Cost-Aware Model Orchestration for LLM-based Systems
Pith reviewed 2026-05-17 02:18 UTC · model grok-4.3
The pith
LLM orchestrators reach better accuracy and efficiency by folding quantitative performance numbers into their model choices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
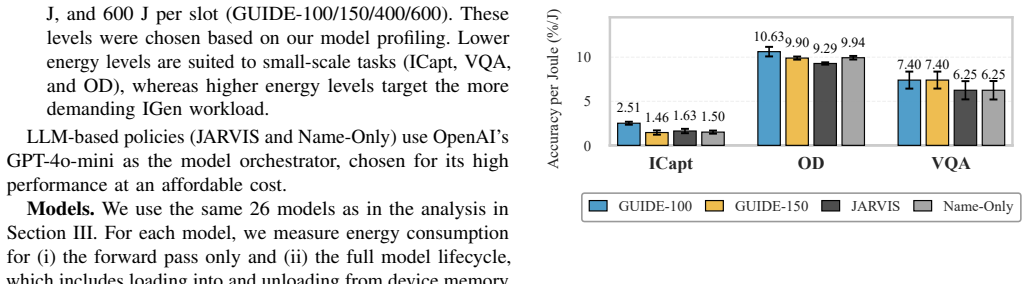
The paper proposes a cost-aware model selection method that accounts for performance-cost trade-offs by incorporating quantitative model performance characteristics within decision-making. Initial experimental results demonstrate that this method increases accuracy by 0.90%-11.92% across various evaluated tasks, achieves up to a 54% energy efficiency improvement, and reduces orchestrator model selection latency from 4.51 s to 7.2 ms.
What carries the argument
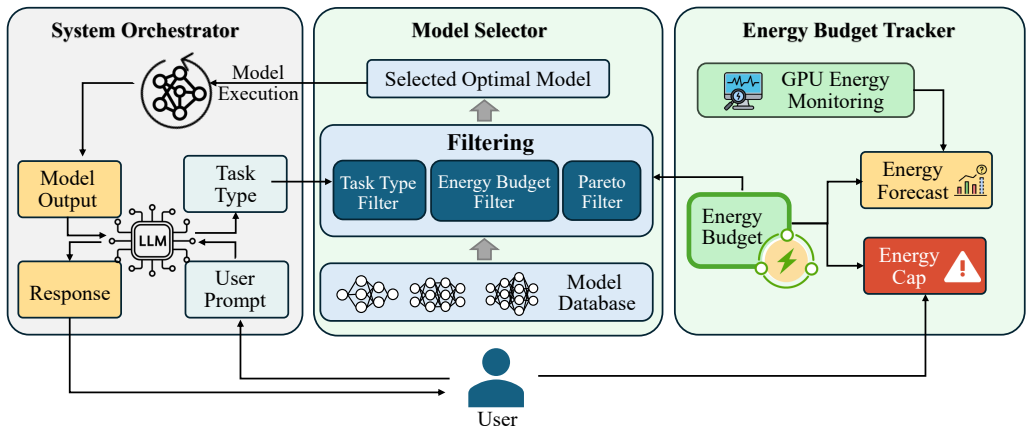
Cost-aware model selection method that incorporates quantitative performance characteristics into the LLM decision-making process.
If this is right
- Accuracy on the evaluated tasks rises between 0.90% and 11.92%.
- Energy efficiency improves by as much as 54%.
- Model selection latency drops from 4.51 seconds to 7.2 milliseconds.
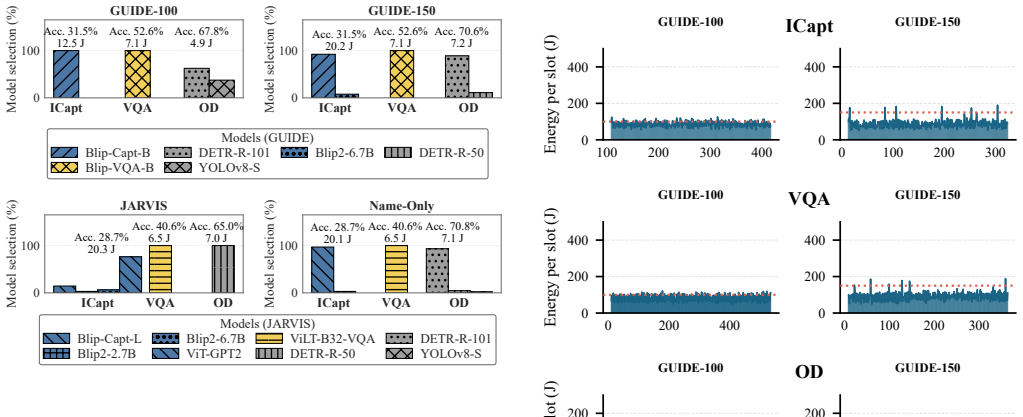
- Selections more closely reflect true model capabilities, lowering the rate of suboptimal choices.
