Bandwidth-constrained Variational Message Encoding for Cooperative Multi-agent Reinforcement Learning
Pith reviewed 2026-05-16 22:43 UTC · model grok-4.3
The pith
Variational message encoding lets multi-agent RL teams coordinate with 67 to 83 percent fewer message dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BVME models each message as a sample drawn from a learned Gaussian posterior that is regularized by KL divergence to an uninformative prior, thereby enforcing bandwidth constraints directly on the representations used for action selection while retaining a principled mechanism to trade off compression strength against information loss.
What carries the argument
The BVME module, which encodes messages as draws from variational Gaussian posteriors regularized by KL divergence to a prior to enforce tunable compression on coordination-critical signals.
If this is right
- Comparable or superior performance holds while using 67-83 percent fewer message dimensions on SMAC and MPE benchmarks.
- The largest gains occur on sparse communication graphs where message quality most strongly affects coordination.
- Performance sensitivity to bandwidth exhibits a U-shape, with BVME excelling at extreme compression ratios while adding only minimal overhead.
Where Pith is reading between the lines
- The same variational regularization could be applied to other resource-limited multi-agent settings such as energy-constrained robot swarms.
- Dynamic adjustment of the KL weight might allow agents to adapt compression strength on the fly as network conditions change.
- The method suggests that explicit variational control over message content could be combined with learned graph structures to produce fully adaptive communication protocols.
Load-bearing premise
That sampling messages from the learned Gaussian posteriors with KL regularization to an uninformative prior retains the coordination-critical information without introducing systematic biases that degrade performance at the tested bandwidth ratios.
What would settle it
Running the same agents and environments with the KL term removed or with bandwidth ratios pushed beyond the reported extremes and observing whether BVME performance collapses to match or fall below naive dimensionality reduction.
Figures






read the original abstract
Graph-based multi-agent reinforcement learning (MARL) enables coordinated behavior under partial observability by modeling agents as nodes and communication links as edges. While recent methods excel at learning sparse coordination graphs-determining who communicates with whom-they do not address what information should be transmitted under hard bandwidth constraints. We study this bandwidth-limited regime and show that naive dimensionality reduction consistently degrades coordination performance. Hard bandwidth constraints force selective encoding, but deterministic projections lack mechanisms to control how compression occurs. We introduce Bandwidth-constrained Variational Message Encoding (BVME), a lightweight module that treats messages as samples from learned Gaussian posteriors regularized via KL divergence to an uninformative prior. BVME's variational framework provides principled, tunable control over compression strength through interpretable hyperparameters, directly constraining the representations used for decision-making. Across SMACv1, SMACv2, and MPE benchmarks, BVME achieves comparable or superior performance while using 67--83% fewer message dimensions, with gains most pronounced on sparse graphs where message quality critically impacts coordination. Ablations reveal U-shaped sensitivity to bandwidth, with BVME excelling at extreme ratios while adding minimal overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bandwidth-constrained Variational Message Encoding (BVME), a lightweight variational module for graph-based cooperative MARL. Messages are modeled as samples from learned Gaussian posteriors regularized by KL divergence to an uninformative prior, providing tunable control over compression under hard bandwidth constraints. The central empirical claim is that BVME achieves comparable or superior performance to baselines on SMACv1, SMACv2, and MPE benchmarks while using 67-83% fewer message dimensions, with largest gains on sparse graphs, and exhibits U-shaped sensitivity to bandwidth ratios.
Significance. If the results hold under more rigorous evaluation, the work fills a practical gap in MARL communication by supplying a principled, hyperparameter-tunable mechanism for selective message compression rather than relying on deterministic projections or full-dimensional transmission. The variational formulation offers interpretable control that could translate to resource-constrained deployments, and the benchmark coverage across SMAC variants and MPE provides a reasonable testbed for coordination under partial observability.
