Recognition: no theorem link
Sparse Concept Anchoring for Interpretable and Controllable Neural Representations
Pith reviewed 2026-05-16 22:12 UTC · model grok-4.3
The pith
Sparse Concept Anchoring positions targeted concepts in latent space using labels for under 0.1 percent of examples, enabling reversible steering and permanent removal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sparse Concept Anchoring biases the latent space to place a targeted subset of concepts along predefined directions or axis-aligned subspaces using only minimal supervision, while other concepts self-organize freely. The training objective combines activation normalization, a separation regularizer, and anchor or subspace regularizers that attract the scarce labeled points to their targets. Once anchored, the geometry permits reversible steering by subtracting the concept's latent component at inference time and permanent removal by targeted ablation of the anchored dimensions. Experiments demonstrate selective attenuation of chosen concepts with negligible effects on orthogonal features and
What carries the argument
Sparse Concept Anchoring via anchor or subspace regularizers that pull rare labeled examples toward predefined directions or axis-aligned subspaces in the latent space.
If this is right
- Reversible steering of model behavior becomes possible by projecting out any anchored concept component at inference.
- Permanent removal of a concept is achieved by ablating the weights tied to its anchored dimensions.
- Targeted concepts can be attenuated selectively while orthogonal features and reconstruction quality stay nearly unchanged.
- Controllable representations are obtained with labels on less than 0.1 percent of examples per anchored concept.
Where Pith is reading between the lines
- The same anchoring technique could be tested on transformer or diffusion models to check whether the linear-separability assumption holds beyond autoencoders.
- Anchoring might allow post-training removal of specific biases or capabilities without retraining the entire network.
- If directions remain stable across fine-tuning, the method offers an editing tool for already-deployed models.
Load-bearing premise
The anchored directions or subspaces stay linearly separable from other learned features after training is complete.
What would settle it
A test in which ablating the anchored dimensions produces reconstruction error on unrelated features that exceeds the theoretical bound by more than a small margin.
Figures















read the original abstract
We introduce Sparse Concept Anchoring, a method that biases latent space to position a targeted subset of concepts while allowing others to self-organize, using only minimal supervision (labels for <0.1% of examples per anchored concept). Training combines activation normalization, a separation regularizer, and anchor or subspace regularizers that attract rare labeled examples to predefined directions or axis-aligned subspaces. The anchored geometry enables two practical interventions: reversible behavioral steering that projects out a concept's latent component at inference, and permanent removal via targeted weight ablation of anchored dimensions. Experiments on structured autoencoders show selective attenuation of targeted concepts with negligible impact on orthogonal features, and complete elimination with reconstruction error approaching theoretical bounds. Sparse Concept Anchoring therefore provides a practical pathway to interpretable, steerable behavior in learned representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sparse Concept Anchoring to bias latent representations towards specific concepts using minimal supervision on less than 0.1% of examples. It employs activation normalization, a separation regularizer, and anchor or subspace regularizers to position concepts in predefined directions or subspaces. This enables inference-time steering by projecting out concept components and permanent removal through targeted weight ablation. Experiments on structured autoencoders are reported to achieve selective concept attenuation with negligible effects on orthogonal features and reconstruction errors approaching theoretical bounds.
Significance. If the experimental results hold, this method offers a practical and efficient way to achieve interpretable and controllable neural representations with sparse supervision. It could have substantial impact on fields requiring model editing, such as AI safety and fairness, by providing reversible and irreversible interventions on learned concepts without full retraining. The minimal supervision aspect enhances its applicability to large-scale models.
major comments (2)
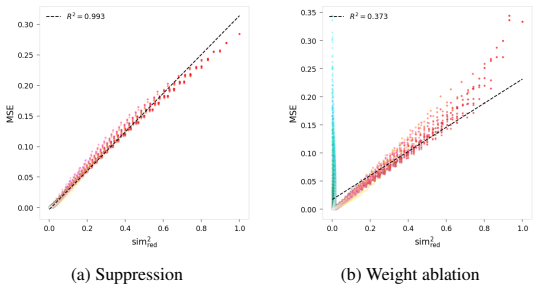
- The abstract claims that experiments demonstrate 'selective attenuation of targeted concepts with negligible impact on orthogonal features' and 'reconstruction error approaching theoretical bounds,' but no quantitative numbers, ablation details, error bars, or specific metrics are supplied. This is load-bearing for the central claim of providing a practical pathway, as the effectiveness cannot be assessed without these results.
