Beyond Flicker: Detecting Kinematic Inconsistencies for Generalizable Deepfake Video Detection
Pith reviewed 2026-05-17 01:48 UTC · model grok-4.3
The pith
Manipulating motion bases in facial landmarks creates training data that teaches detectors to spot kinematic flaws in unseen deepfakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
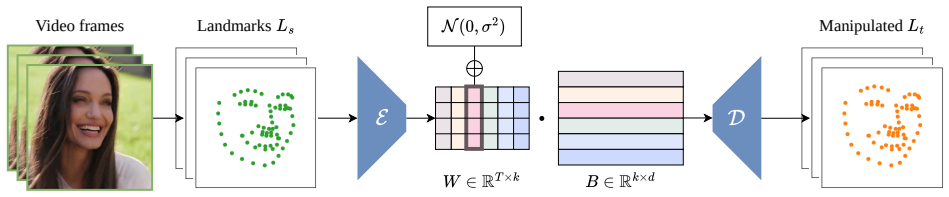
We propose a synthetic video generation method that creates training data with subtle kinematic inconsistencies. We train an autoencoder to decompose facial landmark configurations into motion bases. By manipulating these bases, we selectively break the natural correlations in facial movements and introduce these artifacts into pristine videos via face morphing. A network trained on our data learns to spot these sophisticated biomechanical flaws, achieving state-of-the-art generalization results on several popular benchmarks.
What carries the argument
Autoencoder decomposition of facial landmark configurations into motion bases that are selectively manipulated to violate natural movement correlations.
If this is right
- Detectors can be trained without any real deepfake examples yet still generalize across manipulation methods.
- The key signal shifts from low-level temporal flicker to higher-order violations of facial motion dependencies.
- Any collection of pristine videos can be turned into useful training data by applying the motion-base manipulation process.
- State-of-the-art cross-dataset results are reported on multiple standard deepfake benchmarks.
Where Pith is reading between the lines
- Real deepfake pipelines may systematically fail to reproduce the statistical dependencies that govern natural facial motion.
- The same decomposition-and-disruption technique could be tested on full-body or scene-level motion for broader video forgery detection.
- Combining kinematic inconsistency detection with existing artifact-based methods might yield still stronger generalization.
Load-bearing premise
The kinematic inconsistencies created by manipulating motion bases in pristine videos accurately simulate the motion artifacts present in real deepfake videos produced by diverse unseen methods.
What would settle it
Train the detector on the synthetic data then test it on a set of deepfake videos engineered to preserve natural motion-base correlations while still using novel manipulation pipelines; a sharp drop in detection accuracy would falsify the claim.
Figures



read the original abstract
Generalizing deepfake detection to unseen manipulations remains a key challenge. A recent approach to tackle this issue is to train a network with pristine face images that have been manipulated with hand-crafted artifacts to extract more generalizable clues. While effective for static images, extending this to the video domain is an open issue. Existing methods model temporal artifacts as frame-to-frame instabilities, overlooking a key vulnerability: the violation of natural motion dependencies between different facial regions. In this paper, we propose a synthetic video generation method that creates training data with subtle kinematic inconsistencies. We train an autoencoder to decompose facial landmark configurations into motion bases. By manipulating these bases, we selectively break the natural correlations in facial movements and introduce these artifacts into pristine videos via face morphing. A network trained on our data learns to spot these sophisticated biomechanical flaws, achieving state-of-the-art generalization results on several popular benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a synthetic video generation pipeline to improve generalization in deepfake detection. An autoencoder decomposes facial landmark configurations from pristine videos into motion bases; these bases are manipulated to break natural kinematic correlations between facial regions, and the resulting inconsistencies are inserted into real videos via face morphing. A detector trained on the resulting data is claimed to learn to detect sophisticated biomechanical flaws and achieves state-of-the-art generalization on several popular benchmarks.