major comments (3)
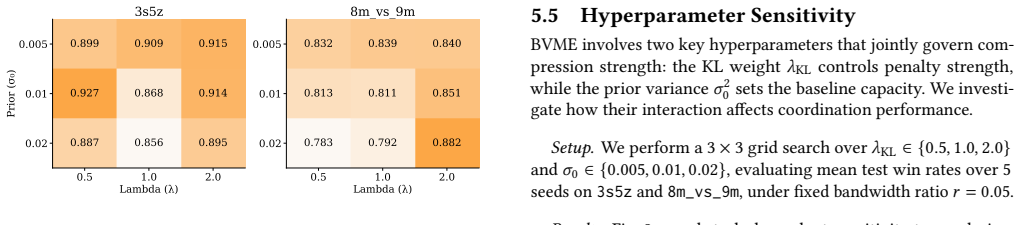
- [§5] Experimental results (throughout §5 and associated tables/figures): performance improvements are reported without error bars, statistical significance tests, exact hyperparameter values, or complete ablation controls, leaving the headline claim of comparable/superior results at 67-83% dimension reduction only moderately supported.
- [§3.2] §3.2 (BVME formulation): the claim that sampling from the learned N(μ,σ) posteriors with KL regularization selectively preserves coordination-critical information lacks direct verification; no mutual-information or value-prediction correlation metrics are provided between compressed messages and joint action-value estimates, so it remains possible that observed gains arise from the regularizing effect of the KL term rather than bandwidth-aware encoding.
- [Ablation studies] Ablation studies on bandwidth sensitivity: the reported U-shaped curve is presented without controls that isolate the variational compression mechanism from generic regularization, undermining attribution of the extreme-ratio gains specifically to the bandwidth-constrained encoding rather than to the added KL penalty.
minor comments (2)
- [Abstract] Abstract and §4: the phrase 'minimal overhead' is used without any reported FLOPs, wall-clock time, or parameter-count comparison relative to the baseline message encoders.
- [§3] Notation in §3: the precise definition of the bandwidth ratio hyperparameter and its mapping to the posterior variance schedule should be stated explicitly rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that the experimental presentation requires strengthening with statistical rigor and additional controls. Below we respond point-by-point and outline the revisions we will make to address the concerns while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [§5] Experimental results (throughout §5 and associated tables/figures): performance improvements are reported without error bars, statistical significance tests, exact hyperparameter values, or complete ablation controls, leaving the headline claim of comparable/superior results at 67-83% dimension reduction only moderately supported.
Authors: We acknowledge this limitation in the current manuscript. The experiments were run with multiple seeds, but error bars, significance tests, and full hyperparameter tables were omitted from the main text and appendix for brevity. In the revised version we will add mean and standard deviation over at least 5 random seeds for all reported curves and tables, include paired statistical tests (e.g., Welch’s t-test) between BVME and baselines at each bandwidth ratio, and provide a complete hyperparameter appendix. These additions will directly strengthen the empirical claims. revision: yes
-
Referee: [§3.2] §3.2 (BVME formulation): the claim that sampling from the learned N(μ,σ) posteriors with KL regularization selectively preserves coordination-critical information lacks direct verification; no mutual-information or value-prediction correlation metrics are provided between compressed messages and joint action-value estimates, so it remains possible that observed gains arise from the regularizing effect of the KL term rather than bandwidth-aware encoding.
Authors: We agree that direct verification via mutual information or correlation with joint action-value estimates would strengthen the mechanistic claim. The original submission relied on end-to-end performance under explicit bandwidth constraints as the primary evidence. In revision we will add a post-hoc analysis computing (i) mutual information between sampled messages and the centralized critic’s value estimates and (ii) correlation between message dimensionality and value-prediction error on held-out trajectories. This will help separate the selective-encoding effect from generic regularization. revision: yes
-
Referee: [Ablation studies] Ablation studies on bandwidth sensitivity: the reported U-shaped curve is presented without controls that isolate the variational compression mechanism from generic regularization, undermining attribution of the extreme-ratio gains specifically to the bandwidth-constrained encoding rather than to the added KL penalty.
Authors: We accept the critique. The current ablations demonstrate the U-shaped bandwidth sensitivity but do not include a control that applies KL regularization without the Gaussian sampling and dimensionality constraint. In the revised manuscript we will add an ablation that trains a non-variational message encoder with an equivalent KL penalty term (but fixed full-dimensional messages) and compare its performance to BVME across the same bandwidth ratios. This will isolate the contribution of the bandwidth-constrained variational mechanism. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmark evaluation
full rationale
The paper defines BVME as a variational module sampling messages from learned Gaussian posteriors with KL regularization to an uninformative prior, then reports empirical results on SMACv1/SMACv2/MPE showing comparable or superior performance at 67-83% fewer dimensions. No load-bearing step reduces a prediction to a fitted parameter by construction, invokes self-citation for uniqueness, or renames a known result as a derivation. The central claims are falsifiable via public benchmarks rather than tautological with the method's own equations or hyperparameters.