Where Pith is reading between the lines
- The same quantitative integration could let orchestrators handle growing catalogs of models without decision time growing proportionally.
- Periodic refresh of the measured characteristics would keep gains intact as models are updated or replaced.
- Hybrid systems could combine the LLM's reasoning with direct metric lookup tables to further reduce reliance on descriptive text alone.
Load-bearing premise
Quantitative performance characteristics of models are readily available, accurate, and can be incorporated into LLM decision-making without introducing new selection biases or significant additional overhead.
What would settle it
A controlled test that runs identical tasks with and without the quantitative characteristics and finds no measurable gain in accuracy or efficiency, or that finds the added data collection increases overall latency.
Figures

read the original abstract
As modern artificial intelligence (AI) systems become more advanced and capable, they can leverage a wide range of tools and models to perform complex tasks. The task of orchestrating these models is increasingly performed by Large Language Models (LLMs) that rely on qualitative descriptions of models for decision-making. However, the descriptions provided to existing LLM-based orchestrators frequently do not reflect true model capabilities and performance characteristics, leading to suboptimal model selection, reduced task accuracy, and increased cost. In this paper, we conduct an empirical analysis of LLM-based orchestration limitations and propose a cost-aware model selection method that accounts for performance-cost trade-offs by incorporating quantitative model performance characteristics within decision-making. Initial experimental results demonstrate that our proposed method increases accuracy by 0.90%-11.92% across various evaluated tasks, achieves up to a 54% energy efficiency improvement, and reduces orchestrator model selection latency from 4.51 s to 7.2 ms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes limitations of LLM-based model orchestration that relies on qualitative model descriptions, which can lead to suboptimal selections. It proposes a cost-aware orchestration method that incorporates quantitative performance metrics (accuracy, energy, latency) into LLM decision-making for model selection. Initial experiments claim accuracy gains of 0.90%-11.92% across tasks, up to 54% energy efficiency improvement, and reduction of selection latency from 4.51 s to 7.2 ms.
Significance. If the net gains hold after including costs of acquiring the quantitative characteristics, the approach could meaningfully improve efficiency and accuracy in multi-model LLM systems by enabling explicit performance-cost trade-offs. The work identifies a practical gap in current qualitative-only orchestration and offers an empirical demonstration of potential benefits.
major comments (1)
- §5 (Experimental Evaluation): The reported accuracy, energy (up to 54%), and latency (4.51 s to 7.2 ms) improvements treat quantitative performance characteristics as available inputs without measuring or subtracting the overhead of obtaining them (via offline profiling or online estimation). This is load-bearing for the central claim, as unaccounted benchmarking costs could negate the net efficiency and latency gains, especially for new tasks where profiling does not transfer.
minor comments (2)
- Abstract: Provide at least high-level information on the number of tasks, models evaluated, and comparison baselines to allow readers to contextualize the 0.90%-11.92% accuracy range.
- §3 (Method): Clarify the exact integration mechanism (e.g., how quantitative metrics are encoded in the LLM prompt or used in a separate selector) with pseudocode or a diagram for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will revise the paper to strengthen the experimental evaluation.
read point-by-point responses
-
Referee: §5 (Experimental Evaluation): The reported accuracy, energy (up to 54%), and latency (4.51 s to 7.2 ms) improvements treat quantitative performance characteristics as available inputs without measuring or subtracting the overhead of obtaining them (via offline profiling or online estimation). This is load-bearing for the central claim, as unaccounted benchmarking costs could negate the net efficiency and latency gains, especially for new tasks where profiling does not transfer.
