Recognition: 2 theorem links
· Lean TheoremDifferent types of syntactic agreement recruit the same units within large language models
Pith reviewed 2026-05-17 02:38 UTC · model grok-4.3
The pith
Different types of syntactic agreement recruit overlapping units inside large language models
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
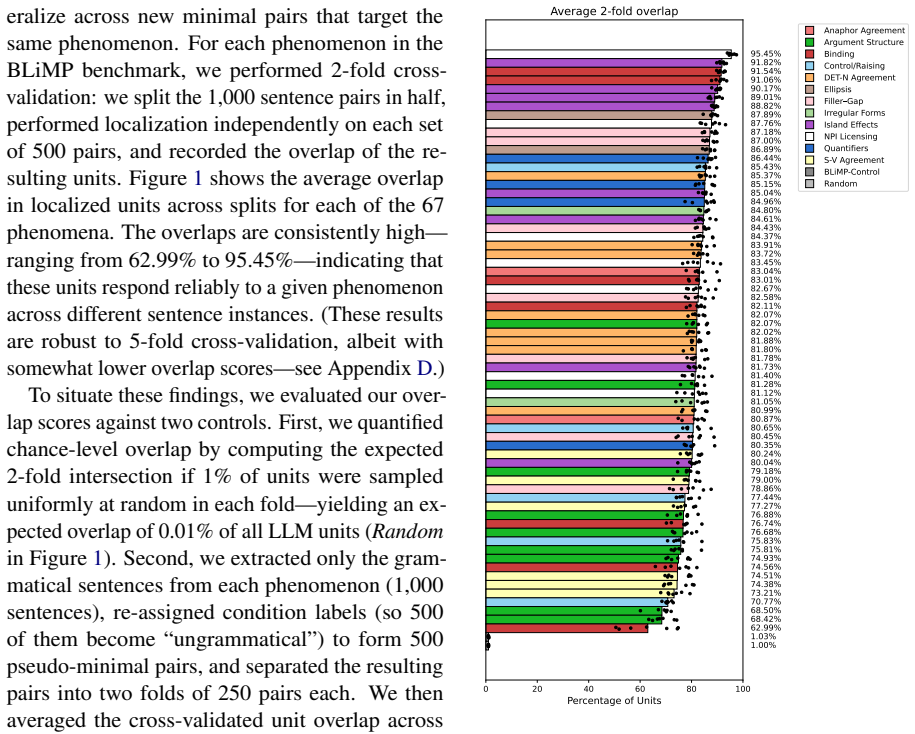
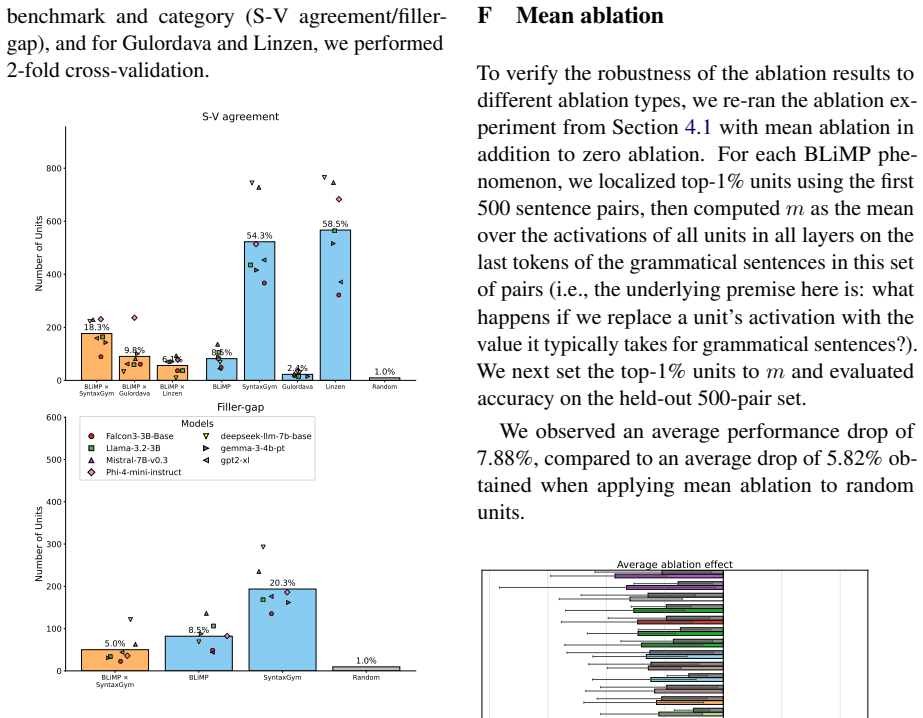
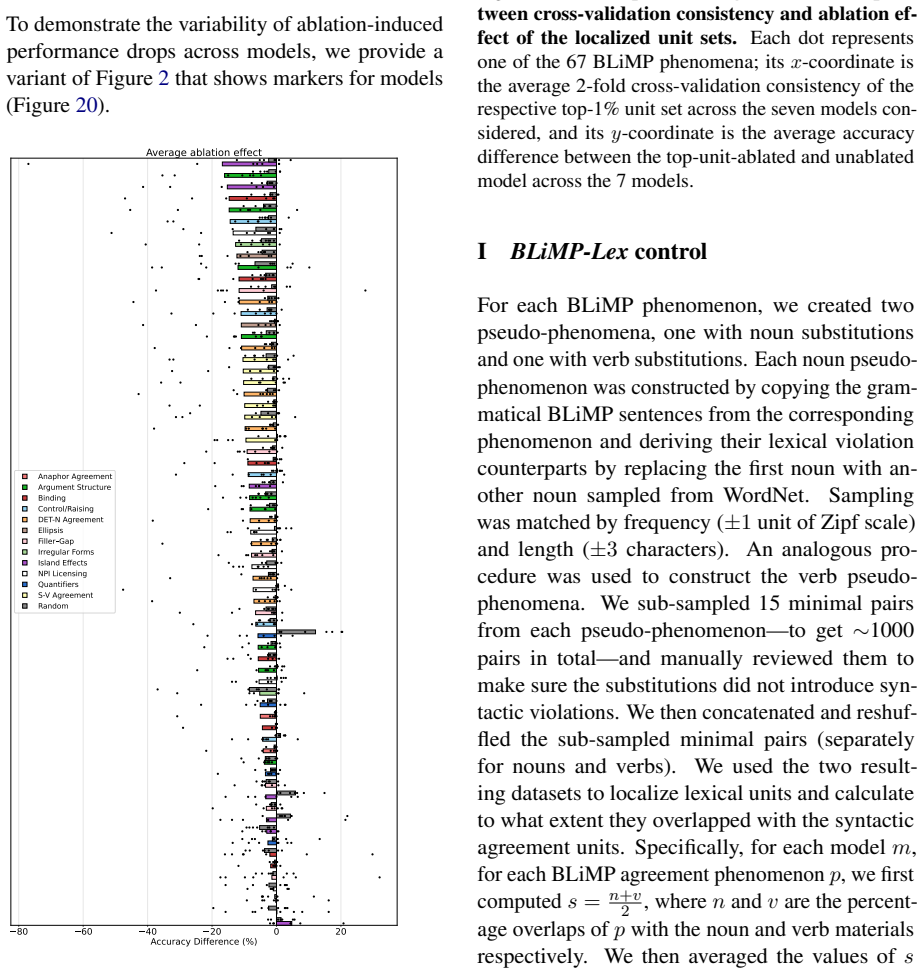
Using functional localization, the authors isolate units most responsive to each syntactic phenomenon and confirm that these units are reliably recruited across sentences and causally improve syntactic performance. Different agreement types recruit overlapping sets of units. This pattern is observed in English, Russian, and Chinese. In a cross-lingual analysis spanning 57 languages, structurally more similar languages share a larger proportion of units for subject-verb agreement.
What carries the argument
Functional localization procedure that selects LLM units showing the strongest response to a given syntactic phenomenon and tests whether intervening on those units affects grammatical judgments.
If this is right
- Agreement processing in LLMs draws on shared representational resources instead of fully separate mechanisms for each subtype.
- The same units that support one agreement relation can be expected to influence performance on other agreement relations.
- Structurally similar languages will tend to align their subject-verb agreement units more closely than dissimilar languages do.
Where Pith is reading between the lines
- Model architectures could be designed with explicit agreement modules that leverage this shared representation.
- Cross-lingual transfer of syntactic capabilities may be strongest between languages that already share agreement units.
- Similar localization methods could be applied to other syntactic dependencies to test whether they also form functional categories.