Axiom & Free-Parameter Ledger
free parameters (2)
- KL divergence weight
- bandwidth ratio
axioms (2)
- domain assumption Message content relevant to coordination can be captured by parameters of a Gaussian distribution
- domain assumption KL regularization to an uninformative prior yields useful compression without destroying coordination signals
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
treats messages as samples from learned Gaussian posteriors regularized via KL divergence to an uninformative prior... KL(p_i(z) || q) with q(z)=N(0, σ₀²I)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
U-shaped sensitivity to bandwidth... on-path coupling... tunable control via r, σ₀, λ_KL
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stav Belogolovsky, Eran Iceland, Itay Naeh, Ariel Barel, and Shie Mannor. 2025. Interpretable Multi-Agent Communication via Information Gating. InICML 2025 Workshop on Collaborative and Federated Agentic Workflows
work page 2025
-
[2]
Wendelin Böhmer, Vitaly Kurin, and Shimon Whiteson. 2020. Deep Coordination Graphs. InInternational Conference on Machine Learning (ICML), Vol. 119. PMLR, 980–991
work page 2020
-
[3]
Abhishek Das, Théophile Gervet, Joshua Romoff, Dhruv Batra, Devi Parikh, Mike Rabbat, and Joelle Pineau. 2019. TarMAC: Targeted Multi-Agent Communication. InInternational Conference on Machine Learning (ICML). PMLR, 1538–1546
work page 2019
-
[4]
Shifei Ding, Wei Du, Ling Ding, Jian Zhang, Lili Guo, and Bo An. 2024. Robust Multi-Agent Communication With Graph Information Bottleneck Optimization. IEEE Transactions on Pattern Analysis and Machine Intelligence46, 5 (2024), 3096–
work page 2024
-
[5]
https://doi.org/10.1109/TPAMI.2023.3337534
-
[6]
Wei Duan, Jie Lu, Yu Guang Wang, and Junyu Xuan. 2024. Layer-diverse Negative Sampling for Graph Neural Networks.Transactions on Machine Learning Research (2024)
work page 2024
-
[7]
Wei Duan, Jie Lu, and Junyu Xuan. 2024. Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning. InProceedings of the Thirty-Third Interna- tional Joint Conference on Artificial Intelligence, (IJCAI 2024), Jeju, South Korea, August 3-9, 2024. 3926–3934
work page 2024
-
[8]
Wei Duan, Jie Lu, and Junyu Xuan. 2025. Bayesian Ego-graph inference for Networked Multi-Agent Reinforcement Learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NIPS 2025)
work page 2025
-
[9]
Wei Duan, Jie Lu, and Junyu Xuan. 2025. Inferring Latent Temporal Sparse Coordination Graph for Multiagent Reinforcement Learning.IEEE Transactions on Neural Networks and Learning Systems36, 8 (2025), 14358–14370. https: //doi.org/10.1109/TNNLS.2024.3513402
-
[10]
Wei Duan, Junyu Xuan, Maoying Qiao, and Jie Lu. 2022. Learning from the Dark: Boosting Graph Convolutional Neural Networks with Diverse Negative Samples. InThirty-Sixth AAAI Conference on Artificial Intelligence (AAAI 2022), Virtual Event. AAAI Press, 6550–6558
work page 2022
-
[11]
Wei Duan, Junyu Xuan, Maoying Qiao, and Jie Lu. 2024. Graph Convolutional Neural Networks With Diverse Negative Samples via Decomposed Determinant Point Processes.IEEE Transactions on Neural Networks and Learning Systems35, 12 (2024), 18160–18171. https://doi.org/10.1109/TNNLS.2023.3312307
-
[12]
Benjamin Ellis, Jonathan Cook, Skander Moalla, Mikayel Samvelyan, Mingfei Sun, Anuj Mahajan, Jakob N. Foerster, and Shimon Whiteson. 2023. SMACv2: An Improved Benchmark for Cooperative Multi-Agent Reinforcement Learning. InThe 36th Annual Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, December 10 - 16
work page 2023
-
[13]
Jakob Foerster, Ioannis Alexandros Assael, Nando de Freitas, and Shimon White- son. 2016. Learning to Communicate with Deep Multi-Agent Reinforcement Learning. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 29
