From monoliths to modules: Decomposing transducers for efficient world modelling
Pith reviewed 2026-05-22 11:49 UTC · model grok-4.3
The pith
Decomposing transducers into sub-transducers on distinct input-output subspaces yields parallel and interpretable world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our results clarify how to invert this process by deriving sub-transducers operating on distinct input-output subspaces, enabling parallelizable and interpretable alternatives to monolithic world modelling that can support distributed inference.
What carries the argument
Decomposition framework for transducers, which generalizes POMDPs, that inverts composition to produce sub-transducers on distinct input-output subspaces.
If this is right
- World model computation becomes parallelizable across subspaces.
- Interpretability of the model increases for inspection and safety analysis.
- Distributed inference across separate components becomes feasible.
- Efficiency gains support scaling to realistic, high-demand scenarios.
Where Pith is reading between the lines
- This approach may allow larger world models to run on distributed hardware without full centralization.
- It could connect to modular designs in other sequential prediction tasks beyond world modeling.
- Empirical tests on agent training loops would show whether speedups appear in practice.
Load-bearing premise
Real-world scenarios tend to involve subcomponents that interact in a modular manner.
What would settle it
A counter-example transducer built from a non-modular real-world process where the derived sub-transducers fail to match the original input-output behavior on their subspaces.
Figures










read the original abstract
World models have been recently proposed as sandbox environments in which AI agents can be trained and evaluated before deployment. While realistic world models often have high computational demands, this can often be alleviated by exploiting the fact that real-world scenarios tend to involve subcomponents that interact in a modular manner. In this paper, we explore this idea by developing a framework for decomposing complex world models represented by transducers, a class of models generalising POMDPs. Whereas the composition of transducers is well understood, our results clarify how to invert this process by deriving sub-transducers operating on distinct input-output subspaces, enabling parallelizable and interpretable alternatives to monolithic world modelling that can support distributed inference. Overall, these results lay groundwork for bridging the computational efficiency required for real-world inference and the structural transparency demanded by AI safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a framework for decomposing transducers (generalizing POMDPs) that represent world models. It inverts the well-understood composition operation to derive sub-transducers operating on distinct input-output subspaces, with the goal of producing parallelizable and interpretable alternatives to monolithic models that support distributed inference and address both computational efficiency and AI safety requirements.
Significance. If the decomposition is shown to preserve dynamics under stated conditions, the work would provide a principled algebraic route to modular world models. This could reduce inference costs via parallelism while improving structural transparency, directly supporting scalable agent training and safety analysis in realistic environments.
major comments (2)
- [§4] §4 (Inversion of Composition): The central derivation of sub-transducers from the composition inverse is presented, but the manuscript does not explicitly state the algebraic conditions on the transition relation or state space that guarantee the chosen input-output subspaces admit a factorization. Without these conditions, the projection step risks discarding cross-subspace dependencies, so that recomposition of the sub-transducers fails to recover the original dynamics (precisely the concern raised by the stress-test note).
- [§5] §5 (Validation): The reported experiments and examples do not include a controlled case in which the monolithic transducer contains non-factorizable cross-subspace interactions. Such a test is required to establish the scope of the method and to confirm that the derived sub-transducers remain equivalent when the factorization assumption holds.
minor comments (2)
- Notation for the input-output subspaces and the projection operators could be introduced earlier and used consistently to improve readability of the derivation.
- [§2] A short related-work paragraph situating the transducer decomposition relative to existing factored POMDP or modular RL literature would help readers assess novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below. The concerns are valid, and we have revised the manuscript to incorporate explicit conditions and an additional validation case.
read point-by-point responses
-
Referee: [§4] §4 (Inversion of Composition): The central derivation of sub-transducers from the composition inverse is presented, but the manuscript does not explicitly state the algebraic conditions on the transition relation or state space that guarantee the chosen input-output subspaces admit a factorization. Without these conditions, the projection step risks discarding cross-subspace dependencies, so that recomposition of the sub-transducers fails to recover the original dynamics (precisely the concern raised by the stress-test note).