Load-bearing premise
The units identified by the localization method are specifically involved in syntactic agreement rather than responding to correlated sentence features such as length, lexical items, or overall predictability.
What would settle it
If targeted interventions on the overlapping units impair only one agreement type while leaving the others intact, or if new models show no consistent overlap across agreement types, the claim that agreement forms a meaningful category would be undermined.
Figures

















read the original abstract
Large language models (LLMs) can reliably distinguish grammatical from ungrammatical sentences, but how grammatical knowledge is represented within the models remains an open question. We investigate whether different syntactic phenomena recruit shared or distinct components in LLMs. Using a functional localization approach inspired by cognitive neuroscience, we identify the LLM units most responsive to 67 English syntactic phenomena in seven open-weight models. These units are consistently recruited across sentences containing the phenomena and causally support the models' syntactic performance. Critically, different types of syntactic agreement (e.g., subject-verb, anaphor, determiner-noun) recruit overlapping sets of units, suggesting that agreement constitutes a meaningful functional category for LLMs. This pattern holds in English, Russian, and Chinese; and further, in a cross-lingual analysis of 57 diverse languages, structurally more similar languages share more units for subject-verb agreement. Taken together, these findings reveal that syntactic agreement-a critical marker of syntactic dependencies-constitutes a meaningful category within LLMs' representational spaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an investigation into how different syntactic phenomena, particularly various types of agreement, are represented in large language models (LLMs). Using a functional localization method inspired by neuroscience, the authors identify units in seven open-weight LLMs that respond most strongly to 67 English syntactic phenomena. They demonstrate that these units are consistently activated by relevant sentences and causally influence the models' ability to handle syntactic tasks. A key finding is that different agreement types—such as subject-verb, anaphor, and determiner-noun—share overlapping units, indicating that agreement may form a distinct functional category in LLMs' internal representations. This pattern is shown to generalize to Russian and Chinese, and cross-lingual analysis across 57 languages reveals greater unit sharing for subject-verb agreement between structurally similar languages.
Significance. If the central findings are robust to controls for stimulus confounds, this work would make a notable contribution to the field of LLM interpretability by providing evidence that syntactic agreement is encoded as a coherent category rather than through disparate mechanisms. The neuroscience-inspired functional localization approach, combined with causal interventions and cross-linguistic comparisons, offers a promising framework for understanding structured knowledge in neural networks. It could influence research on model alignment with human-like grammatical processing and cross-lingual generalization.
major comments (2)
- [Methods] Methods (functional localization): The procedure selects units most responsive to sentences containing each syntactic phenomenon, but provides no explicit controls or matching for confounding variables such as sentence length, lexical predictability, or overall syntactic complexity across stimulus sets for different agreement types. If these differ systematically, the reported overlap for subject-verb, anaphor, and determiner-noun agreement could arise from shared non-syntactic features rather than a common functional category for agreement. This is load-bearing for the central claim that agreement constitutes a meaningful category.
- [Results] Results (causal interventions): The abstract asserts that the identified units causally support syntactic performance, yet the exact intervention technique (e.g., activation patching, ablation) and any specificity controls to distinguish agreement processing from general syntactic or semantic effects are not detailed. This leaves open whether the interventions confirm agreement-specific involvement or broader sentence-level functions.
minor comments (2)
- [Abstract] Abstract: The reference to '67 English syntactic phenomena' would benefit from a brief indication of selection criteria or a pointer to the supplementary materials for the full list and categorization.
- [Cross-lingual analysis] Cross-lingual analysis: Clarify how structural similarity between languages was quantified (e.g., specific metrics or treebank features) to support the claim of greater unit sharing.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that clarifying controls for potential confounds and providing more specifics on causal interventions will strengthen the manuscript. We address each major comment below and will incorporate revisions to improve transparency and robustness.
read point-by-point responses
-
Referee: [Methods] Methods (functional localization): The procedure selects units most responsive to sentences containing each syntactic phenomenon, but provides no explicit controls or matching for confounding variables such as sentence length, lexical predictability, or overall syntactic complexity across stimulus sets for different agreement types. If these differ systematically, the reported overlap for subject-verb, anaphor, and determiner-noun agreement could arise from shared non-syntactic features rather than a common functional category for agreement. This is load-bearing for the central claim that agreement constitutes a meaningful category.