work page 2016
-
[14]
Shengchao He, Hongzhi Ni, Jianhao Wang, Luo Wu, and Chongjie Zhang. 2024. Learning Multi-Agent Communication from Graph Modeling Perspective. In International Conference on Learning Representations (ICLR)
work page 2024
-
[15]
Shariq Iqbal and Fei Sha. 2019. Actor-Attention-Critic for Multi-Agent Reinforce- ment Learning. InInternational Conference on Machine Learning (ICML). PMLR, 2961–2970
work page 2019
-
[16]
Jiechuan Jiang, Chen Dun, Tiejun Huang, and Zongqing Lu. 2020. Graph Convo- lutional Reinforcement Learning. InInternational Conference on Learning Repre- sentations (ICLR)
work page 2020
-
[17]
Jiechuan Jiang and Zongqing Lu. 2018. Learning Attentional Communication for Multi-Agent Cooperation. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 31
work page 2018
-
[18]
Daewoo Kim, Sangwoo Moon, David Hostallero, Wan Ju Kang, Taeyoung Lee, Kyunghwan Son, and Yung Yi. 2019. Learning to Schedule Communication in Multi-agent Reinforcement Learning. In7th International Conference on Learning Representations, ICLR 2019
work page 2019
-
[19]
Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings
work page 2014
-
[20]
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net
work page 2017
-
[21]
Sheng Li, Jayesh K. Gupta, Peter Morales, Ross E. Allen, and Mykel J. Kochen- derfer. 2021. Deep Implicit Coordination Graphs for Multi-agent Reinforcement Learning. InAAMAS ’21: 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021), Virtual Event, United Kingdom. ACM, 764–772
work page 2021
-
[22]
Xiangyu Liu and Kaiqing Bai. 2023. Partially Observable Multi-agent RL with (Quasi-)Efficiency: The Blessing of Information Sharing. InInternational Confer- ence on Machine Learning (ICML). PMLR, 22106–22130
work page 2023
-
[23]
Yong Liu, Weixun Wang, Yujing Hu, Jianye Hao, Xingguo Chen, and Yang Gao
-
[24]
In The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA,
Multi-Agent Game Abstraction via Graph Attention Neural Network. In The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA,. AAAI Press, 7211–7218
work page 2020
-
[25]
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. 2017. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In The 30th Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. 6379–6390
work page 2017
-
[26]
Hangyu Mao, Zhengchao Zhang, Zhen Xiao, Zhibo Gong, and Yan Ni. 2020. Learning Agent Communication under Limited Bandwidth by Message Pruning. InThe Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advance...
work page 2020
-
[27]
Oliehoek and Christopher Amato
Frans A. Oliehoek and Christopher Amato. 2016.A Concise Introduction to Decentralized POMDPs. Springer
work page 2016
-
[28]
Thomy Phan, Fabian Ritz, Lenz Belzner, Philipp Altmann, Thomas Gabor, and Claudia Linnhoff-Popien. 2021. VAST: Value Function Factorization with Variable Agent Sub-Teams. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems (NIPS 2021), December 6-14, virtual. 24018–24032
work page 2021
-
[29]
Tabish Rashid, Mikayel Samvelyan, Christian Schröder de Witt, Gregory Farquhar, Jakob N. Foerster, and Shimon Whiteson. 2018. QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. InProceedings of the 35th International Conference on Machine Learning (ICML 2018), Stockholmsmässan, Stockholm, Sweden, Vol. 80. 4292–4301
work page 2018
-
[30]
Mikayel Samvelyan, Tabish Rashid, Christian Schröder de Witt, Gregory Far- quhar, Nantas Nardelli, Tim G. J. Rudner, Chia-Man Hung, Philip H. S. Torr, Jakob N. Foerster, and Shimon Whiteson. 2019. The StarCraft Multi-Agent Chal- lenge. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS 2019), Montreal, QC...
