DFedReweighting: A Unified Framework for Objective-Oriented Reweighting in Decentralized Federated Learning
Pith reviewed 2026-05-16 22:30 UTC · model grok-4.3
The pith
DFedReweighting reweights client contributions in each round of decentralized federated learning by first scoring them on a target performance metric evaluated on local auxiliary data and then applying a customized refinement strategy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
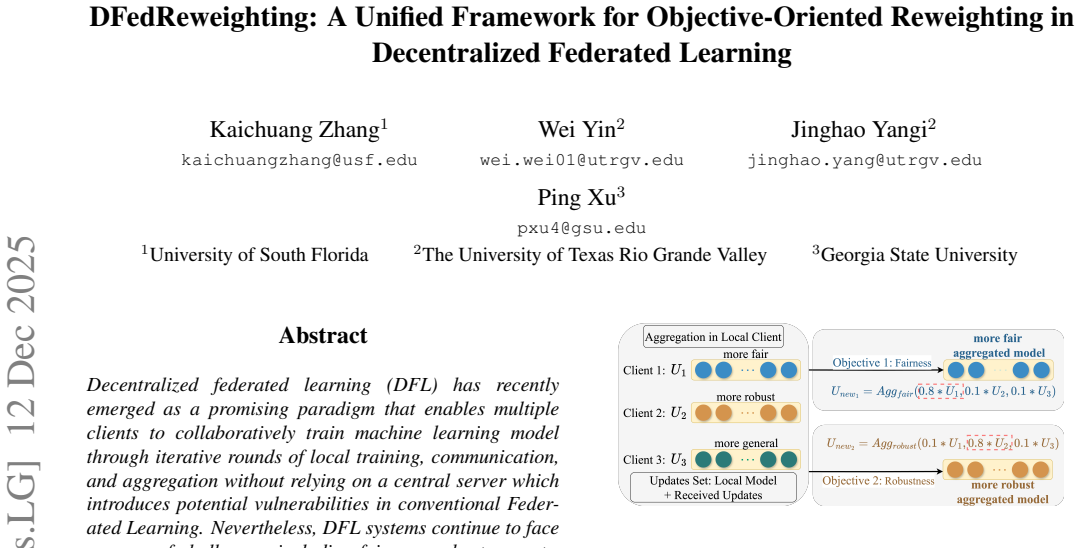
DFedReweighting evaluates a target performance metric on a compact auxiliary dataset constructed from each client's local data to obtain preliminary aggregation weights, then refines those weights with a customized reweighting strategy to produce the final weights; an appropriate combination of the metric and strategy guarantees linear convergence for general L-smooth and strongly convex functions while delivering improved fairness and Byzantine robustness.
What carries the argument
The TPM-CRS pair: a target performance metric (TPM) computed on a compact local auxiliary dataset that yields preliminary weights, followed by a customized reweighting strategy (CRS) that adjusts them into the final aggregation weights.
If this is right
- Fairness across clients improves by down-weighting those whose local models perform poorly on the chosen metric.
- Robustness to Byzantine clients increases because malicious updates receive low weights after the refinement step.
- A wide range of objectives can be realized simply by selecting different target metrics and reweighting rules.
- Linear convergence holds for any L-smooth strongly convex loss once the metric and strategy satisfy the stated compatibility condition.
Where Pith is reading between the lines
- The same auxiliary-dataset approach might allow reweighting rules to be adapted on the fly when client data distributions shift.
- The framework could be combined with existing decentralized averaging methods to add objective-oriented control without redesigning the communication pattern.
- If the auxiliary dataset is kept private, the method may preserve more data locality than approaches that require sharing validation sets.
Load-bearing premise
Each client can form a compact auxiliary dataset from its local data that is representative enough for the chosen performance metric to generate useful preliminary weights.
What would settle it
Demonstration that the proposed TPM-CRS pair fails to produce linear convergence on an L-smooth strongly convex problem, or that fairness and robustness gains disappear when the auxiliary dataset is replaced by a non-representative sample.
