The Equivalence of Fast Algorithms for Convolution, Parallel FIR Filters, Polynomial Modular Multiplication, and Pointwise Multiplication in DFT/NTT Domain
Pith reviewed 2026-05-17 02:37 UTC · model grok-4.3
The pith
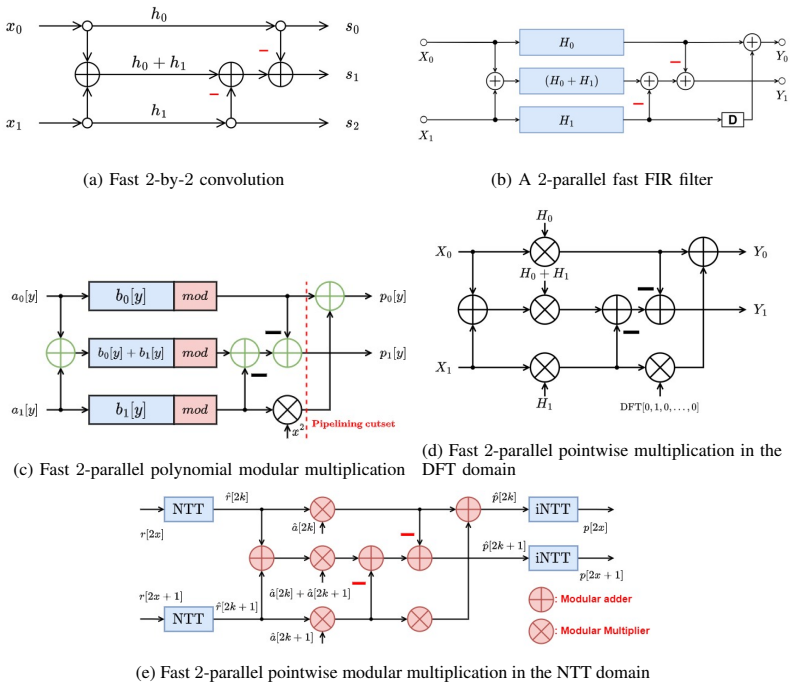
Fast convolution structures serve as the foundation for fast algorithms in parallel FIR filtering, polynomial modular multiplication, and pointwise multiplications over DFT and NTT domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Well known fast convolution structures form the basis for design of fast algorithms in four other problem domains: fast parallel filters, fast polynomial modular multiplication, and fast pointwise multiplication in the DFT and NTT domains. Fast polynomial modular multiplication and fast pointwise multiplication problems are important for cryptosystem applications such as post-quantum cryptography and homomorphic encryption. By establishing the equivalence of these problems, a fast structure from one domain can be used to design a fast structure for another domain.
What carries the argument
Algebraic mappings from fast convolution structures, including those from Cook-Toom and Winograd algorithms, that connect convolution to parallel FIR filters and to pointwise multiplications in DFT and NTT domains while preserving multiplication complexity reductions.
Load-bearing premise
The algebraic mappings between convolution, FIR filtering, polynomial modular multiplication, and pointwise DFT/NTT multiplication preserve both correctness and the claimed reduction in multiplication complexity without additional overhead or hidden assumptions on field characteristics or transform lengths.
What would settle it
A concrete case of a specific length and field where mapping a known fast convolution structure to polynomial modular multiplication produces either an incorrect result or requires more multiplications than a direct method.
Figures



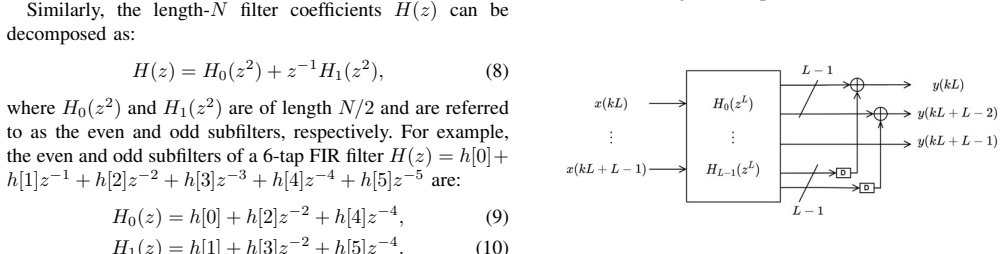




read the original abstract
Fast time-domain algorithms have been developed in signal processing applications to reduce the multiplication complexity. For example, fast convolution structures using Cook-Toom and Winograd algorithms are well understood. Short length fast convolutions can be iterated to obtain fast convolution structures for long lengths. In this paper, we show that well known fast convolution structures form the basis for design of fast algorithms in four other problem domains: fast parallel filters, fast polynomial modular multiplication, and fast pointwise multiplication in the DFT and NTT domains. Fast polynomial modular multiplication and fast pointwise multiplication problems are important for cryptosystem applications such as post-quantum cryptography and homomorphic encryption. By establishing the equivalence of these problems, we show that a fast structure from one domain can be used to design a fast structure for another domain. This understanding is important as there are many well known solutions for fast convolution that can be used in other signal processing and cryptosystem applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that well-known fast convolution algorithms (Cook-Toom and Winograd) and their iterated long-length versions are algebraically equivalent to fast algorithms for parallel FIR filtering, polynomial modular multiplication, and pointwise multiplication in the DFT and NTT domains. By establishing these equivalences, structures developed for one domain can be reused in the others while preserving the same multiplication-complexity reduction, with particular relevance to post-quantum cryptography and homomorphic encryption.
