Structural Prognostic Event Modeling for Multimodal Cancer Survival Analysis
Pith reviewed 2026-05-17 02:13 UTC · model grok-4.3
The pith
A slot attention model compresses multimodal cancer data into distinct prognostic events to improve survival predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
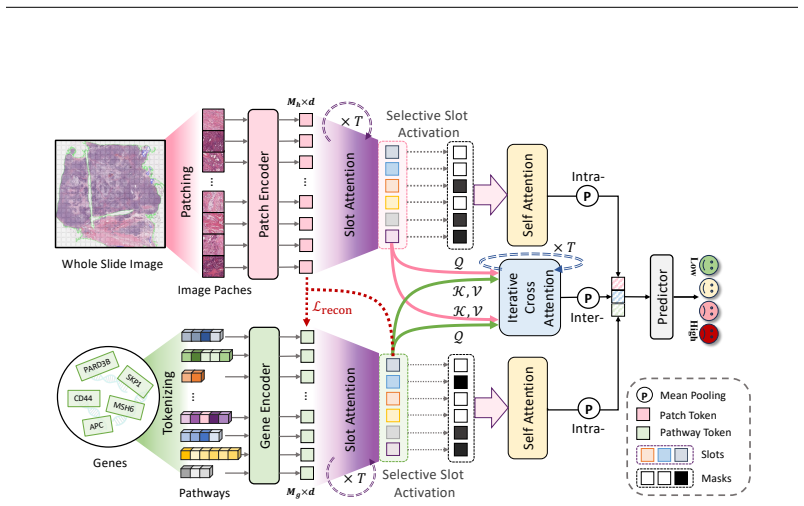
By applying slot attention to compress each patient's multimodal inputs into compact, modality-specific sets of mutually distinctive slots, the framework encodes prognostic events in a way that supports efficient intra- and inter-modal interaction modeling and the direct inclusion of biological priors.
What carries the argument
Slot attention producing modality-specific sets of mutually distinctive slots that serve as encodings for sparse, patient-specific prognostic events.
If this is right
- The model outperforms prior methods in eight of ten cancer cohorts.
- It delivers an overall 2.9 percent gain in survival prediction performance.
- Performance stays stable when genomic data is missing.
- Interpretability improves through explicit decomposition into structured prognostic events.
Where Pith is reading between the lines
- The slot decomposition may make it easier to connect model outputs to specific clinical or biological hypotheses for targeted follow-up.
- The same compression strategy could be tested on other multimodal medical tasks such as treatment-response prediction.
- Adding richer pathway-level priors during slot learning might increase the biological relevance of the discovered events.
Load-bearing premise
The learned slots genuinely correspond to meaningful sparse prognostic events rather than functioning only as a convenient data compression that improves scores.
What would settle it
A follow-up study that checks whether the extracted slots align with independently verified histologic patterns or known gene pathway activations in the same patient samples.
Figures













read the original abstract
The integration of histology images and gene profiles has shown great promise for improving survival prediction in cancer. However, current approaches often struggle to model intra- and inter-modal interactions efficiently and effectively due to the high dimensionality and complexity of the inputs. A major challenge is capturing critical prognostic events that, though few, underlie the complexity of the observed inputs and largely determine patient outcomes. These events, manifested as high-level structural signals such as spatial histologic patterns or pathway co-activations, are typically sparse, patient-specific, and unannotated, making them inherently difficult to uncover. To address this, we propose SlotSPE, a slot-based framework for structural prognostic event modeling. Specifically, inspired by the principle of factorial coding, we compress each patient's multimodal inputs into compact, modality-specific sets of mutually distinctive slots using slot attention. By leveraging these slot representations as encodings for prognostic events, our framework enables both efficient and effective modeling of complex intra- and inter-modal interactions, while also facilitating seamless incorporation of biological priors that enhance prognostic relevance. Extensive experiments on ten cancer benchmarks show that SlotSPE outperforms existing methods in 8 out of 10 cohorts, achieving an overall improvement of 2.9%. It remains robust under missing genomic data and delivers markedly improved interpretability through structured event decomposition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SlotSPE, a slot attention-based framework for structural prognostic event modeling in multimodal cancer survival analysis. It compresses high-dimensional histology images and gene profiles into compact, modality-specific sets of mutually distinctive slots that serve as encodings of sparse, patient-specific, unannotated prognostic events (e.g., spatial histologic patterns or pathway co-activations). These slots enable efficient intra- and inter-modal interaction modeling and incorporation of biological priors. Experiments on ten cancer cohorts report outperformance versus existing methods in 8/10 cases with an overall 2.9% improvement, robustness to missing genomic data, and improved interpretability via structured event decomposition.