Figures


read the original abstract
Decentralized federated learning (DFL) has emerged as a promising paradigm that enables multiple clients to collaboratively train machine learning models through iterative rounds of local training, communication, and aggregation, without relying on a central server. Nevertheless, DFL systems continue to face a range of challenges, including fairness and Byantine robustness. To address these challenges, we propose \textbf{DFedReweighting}, a unified aggregation framework that achieves diverse learning objectives in DFL via objective-oriented reweighting at the final step of each learning round. Specifically, for each client, the framework first evaluates a target performance metric (TPM) on a compact auxiliary dataset constructed from local data, yielding preliminary aggregation weights, which are subsequently refined by a customized reweighting strategy (CRS) to produce the final aggregation weights. Theoretically, we prove that an appropriate TPM-CRS combination guarantees linear convergence for general $L$-smoothand strongly convex functions. Empirical results consistently demonstrate that \textbf{DFedReweighting} significantly improves fairness and robustness against Byzantine attacks across diverse settings. Two multi-objective examples, spanning tasks across and within clients, further establish that a broad range of desired learning objectives can be accommodated by appropriately designing the TPM and CRS. Our code is available at https://github.com/KaichuangZhang/DFedReweighting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DFedReweighting, a unified aggregation framework for decentralized federated learning that computes preliminary weights by evaluating a target performance metric (TPM) on a compact auxiliary dataset constructed from each client's local data, then refines them via a customized reweighting strategy (CRS) to achieve diverse objectives such as fairness and Byzantine robustness. It claims a linear convergence guarantee for L-smooth and strongly convex objectives under appropriate TPM-CRS pairs, supported by empirical results across settings and two multi-objective examples; code is released.
Significance. If the convergence result holds with the stated assumptions, the framework provides a flexible, objective-oriented mechanism for handling fairness and security in serverless DFL, extending beyond standard averaging. The explicit code release and multi-objective examples are strengths that support reproducibility and generality.
major comments (1)
- [Abstract and theoretical analysis section] Abstract and theoretical analysis section: the linear convergence claim for general L-smooth and strongly convex functions relies on the TPM evaluated on the compact auxiliary dataset producing weights whose effect yields a contraction mapping. No quantitative bound is given on the deviation between these weights and those obtained from the full local data distribution, nor on the auxiliary dataset construction (size, sampling) needed to control the error under heterogeneity; this approximation error is load-bearing for the contraction and is not addressed in the proof sketch.
minor comments (2)
- [Abstract] Abstract: 'L-smoothand' is missing a space.
- [Method description] The description of how the compact auxiliary dataset is constructed from local data (e.g., sampling method, size relative to local dataset) is insufficiently detailed for readers to assess representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical analysis. We agree that the approximation error from the auxiliary dataset must be rigorously bounded to support the linear convergence claim and will revise the proof accordingly.
read point-by-point responses
-
Referee: [Abstract and theoretical analysis section] Abstract and theoretical analysis section: the linear convergence claim for general L-smooth and strongly convex functions relies on the TPM evaluated on the compact auxiliary dataset producing weights whose effect yields a contraction mapping. No quantitative bound is given on the deviation between these weights and those obtained from the full local data distribution, nor on the auxiliary dataset construction (size, sampling) needed to control the error under heterogeneity; this approximation error is load-bearing for the contraction and is not addressed in the proof sketch.