Authors: We acknowledge the validity of this concern. Our stimulus construction aimed to isolate syntactic phenomena by using minimal pairs where possible, but we did not perform explicit matching or regression controls for sentence length, lexical predictability, or overall complexity across the full set of 67 phenomena. To address this directly, we will add supplementary analyses in the revised manuscript that include length-matched controls, perplexity-based predictability measures, and partial correlation or regression models to isolate syntactic effects. These additions will test whether the observed unit overlap for agreement types persists after accounting for non-syntactic factors. revision: yes
-
Referee: [Results] Results (causal interventions): The abstract asserts that the identified units causally support syntactic performance, yet the exact intervention technique (e.g., activation patching, ablation) and any specificity controls to distinguish agreement processing from general syntactic or semantic effects are not detailed. This leaves open whether the interventions confirm agreement-specific involvement or broader sentence-level functions.
Authors: We appreciate this observation. The manuscript describes causal interventions via targeted activation patching on the localized units, showing performance drops on agreement-related tasks. However, we agree that greater detail on the precise technique and specificity controls (e.g., comparisons to general syntactic or semantic interventions) is warranted for clarity. In the revision, we will expand the methods and results sections to fully specify the patching procedure, include control interventions on non-agreement units, and report quantitative comparisons demonstrating that effects are stronger for agreement tasks than for matched general syntactic or semantic benchmarks. revision: yes
Circularity Check
Empirical localization and overlap analysis without circular reduction
full rationale
The paper derives its claims from direct empirical procedures: measuring unit activations in response to sentences containing specific syntactic phenomena, selecting the most responsive units, and testing their causal role via interventions. Overlap among units for different agreement types is reported as an observed pattern across models and languages, not as a quantity forced by definition, a fitted parameter, or a self-citation chain. No equations or derivations reduce the central result to its inputs by construction; the functional localization is applied to open models using stimulus sets whose properties are external to the analysis itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Units identified as most responsive via the localization procedure are causally involved in syntactic processing rather than reflecting correlated but non-syntactic features.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a functional localization approach inspired by cognitive neuroscience, we identify the LLM units most responsive to 67 English syntactic phenomena... different types of syntactic agreement recruit overlapping sets of units
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify units in seven open-weight LLMs that are engaged in each of 67 syntactic phenomena, generalize across sentences containing that phenomenon, and are causally implicated in model behavior
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Fine-Grained Analysis of Shared Syntactic Mechanisms in Language Models
Language models employ a highly localized shared mechanism for filler-gap dependencies but no unified mechanism for NPI licensing, and activation patching generalizes better than supervised alignment search.
Reference graph
Works this paper leans on
-
[1]
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, and Martin Schrimpf. 2025. https://doi.org/10.18653/v1/2025.naacl-long.544 The LLM language network: A neuroscientific approach for identifying causally task-relevant units . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human...
- [2]
-
[3]
Catherine Arnett, Tyler A. Chang, James A. Michaelov, and Benjamin K. Bergen. 2025. https://arxiv.org/abs/2503.03962 On the acquisition of shared grammatical representations in bilingual language models . arXiv preprint arXiv:2503.03962
- [4]
-
[5]
Yonatan Belinkov, Llu \' s M \`a rquez, Hassan Sajjad, Nadir Durrani, Fahim Dalvi, and James Glass. 2017. Evaluating layers of representation in neural machine translation on part-of-speech and semantic tagging tasks. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1--10
work page 2017
- [6]
- [7]
-
[8]
Lyle Campbell and Ver \'o nica Grondona. 2008. Ethnologue: Languages of the world. Language, 84(3):636--641
work page 2008
-
[9]
Chi, John Hewitt, and Christopher D
Ethan A. Chi, John Hewitt, and Christopher D. Manning. 2020. https://doi.org/10.18653/v1/2020.acl-main.493 Finding universal grammatical relations in multilingual BERT . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5564--5577, Online. Association for Computational Linguistics
