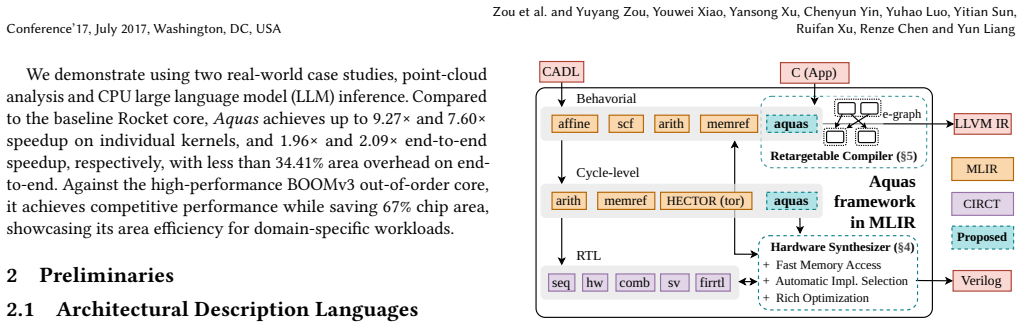
Aquas proposes a memory interface model that jointly considers interface characteristics and cache effects, along with an interface-aware synthesis flow that optimizes the input specification and generates efficient hardware. It also introduces an e-graph-based retargetable compiler with a novel matching engine for robust instruction mapping and offloading. Case studies in four domains demonstrate up to 15.61x speedup with 14.5 percent area overhead and zero frequency degradation, remaining competitive against stronger general-purpose cores and vector extensions.
What carries the argument
The memory interface model that accounts for both interface traits and cache effects, paired with an e-graph-based retargetable compiler featuring a novel matching engine for automated instruction offloading.
If this is right
- Memory access can be optimized progressively during synthesis rather than treated as an afterthought.
- Custom instructions with non-trivial control and memory behavior become viable for automated offloading.
- Domain accelerators achieve high speedups while using less area than more powerful general cores.
- The framework supports multiple diverse applications through a single retargetable compilation approach.
Where Pith is reading between the lines
- This style of co-optimization might shorten the iteration cycle between hardware generation and software adaptation in RISC-V ecosystems.
- If the matching engine proves robust, similar e-graph techniques could apply to other compiler targets beyond MLIR dialects.
- The low area overhead suggests the approach could scale to systems with multiple specialized extensions without compounding hardware costs.
Load-bearing premise
The memory interface model and e-graph compiler will generalize to new domains without needing extensive manual tuning or post-hoc fixes.
What would settle it
Applying Aquas to a fifth domain with highly irregular memory patterns and complex control logic, then measuring whether speedups remain above 5x without developer adjustments to the models or engine.
Figures


read the original abstract
Application-Specific Instruction-Set Processors (ASIPs) built on the RISC-V architecture offer specialization opportunities for various applications. Existing frameworks are largely designed around fixed instruction extension interfaces and rely on manual software adaptation. However, as emerging domains scale up in complexity, two major challenges arise. First, memory access remains a primary bottleneck as existing design flows lack architectural awareness of memory interfaces, leading to suboptimal interface selection and orchestration. Second, the semantic complexity of custom instruction extensions, characterized by non-trivial control logic and irregular memory behaviors, hinders the ability of conventional compilers to perform automated and comprehensive offloading. We present Aquas, a holistic hardware-software co-design framework built upon MLIR. Aquas proposes a memory interface model that jointly considers interface characteristics and cache effects, along with an interface-aware synthesis flow guided by this model that progressively optimizes the input specification and generates efficient hardware implementations. We also propose an e-graph-based retargetable compiler approach with a novel matching engine for efficient instruction mapping and offloading, enabling robust and effective utilization of custom instruction capabilities. Case studies across four diverse domains show that Aquas delivers substantial acceleration, achieving up to 15.61x speedup with 14.5% area overhead and zero frequency degradation, proving highly competitive in domain acceleration against more powerful general-purpose cores and vector extensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Aquas, an MLIR-based holistic hardware-software co-design framework for RISC-V ASIPs. It introduces a memory interface model that jointly accounts for interface characteristics and cache effects, an interface-aware synthesis flow for hardware generation, and an e-graph-based retargetable compiler with a novel matching engine for automated instruction offloading. Case studies in four domains report up to 15.61x speedup, 14.5% area overhead, and zero frequency degradation, claiming competitiveness versus general-purpose cores and vector extensions.