Authors: We agree that a quantitative bound on the approximation error is necessary for a complete proof. In the revised version, we will augment the theoretical analysis section with an explicit error bound between the TPM weights computed on the compact auxiliary dataset and those on the full local data distribution. Under the L-smooth and strongly convex assumptions, we will apply standard concentration inequalities (e.g., Hoeffding or Bernstein) to control the deviation as a function of auxiliary dataset size and heterogeneity level. The auxiliary dataset construction will be specified as uniform random sampling without replacement, with a minimum size requirement (scaling logarithmically with the number of clients and inversely with the desired error tolerance) to ensure the total error term remains smaller than the contraction factor, thereby preserving the linear convergence rate up to a controllable additive constant. This analysis will be added to the proof sketch and supported by a new lemma. revision: yes
Circularity Check
No circularity: theoretical convergence proof is independent of fitted inputs or self-referential definitions
full rationale
The paper's central claim is a theoretical proof that an appropriate TPM-CRS pair guarantees linear convergence for L-smooth strongly convex objectives. The abstract and description present this as a separate analysis with no equations shown that reduce the contraction mapping to a fitted parameter, self-citation chain, or definition by construction. The auxiliary dataset is stated as an assumption for constructing preliminary weights, but the convergence result is not shown to be forced by that construction or by renaming prior results. No load-bearing self-citation or ansatz smuggling is evident in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Objective functions are L-smooth and strongly convex
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theoretically, we prove that an appropriate TPM-CRS combination guarantees linear convergence for general L-smooth and strongly convex functions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DFedReweighting employs the objective-oriented reweighting aggregation defined in Equation (5)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mda: Availability-aware federated learning client selection.arXiv preprint arXiv:2211.14391, 2022
Amin Eslami Abyane, Steve Drew, and Hadi Hemmati. Mda: Availability-aware federated learning client selection.arXiv preprint arXiv:2211.14391, 2022. 3
-
[2]
Federated learning under arbitrary communication patterns
Dmitrii Avdiukhin and Shiva Kasiviswanathan. Federated learning under arbitrary communication patterns. InInter- national Conference on Machine Learning, pages 425–435. PMLR, 2021. 5, 1
work page 2021
-
[3]
Gilad Baruch, Moran Baruch, and Yoav Goldberg. A lit- tle is enough: Circumventing defenses for distributed learn- ing.Advances in Neural Information Processing Systems, 32, 2019. 8 Figure 3.Different TPM-CRS combinations lead to different final performance on Byzantine attack robustness (same problem).The first combination (TPM: Loss, CRS: Equation (17))...
work page 2019
-
[4]
Peva Blanchard, El Mahdi El Mhamdi, Rachid Guerraoui, and Julien Stainer. Machine learning with adversaries: Byzantine tolerant gradient descent.Advances in Neural In- formation Processing Systems, 30, 2017. 8
work page 2017
-
[5]
Expanding the Reach of Federated Learning by Reducing Client Resource Requirements
Sebastian Caldas, Jakub Kone ˇcny, H Brendan McMahan, and Ameet Talwalkar. Expanding the reach of federated learning by reducing client resource requirements.arXiv preprint arXiv:1812.07210, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Robust blockchained federated learning with model validation and proof-of-stake inspired consensus
Hang Chen, Syed Ali Asif, Jihong Park, Chien-Chung Shen, and Mehdi Bennis. Robust blockchained federated learning with model validation and proof-of-stake inspired consensus. arXiv preprint arXiv:2101.03300, 2021. 1
-
[7]
Zheyi Chen, Weixian Liao, Pu Tian, Qianlong Wang, and Wei Yu. A fairness-aware peer-to-peer decentralized learning framework with heterogeneous devices.Future Internet, 14 (5):138, 2022. 2
work page 2022
-
[8]