Significance. If the slots can be validated as capturing biologically meaningful prognostic events rather than generic compressed features, the framework offers a principled way to decompose multimodal inputs for both predictive performance and interpretability in survival analysis. The scale of evaluation across ten cohorts and the reported robustness to missing data are strengths that would support practical adoption if the central correspondence claim is substantiated.
major comments (2)
- [Abstract / Results] Abstract and Results: The claim of outperforming existing methods in 8 out of 10 cohorts with an 'overall improvement of 2.9%' provides no definition of the aggregate metric (e.g., mean C-index difference), no statistical significance tests, no error bars or confidence intervals, and no mention of multiple-testing correction across cohorts. This directly weakens the central empirical claim of superiority.
- [Abstract / Methods] Abstract and Methods: The framework treats learned slots as encodings of 'sparse, patient-specific, and unannotated prognostic events' to justify both interaction modeling and 'markedly improved interpretability through structured event decomposition.' No quantitative validation (e.g., alignment with known histologic patterns, pathway markers, or supervised event labels) or ablation enforcing biological priors is described to establish this correspondence over generic representation learning. This assumption is load-bearing for the title, novelty, and interpretability claims.
minor comments (2)
- [Methods] The exact formulation of the slot attention updates and the loss terms used to encourage mutual distinctiveness of slots should be stated explicitly with equations rather than high-level description.
- [Figures] Figure captions and legends should clarify what the visualized slots represent (e.g., attention maps overlaid on histology) and how they are selected for display.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, agreeing where revisions are needed to strengthen statistical reporting and providing clarifications on the interpretability claims while proposing targeted additions.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results: The claim of outperforming existing methods in 8 out of 10 cohorts with an 'overall improvement of 2.9%' provides no definition of the aggregate metric (e.g., mean C-index difference), no statistical significance tests, no error bars or confidence intervals, and no mention of multiple-testing correction across cohorts. This directly weakens the central empirical claim of superiority.
Authors: We agree that the aggregate metric requires explicit definition and statistical support for rigor. The reported 2.9% overall improvement is the mean C-index difference across the eight cohorts where SlotSPE outperformed baselines. In the revised manuscript, we will define this metric clearly as the average per-cohort C-index improvement, report individual cohort results with standard errors from cross-validation folds, include paired statistical significance tests (e.g., Wilcoxon signed-rank or DeLong's test), and apply Bonferroni correction for multiple comparisons. These details will be added to the Results section with updated tables and summarized concisely in the Abstract. revision: yes
-
Referee: [Abstract / Methods] Abstract and Methods: The framework treats learned slots as encodings of 'sparse, patient-specific, and unannotated prognostic events' to justify both interaction modeling and 'markedly improved interpretability through structured event decomposition.' No quantitative validation (e.g., alignment with known histologic patterns, pathway markers, or supervised event labels) or ablation enforcing biological priors is described to establish this correspondence over generic representation learning. This assumption is load-bearing for the title, novelty, and interpretability claims.