- The separability of anchored directions from other features after end-to-end training is assumed but not verified. No post-training analysis, such as the Gram matrix of concept vectors or per-concept reconstruction errors following ablation, is mentioned to confirm that the regularizers prevent entanglement, which is necessary for the selective attenuation to succeed.
minor comments (2)
- The supervision level is stated as '<0.1% of examples per anchored concept' but lacks details on the exact datasets, number of concepts, or how the labels are used in training.
- The tuning of regularizer strengths is described as part of the method, but it would benefit from discussion on sensitivity to these hyperparameters and whether they are chosen independently of performance metrics.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the method's potential impact on interpretable and controllable representations. We agree that the experimental claims require more detailed quantitative support and verification, and we will revise the manuscript accordingly to address both major comments.
read point-by-point responses
-
Referee: The abstract claims that experiments demonstrate 'selective attenuation of targeted concepts with negligible impact on orthogonal features' and 'reconstruction error approaching theoretical bounds,' but no quantitative numbers, ablation details, error bars, or specific metrics are supplied. This is load-bearing for the central claim of providing a practical pathway, as the effectiveness cannot be assessed without these results.
Authors: We agree that specific quantitative results are necessary to substantiate the abstract claims. In the revised manuscript we will add a dedicated results table reporting exact attenuation percentages for targeted concepts, reconstruction MSE values (with standard deviations over 5 random seeds), ablation-induced error increases on orthogonal features, and direct comparison to the theoretical reconstruction bound. These numbers will also be referenced briefly in the abstract. revision: yes
-
Referee: The separability of anchored directions from other features after end-to-end training is assumed but not verified. No post-training analysis, such as the Gram matrix of concept vectors or per-concept reconstruction errors following ablation, is mentioned to confirm that the regularizers prevent entanglement, which is necessary for the selective attenuation to succeed.
Authors: We acknowledge that explicit verification of post-training separability strengthens the central claim. We will add two new analyses in the Experiments section: (1) the Gram matrix of the learned anchor vectors after training to quantify their mutual orthogonality, and (2) per-concept reconstruction error curves after ablating each anchored dimension individually, demonstrating that error increases remain negligible for non-targeted concepts. These additions will confirm that the separation and anchor regularizers achieve the intended disentanglement. revision: yes
Circularity Check
No significant circularity in method or claims
full rationale
The paper proposes Sparse Concept Anchoring via activation normalization plus separation and anchor/subspace regularizers applied to <0.1% labeled examples. Central claims about projection-based steering and ablation rest on post-training experimental measurements of selective attenuation and reconstruction error on structured autoencoders. No derivation step equates a result to its inputs by construction, renames a fitted quantity as a prediction, or reduces the separability outcome to a self-citation or definitional identity. The linear-separability assumption is treated as an empirical consequence of the regularizers rather than a tautology, and performance is reported as measured rather than forced.
Axiom & Free-Parameter Ledger
free parameters (2)
- anchor directions or subspaces
- regularizer coefficients
axioms (1)
- domain assumption Concepts of interest admit linear or axis-aligned representations in the latent space that can be isolated from orthogonal features.
Reference graph
Works this paper leans on
-
[1]
Critical learning periods in deep networks
Alessandro Achille, Matteo Rovere, and Stefano Soatto. Critical learning periods in deep networks. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9,
work page 2019
-
[2]
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda
URL https://openreview.net/forum?id=Bk eStsCcKQ. Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, ...