Authors: We agree that the algebraic conditions must be stated explicitly. The derivation in §4 assumes a product state space S = S1 × S2 and a separable transition relation δ((s1, s2), (i1, i2)) = (δ1(s1, i1), δ2(s2, i2)) with no cross terms. We have added a formal statement of this precondition together with a short proof that, under separability, projection yields sub-transducers whose composition recovers the original transducer exactly. This makes clear that cross-subspace dependencies are excluded by the assumption rather than discarded after the fact. revision: yes
-
Referee: [§5] §5 (Validation): The reported experiments and examples do not include a controlled case in which the monolithic transducer contains non-factorizable cross-subspace interactions. Such a test is required to establish the scope of the method and to confirm that the derived sub-transducers remain equivalent when the factorization assumption holds.
Authors: The referee correctly identifies a gap in the validation. The existing examples assume modular structure by construction. We have added a controlled counter-example in the revised §5: a transducer whose transition couples the two subspaces (a simple joint-update rule). As predicted, the projected sub-transducers fail to recompose to the original dynamics. We report both the successful modular cases and this negative result to delineate the precise scope of the method. revision: yes
Circularity Check
No circularity: derivation relies on algebraic inversion of transducer composition
full rationale
The paper develops a mathematical framework for inverting transducer composition to obtain sub-transducers on distinct I/O subspaces. This is presented as a direct derivation from the well-understood composition operation, without evidence of self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central claim to its own inputs. The modular interaction assumption is explicitly motivational rather than part of the derivation chain. No equations or steps in the abstract reduce by construction to prior results from the same authors; the work appears self-contained against external algebraic benchmarks for transducers and POMDPs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world scenarios tend to involve subcomponents that interact in a modular manner.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We explore this idea by developing a framework for decomposing complex world models represented by transducers... deriving sub-transducers operating on distinct input-output subspaces
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
transducers... stochastic kernel T(y|x) r→r′ ... linear operator ˆT(y|x) = Σ T(y|x) r→r′ |r′⟩⟨r|
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Junyeob Baek, Yi-Fu Wu, Gautam Singh, and Sungjin Ahn. Dreamweaver: Learning compositional world representations from pixels.arXiv preprint arXiv:2501.14174,
-
[2]
Yoshua Bengio, Sören Mindermann, Daniel Privitera, Tamay Besiroglu, Rishi Bommasani, Stephen Casper, Yejin Choi, Danielle Goldfarb, Hoda Heidari, Leila Khalatbari, et al. International sci- entific report on the safety of advanced ai (interim report).arXiv preprint arXiv:2412.05282,
-
[3]
Dota 2 with Large Scale Deep Reinforcement Learning
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław D˛ ebiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[4]
Alexander B Boyd, James P Crutchfield, Mile Gu, and Felix C Binder. Thermodynamic overfitting and generalization: Energetic limits on predictive complexity.arXiv preprint arXiv:2402.16995,
-
[5]
A Prime Decomposition of Probabilistic Automata
20 Gunnar Carlsson and Jun Yu. A prime decomposition of probabilistic automata.arXiv preprint arXiv:1503.01502,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Towards guaranteed safe ai: A framework for ensuring robust and reliable ai systems
David Dalrymple, Joar Skalse, Yoshua Bengio, Stuart Russell, Max Tegmark, Sanjit Seshia, Steve Omohundro, Christian Szegedy, Ben Goldhaber, Nora Ammann, et al. Towards guaranteed safe AI: A framework for ensuring robust and reliable ai systems.arXiv preprint arXiv:2405.06624,
-
[7]
Lukas J Fiderer, Paul C Barth, Isaac D Smith, and Hans J Briegel. The work capacity of channels with memory: Maximum extractable work in percept-action loops.arXiv preprint arXiv:2504.06209,
-
[8]
Abel Jansma. Decomposing interventional causality into synergistic, redundant, and unique compo- nents.arXiv preprint arXiv:2501.11447,
-
[9]
Mateusz Piotrowski, Paul M Riechers, Daniel Filan, and Adam S Shai. Constrained belief updates explain geometric structures in transformer representations.arXiv preprint arXiv:2502.01954,
-
[10]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.arXiv preprint arXiv:1709.10087,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Parallel intersection and serial composition of finite state trans- ducers
Mike Reape and Henry Thompson. Parallel intersection and serial composition of finite state trans- ducers. InColing Budapest 1988 Volume 2: International Conference on Computational Linguis- tics,
work page 1988
-
[12]
Fernando E Rosas, Bernhard C Geiger, Andrea I Luppi, Anil K Seth, Daniel Polani, Michael Gast- par, and Pedro AM Mediano. Software in the natural world: A computational approach to hierar- chical emergence.arXiv preprint arXiv:2402.09090,
-
[13]
Mathematical Sciences Directorate, Air Force Office of Scientific Research, 1961a
Marcel P Schützenberger.A remark on finite transducers. Mathematical Sciences Directorate, Air Force Office of Scientific Research, 1961a. M.P. Schützenberger. A remark on finite transducers.Information and Control, 4(2):185–196, 1961b. ISSN 0019-9958. DOI: https://doi.org/10.1016/S0019-9958(61)80006-5. Adam Shai, Lucas Teixeira, Alexander Oldenziel, Sara...