Li Deng. The mnist database of handwritten digit images for machine learning research.IEEE Signal Processing Maga- zine, 29(6):141–142, 2012. 6
work page 2012
-
[9]
Fairness-aware agnostic federated learning
Wei Du, Depeng Xu, Xintao Wu, and Hanghang Tong. Fairness-aware agnostic federated learning. InProceedings of the 2021 SIAM International Conference on Data Mining (SDM), pages 181–189. SIAM, 2021. 2
work page 2021
-
[10]
Ezzeldin, Shen Yan, Chaoyang He, Emilio Ferrara, and Salman Avestimehr
Yahya H. Ezzeldin, Shen Yan, Chaoyang He, Emilio Ferrara, and Salman Avestimehr. Fairfed: Enabling group fairness in federated learning.arXiv preprint arXiv:2110.00857, 2021. 2
-
[11]
Local model poisoning attacks to byzantine-robust federated learning
Minghong Fang, Xiaoyu Cao, Jinyuan Jia, and Neil Gong. Local model poisoning attacks to byzantine-robust federated learning. In29th USENIX Security Symposium (USENIX Se- curity 20), pages 1605–1622, 2020. 6
work page 2020
-
[12]
Byzantine- robust decentralized federated learning.arXiv preprint arXiv:2406.10416, 2024
Minghong Fang, Zifan Zhang, Prashant Khanduri, Song- tao Lu, Yuchen Liu, Neil Gong, et al. Byzantine- robust decentralized federated learning.arXiv preprint arXiv:2406.10416, 2024. 3, 8, 1
-
[13]
Fedgr: Federated learning with gravitation regulation for double imbalance distribu- tion
Songyue Guo, Xu Yang, Jiyuan Feng, Ye Ding, Wei Wang, Yunqing Feng, and Qing Liao. Fedgr: Federated learning with gravitation regulation for double imbalance distribu- tion. InInternational Conference on Database Systems for Advanced Applications, pages 703–718. Springer, 2023. 6
work page 2023
-
[14]
Chaoyang He, Conghui Tan, Hanlin Tang, Shuang Qiu, and Ji Liu. Central server free federated learning over single-sided trust social networks.arXiv preprint arXiv:1910.04956, 2019. 1
-
[15]
Chaoyang He, Emir Ceyani, Keshav Balasubramanian, Mu- rali Annavaram, and Salman Avestimehr. Spreadgnn: Serverless multi-task federated learning for graph neural net- works.arXiv preprint arXiv:2106.02743, 2021. 1
-
[16]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Mea- suring the effects of non-identical data distribution for feder- ated visual classification.arXiv preprint arXiv:1909.06335,
work page internal anchor Pith review arXiv 1909
-
[17]
Zeou Hu, Kiarash Shaloudegi, Guojun Zhang, and Yaoliang Yu. Fedmgda+: Federated learning meets multi-objective optimization.arXiv preprint arXiv:2006.11489, 2020. 2
-
[18]
Performance analysis of decentralized federated learning de- ployments, 2025
Chengyan Jiang, Jiamin Fan, Talal Halabi, and Israat Haque. Performance analysis of decentralized federated learning de- ployments, 2025. 5, 1
work page 2025
-
[19]
Malcolm Shepherd Knowles.Self-directed learning: A guide for learners and teachers. Association Press, 1975. 2
work page 1975
-
[20]
Federated Learning: Strategies for Improving Communication Efficiency
Jakub Kone ˇcn`y, H Brendan McMahan, Felix X Yu, Peter Richt´arik, Ananda Theertha Suresh, and Dave Bacon. Fed- erated learning: Strategies for improving communication ef- ficiency.arXiv preprint arXiv:1610.05492, 2016. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[21]
Benign overfitting in two-layer relu convolutional neural networks
Yiwen Kou, Zixiang Chen, Yuanzhou Chen, and Quanquan Gu. Benign overfitting in two-layer relu convolutional neural networks. InInternational conference on machine learning, pages 17615–17659. PMLR, 2023. 8
work page 2023
-
[22]
Fully decentralized federated learning
Anusha Lalitha, Shubhanshu Shekhar, Tara Javidi, and Fari- naz Koushanfar. Fully decentralized federated learning. InThird Workshop on Bayesian Deep Learning (NeurIPS),
-
[23]
Peer-to-peer Federated Learning on Graphs
Anusha Lalitha, Osman Cihan Kilinc, Tara Javidi, and Fari- naz Koushanfar. Peer-to-peer federated learning on graphs. arXiv preprint arXiv:1901.11173, 2019. 1
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[24]
The byzantine generals problem
Leslie Lamport, Robert Shostak, and Marshall Pease. The byzantine generals problem. InConcurrency: the works of leslie lamport, pages 203–226. 2019. 8
work page 2019
-
[25]
Khiem Le, Nhan Luong-Ha, Manh Nguyen-Duc, Danh Le- Phuoc, Cuong Do, and Kok-Seng Wong. Exploring the prac- ticality of federated learning: A survey towards the com- munication perspective.arXiv preprint arXiv:2405.20431,