work page 2019
-
[31]
Jianzhun Shao, Yao Lou, Hongchang Zhou, Shuncheng Jiang, and Xiangyang Ji
-
[32]
In International Conference on Machine Learning (ICML)
Complementary Attention for Multi-Agent Reinforcement Learning. In International Conference on Machine Learning (ICML). PMLR, 30780–30797
-
[33]
Amanpreet Singh, Tushar Jain, and Sainbayar Sukhbaatar. 2019. Learning when to Communicate at Scale in Multiagent Cooperative and Competitive Tasks. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net
work page 2019
-
[34]
Sainbayar Sukhbaatar, Rob Fergus, et al. 2016. Learning Multiagent Communica- tion with Backpropagation. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 29
work page 2016
-
[35]
Leibo, Karl Tuyls, and Thore Graepel
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech Marian Czarnecki, Viní- cius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. 2018. Value-Decomposition Networks For Cooperative Multi-Agent Learning Based On Team Reward. InProceedings of the 17th International Conference on Autonomous Agents...
work page 2018
-
[36]
Naftali Tishby, Fernando C Pereira, and William Bialek. 2000. The information bottleneck method.arXiv preprint physics/0004057(2000)
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[37]
Varela, Alberto Sardinha, and Francisco S
Guilherme S. Varela, Alberto Sardinha, and Francisco S. Melo. 2025. Networked Agents in the Dark: Team Value Learning under Partial Observability. InProceed- ings of the 24th International Conference on Autonomous Agents and Multiagent Systems, AAMAS 2025, Detroit, MI, USA, May 19-23, 2025. International Foundation for Autonomous Agents and Multiagent Sys...
work page 2025
-
[38]
Anthony Wang, Songyuan Peng, Vijay Kumar, and Alejandro Ribeiro. 2024. Graph Neural Network-based Multi-agent Reinforcement Learning for Resilient Dis- tributed Coordination of Multi-Robot Systems. InIEEE International Conference on Robotics and Automation (ICRA)
work page 2024
-
[39]
Tonghan Wang, Jianhao Wang, Chongyi Zheng, and Chongjie Zhang. 2020. Learn- ing Nearly Decomposable Value Functions Via Communication Minimization. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net
work page 2020
-
[40]
Jannis Weil, Zhenghua Bao, Osama Abboud, and Tobias Meuser. 2024. Towards Generalizability of Multi-Agent Reinforcement Learning in Graphs with Re- current Message Passing. InProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, (AAMAS 2024), Auckland, New Zealand, May 6-10, 2024. 1919–1927
work page 2024
-
[41]
Qianlan Yang, Weijun Dong, Zhizhou Ren, Jianhao Wang, Tonghan Wang, and Chongjie Zhang. 2022. Self-Organized Polynomial-Time Coordination Graphs. In International Conference on Machine Learning (ICML 2022), Baltimore, Maryland, USA (Proceedings of Machine Learning Research, Vol. 162). PMLR, 24963–24979
work page 2022
-
[42]
Xiaoyu Yang, Jie Lu, and En Yu. 2025. Adapting Multi-modal Large Language Model to Concept Drift From Pre-training Onwards. InThe Thirteenth Interna- tional Conference on Learning Representations. https://openreview.net/forum?id= b20VK2GnSs
work page 2025
-
[43]
Xiaoyu Yang, Jie Lu, and En Yu. 2025. Walking the Tightrope: Autonomous Disentangling Beneficial and Detrimental Drifts in Non-Stationary Custom- Tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=1BAiQmAFsx
work page 2025
- [44]
-
[45]
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre M. Bayen, and Yi Wu. 2022. The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022
work page 2022
- [46]
-
[47]
En Yu, Jie Lu, Xiaoyu Yang, Guangquan Zhang, and Zhen Fang. 2025. Learning Robust Spectral Dynamics for Temporal Domain Generalization. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems
work page 2025
-
[48]
Ziluo Zhang, Tiejun Zhao, and Chongjie Meng. 2024. Multi-Agent Coordination via Multi-Level Communication. InAdvances in Neural Information Processing Systems (NeurIPS). A CLOSED-FORM KL DIVERGENCE DERIV ATION We derive the closed-form expression for the diagonal Gaussian KL divergence used in BVME (Eq. 13). General multivariate Gaussian KL.For a 𝑘-dimens...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.