Significance. If the central performance claims are substantiated by detailed ablations and reproducible methodology, the work could advance automated domain specialization by unifying memory-aware synthesis with compiler retargeting in a single MLIR infrastructure. The e-graph matching approach for irregular custom instructions represents a technically interesting direction that could reduce manual effort in ASIP flows.
major comments (2)
- [Evaluation / Case Studies] Evaluation section (case studies): the headline results (up to 15.61x speedup, 14.5% area, zero frequency loss) are presented without ablations that isolate the contribution of the joint memory-interface/cache model versus the novel e-graph matcher, nor any count of manually added patterns per domain. This leaves open whether the reported gains derive from the automated co-optimization framework or from domain-specific manual tuning in the synthesis and matching rules.
- [Memory Interface Model] Memory interface model description: the claim that the model 'jointly considers interface characteristics and cache effects' is central to addressing the stated memory bottleneck, yet the manuscript provides no quantitative comparison against prior interface-only models or sensitivity analysis on cache-effect parameters, making it impossible to verify that the model itself drives the observed interface selection improvements.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction use 'zero frequency degradation' without specifying the synthesis tool, target process node, or timing constraints under which this holds; add a sentence clarifying the experimental setup.
- [Compiler Approach] Notation for the e-graph matching engine (e.g., cost functions or rewrite rules) is introduced without a compact summary table; a small table listing the novel matching heuristics would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [Evaluation / Case Studies] Evaluation section (case studies): the headline results (up to 15.61x speedup, 14.5% area, zero frequency loss) are presented without ablations that isolate the contribution of the joint memory-interface/cache model versus the novel e-graph matcher, nor any count of manually added patterns per domain. This leaves open whether the reported gains derive from the automated co-optimization framework or from domain-specific manual tuning in the synthesis and matching rules.
Authors: We agree that explicit ablations would strengthen the evaluation by isolating component contributions. In the revised manuscript we will add ablations that separately disable the joint memory-interface/cache model and the e-graph matcher to quantify their individual effects on the reported speedups. We will also include a table reporting the number of manually added patterns per domain; these are limited to a small set of domain-specific edge cases, as the majority of instruction patterns are automatically discovered and matched by the e-graph engine. revision: yes
-
Referee: [Memory Interface Model] Memory interface model description: the claim that the model 'jointly considers interface characteristics and cache effects' is central to addressing the stated memory bottleneck, yet the manuscript provides no quantitative comparison against prior interface-only models or sensitivity analysis on cache-effect parameters, making it impossible to verify that the model itself drives the observed interface selection improvements.
Authors: We acknowledge the value of direct quantitative validation. The revised version will include a new subsection with comparisons of the joint model against prior interface-only models on the same benchmarks, plus sensitivity analysis varying cache-effect parameters (e.g., hit rates and latency multipliers) to show their influence on interface selection and overall performance. revision: yes
Circularity Check
No significant circularity; framework and results are independent of each other.
full rationale
The paper describes a hardware-software co-design framework using MLIR, a memory interface model, and an e-graph retargetable compiler, then reports empirical speedups from case studies on four domains. No equations, fitted parameters, or self-citations are shown that would make the performance numbers reduce to the inputs by construction. The claimed acceleration is presented as an outcome of applying the described components rather than a tautological renaming or load-bearing self-reference. The derivation chain for the models and compiler remains self-contained against the external benchmarks of the evaluated domains.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Aquas proposes a memory interface model that jointly considers interface characteristics and cache effects, along with an interface-aware synthesis flow... e-graph-based retargetable compiler approach with a novel matching engine
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
up to 9.27× speedup... 34.41% area overhead
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AMD. 2025. AMD Vitis™HLS. https://www.amd.com/en/products/software/ adaptive-socs-and-fpgas/vitis/vitis-hls.html
work page 2025
-
[2]
Giorgos Armeniakos, Alexis Maras, Sotirios Xydis, and Dimitrios Soudris. 2025. Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi- Pumped Soft SIMD Operations. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. Association for Computing Machinery, New York, NY, USA, 1–9. https://doi.org/10.1145/367...
