RAST-MoE-RL: A Regime-Aware Spatio-Temporal MoE Framework for Deep Reinforcement Learning in Ride-Hailing
Pith reviewed 2026-05-16 22:15 UTC · model grok-4.3
The pith
A mixture-of-experts encoder in reinforcement learning lets ride-hailing agents specialize across supply-demand regimes and cuts both matching and pickup delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
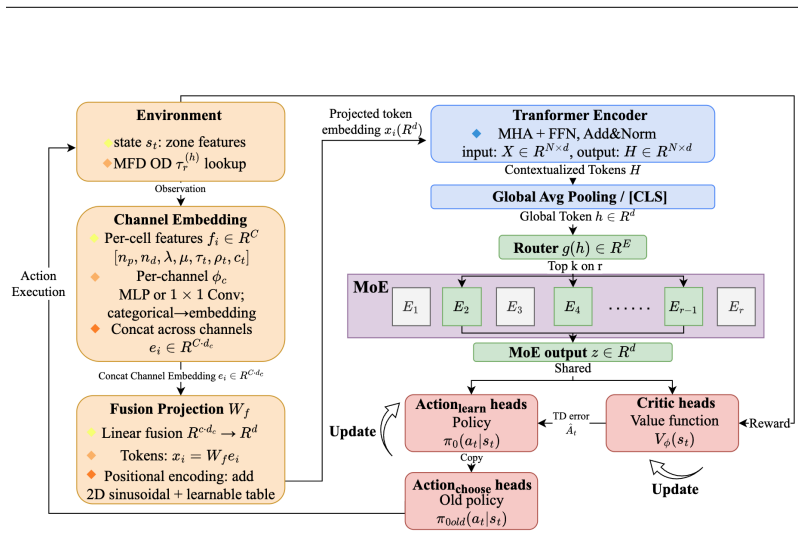
The RAST-MoE framework casts adaptive delayed matching as a regime-aware MDP and replaces the usual monolithic encoder with a self-attention MoE layer; different experts learn to specialize in separate supply-demand and congestion regimes, yielding a policy that lowers matching delay by 10 percent and pickup delay by 15 percent on San Francisco Uber data while remaining stable and robust to unseen regimes.
What carries the argument
Self-attention mixture-of-experts encoder that routes spatio-temporal state features to regime-specialized sub-networks inside the reinforcement-learning policy.
If this is right
- The policy maintains stable training without reward hacking across multiple demand regimes.
- Expert specialization emerges automatically and improves robustness when the system encounters previously unseen demand patterns.
- Per-sample computation stays efficient despite the added capacity, supporting deployment at city scale.
- The same regime-aware MDP formulation can be reused for other batching decisions such as vehicle repositioning.
Where Pith is reading between the lines
- The approach could be tested in other non-stationary resource-allocation domains such as dynamic pricing or traffic-signal control by swapping the observation encoder.
- Because the model size remains modest, further scaling to multi-city data or longer time horizons should remain computationally feasible.
- Controlled ablation experiments that isolate the routing mechanism from the self-attention layers would clarify which component drives the observed delay reductions.
Load-bearing premise
Shallow encoders cannot capture the dynamic supply-demand patterns and congestion effects that appear in real ride-hailing environments.
What would settle it
Running the identical reinforcement-learning algorithm on the same San Francisco dataset but replacing the MoE encoder with a standard deep feed-forward or attention network and obtaining equal or lower delay values would falsify the necessity of the mixture-of-experts component.