Significance. If the synthetic kinematic inconsistencies are shown to be representative of motion artifacts arising in real unseen deepfake generators, the approach would offer a scalable, manipulation-agnostic route to training generalizable detectors that focuses on violation of natural motion dependencies rather than frame-level flicker. The method supplies a concrete, falsifiable mechanism for creating training signals and could be reproduced given the described autoencoder and morphing steps.
major comments (2)
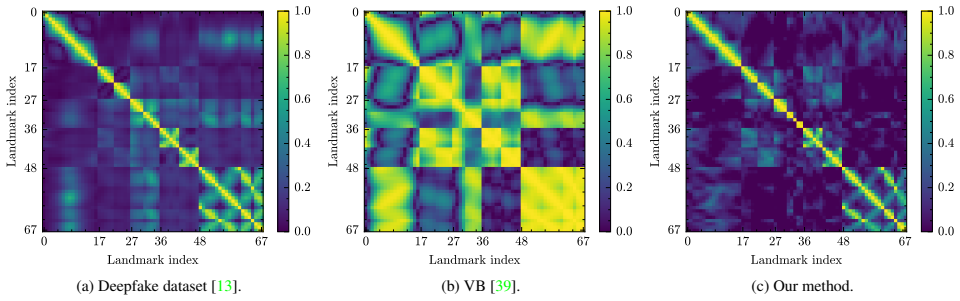
- [§3.2] §3.2 (Synthetic Data Generation): The claim that selectively breaking correlations via manipulation of autoencoder-derived motion bases produces flaws representative of those in real deepfakes from diverse unseen methods is load-bearing for the generalization result, yet the manuscript provides no distributional comparison (e.g., motion correlation statistics or feature-space distance) between the synthetic artifacts and the actual inconsistencies present in the benchmark deepfakes.
- [Table 2] Table 2 (Generalization benchmarks): The reported SOTA cross-dataset numbers rest on the assumption that the introduced kinematic flaws are the operative cues; without an ablation that removes or varies the motion-base manipulation while keeping other factors fixed, it is unclear whether the performance gain is attributable to the kinematic focus or to other aspects of the synthetic pipeline.
minor comments (2)
- [Abstract] The abstract states 'state-of-the-art generalization results' without quoting the precise metrics or the size of the improvement over the strongest baseline.
- [§3] Notation for the number of motion bases and the manipulation intensity parameter should be introduced with explicit symbols and ranges in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will revise the manuscript to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Synthetic Data Generation): The claim that selectively breaking correlations via manipulation of autoencoder-derived motion bases produces flaws representative of those in real deepfakes from diverse unseen methods is load-bearing for the generalization result, yet the manuscript provides no distributional comparison (e.g., motion correlation statistics or feature-space distance) between the synthetic artifacts and the actual inconsistencies present in the benchmark deepfakes.
Authors: We agree that a direct distributional comparison would strengthen the claim that the synthetic kinematic inconsistencies are representative of those arising in real unseen deepfakes. In the revised manuscript, we will add a quantitative analysis (e.g., in an expanded Section 3.2) comparing motion correlation statistics—specifically, pairwise velocity correlations across facial regions—between our synthetically manipulated videos and the deepfake videos in the benchmark datasets. We will report metrics such as the average absolute difference in correlation matrices and feature-space distances to demonstrate that the introduced artifacts align with real biomechanical inconsistencies. revision: yes
-
Referee: [Table 2] Table 2 (Generalization benchmarks): The reported SOTA cross-dataset numbers rest on the assumption that the introduced kinematic flaws are the operative cues; without an ablation that removes or varies the motion-base manipulation while keeping other factors fixed, it is unclear whether the performance gain is attributable to the kinematic focus or to other aspects of the synthetic pipeline.