-
[26]
Haoyu Lei, Shizhan Gong, Qi Dou, and Farzan Farnia. pfedfair: Towards optimal group fairness-accuracy trade- off in heterogeneous federated learning.arXiv preprint arXiv:2503.14925, 2025. 2
-
[27]
Suyi Li, Yong Cheng, Wei Wang, Yang Liu, and Tianjian Chen. Learning to detect malicious clients for robust feder- ated learning.arXiv preprint arXiv:2002.00211, 2020. 2
-
[28]
Fair re- source allocation in federated learning,
Tian Li, Maziar Sanjabi, Ahmad Beirami, and Virginia Smith. Fair resource allocation in federated learning.arXiv preprint arXiv:1905.10497, 2019. 2, 6
-
[29]
Ditto: Fair and robust federated learning through per- sonalization
Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. Ditto: Fair and robust federated learning through per- sonalization. InInternational conference on machine learn- ing, pages 6357–6368. PMLR, 2021. 7
work page 2021
-
[30]
Yipeng Li and Xinchen Lyu. Convergence analysis of se- quential federated learning on heterogeneous data.Advances in Neural Information Processing Systems, 36:56700–56755,
-
[31]
Edwin A Locke and Gary P Latham. Building a practically useful theory of goal setting and task motivation: A 35-year odyssey.American psychologist, 57(9):705, 2002. 2
work page 2002
-
[32]
Zhuoran Ma, Jianfeng Ma, Yinbin Miao, Yingjiu Li, and Robert H Deng. Shieldfl: Mitigating model poisoning at- tacks in privacy-preserving federated learning.IEEE Trans- actions on Information Forensics and Security, 17:1639– 1654, 2022. 5
work page 2022
-
[33]
Communication- efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication- efficient learning of deep networks from decentralized data. InArtificial Intelligence and Statistics, pages 1273–1282. PMLR, 2017. 1, 2, 6
work page 2017
-
[34]
Mehryar Mohri, Gary Sivek, and Ananda Theertha Suresh. Agnostic federated learning. InProceedings of the 36th In- ternational Conference on Machine Learning, pages 4615– 4625, 2019. 2
work page 2019
-
[35]
Viraaji Mothukuri, Reza M Parizi, Seyedamin Pouriyeh, Yan Huang, Ali Dehghantanha, and Gautam Srivastava. A survey on security and privacy of federated learning.Future Gener- ation Computer Systems, 115:619–640, 2021. 3
work page 2021
-
[36]
In31st USENIX Security Symposium (USENIX Se- curity 22), pages 1415–1432, 2022
Thien Duc Nguyen, Phillip Rieger, Roberta De Viti, Huili Chen, Bj ¨orn B Brandenburg, Hossein Yalame, Helen M¨ollering, Hossein Fereidooni, Samuel Marchal, Markus Miettinen, et al.{FLAME}: Taming backdoors in federated learning. In31st USENIX Security Symposium (USENIX Se- curity 22), pages 1415–1432, 2022. 8
work page 2022
-
[37]
Jie Peng, Weiyu Li, and Qing Ling. Byzantine-robust decen- tralized stochastic optimization over static and time-varying networks.Signal Processing, 183:108020, 2021. 5
work page 2021
-
[38]
M ´onica Ribero and Haris Vikalo. Reducing communication in federated learning via efficient client sampling.Pattern Recognition, 148:110122, 2024. 2
work page 2024
-
[39]
Suhail Mohmad Shah and Vincent KN Lau. Model compres- sion for communication efficient federated learning.IEEE Transactions on Neural Networks and Learning Systems, 34 (9):5937–5951, 2021. 2
work page 2021
-
[40]
Privacy-preserving deep learning
Reza Shokri and Vitaly Shmatikov. Privacy-preserving deep learning. InProceedings of the 22nd ACM SIGSAC Con- ference on Computer and Communications Security, pages 1310–1321, 2015. 1
work page 2015
-
[41]
Tao Sun, Dongsheng Li, and Bao Wang. Decentralized feder- ated averaging.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4289–4301, 2022. 3
work page 2022
-
[42]
Cognitive load during problem solving: Effects on learning.Cognitive science, 12(2):257–285, 1998
John Sweller, Jeroen JG van Merri ¨enboer, and Fred GWC Paas. Cognitive load during problem solving: Effects on learning.Cognitive science, 12(2):257–285, 1998. 2
work page 1998
-
[43]
Federated learning with fair averaging.arXiv preprint arXiv:2104.14937, 2021
Zheng Wang, Xiaoliang Fan, Jianzhong Qi, Chenglu Wen, Cheng Wang, and Rongshan Yu. Federated learning with fair averaging.arXiv preprint arXiv:2104.14937, 2021. 2
-
[44]
Chuhan Wu, Fangzhao Wu, Lingjuan Lyu, Yongfeng Huang, and Xing Xie. Communication-efficient federated learning via knowledge distillation.Nature communications, 13(1): 2032, 2022. 2