-
[3]
2016.The Rocket Chip Generator
Krste Asanović, Rimas Avižienis, and Jonathan Bachrach. 2016.The Rocket Chip Generator. Technical Report UCB/EECS-2016-17. Berkeley, CA. http: //www.eecs.berkeley.edu/Pubs/TechRpts/2016/EECS-2016-17.html
work page 2016
-
[4]
Yaohui Cai, Kaixin Yang, Chenhui Deng, Cunxi Yu, and Zhiru Zhang. 2025. SmoothE: Differentiable E-Graph Extraction. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 (ASPLOS ’25). Association for Computing Machinery, New York, NY, USA, 1020–1034. doi:10.1145/3669940.3707262
-
[5]
Hao Cheng, Georgios Fotiadis, Johann Großschädl, Daniel Page, Thinh H. Pham, and Peter Y. A. Ryan. 2024. RISC-V Instruction Set Extensions for Multi-Precision Integer Arithmetic: A Case Study on Post-Quantum Key Exchange Using CSIDH-
work page 2024
-
[6]
Association for Computing Machinery, New York, NY, USA, 1–6
InProceedings of the 61st ACM/IEEE Design Automation Conference (DAC ’24). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/ 3649329.3657347
-
[7]
Codasip. 2025. CodAL RISC-V architecture description language - Codasip. https://codasip.com/products/codasip-studio/codal/
work page 2025
-
[8]
Schuyler Eldridge, Prithayan Barua, Aliaksei Chapyzhenka, Adam Izraelevitz, Jack Koenig, Chris Lattner, Andrew Lenharth, George Leontiev, Fabian Schuiki, Ram Sunder, Andrew Young, and Richard Xia. 2021. MLIR as Hardware Compiler Infrastructure. InWorkshop on Open-Source EDA Technology (WOSET)
work page 2021
-
[9]
Gerasimos Gerogiannis, Stijn Eyerman, Evangelos Georganas, Wim Heirman, and Josep Torrellas. 2025. DECA: A Near-Core LLM Decompression Accelerator Grounded on a 3D Roofline Model. InProceedings of the 58th IEEE/ACM Interna- tional Symposium on Microarchitecture (MICRO ’25). Association for Computing Machinery, New York, NY, USA, 184–200. doi:10.1145/37258...
-
[10]
James C. Hoe and Arvind. 2000. Synthesis of operation-centric hardware descrip- tions. InProceedings of the 2000 IEEE/ACM international conference on Computer- aided design (ICCAD ’00). IEEE Press, San Jose, California, 511–519
work page 2000
-
[11]
Lana Josipović. 2025. dynamatic: DHLS (Dynamic High-Level Synthesis) compiler based on MLIR. https://github.com/EPFL-LAP/dynamatic
work page 2025
-
[12]
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Olek- sandr Zinenko. 2021. MLIR: Scaling Compiler Infrastructure for Domain Specific Computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). 2–14. doi:10.1109/CGO51591.2021.9370308
-
[13]
Huimin Li, Nele Mentens, and Stjepan Picek. 2022. A scalable SIMD RISC-V based processor with customized vector extensions for CRYSTALS-kyber. InProceedings of the 59th ACM/IEEE Design Automation Conference (DAC ’22). Association for Computing Machinery, New York, NY, USA, 733–738. doi:10.1145/3489517. 3530552
-
[14]
Jules Merckx, Alexandre Lopoukhine, Samuel Coward, Jianyi Cheng, Bjorn De Sutter, and Tobias Grosser. 2025. eqsat: An Equality Saturation Dialect for Non- destructive Rewriting. doi:10.48550/arXiv.2505.09363 arXiv:2505.09363 [cs]
-
[15]
Julian Oppermann, Brindusa Mihaela Damian-Kosterhon, Florian Meisel, Tammo Mürmann, Eyck Jentzsch, and Andreas Koch. 2024. Longnail: High-Level Syn- thesis of Portable Custom Instruction Set Extensions for RISC-V Processors from Descriptions in the Open-Source CoreDSL Language. InProceedings of the 29th ACM International Conference on Architectural Suppor...
-
[16]
Tianwei Pan, Tianao Dai, Jianlei Yang, Hongbin Jing, Yang Su, Zeyu Hao, Xi- aotao Jia, Chunming Hu, and Weisheng Zhao. 2025. Finesse: An Agile Design Framework for Pairing-based Cryptography via Software/Hardware Co-Design. InProceedings of the 52nd Annual International Symposium on Computer Architec- ture. ACM, Tokyo Japan, 65–77. doi:10.1145/3695053.3731033
-
[17]
Radu Bogdan Rusu and Steve Cousins. 2011. 3D is here: Point Cloud Library (PCL). InIEEE International Conference on Robotics and Automation (ICRA). IEEE, Shanghai, China
work page 2011
-
[18]
Paul Scheffler, Luca Colagrande, and Luca Benini. 2024. SARIS: Accelerating Stencil Computations on Energy-Efficient RISC-V Compute Clusters with Indi- rect Stream Registers. InProceedings of the 61st ACM/IEEE Design Automation Conference (DAC ’24). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/3649329.3658494
-
[19]
Synopsys, Inc. 2025. ASIP Designer. https://www.synopsys.com/dw/ipdir.php? ds=asip-designer
work page 2025
-
[20]
Simpson, Fadi Alzammar, Liam Cooper, and Hyesoon Kim
Blaise Tine, Varun Saxena, Santosh Srivatsan, Joshua R. Simpson, Fadi Alzammar, Liam Cooper, and Hyesoon Kim. 2023. Skybox: Open-Source Graphic Rendering on Programmable RISC-V GPUs. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 (ASPLOS 2023). Association for Compu...