Authors: We concur that an ablation isolating the effect of the motion-base manipulation is necessary to attribute the generalization gains specifically to the kinematic inconsistencies. In the revised manuscript, we will add an ablation study comparing the full pipeline against a control variant in which the autoencoder-derived bases are either left unmanipulated or subjected to random perturbations that do not target natural correlations, while holding the face-morphing step and all other pipeline components fixed. Generalization results on the benchmarks will be reported to confirm that the targeted correlation-breaking step is the primary driver of the observed improvements. revision: yes
Circularity Check
No circularity: synthetic data pipeline and generalization claim are independent of fitted inputs
full rationale
The paper describes a self-contained pipeline: an autoencoder is trained on facial landmarks from pristine videos to extract motion bases; these bases are then manipulated to break natural correlations and the resulting inconsistencies are inserted into pristine videos via face morphing to create synthetic training data; a detector is trained on that data and evaluated for generalization on external benchmarks. None of the claimed results (e.g., state-of-the-art generalization) reduce by construction to the inputs via self-definition, renaming of fitted quantities, or load-bearing self-citations. The central assumption that the synthetic kinematic flaws are representative is an empirical hypothesis, not a tautological equivalence, and the derivation chain remains independent of the target deepfake distributions.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of motion bases
- manipulation intensity
axioms (1)
- domain assumption Facial movements exhibit consistent natural correlations across regions that can be captured by linear or low-dimensional bases
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train an autoencoder to decompose facial landmark configurations into motion bases. By manipulating these bases, we selectively break the natural correlations in facial movements
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deepshield: Forti- fying deepfake video detection with local and global forgery analysis
Yinqi Cai, Jichang Li, Zhaolun Li, Weikai Chen, Rushi Lan, Xi Xie, Xiaonan Luo, and Guanbin Li. Deepshield: Forti- fying deepfake video detection with local and global forgery analysis. InICCV, pages 12524–12534, 2025
work page 2025
-
[2]
MARLIN: masked autoencoder for facial video rep- resentation learning
Zhixi Cai, Shreya Ghosh, Kalin Stefanov, Abhinav Dhall, Jianfei Cai, Hamid Rezatofighi, Reza Haffari, and Munawar Hayat. MARLIN: masked autoencoder for facial video rep- resentation learning. InCVPR, pages 1493–1504, 2023
work page 2023
-
[3]
End-to-end reconstruction- classification learning for face forgery detection
Junyi Cao, Chao Ma, Taiping Yao, Shen Chen, Shouhong Ding, and Xiaokang Yang. End-to-end reconstruction- classification learning for face forgery detection. InCVPR, pages 4103–4112, 2022
work page 2022
-
[4]
Liang Chen, Yong Zhang, Yibing Song, Lingqiao Liu, and Jue Wang. Self-supervised learning of adversarial exam- ple: Towards good generalizations for deepfake detection. InCVPR, pages 18689–18698, 2022
work page 2022
-
[5]
Alejandro Cobo, Roberto Valle, Jos ´e M. Buenaposada, and Luis Baumela. Spatiotemporal face alignment for generaliz- able deepfake detection. InIEEE FG, pages 1–6, 2025
work page 2025
-
[6]
Timothy F. Cootes, Gareth J. Edwards, and Christopher J. Taylor. Active appearance models.IEEE TPAMI, 23(6):681– 685, 2001
work page 2001
-
[7]
Retinaface: Single-shot multi-level face localisation in the wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. InCVPR, pages 5202–5211, 2020
work page 2020
-
[8]
Brian Dolhansky, Russell Howes, Ben Pflaum, Niv Baram, and Cristian Canton Ferrer
Brian Dolhansky, Russ Howes, Ben Pflaum, Nicole Baram, and Cristian Canton-Ferrer. The deepfake detec- tion challenge (DFDC) preview dataset.arXiv preprint, abs/1910.08854, 2019
-
[9]