work page 2024
-
[3]
URL http: //papers.nips.cc/paper_files/paper/2024/hash/f545448535dfde4f978 6555403ab7c49-Abstract-Conference.html. 8 Yoshua Bengio, Aaron C. Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828,
work page 2024
-
[4]
URLhttps://doi.org/10.1109/TPAMI.2013.50
doi: 10.1109/TP AMI.2013.50. URLhttps://doi.org/10.1109/TPAMI.2013.50. Leonard Bereska and Stratis Gavves. Mechanistic interpretability for AI safety - A review.Trans. Mach. Learn. Res., 2024,
work page doi:10.1109/tp 2013
-
[5]
Lucas Bourtoule, Varun Chandrasekaran, Christopher A
URL https://openreview.net/forum?id=ePUVet PKu6. Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In42nd IEEE Symposium on Security and Privacy, SP 2021, San Francisco, CA, USA, 24-27 May 2021, pp. 141–159. IEEE,
work page 2021
-
[6]
Compositional non-interference for fine-grained concurrent programs
doi: 10.1109/SP40001.2021.00019. URL https://doi.org/10.110 9/SP40001.2021.00019. Yuanpu Cao, Tianrong Zhang, Bochuan Cao, Ziyi Yin, Lu Lin, Fenglong Ma, and Jinghui Chen. Personalized steering of large language models: Versatile steering vectors through bi-directional preference optimization. InAdvances in Neural Information Processing Systems 38: Annual...
-
[7]
Zhi Chen, Yijie Bei, and Cynthia Rudin
URL http://papers.nips.cc/paper_files /paper/2024/hash/58cbe393b4254da8966780a40d023c0b-Abstract-Confe rence.html. Zhi Chen, Yijie Bei, and Cynthia Rudin. Concept whitening for interpretable image recognition. Nature Machine Intelligence, 2(12):772–782, December
work page 2024
-
[8]
doi: 10.1038/s4 2256-020-00265-z
ISSN 2522-5839. doi: 10.1038/s4 2256-020-00265-z. URLhttp://dx.doi.org/10.1038/s42256-020-00265-z. Jiankang Deng, Jia Guo, Jing Yang, Niannan Xue, Irene Kotsia, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition.IEEE Trans. Pattern Anal. Mach. Intell., 44(10):5962–5979,
-
[9]
URL https://doi.org/10 .1109/TPAMI.2021.3087709
doi: 10.1109/TPAMI.2021.3087709. URL https://doi.org/10 .1109/TPAMI.2021.3087709. Hanyu Duan, Yi Yang, Ahmed Abbasi, and Kar Yan Tam. Ready2unlearn: A learning-time approach for preparing models with future unlearning readiness.CoRR, abs/2505.10845,
-
[10]
URLhttps://doi.org/10.48550/arXiv.2505.10845
doi: 10.485 50/ARXIV.2505.10845. URLhttps://doi.org/10.48550/arXiv.2505.10845. Joshua Engels, Eric J. Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
-
[11]
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey
URL https://openreview.net/forum?id=d63a4AM4hb. Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
work page 2024
-
[12]
Knowledge unlearning for mitigating privacy risks in language models
URLhttps://openreview.net/forum?id=F76bwRSLeK. Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models.CoRR, abs/2210.01504,
-
[13]
Knowledge unlearning for mitigating privacy risks in language models
doi: 10.48550/ARXIV.2210.01504. URL https://doi.org/10.4 8550/arXiv.2210.01504. Been Kim, Martin Wattenberg, Justin Gilmer, Carrie J. Cai, James Wexler, Fernanda B. Viégas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCA V). InProceedings of the 35th International Conference on Machin...
-
[14]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang
URL http: //proceedings.mlr.press/v80/kim18d.html. Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, pp. 533...
work page 2020
-
[15]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D
URL https: //arxiv.org/abs/2409.09951. Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Ari...