Authors: The slot attention design, inspired by factorial coding, produces mutually distinctive representations, and biological priors are incorporated to enhance prognostic relevance as described in the Methods. Interpretability is supported by qualitative analyses of slot specialization and survival associations in the current experiments. We acknowledge the absence of direct quantitative alignment metrics against annotated events, which would require additional labeled data not present in the public cohorts. In revision, we will add an ablation comparing performance and slot distinctiveness with versus without prior incorporation, plus expanded qualitative examples linking slots to known histologic or pathway features. This will better substantiate the structured decomposition claim while maintaining that the framework goes beyond generic compression through its event-oriented design. revision: partial
Circularity Check
No significant circularity; framework is an independent modeling proposal validated experimentally
full rationale
The paper introduces SlotSPE as a new slot-attention-based compression of multimodal inputs into representations that are then interpreted as encodings of sparse prognostic events. Performance improvements (2.9% overall on 8/10 cohorts) and robustness claims are presented as outcomes of direct benchmark experiments rather than any derivation that reduces by construction to fitted parameters or prior self-citations. No equations or steps in the provided text exhibit self-definitional loops, fitted-input-as-prediction, or load-bearing self-citation chains. The interpretability claim rests on the modeling choice itself and is therefore subject to external validation rather than internal tautology.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inspired by factorial coding (Schmidhuber, 1992; Higgins et al., 2017; Greff et al., 2020), our method compresses high-dimensional multimodal inputs into a compact set of semantic slots using a slot attention module (Locatello et al., 2020), where each slot corresponds to a latent prognostic event.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Selective slot activation through a Mixture-of-Experts–style decoder that activates only the most predictive slots for each patient.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep Variational Information Bottleneck
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck.arXiv preprint arXiv:1612.00410,
work page internal anchor Pith review arXiv
-
[2]
The reactome pathway knowledgebase 2022.Nucleic acids research, 50(D1):D687–D692,
Marc Gillespie, Bijay Jassal, Ralf Stephan, Marija Milacic, Karen Rothfels, Andrea Senff-Ribeiro, Johannes Griss, Cristoffer Sevilla, Lisa Matthews, Chuqiao Gong, et al. The reactome pathway knowledgebase 2022.Nucleic acids research, 50(D1):D687–D692,
work page 2022
-
[3]
On the binding problem in artificial neural networks.arXiv preprint arXiv:2012.05208,
Klaus Greff, Sjoerd Van Steenkiste, and J ¨urgen Schmidhuber. On the binding problem in artificial neural networks.arXiv preprint arXiv:2012.05208,
-
[4]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Hong Liu, Haosen Yang, Federica Eduati, Josien PW Pluim, and Mitko Veta. Adaptive prototype learning for multimodal cancer survival analysis.arXiv preprint arXiv:2503.04643, 2025a. Junzhuo Liu, Markus Eckstein, Zhixiang Wang, Friedrich Feuerhake, and Dorit Merhof. Spatial transcriptomics expression prediction from histopathology based on cross-modal mask ...
-
[7]
Multimodal prototyping for cancer survival prediction.arXiv preprint arXiv:2407.00224,
Andrew H Song, Richard J Chen, Guillaume Jaume, Anurag J Vaidya, Alexander S Baras, and Faisal Mahmood. Multimodal prototyping for cancer survival prediction.arXiv preprint arXiv:2407.00224,
-
[8]
The information bottleneck method
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Sarah V olinsky-Fremond, Nanda Horeweg, Sonali Andani, Jurriaan Barkey Wolf, Maxime W La- farge, Cor D de Kroon, Gitte Ørtoft, Estrid Høgdall, Jouke Dijkstra, Jan J Jobsen, et al. Prediction of recurrence risk in endometrial cancer with multimodal deep learning.Nature medicine, 30(7): 1962–1973,
work page 1962
-
[10]
Shuaiyu Zhang, Xun Lin, Rongxiang Zhang, Yu Bai, Yong Xu, Tao Tan, Xunbin Zheng, and Zitong Yu. Adamhf: Adaptive multimodal hierarchical fusion for survival prediction.arXiv preprint arXiv:2503.21124,
-
[11]
Yilan Zhang, Yingxue Xu, Jianqi Chen, Fengying Xie, and Hao Chen. Prototypical informa- tion bottlenecking and disentangling for multimodal cancer survival prediction.arXiv preprint arXiv:2401.01646,
-
[12]
19 B.2 Details of Selective Slot Activation
17 APPENDIXTABLE OFCONTENTS A The Use of Large Language Models (LLMs) 19 B Method Details 19 B.1 Problem Formulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 B.2 Details of Selective Slot Activation . . . . . . . . . . . . . . . . . . . . . . . . . . 19 B.3 Details of Reconstructions . . . . . . . . . . . . . . . . . . . . . . ...
work page 2024
-
[13]
are: h(i) t =P(T=t|T≥t,z (i)),S (i) t = tY k=1 1−h (i) k , Lsurv({z(i), t(i), c(i)}ND i=1) =− NDX i=1 h c(i) logS (i) t(i) + (1−c (i)) logS (i) t(i)−1 + (1−c (i)) logh (i) t(i) i . (8) B.2 DETAILS OFSELECTIVESLOTACTIVATION To achieve sparse yet differentiable slot selection, we adopt the Gumbel-Top-K(Gumbel, 1954; Maddison et al., 2014; Kool et al.,
work page 1954
-
[14]
Given slot scoresr∈R S, we add i.i.d
trick combined with a Straight-Through (ST) estima- tor (Jang et al., 2016). Given slot scoresr∈R S, we add i.i.d. Gumbel noiseg k ∼Gumbel(0,1): ˜rk =r k +g k.(9) This perturbation transforms deterministic scores into a stochastic sampling process where largerrk values are more likely to be selected. To obtain a differentiable relaxation, we then apply so...