Ralph Gross, Iain Matthews, Jeffrey Cohn, Takeo Kanade, and Simon Baker. Multi-pie.Image and Vis. Comput., 28(5): 807–813, 2010
work page 2010
-
[10]
Controllable guide-space for generalizable face forgery detection
Ying Guo, Cheng Zhen, and Pengfei Yan. Controllable guide-space for generalizable face forgery detection. In ICCV, pages 20761–20770, 2023
work page 2023
-
[11]
Leveraging real talking faces via self- supervision for robust forgery detection
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, and Maja Pantic. Leveraging real talking faces via self- supervision for robust forgery detection. InCVPR, pages 14930–14942, 2022
work page 2022
-
[12]
Yue-Hua Han, Tai-Ming Huang, Kai-Lung Hua, and Jun- Cheng Chen. Towards more general video-based deepfake detection through facial component guided adaptation for foundation model. InCVPR, pages 22995–23005, 2025
work page 2025
-
[13]
Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, and Chen Change Loy. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. InCVPR, pages 2886–2895, 2020
work page 2020
-
[14]
Beyond spatial frequency: Pixel-wise temporal frequency- based deepfake video detection.ICCV, 2025
Taehoon Kim, Jongwook Choi, Yonghyun Jeong, Haeun Noh, Jaejun Yoo, Seungryul Baek, and Jongwon Choi. Beyond spatial frequency: Pixel-wise temporal frequency- based deepfake video detection.ICCV, 2025
work page 2025
-
[15]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR, 2015
work page 2015
-
[16]
Seeable: Soft discrepancies and bounded contrastive learning for exposing deepfakes
Nicolas Larue, Ngoc-Son Vu, Vitomir Struc, Peter Peer, and Vassilis Christophides. Seeable: Soft discrepancies and bounded contrastive learning for exposing deepfakes. In ICCV, pages 20954–20964, 2023
work page 2023
-
[17]
Face x-ray for more general face forgery detection
Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Baining Guo. Face x-ray for more general face forgery detection. InCVPR, pages 5000–5009, 2020
work page 2020
-
[18]
Celeb-df: A large-scale challenging dataset for deep- fake forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deep- fake forensics. InCVPR, pages 3204–3213, 2020
work page 2020
-
[19]
Fakeradar: Probing forgery outliers to detect unknown deepfake videos
Zhaolun Li, Jichang Li, Yinqi Cai, Junye Chen, Xiaonan Luo, Guanbin Li, and Rushi Lan. Fakeradar: Probing forgery outliers to detect unknown deepfake videos. InICCV, 2025
work page 2025
-
[20]
Yuzhen Lin, Wentang Song, Bin Li, Yuezun Li, Jiangqun Ni, Han Chen, and Qiushi Li. Fake it till you make it: Curricu- lar dynamic forgery augmentations towards general deepfake detection. InECCV, pages 104–122, 2024
work page 2024
-
[21]
Spatial- phase shallow learning: Rethinking face forgery detection in frequency domain
Honggu Liu, Xiaodan Li, Wenbo Zhou, Yuefeng Chen, Yuan He, Hui Xue, Weiming Zhang, and Nenghai Yu. Spatial- phase shallow learning: Rethinking face forgery detection in frequency domain. InCVPR, pages 772–781, 2021
work page 2021
-
[22]
Gener- alizing face forgery detection with high-frequency features
Yuchen Luo, Yong Zhang, Junchi Yan, and Wei Liu. Gener- alizing face forgery detection with high-frequency features. InCVPR, pages 16317–16326, 2021
work page 2021
-
[23]
Dat Nguyen, Marcella Astrid, Anis Kacem, Enjie Ghorbel, and Djamila Aouada. Vulnerability-aware spatio-temporal learning for generalizable and interpretable deepfake video detection. InICCV, 2025
work page 2025
-
[24]
Shape preserving facial landmarks with graph attention networks
Andr ´es Prados-Torreblanca, Jos´e Miguel Buenaposada, and Luis Baumela. Shape preserving facial landmarks with graph attention networks. InBMVC, 2022
work page 2022
-
[25]
Thinking in frequency: Face forgery detection by min- ing frequency-aware clues
Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. Thinking in frequency: Face forgery detection by min- ing frequency-aware clues. InECCV, pages 86–103, 2020
work page 2020
-
[26]
Google Research. Contributing data to deepfake de- tection research.https://research.google/ blog/contributing-data-to-deepfake- detection-research/, 2019. Accessed: 2025-10-04
work page 2019
-
[27]
Faceforen- sics++: Learning to detect manipulated facial images