-
[21]
Blaise Tine, Krishna Praveen Yalamarthy, Fares Elsabbagh, and Kim Hyesoon
-
[22]
Post-Fabrication Microarchitecture,
Vortex: Extending the RISC-V ISA for GPGPU and 3D-Graphics. InMICRO- 54: 54th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO ’21). Association for Computing Machinery, New York, NY, USA, 754–766. doi:10. 1145/3466752.3480128
-
[23]
Johan Van Praet, Dirk Lanneer, Werner Geurts, and Gert Goossens. 2008. Chapter 4 - nML: A Structural Processor Modeling Language for Retargetable Compilation and ASIP Design. InProcessor Description Languages. Systems on Silicon, Vol. 1. Morgan Kaufmann, Burlington, 65–93. doi:10.1016/B978-012374287-2.50007-0
-
[24]
Veripool. 2025. Veripool. https://www.veripool.org/verilator/
work page 2025
-
[25]
Andrew Waterman, Yunsup Lee, David A. Patterson, and Krste Asanović. 2014. The RISC-V Instruction Set Manual, Volume I: User-Level ISA, Version 2.0. Technical Report UCB/EECS-2014-54. EECS Department, University of California, Berkeley, Berkeley, CA. http://www2.eecs.berkeley.edu/Pubs/TechRpts/2014/EECS-2014- 54.html
work page 2014
-
[26]
egg: Fast and Extensible Equality Saturation , url =
Max Willsey, Chandrakana Nandi, Yisu Remy Wang, Oliver Flatt, Zachary Tatlock, and Pavel Panchekha. 2021. egg: Fast and extensible equality saturation.Artifact for "Fast and Extensible Equality Saturation"5, POPL (Jan. 2021), 23:1–23:29. doi:10.1145/3434304
-
[27]
Youwei Xiao, Yuyang Zou, Yansong Xu, Yuhao Luo, Yitian Sun, Chenyun Yin, Ruifan Xu, Renze Chen, and Yun Liang. 2025. APS: Open-Source Hardware- Software Co-Design Framework for Agile Processor Specialization. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). Mu- nich, Germany
work page 2025
-
[28]
Ruifan Xu, Youwei Xiao, Jin Luo, and Yun Liang. 2022. HECTOR: A Multi-level Intermediate Representation for Hardware Synthesis Methodologies. In2022 IEEE/ACM International Conference On Computer Aided Design (ICCAD). San Diego, California, USA, 1–9. https://ieeexplore.ieee.org/document/10068908 ISSN: 1558-2434
-
[29]
En-Yu Yang, Tianyu Jia, David Brooks, and Gu-Yeon Wei. 2021. FlexACC: A Pro- grammable Accelerator with Application-Specific ISA for Flexible Deep Neural Network Inference. In2021 IEEE 32nd International Conference on Application- specific Systems, Architectures and Processors (ASAP). 266–273. doi:10.1109/ ASAP52443.2021.00046 ISSN: 2160-052X
-
[30]
Hanchen Ye, HyeGang Jun, Hyunmin Jeong, Stephen Neuendorffer, and Deming Chen. 2022. ScaleHLS: a scalable high-level synthesis framework with multi-level transformations and optimizations: invited. InProceedings of the 59th ACM/IEEE Design Automation Conference (DAC ’22). Association for Computing Machinery, New York, NY, USA, 1355–1358. doi:10.1145/34895...
-
[31]
Jiaqi Yin, Zhan Song, Chen Chen, Yaohui Cai, Zhiru Zhang, and Cunxi Yu. 2025. e-boost: Boosted E-Graph Extraction with Adaptive Heuristics and Exact Solving. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). Munich, Germany
work page 2025
-
[32]
Abd-El-Aziz Zayed and Christophe Dubach. 2025. DialEgg: Dialect-Agnostic MLIR Optimizer using Equality Saturation with Egglog. InProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Optimization (CGO ’25). Association for Computing Machinery, New York, NY, USA, 271–283. doi:10.1145/3696443.3708957
-
[33]
Better Together: Unifying Datalog and Equality Saturation
Yihong Zhang, Yisu Remy Wang, Oliver Flatt, David Cao, Philip Zucker, Eli Rosenthal, Zachary Tatlock, and Max Willsey. 2023. Better Together: Unifying 7 Conference’17, July 2017, Washington, DC, USA Zou et al. and Yuyang Zou, Youwei Xiao, Yansong Xu, Chenyun Yin, Yuhao Luo, Yitian Sun, Ruifan Xu, Renze Chen and Yun Liang Datalog and Equality Saturation.Ar...
work page 2023
-
[34]
Jerry Zhao, Ben Korpan, Abraham Gonzalez, and Krste Asanovic. 2020. Son- icBOOM: The 3rd Generation Berkeley Out-of-Order Machine. InThe Fourth Workshop on RISC-V for Computer Architecture Research (CARRV). 8
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.