work page 2016
-
[15]
as the reconstruction head. For genomics, slot embeddingsS g are decoded to approximate the original pathway embeddingsX g, guided by the positional embeddings Qg (Eq. 5), with reconstruction optimized via MSE loss: ˆXg =R(Q g,S g),L g recon =∥ ˆXg −X g∥2 2.(12) For histopathology, reconstructing entire WSIs is infea1sible due to their scale and random pa...
work page 2023
-
[16]
Following (Jaume et al., 2024), we predict disease-specific survival (DSS), a more precise indicator of patient status than overall survival. Histological data include all diagnostic WSIs, while transcriptomic profiles with DSS labels are obtained from cBioPortal
work page 2024
-
[17]
Pathway gene sets are curated from Hallmarks (Subra- manian et al., 2005; Liberzon et al.,
work page 2005
-
[18]
and Reactome (Gillespie et al., 2022), with genes absent in cBioPortal removed, yielding 330 pathways. Evaluation. We adopt 5-fold cross-validation and report the concordance index (C-index) (Har- rell Jr et al.,
work page 2022
-
[19]
In addition, we compute the restricted mean survival time (RMST) (Irwin, 1949; Karrison, 1986)
to evaluate global differences in sur- vival distributions. In addition, we compute the restricted mean survival time (RMST) (Irwin, 1949; Karrison, 1986). RMST, defined as the area under the estimated survival curve up to a clinically meaningful truncation time (60 months in our experiments), provides an interpretable summary of the average survival time...
work page 1949
-
[20]
In addition, we also report results using 8 slots per modality andT= 3iterations in slot attention, with further ablations on the number of slots provided in Appendix F.3.1 and on the number of iterations in Appendix F.3.2. The results demonstrate that even with a very small number of slots for both histopathology and genomics, SlotSPE maintains strong pe...
work page 2005
-
[21]
For completeness, we also include two strong methods (MOTCAT and CMTA)
While most baselines are not explicitly designed to handle missing modalities, they can still be evaluated under missing-genomics settings by supplying a neu- tral placeholder input in place of genomic features (Zhang et al., 2025). For completeness, we also include two strong methods (MOTCAT and CMTA). The results show that when these approaches rely sol...
work page 2025
-
[22]
F.2 HISTOLOGYENCODER ABLATIONS To assess the robustness of SlotSPE to the choice of visual encoder, we first replace the histology en- coder with a ResNet50 (Srivastava et al., 2015; He et al.,
work page 2015
-
[23]
pretrained only on ImageNet (Deng et al., 2009), rather than a pathology-specific foundation model. This setting tests whether SlotSPE 25 Table 8: Ablation of model components reported as C-index (mean±std) across ten cancer datasets. Best and second-best results are inboldand underline . Variants BRCA (N=1046) COADREAD (N=573) KIRC (N=488) UCEC (N=488) L...
work page 2009
-
[24]
As summarized in Table 9, SlotSPE continues to outperform all baselines under this weaker configuration, suggesting that its performance is not tightly coupled to a specialized encoder. We further extend this analysis by examining SlotSPE with recent pathology foundation models, includ- ing CONCH (Lu et al., 2024), CONCH v1.5 (used in TITAN (Ding et al., ...
work page 2024
-
[25]
as an approximation to full self-attention, but its capacity remains insufficient to capture the sparse, patient-specific prognostic signals. LD-CV AE attains the second-best performance, yet its reliance on a variational autoencoder introduces sub- stantial memory and runtime overhead. G.2 TRAININGRUNTIME ANDMEMORY We also compare training-time runtime a...
work page 2019
-
[26]
using both clinical covariates and our model’s predicted risk scores. For each cohort, we merged the risk prediction of SlotSPE with these clinical variables on a per-patient basis. Importantly, the risk scores were obtained from the validation folds, ensuring that the model had no access to these samples during training. We then fitted Cox models across ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.