Andreas R ¨ossler, Davide Cozzolino, Luisa Verdoliva, Chris- tian Riess, Justus Thies, and Matthias Nießner. Faceforen- sics++: Learning to detect manipulated facial images. In ICCV, pages 1–11, 2019
work page 2019
-
[28]
Deepfake-adapter: Dual-level adapter for deepfake detec- tion.IJCV, 133(6):3613–3628, 2025
Rui Shao, Tianxing Wu, Liqiang Nie, and Ziwei Liu. Deepfake-adapter: Dual-level adapter for deepfake detec- tion.IJCV, 133(6):3613–3628, 2025
work page 2025
-
[29]
Detecting deep- fakes with self-blended images
Kaede Shiohara and Toshihiko Yamasaki. Detecting deep- fakes with self-blended images. InCVPR, pages 18699– 18708, 2022
work page 2022
-
[30]
De- ferred neural rendering: image synthesis using neural tex- tures.ACM TOG, 38(4):66:1–66:12, 2019
Justus Thies, Michael Zollh ¨ofer, and Matthias Nießner. De- ferred neural rendering: image synthesis using neural tex- tures.ACM TOG, 38(4):66:1–66:12, 2019
work page 2019
-
[31]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, pages 5998–6008, 2017
work page 2017
-
[32]
Gaojian Wang, Feng Lin, Tong Wu, Zhenguang Liu, Zhongjie Ba, and Kui Ren. FSFM: A generalizable face se- curity foundation model via self-supervised facial represen- tation learning. InCVPR, pages 24364–24376, 2025. 9
work page 2025
-
[33]
Altfreezing for more general video face forgery detection
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, and Houqiang Li. Altfreezing for more general video face forgery detection. InCVPR, pages 4129–4138, 2023
work page 2023
-
[34]
TALL: thumbnail layout for deepfake video detection
Yuting Xu, Jian Liang, Gengyun Jia, Ziming Yang, Yanhao Zhang, and Ran He. TALL: thumbnail layout for deepfake video detection. InICCV, pages 22601–22611, 2023
work page 2023
-
[35]
UCF: uncovering common features for generalizable deep- fake detection
Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. UCF: uncovering common features for generalizable deep- fake detection. InICCV, pages 22355–22366, 2023
work page 2023
-
[36]
Transcending forgery specificity with latent space augmentation for generalizable deepfake detection
Zhiyuan Yan, Yuhao Luo, Siwei Lyu, Qingshan Liu, and Baoyuan Wu. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. In CVPR, pages 8984–8994, 2024
work page 2024
-
[37]
DF40: toward next-generation deepfake detection
Zhiyuan Yan, Taiping Yao, Shen Chen, Yandan Zhao, Xinghe Fu, Junwei Zhu, Donghao Luo, Chengjie Wang, Shouhong Ding, Yunsheng Wu, and Li Yuan. DF40: toward next-generation deepfake detection. InNeurIPS, 2024
work page 2024
-
[38]
Orthogonal subspace decom- position for generalizable AI-generated image detection
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Orthogonal subspace decom- position for generalizable AI-generated image detection. In ICML, 2025
work page 2025
-
[39]
Zhiyuan Yan, Yandan Zhao, Shen Chen, Mingyi Guo, Xinghe Fu, Taiping Yao, Shouhong Ding, Yunsheng Wu, and Li Yuan. Generalizing deepfake video detection with plug- and-play: Video-level blending and spatiotemporal adapter tuning. InCVPR, pages 12615–12625, 2025
work page 2025
-
[40]
Multi-attentional deep- fake detection
Hanqing Zhao, Wenbo Zhou, Dongdong Chen, Tianyi Wei, Weiming Zhang, and Nenghai Yu. Multi-attentional deep- fake detection. InCVPR, pages 2185–2194, 2021
work page 2021
-
[41]
Exploring temporal coherence for more general video face forgery detection
Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, and Fang Wen. Exploring temporal coherence for more general video face forgery detection. InICCV, pages 15024–15034, 2021
work page 2021
-
[42]
Celebv- hq: A large-scale video facial attributes dataset
Hao Zhu, Wayne Wu, Wentao Zhu, Liming Jiang, Siwei Tang, Li Zhang, Ziwei Liu, and Chen Change Loy. Celebv- hq: A large-scale video facial attributes dataset. InECCV, pages 650–667, 2022
work page 2022
-
[43]
Wilddeepfake: A challenging real-world dataset for deepfake detection
Bojia Zi, Minghao Chang, Jingjing Chen, Xingjun Ma, and Yu-Gang Jiang. Wilddeepfake: A challenging real-world dataset for deepfake detection. InACM MM, pages 2382– 2390, 2020. 10
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.