-
[10]
Noam Chomsky. 1981. https://doi.org/doi:10.1515/tlir.1981.1.1.3 On the representation of form and function . The Linguistic Review, 1(1):3--40
-
[11]
Chris Collins and Richard Kayne. 2011. Syntactic structures of the world’s languages
work page 2011
-
[12]
Andrea Gregor de Varda and Marco Marelli. 2023. Data-driven cross-lingual syntax: An agreement study with massively multilingual models. Computational Linguistics, 49(2):261--299
work page 2023
-
[13]
Google DeepMind. 2025. https://arxiv.org/pdf/2503.19786 Gemma 3 technical report . arXiv preprint arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Deep S eek. 2024. https://arxiv.org/abs/2401.02954 Deep S eek LLM : Scaling open-source language models with longtermism . arXiv preprint arXiv:2401.02954
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Dryer and Martin Haspelmath, editors
Matthew S. Dryer and Martin Haspelmath, editors. 2013. https://doi.org/10.5281/zenodo.13950591 WALS Online (v2020.4) . Zenodo
- [16]
- [17]
-
[18]
Evelina Fedorenko, Po-Jang Hsieh, Alfonso Nieto-Casta \ n \'o n, Susan Whitfield-Gabrieli, and Nancy Kanwisher. 2010. New method for f MRI investigations of language: defining ROI s functionally in individual subjects. Journal of neurophysiology, 104(2):1177--1194
work page 2010
-
[19]
Javier Ferrando and Marta R. Costa-juss \`a . 2024. On the similarity of circuits across languages: a case study on the subject-verb agreement task. In ICML 2024 Workshop on Mechanistic Interpretability
work page 2024
-
[20]
Richard Futrell, Ethan Wilcox, Takashi Morita, Peng Qian, Miguel Ballesteros, and Roger Levy. 2019. Neural language models as psycholinguistic subjects: Representations of syntactic state. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Sh...
work page 2019
-
[21]
Jon Gauthier, Jennifer Hu, Ethan Wilcox, Peng Qian, and Roger Levy. 2020. https://doi.org/10.18653/v1/2020.acl-demos.10 S yntax G ym: An online platform for targeted evaluation of language models . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 70--76, Online. Association for Comput...
-
[22]
Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. 2024. Finding alignments between interpretable causal variables and distributed neural representations. In Causal Learning and Reasoning, pages 160--187. PMLR
work page 2024
-
[23]
Kristina Gulordava, Piotr Bojanowski, Edouard Grave, Tal Linzen, and Marco Baroni. 2018. https://doi.org/10.18653/v1/N18-1108 Colorless green recurrent networks dream hierarchically . In Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , ...
-
[24]
Bobby He, Lorenzo Noci, Daniele Paliotta, Imanol Schlag, and Thomas Hofmann. 2024. Understanding and minimising outlier features in transformer training. Advances in Neural Information Processing Systems, 37:83786--83846
work page 2024
-
[25]
John Hewitt and Christopher D. Manning. 2019. https://doi.org/10.18653/v1/N19-1419 A structural probe for finding syntax in word representations . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4129--4138, Minneapol...
-
[26]
Huang, Kuan-Hao Huang, and Kai-Wei Chang
James Y. Huang, Kuan-Hao Huang, and Kai-Wei Chang. 2021. https://arxiv.org/abs/2104.05115 Disentangling semantics and syntax in sentence embeddings with pre-trained language models . arXiv preprint arXiv:2104.05115
-
[27]
Vo, Leila Wehbe, and Alexander G
Shailee Jain, Vy A. Vo, Leila Wehbe, and Alexander G. Huth. 2024. Computational language modeling and the promise of in silico experimentation. Neurobiology of Language, 5(1):80--106
work page 2024
-
[28]
Ganesh Jawahar, Beno \^i t Sagot, and Djam \'e Seddah. 2019. https://doi.org/10.18653/v1/P19-1356 What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651--3657, Florence, Italy. Association for Computational Linguistics
-
[29]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. https://arxiv.org/abs/2310.0...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Cameron Jones and Ben Bergen. 2024. Does GPT -4 pass the T uring test? In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5183--5210
work page 2024
-
[31]
Cameron R. Jones and Benjamin K. Bergen. 2025. https://arxiv.org/abs/2503.23674 Large language models pass the T uring test . arXiv preprint arXiv:2503.23674
-
[32]
Jaap Jumelet, Leonie Weissweiler, and Arianna Bisazza. 2025. https://arxiv.org/abs/2504.02768 Multi BL i MP 1.0: A massively multilingual benchmark of linguistic minimal pairs . arXiv preprint arXiv:2504.02768
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Yair Lakretz, Dieuwke Hupkes, Alessandra Vergallito, Marco Marelli, Marco Baroni, and Stanislas Dehaene. 2021. Mechanisms for handling nested dependencies in neural-network language models and humans. Cognition, 213:104699
work page 2021
-
[34]
Yair Lakretz, Germ \'a n Kruszewski, Th \'e o Desbordes, Dieuwke Hupkes, Stanislas Dehaene, and Marco Baroni. 2019. The emergence of number and syntax units in LSTM language models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Pap...