-
[16]
Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song
URLhttps://openreview.net/forum?id=xlr6AUDuJz. Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. Sphereface: Deep hypersphere embedding for face recognition. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pp. 6738–6746. IEEE Computer Society,
work page 2017
-
[17]
URL https://doi.org/10.110 9/CVPR.2017.713
doi: 10.1109/CVPR.2017.713. URL https://doi.org/10.110 9/CVPR.2017.713. Ilya Loshchilov, Cheng-Ping Hsieh, Simeng Sun, and Boris Ginsburg. ngpt: Normalized transformer with representation learning on the hypersphere.CoRR, abs/2410.01131,
-
[18]
URLhttps://doi.org/10.48550/arXiv.2410.01131
doi: 10.48550/A RXIV.2410.01131. URLhttps://doi.org/10.48550/arXiv.2410.01131. Andrei Margeloiu, Matthew Ashman, Umang Bhatt, Yanzhi Chen, Mateja Jamnik, and Adrian Weller. Do concept bottleneck models learn as intended?CoRR, abs/2105.04289,
-
[19]
Do concept bottleneck models learn as intended?arXiv preprint arXiv:2105.04289, 2021
URL https://arxiv.org/abs/2105.04289. Richard Meyes, Melanie Lu, Constantin Waubert de Puiseau, and Tobias Meisen. Ablation studies in artificial neural networks.CoRR, abs/1901.08644,
-
[20]
URL https://proceedings.neurip s.cc/paper_files/paper/2013/file/9aa42b31882ec039965f3c4923ce901 b-Paper.pdf. Tuomas P. Oikarinen, Subhro Das, Lam M. Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
work page 2013
-
[21]
Jeffrey Pennington, Richard Socher, and Christopher D
URL https://openreview .net/forum?id=FlCg47MNvBA. Jeffrey Pennington, Richard Socher, and Christopher D. Manning. Glove: Global vectors for word representation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL, pp...
work page 2014
-
[22]
URL https://doi.org/10.3115/v1/d14-1162
doi: 10.3115/V1/D14-1162. URL https://doi.org/10.3115/v1/d14-1162. Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailan...
-
[23]
URL https://doi.org/10.18653/v1/2024 .acl-long.828
doi: 10.18653/V1/2024.ACL-LONG.828. URL https://doi.org/10.18653/v1/2024 .acl-long.828. Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nat. Mach. Intell., 1(5):206–215,
-
[24]
URLhttps://doi.org/10.1038/s42256-019-0048-x
doi: 10.1038/S42256-019-0 048-X. URLhttps://doi.org/10.1038/s42256-019-0048-x. 10 Yoshihide Sawada and Keigo Nakamura. Concept bottleneck model with additional unsupervised concepts.IEEE Access, 10:41758–41765,
-
[25]
URL https://doi.org/10.1109/ACCESS.2022.3167702
doi: 10.1109/ACCESS.2022.3167702. URL https://doi.org/10.1109/ACCESS.2022.3167702. Andrei Semenov, Vladimir Ivanov, Aleksandr Beznosikov, and Alexander V . Gasnikov. Sparse concept bottleneck models: Gumbel tricks in contrastive learning.CoRR, abs/2404.03323,
-
[26]
URL https://doi.org/10.48550/arXiv.2404
doi: 10.48550/ARXIV.2404.03323. URL https://doi.org/10.48550/arXiv.2404. 03323. Ivaxi Sheth and Samira Ebrahimi Kahou. Auxiliary losses for learning generalizable concept-based models. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023,
-
[27]
URL http://papers.nips.cc/paper_files/paper/2023/hash/5 55479a201da27c97aaeed842d16ca49-Abstract-Conference.html. Viacheslav Sinii, Nikita Balagansky, Gleb Gerasimov, Daniil Laptev, Yaroslav Aksenov, Vadim Kurochkin, Alexey Gorbatovski, Boris Shaposhnikov, and Daniil Gavrilov. Small vectors, big effects: A mechanistic study of rl-induced reasoning via ste...
-
[28]
doi: 10.48550/ARXIV.2509.06608. URL https://doi.org/10.48550/arXiv.2 509.06608. Daniel Tan, David Chanin, Aengus Lynch, Brooks Paige, Dimitrios Kanoulas, Adrià Garriga-Alonso, and Robert Kirk. Analysing the generalisation and reliability of steering vectors. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Pr...