work page 2032
-
[45]
Zhaoxian Wu, Tianyi Chen, and Qing Ling. Byzantine- resilient decentralized stochastic optimization with robust aggregation rules.IEEE transactions on signal processing, 71:3179–3195, 2023. 3, 5
work page 2023
-
[46]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion- mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[47]
Hong Xing, Osvaldo Simeone, and Suzhi Bi. Federated learning over wireless device-to-device networks: Algo- rithms and convergence analysis.IEEE Journal on Selected Areas in Communications, 39(12):3723–3741, 2021. 1
work page 2021
-
[48]
Byzantine-robust decentral- ized learning via remove-then-clip aggregation
Caiyi Yang and Javad Ghaderi. Byzantine-robust decentral- ized learning via remove-then-clip aggregation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 21735–21743, 2024. 1
work page 2024
-
[49]
Hao Ye, Le Liang, and Geoffrey Ye Li. Decentralized fed- erated learning with unreliable communications.IEEE Jour- nal of Selected Topics in Signal Processing, 16(3):487–500,
-
[50]
On the tradeoff be- tween privacy preservation and byzantine-robustness in de- centralized learning
Haoxiang Ye, Heng Zhu, and Qing Ling. On the tradeoff be- tween privacy preservation and byzantine-robustness in de- centralized learning. InICASSP 2024-2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 9336–9340. IEEE, 2024. 6, 8, 1
work page 2024
-
[51]
Byzantine-robust distributed learning: Towards op- timal statistical rates
Dong Yin, Yudong Chen, Ramchandran Kannan, and Peter Bartlett. Byzantine-robust distributed learning: Towards op- timal statistical rates. InInternational Conference on Ma- chine Learning, pages 5650–5659. Pmlr, 2018. 8
work page 2018
-
[52]
Decentralized federated learning: A survey and perspective.IEEE Internet of Things Journal,
Liangqi Yuan, Ziran Wang, Lichao Sun, Philip S Yu, and Christopher G Brinton. Decentralized federated learning: A survey and perspective.IEEE Internet of Things Journal,
-
[53]
Xubo Yue, Maher Nouiehed, and Raed Al Kontar. Gifair-fl: A framework for group and individual fairness in federated learning.INFORMS Journal on Data Science, 2(1):10–23,
-
[54]
Byzantine- robust decentralized federated learning via local perfor- mance checking
Kaichuang Zhang, Alina Basharat, and Ping Xu. Byzantine- robust decentralized federated learning via local perfor- mance checking. In31st International Conference on Neural Information Processing, 2024. 1, 3, 6
work page 2024
-
[55]
Distributional and byzantine robust decentralized federated learning
Kaichuang Zhang, Ping Xu, and Zhi Tian. Distributional and byzantine robust decentralized federated learning. In2025 59th Annual Conference on Information Sciences and Sys- tems (CISS), pages 1–6. IEEE, 2025. 1
work page 2025
-
[56]
A dynamic reweighting strat- egy for fair federated learning
Zhiyuan Zhao and Gauri Joshi. A dynamic reweighting strat- egy for fair federated learning. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8772–8776. IEEE, 2022. 2 DFedReweighting: A Unified Framework for Objective-Oriented Reweighting in Decentralized Federated Learning Supplementary Material
work page 2022
-
[57]
Convergence Analysis 8.1. Assumptions and Remarks Beyond Assumptions 3 and 4 in the main text, we introduce additional assumptions for our convergence analysis. Assumption 3G B is connected.[12, 48, 50] The subgraph of benign nodes should be connected, meaning that there should exist a path between any two benign nodes allowing them to reach each other. A...
-
[58]
For each candidatew a, com- pute its distances to all other candidates and letS a be the multiset of the smallestn−f−2distances, wheren=|N i| andfis the Byzantine tolerance parameter. The Krum score ofw a is score(w t+ 1 2 a ) = X d∈Sa d.(41) Krum selects the candidate with the minimal score and uses it as the aggregated model: wt+1 i = arg min w t+ 1 2a ...
-
[59]
Given a smoothing parameterβ >0, it then defines the unnormalized weight uj = 1 dj +β , the normalized weightp j = ujP k uk , and finally updates its model by wt+1 i = X j∈Ni pjw t+ 1 2 j .(45) In our experiments, the default value ofβis1.0
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.