Significance. If the mappings are exact equivalences that introduce neither extra general multiplications nor domain-specific overhead, the paper supplies a unifying design principle that lets the extensive literature on fast convolution be ported directly to cryptographic polynomial arithmetic. This would be a useful contribution for practitioners who need low-multiplication implementations in rings with specific algebraic constraints.
major comments (2)
- [§4] §4 (NTT equivalence): the claim that the fast convolution structure transfers without change in multiplication count is not accompanied by an explicit statement of the necessary condition that n divides q-1 for the existence of a primitive n-th root of unity. Without this, it is unclear whether the usable lengths are restricted relative to the original convolution case, undermining the assertion that the complexity reduction carries over unchanged.
- [§3.2] §3.2 (polynomial modular multiplication mapping): the reduction step modulo the polynomial (e.g., x^n-1 or x^n+1) is described only at the level of the linear convolution; the manuscript does not count or bound any additional scalar multiplications or additions required for the modular reduction after the fast convolution block. If these operations are non-negligible, the claimed multiplication savings are not preserved.
minor comments (2)
- [Abstract] The abstract and introduction repeatedly use the phrase 'equivalence of these problems' without a precise definition of what is being equated (input-output map, arithmetic complexity, or both). A short clarifying sentence would help readers.
- [§5] Notation for the transform lengths (n, N, etc.) is introduced inconsistently across the DFT and NTT sections; a single table summarizing the parameter correspondences would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and will revise the paper accordingly to improve clarity while preserving the core claims of equivalence.
read point-by-point responses
-
Referee: [§4] §4 (NTT equivalence): the claim that the fast convolution structure transfers without change in multiplication count is not accompanied by an explicit statement of the necessary condition that n divides q-1 for the existence of a primitive n-th root of unity. Without this, it is unclear whether the usable lengths are restricted relative to the original convolution case, undermining the assertion that the complexity reduction carries over unchanged.
Authors: We agree that a primitive n-th root of unity exists only when n divides q-1. The equivalences in the manuscript are stated for NTT lengths where such a root exists, which is the standard assumption in the cryptographic settings (post-quantum cryptography and homomorphic encryption) where NTTs are employed; q is chosen to support the desired n. Under this condition the multiplication count remains identical to the convolution case, with no extra multiplications introduced. We will revise §4 to state this necessary condition explicitly and note that usable lengths are restricted to those for which the NTT is defined, consistent with the lengths considered in the convolution setting. revision: yes
-
Referee: [§3.2] §3.2 (polynomial modular multiplication mapping): the reduction step modulo the polynomial (e.g., x^n-1 or x^n+1) is described only at the level of the linear convolution; the manuscript does not count or bound any additional scalar multiplications or additions required for the modular reduction after the fast convolution block. If these operations are non-negligible, the claimed multiplication savings are not preserved.
Authors: For modular reduction modulo x^n-1 or x^n+1, the linear convolution of two degree-(n-1) polynomials yields a degree-(2n-2) result. Reduction is performed by adding (for x^n-1) or subtracting (for x^n+1) the upper n-1 coefficients to the lower n-1 coefficients. This step uses only additions and subtractions and requires no scalar multiplications. Consequently the multiplication count of the fast structure is unchanged. We will revise §3.2 to describe the reduction explicitly, bound the added operations, and confirm that they introduce no multiplications. revision: yes
Circularity Check
No circularity: algebraic equivalences link independent known structures
full rationale
The paper claims that known fast convolution algorithms (Cook-Toom, Winograd) can be reused in four other domains via algebraic mappings that preserve correctness and multiplication complexity. The abstract and description present this as an observation of equivalence rather than a quantity defined in terms of itself. No equation reduces a derived result to a fitted input by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work. The mappings are asserted to be equivalences that transfer existing structures without introducing new overhead, and the paper does not rely on self-referential definitions or load-bearing self-citations for its central claim. The derivation is therefore self-contained and draws on externally established fast convolution results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. E. Blahut,Fast algorithms for signal processing. Cambridge University Press, 2010
work page 2010
-
[2]
Fast FIR filtering: Algorithms and imple- mentations,
Z.-J. Mou and P. Duhamel, “Fast FIR filtering: Algorithms and imple- mentations,”Signal Processing, vol. 13, no. 4, pp. 377–384, 1987
work page 1987
-
[3]
Short-length FIR filters and their use in fast nonrecursive filtering,
——, “Short-length FIR filters and their use in fast nonrecursive filtering,” IEEE Transactions on Signal Processing, vol. 39, no. 6, pp. 1322–1332, 1991
work page 1991
-
[4]
P. P. Vaidyanathan,Multirate Systems and Filter Banks. Prentice Hall, Aug. 1993
work page 1993
-
[5]
K. K. Parhi,VLSI Digital Signal Processing Systems: Design and Imple- mentation. John Wiley & Sons, 1999
work page 1999
-
[6]
Hardware efficient fast parallel FIR filter structures based on iterated short convolution,
C. Cheng and K. K. Parhi, “Hardware efficient fast parallel FIR filter structures based on iterated short convolution,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 51, no. 8, pp. 1492–1500, 2004
work page 2004
-
[7]
W. Tan, A. Wang, X. Zhang, Y . Lao, and K. K. Parhi, “High-speed vlsi architectures for modular polynomial multiplication via fast filtering and applications to lattice-based cryptography,”IEEE Transactions on Computers, vol. 72, no. 9, pp. 2454–2466, 2023
work page 2023
-
[8]
W. Tan, Y . Lao, and K. K. Parhi, “KyberMat: Efficient accelerator for matrix-vector polynomial multiplication in CRYSTALS-Kyber scheme via NTT and polyphase decomposition,” in2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 2023, pp. 1–9
work page 2023
-
[9]
Low-area/power parallel FIR digital filter implementations,
D. A. Parker and K. K. Parhi, “Low-area/power parallel FIR digital filter implementations,”Journal of VLSI signal processing systems for signal, image and video technology, vol. 17, no. 1, pp. 75–92, 1997
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.