-
[29]
Steering Language Models With Activation Engineering
URL https://transformer-circuits.pub/2024/scaling-monos emanticity/index.html. Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization.CoRR, abs/2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Steering Language Models With Activation Engineering
doi: 10.48550/ARXIV.2308.10248. URL https://doi.org/10.4 8550/arXiv.2308.10248. Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InProceedings of the 37th International Con- ference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceeding...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248 2020
-
[31]
Zero-shot Concept Bottleneck Models
URL http: //proceedings.mlr.press/v119/wang20k.html. Shin’ya Yamaguchi, Kosuke Nishida, Daiki Chijiwa, and Yasutoshi Ida. Zero-shot concept bottleneck models.CoRR, abs/2502.09018,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Zero-shot Concept Bottleneck Models
doi: 10.48550/ARXIV.2502.09018. URL https: //doi.org/10.48550/arXiv.2502.09018. Jin Yao, Eli Chien, Minxin Du, Xinyao Niu, Tianhao Wang, Zezhou Cheng, and Xiang Yue. Machine unlearning of pre-trained large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8403–8419, Bang...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09018
-
[33]
doi: 10.18653/v1/2024.acl-long.457
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.457. URLhttps://aclanthology.org/2024.acl-long.457/. Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning.CoRR, abs/2404.05868,
-
[34]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
doi: 10.48550/ARXIV.2404.05868. URLhttps://doi.org/10.48550/arXiv.2404.05868. Andy Zou, Long Phan, Sarah Li Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt 11 Fredrikson, J. ...
work page internal anchor Pith review doi:10.48550/arxiv.2404.05868
-
[35]
Representation Engineering: A Top-Down Approach to AI Transparency
doi: 10.48550/ARXIV.2310.01405. URL https://doi.org/10.48550/arXiv.2310.01405. 12 A RELATEDWORK Our work sits at the intersection of several active research areas: methods for building interpretability into models during training, techniques for steering model behavior through representation manipula- tion, and approaches for removing specific model capab...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405
-
[36]
enforce interpretability architecturally by introducing an intermediate layer where each dimension corresponds to a predefined concept, enabling test-time interventions—though originally requiring full supervision, recent work has reduced this burden through post-hoc discovery or sparse training-time methods with minimal labels (Oikarinen et al., 2023; Se...
work page 2023
-
[37]
take a lightweight post-hoc approach, learning linear probes from as few as 30 examples per concept to identify where concepts appear in trained models—useful for bias detection but providing no architectural guarantees for interventions. Sparse Autoencoders use unsupervised dictionary learning to discover interpretable features models actually use, recen...
work page 2024
-
[38]
These methods trade off supervision requirements, timing of concept incorporation (training vs
replaces batch normalization with transformations that align latent space axes with concepts using representative examples, enabling layer-wise interpretability without hurting performance. These methods trade off supervision requirements, timing of concept incorporation (training vs. post-hoc), and intervention capabilities. A.2 MACHINEUNLEARNING ANDREPR...
work page 2022
-
[39]
uses meta-learning to prepare models for later unlearning—yet both operate through data organization or optimization dynamics rather than explicit geometric positioning. Representation engineering methods manipulate behavior by modifying internal activations (Zou et al., 2023): activation addi- tion (Turner et al.,
work page 2023
-
[40]
train better steering vectors—but all depend on directions discovered in already-trained models. Systematic analysis reveals substantial reliability issues: steering effectiveness varies dramatically across inputs, many concepts prove "anti-steerable", and success often depends on spurious correlations rather than coherent concepts (Tan et al., 2024). Abl...
work page 2024
-
[41]
demonstrated that safety behaviors can be removed through targeted weight orthogonalization with negligible performance degradation, providing evidence for the linear representation hypothesis—yet achieving selective ablation without side effects remains challenging when features are distributed or when networks exhibit "compensatory masquerade" by routin...
work page 2019
-
[42]
Angular margin losses from face recognition (Liu et al., 2017; Deng et al.,
normalizes all transformer components to unit norm, constraining representations to a hypersphere, yielding 4-20× faster convergence, more interpretable angular relationships, and stable gradients—suggesting hypersphere constraints improve 13 both interpretability and optimization itself. Angular margin losses from face recognition (Liu et al., 2017; Deng et al.,
work page 2017
-
[43]
enforce separation between classes in hyperspherical geometry through L2-normalized features and additive margins, achieving state-of-the-art results because angular constraints create geometrically clean separation. Theoretical analysis shows contrastive learning on hyperspheres naturally optimizes for alignment and uniformity (Wang & Isola, 2020)—proper...
work page 2020
-
[44]
encourages separation between learned concept representations while reducing intra-concept distance, improving concept disentanglement in CBMs through auxiliary training objectives—though applied to dense concept bottlenecks rather than sparse, pre-positioned concepts. While geometric constraints have improved training efficiency and discriminability, the...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.