Authors: We agree this is a valid concern and a limitation in the current presentation of results. The reported gains focus on the online orchestration and execution phase, under the assumption that quantitative metrics (accuracy, energy, latency) have been pre-computed via offline profiling, which is a realistic setup for production multi-model systems where profiling occurs once and is reused. However, we acknowledge that the one-time cost of profiling could reduce net benefits for infrequent or entirely new tasks where metrics do not transfer. In the revised manuscript we will add a dedicated analysis in §5 that (1) reports the measured time and energy overhead of our offline profiling procedure for the evaluated models, (2) discusses amortization over repeated task invocations, and (3) identifies conditions under which the net gains remain positive. This will make the efficiency claims more precise without altering the core experimental findings. revision: yes
Circularity Check
No circularity: empirical method relies on external measurements with no internal derivation chain
full rationale
The paper conducts an empirical analysis of LLM orchestration limitations and proposes a cost-aware selection method that incorporates quantitative performance characteristics (accuracy, energy, latency) as inputs to decision-making. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the abstract or described approach. The reported gains (+0.90–11.92% accuracy, up to 54% energy improvement, latency reduction to 7.2 ms) are presented as experimental outcomes using externally obtained characteristics, rendering the work self-contained against external benchmarks rather than reducing any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We use Pareto optimization to balance accuracy and average energy usage when selecting models... the Selector performs Pareto-Efficient filtering to obtain a subset of models on the Pareto Frontier of (Acc, Eavg).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GUIDE achieves significant accuracy improvements... up to 54% in Accuracy-per-Joule... while operating at 7.2 ms latency per request (vs 4.51 s for LLM-based methods).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ajantha Vijayakumar and Subramaniyaswamy Vairavasun- daram. YOLO-based object detection models: A review and its applications.Multimedia Tools and Applications, 83(35):83535–83574, 10 2024
work page 2024
-
[2]
Automatic speech recognition: Systematic literature review.IEEE Access, 9:131858–131876, 2021
Sadeen Alharbi, Muna Alrazgan, Alanoud Alrashed, Turkiayh Alnomasi, Raghad Almojel, Rimah Alharbi, Saja Alharbi, Sahar Alturki, Fatimah Alshehri, and Maha Almojil. Automatic speech recognition: Systematic literature review.IEEE Access, 9:131858–131876, 2021
work page 2021
-
[3]
LLaV A- Plus: Learning to use tools for creating multimodal agents, 2023
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang, Jianfeng Gao, and Chunyuan Li. LLaV A- Plus: Learning to use tools for creating multimodal agents, 2023
work page 2023
-
[4]
HuggingGPT: Solving AI tasks with ChatGPT and its friends in Hugging Face, 2023
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI tasks with ChatGPT and its friends in Hugging Face, 2023
work page 2023
-
[5]
ViperGPT: Visual inference via python execution for reasoning, 2023
D´ıdac Sur´ıs, Sachit Menon, and Carl V ondrick. ViperGPT: Visual inference via python execution for reasoning, 2023
work page 2023
-
[6]
Visual ChatGPT: Talking, drawing and editing with visual foundation models, 2023
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual ChatGPT: Talking, drawing and editing with visual foundation models, 2023
work page 2023
-
[7]
Agentic reasoning and tool integration for LLMs via reinforcement learning, 2025
Joykirat Singh, Raghav Magazine, Yash Pandya, and Akshay Nambi. Agentic reasoning and tool integration for LLMs via reinforcement learning, 2025
work page 2025
-
[8]
Towards robust multi-modal reasoning via model selection, 2024
Xiangyan Liu, Rongxue Li, Wei Ji, and Tao Lin. Towards robust multi-modal reasoning via model selection, 2024
work page 2024
-
[9]
Toolformer: Language models can teach themselves to use tools, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Can- cedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023
work page 2023
-
[10]