-
[14]
DOI: 10.1038/s41586-025-09805-2. Xiangru Tang, Qiao Jin, Kunlun Zhu, Tongxin Yuan, Yichi Zhang, Wangchunshu Zhou, Meng Qu, Yilun Zhao, Jian Tang, Zhuosheng Zhang, et al. Prioritizing safeguarding over autonomy: Risks of llm agents for science. InICLR 2024 Workshop on Large Language Model (LLM) Agents,
-
[15]
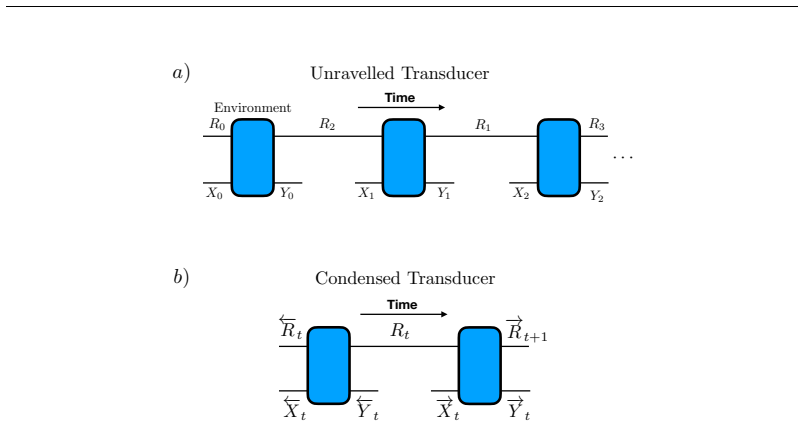
24 Supplementary Materials The following content was not necessarily subject to peer review. A Feedback interfaces In the context of a perception-action loop linking an agent and an environment, the environment can be thought of as a system that stochastically turns action sequencesx 0:t =x 0 · · ·x t−1 into observation sequencesy 0:t =y 0 · · ·y t−1 for ...
work page 2025
-
[16]
IE(y0:t|x0:t) = Pr(Y 0:t =y 0:t|X0:t =x 0:t) IA(x0:t|y0:t) = Pr(X 0:t =x 0:t|Y0:t =y 0:t).(23) Here, the capital variables represent random variables while the lowercase represent specific re- alizations. Together, they produce the joint probability of an action-observation sequence in the perception-action loop (Fiderer et al., 2025): Pr(X0:t =x 0:t, Y0:...
work page 2025
-
[17]
t−1Y i=0 e(yi, ri+1|xi, ri) (29) = Pr(X 0:t =x 0:t|Y0:t =y 0:t) Pr(Y0:t =y 0:t|X0:t =x 0:t)(30) =I A(x0:t|y0:t)IE(y0:t|x0:t).(31) The interface characterizes the behavior of the agent or environment, independent of the details of their internal models or other latents. Figure 11 shows how the perception-action loop can be decomposed into distinct inte...
work page 2025
-
[18]
There are two main types of composition of weighted finite state transducers (WFSTs): in parallel and in series (Mohri, 1997; Mohri et al., 2002). Definition 8(Parallel composition).LetT= (X,Y,R, T (y|x) r→r′ )andU= (Z,W,S, U (w|z) s→s′ )be transducers. The parallel composition ofTandUis a new transducerV= (X × Z,Y × W,R × S, V (yw|rz) rs→r′s′ )with input...
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.