work page 2019
-
[35]
Lepori, Thomas Serre, and Ellie Pavlick
Michael A. Lepori, Thomas Serre, and Ellie Pavlick. 2023. Uncovering intermediate variables in transformers using circuit probing. In First Conference on Language Modeling
work page 2023
-
[36]
Tal Linzen, Emmanuel Dupoux, and Yoav Goldberg. 2016. https://doi.org/10.1162/tacl_a_00115 Assessing the ability of LSTM s to learn syntax-sensitive dependencies . Transactions of the Association for Computational Linguistics, 4:521--535
-
[37]
Mortensen, Ke Lin, Katherine Kairis, Carlisle Turner, and Lori Levin
Patrick Littell, David R. Mortensen, Ke Lin, Katherine Kairis, Carlisle Turner, and Lori Levin. 2017. Uriel and lang2vec: Representing languages as typological, geographical, and phylogenetic vectors. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 8--14
work page 2017
-
[38]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J. Michaud, Yonatan Belinkov, David Bau, and Aaron Mueller. 2024. https://arxiv.org/abs/2403.19647 Sparse feature circuits: Discovering and editing interpretable causal graphs in language models . arXiv preprint arXiv:2403.19647
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Rebecca Marvin and Tal Linzen. 2018. Targeted syntactic evaluation of language models. In 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, pages 1192--1202. Association for Computational Linguistics
work page 2018
-
[40]
Thomas McCoy, Ellie Pavlick, and Tal Linzen
R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. 2020. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. In 57th Annual Meeting of the Association for Computational Linguistics, ACL 2019, pages 3428--3448. Association for Computational Linguistics (ACL)
work page 2020
-
[41]
Meta. 2024. https://huggingface.co/blog/llama32 Llama can now see and run on your device - welcome L lama 3.2
work page 2024
-
[42]
James Michaelov, Catherine Arnett, Tyler Chang, and Ben Bergen. 2023. Structural priming demonstrates abstract grammatical representations in multilingual language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3703--3720
work page 2023
-
[43]
Microsoft. 2025. https://arxiv.org/abs/2503.01743 Phi-4-mini technical report: Compact yet powerful multimodal language models via M ixture-of- L o RA s . arXiv preprint arXiv:2503.01743
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
-
[45]
Aaron Mueller, Jannik Brinkmann, Millicent Li, Samuel Marks, Koyena Pal, Nikhil Prakash, Can Rager, Aruna Sankaranarayanan, Arnab Sen Sharma, Jiuding Sun, Eric Todd, David Bau, and Yonatan Belinkov. 2024. https://arxiv.org/abs/2408.01416 The quest for the right mediator: A history, survey, and theoretical grounding of causal interpretability . arXiv prepr...
-
[46]
Aaron Mueller, Yu Xia, and Tal Linzen. 2022. https://doi.org/10.18653/v1/2022.conll-1.8 Causal analysis of syntactic agreement neurons in multilingual language models . In Proceedings of the 26th Conference on Computational Natural Language Learning (CoNLL), pages 95--109, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics
-
[47]
Chi, Richard Futrell, and Kyle Mahowald
Isabel Papadimitriou, Ethan A. Chi, Richard Futrell, and Kyle Mahowald. 2021. https://arxiv.org/abs/2101.11043 Deep subjecthood: Higher-order grammatical features in multilingual BERT . arXiv preprint arXiv:2101.11043
-
[48]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners
work page 2019
- [49]
-
[50]
Aniketh Janardhan Reddy and Leila Wehbe. 2021. https://proceedings.neurips.cc/paper_files/paper/2021/file/51a472c08e21aef54ed749806e3e6490-Paper.pdf Can f MRI reveal the representation of syntactic structure in the brain? In Advances in Neural Information Processing Systems, volume 34, pages 9843--9856. Curran Associates, Inc
work page 2021
-
[51]
Rebecca Saxe, Matthew Brett, and Nancy Kanwisher. 2006. Divide and conquer: a defense of functional localizers. Neuroimage, 30(4):1088--1096
work page 2006
-
[52]
Yixiao Song, Kalpesh Krishna, Rajesh Bhatt, and Mohit Iyyer. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.305 SLING : S ino linguistic evaluation of large language models . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 4606--4634, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[53]
Karolina Stanczak, Edoardo Ponti, Lucas Torroba Hennigen, Ryan Cotterell, and Isabelle Augenstein. 2022. https://doi.org/10.18653/v1/2022.naacl-main.114 Same neurons, different languages: Probing morphosyntax in multilingual pre-trained models . In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Lingui...