The growing energy footprint of artificial intelligence.Joule, 7(10):2191–2194, 2023
Alex De Vries. The growing energy footprint of artificial intelligence.Joule, 7(10):2191–2194, 2023
work page 2023
-
[11]
Tryage: Real- time, intelligent routing of user prompts to large language models, 2023
Surya Narayanan Hari and Matt Thomson. Tryage: Real- time, intelligent routing of user prompts to large language models, 2023
work page 2023
-
[12]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V . S. Laksh- manan, and Ahmed Hassan Awadallah. Hybrid LLM: Cost-efficient and quality-aware query routing, 2024
work page 2024
-
[13]
TensorOpera Router: A multi-model router for efficient LLM inference, 2024
Dimitris Stripelis, Zijian Hu, Jipeng Zhang, Zhaozhuo Xu, Alay Dilipbhai Shah, Han Jin, Yuhang Yao, Salman Avestimehr, and Chaoyang He. TensorOpera Router: A multi-model router for efficient LLM inference, 2024
work page 2024
-
[14]
Gonzalez, M Waleed Kadous, and Ion Stoica
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, and Ion Stoica. RouteLLM: Learning to route LLMs with preference data, 2025
work page 2025
-
[15]
Energy-aware tinyML model selection on zero energy devices.Internet of Things, 30:101488, 2025
Adnan Sabovic, Jaron Fontaine, Eli De Poorter, and Jeroen Famaey. Energy-aware tinyML model selection on zero energy devices.Internet of Things, 30:101488, 2025
work page 2025
-
[16]
LOVM: Language-only vision model selection, 2023
Orr Zohar, Shih-Cheng Huang, Kuan-Chieh Wang, and Serena Yeung. LOVM: Language-only vision model selection, 2023
work page 2023
-
[17]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs, 2023
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs, 2023
work page 2023
-
[18]
From words to watts: Benchmarking the energy costs of large language model inference, 2023
Siddharth Samsi, Dan Zhao, Joseph McDonald, Baolin Li, Adam Michaleas, Michael Jones, William Bergeron, Jeremy Kepner, Devesh Tiwari, and Vijay Gadepally. From words to watts: Benchmarking the energy costs of large language model inference, 2023
work page 2023
-
[19]
DETRs beat YOLOs on real-time object detection, 2024
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. DETRs beat YOLOs on real-time object detection, 2024
work page 2024
-
[20]
Vanessa Mehlin, Sigurd Schacht, and Carsten Lanquillon. Towards energy-efficient deep learning: An overview of energy-efficient approaches along the deep learning lifecycle, 2023
work page 2023
-
[21]
Zeyu Yang and Wesley Armour. The hidden joules: Evaluating the energy consumption of vision backbones for progress towards more efficient model inference. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[22]
GreenLLM: SLO-Aware dynamic frequency scaling for energy-efficient LLM serving, 2025
Qunyou Liu, Darong Huang, Marina Zapater, and David Atienza. GreenLLM: SLO-Aware dynamic frequency scaling for energy-efficient LLM serving, 2025
work page 2025
-
[23]
Energy-aware dynamic neural inference, 2024
Marcello Bullo, Seifallah Jardak, Pietro Carnelli, and Deniz G ¨und¨uz. Energy-aware dynamic neural inference, 2024
work page 2024
-
[24]
Carbon- and precedence-aware scheduling for data processing clusters
Adam Lechowicz, Rohan Shenoy, Noman Bashir, Mo- hammad Hajiesmaili, Adam Wierman, and Christina Delimitrou. Carbon- and precedence-aware scheduling for data processing clusters. InProceedings of the ACM SIGCOMM 2025 Conference, page 1241–1244, New York, USA, 2025
work page 2025
-
[25]
Yadwadkar, and Christos Kozyrakis
Francisco Romero, Qian Li, Neeraja J. Yadwadkar, and Christos Kozyrakis. INFaaS: Automated model-less inference serving. InProceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC 2021), pages 397–411, 2021
work page 2021
-
[26]
Kalbarczyk, Tamer Bas ¸ar, and Ravishankar K
Haoran Qiu, Weichao Mao, Archit Patke, Shengkun Cui, Saurabh Jha, Chen Wang, Hubertus Franke, Zbigniew T. Kalbarczyk, Tamer Bas ¸ar, and Ravishankar K. Iyer. Power- aware deep learning model serving with µ-serve. In Proceedings of the 2024 USENIX Annual Technical Conference (USENIX ATC 2024), pages 75–93, Santa Clara, USA, 2024
work page 2024
-
[27]
CATP-LLM: Empowering large language models for cost-aware tool planning, 2025
Duo Wu, Jinghe Wang, Yuan Meng, Yanning Zhang, Le Sun, and Zhi Wang. CATP-LLM: Empowering large language models for cost-aware tool planning, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.