-
[54]
Giulio Starace, Konstantinos Papakostas, Rochelle Choenni, Apostolos Panagiotopoulos, Matteo Rosati, Alina Leidinger, and Ekaterina Shutova. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.476 Probing LLM s for joint encoding of linguistic categories . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7158--7179, Singap...
-
[55]
Michelle Suijkerbuijk, Zoë Prins, Marianne de Heer Kloots, Willem Zuidema, and Stefan L. Frank. 2025. https://doi.org/10.1162/coli_a_00559 BL i MP-NL : A corpus of D utch minimal pairs and acceptability judgments for language model evaluation . Computational Linguistics, pages 1--35
-
[56]
Ekaterina Taktasheva, Maxim Bazhukov, Kirill Koncha, Alena Fenogenova, Ekaterina Artemova, and Vladislav Mikhailov. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.522 R u BL i MP : R ussian benchmark of linguistic minimal pairs . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9268--9299, Miami, Florida,...
-
[57]
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Wayne Xin Zhao, Furu Wei, and Ji-Rong Wen. 2024. Language-specific neurons: The key to multilingual capabilities in large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5701--5715
work page 2024
-
[58]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. https://doi.org/10.18653/v1/P19-1452 BERT rediscovers the classical NLP pipeline . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593--4601, Florence, Italy. Association for Computational Linguistics
-
[59]
Technology Innovation Institute (TII). 2024. https://huggingface.co/blog/falcon3 Welcome to the F alcon 3 family of open models!
work page 2024
-
[60]
Greta Tuckute, Nancy Kanwisher, and Evelina Fedorenko. 2024. Language in brains, minds, and machines. Annual Review of Neuroscience, 47(2024):277--301
work page 2024
-
[61]
Mingyang Wang, Heike Adel, Lukas Lange, Yihong Liu, Ercong Nie, Jannik Str \"o tgen, and Hinrich Sch \"u tze. 2025. https://arxiv.org/abs/2504.04264 Lost in multilinguality: Dissecting cross-lingual factual inconsistency in transformer language models . arXiv preprint arXiv:2504.04264
-
[62]
Alex Warstadt, Yu Cao, Ioana Grosu, Wei Peng, Hagen Blix, Yining Nie, Anna Alsop, Shikha Bordia, Haokun Liu, Alicia Parrish, Sheng-Fu Wang, Jason Phang, Anhad Mohananey, Phu Mon Htut, Paloma Jeretic, and Samuel R. Bowman. 2019. https://arxiv.org/abs/1909.02597 Investigating BERT 's knowledge of language: Five analysis methods with NPI s . arXiv preprint a...
-
[63]
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R. Bowman. 2020. https://doi.org/10.1162/tacl_a_00321 BL i MP : The benchmark of linguistic minimal pairs for E nglish . Transactions of the Association for Computational Linguistics, 8:377--392
-
[64]
Ethan Wilcox, Roger Levy, Takashi Morita, and Richard Futrell. 2018. What do RNN language models learn about filler-gap dependencies? In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 211--221
work page 2018
-
[65]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R \'e mi Louf, Morgan Funtowicz, and 1 others. 2019. https://arxiv.org/abs/1910.03771 Hugging F ace's transformers: State-of-the-art natural language processing . arXiv preprint arXiv:1910.03771
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[66]
Zhengxuan Wu, Atticus Geiger, Thomas Icard, Christopher Potts, and Noah Goodman. 2023. Interpretability at scale: Identifying causal mechanisms in A lpaca. Advances in neural information processing systems, 36:78205--78226
work page 2023
-
[67]
Xiaohan Zhang, Shaonan Wang, Nan Lin, Jiajun Zhang, and Chengqing Zong. 2022. https://doi.org/10.1609/aaai.v36i10.21427 Probing word syntactic representations in the brain by a feature elimination method . Proceedings of the AAAI Conference on Artificial Intelligence, 36(10):11721--11729
-
[68]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[69]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.