Figures





read the original abstract
Ride-hailing platforms face the challenge of balancing passenger waiting times with overall system efficiency under highly uncertain supply-demand conditions. Adaptive delayed matching, which controls the holding intervals for batched sets of requests and vehicles, reveals an inherent trade-off between matching and pickup delays. The resulting environment with temporally varying request arrival patterns and dynamic congestion calls for more expressive networks with sufficient capacity to capture their non-stationarity. To address the limitations of existing methods that rely on shallow encoders that cannot capture dynamic supply-demand patterns and congestion effects, we introduce the Regime-Aware Spatio-Temporal Mixture-of-Experts (RAST-MoE) framework, which formalizes adaptive delayed matching as a regime-aware Markov Decision Process and equips RL agents with a self-attention MoE encoder. Instead of relying on a single monolithic network, our design allows different experts to specialize automatically in varying operational conditions, improving representation capacity while maintaining per-sample computation efficiency. Despite its modest size of only 12M parameters, our framework consistently outperforms strong baselines. On real-world Uber trajectory data from San Francisco, it reduces average matching delay by 10%, and pickup delay by 15%. In addition, it demonstrates robustness to unseen demand regimes, stable training behavior without reward hacking, and expert specialization to different regimes. This study shows the strength of MoE-enhanced RL for large-scale decision-making tasks with complex spatiotemporal dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Regime-Aware Spatio-Temporal Mixture-of-Experts (RAST-MoE-RL) framework for deep RL in ride-hailing. It formalizes adaptive delayed matching as a regime-aware MDP and equips the agent with a self-attention MoE encoder (12M parameters) that allows experts to specialize across varying supply-demand regimes. The central claim is that this yields consistent outperformance over strong baselines, specifically reducing average matching delay by 10% and pickup delay by 15% on real-world Uber trajectory data from San Francisco, while also showing robustness to unseen regimes, stable training, and expert specialization.
Significance. If the reported gains can be shown to arise specifically from the MoE routing and regime-aware formulation rather than raw capacity or attention alone, the work would offer a practical template for scaling RL to non-stationary spatiotemporal control problems. The use of real Uber data is a positive for external validity, but the absence of controlled ablations currently prevents a clear assessment of whether the MoE component is the load-bearing innovation.
major comments (2)
- [Experimental Results] The headline performance claims (10% matching-delay reduction, 15% pickup-delay reduction) rest on comparisons to unspecified 'strong baselines' without any ablation that replaces the MoE router with a single expert or monolithic transformer of matched 12M-parameter capacity while preserving the regime-aware MDP and training protocol. This omission makes it impossible to attribute gains to expert specialization rather than overall model size or architectural changes.
- [Experimental Results] No details are provided on the number of independent runs, standard deviations, or statistical significance tests for the reported percentage improvements, which is required to substantiate that the gains are robust rather than sensitive to random seeds or post-hoc baseline selection.
minor comments (2)
- [Abstract] The abstract refers to 'strong baselines' without naming them or citing their original papers; this information should be supplied in the main text and tables.
- [Method] The description of the self-attention MoE encoder lacks a precise specification of the number of experts, routing mechanism (e.g., top-k), and how regime awareness is injected into the router.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for strengthening the experimental evidence. We address each major comment below and will revise the manuscript to incorporate the requested details and ablations.
read point-by-point responses
-
Referee: [Experimental Results] The headline performance claims (10% matching-delay reduction, 15% pickup-delay reduction) rest on comparisons to unspecified 'strong baselines' without any ablation that replaces the MoE router with a single expert or monolithic transformer of matched 12M-parameter capacity while preserving the regime-aware MDP and training protocol. This omission makes it impossible to attribute gains to expert specialization rather than overall model size or architectural changes.
Authors: We agree that explicit ablations isolating the MoE router are needed to attribute gains specifically to expert specialization. In the revised manuscript we will add controlled experiments comparing RAST-MoE-RL to (i) a single-expert variant and (ii) a monolithic self-attention transformer, both with exactly 12M parameters, while preserving the regime-aware MDP and training protocol. We will also explicitly enumerate the strong baselines used in the original comparisons. These additions will clarify that performance improvements arise from the regime-aware MoE design rather than capacity or attention alone. revision: yes
-
Referee: [Experimental Results] No details are provided on the number of independent runs, standard deviations, or statistical significance tests for the reported percentage improvements, which is required to substantiate that the gains are robust rather than sensitive to random seeds or post-hoc baseline selection.
Authors: We acknowledge that statistical reporting is essential. The revised manuscript will report results averaged over five independent runs with different random seeds, include standard deviations for all metrics, and provide p-values from paired t-tests against the baselines. This will demonstrate that the reported 10% and 15% reductions are statistically significant and robust to seed variation. revision: yes
Circularity Check
No circularity; empirical claims rest on external Uber data and independent MDP formulation
full rationale
The paper introduces a regime-aware MDP formulation and self-attention MoE encoder for RL in ride-hailing, then evaluates on independent real-world Uber trajectory data from San Francisco. Reported gains (10% matching delay reduction, 15% pickup delay reduction) are measured against external baselines rather than quantities defined in terms of the model's own fitted parameters or self-referential predictions. No equations, uniqueness theorems, or ansatzes are shown to reduce by construction to inputs; the 12M-parameter design and expert specialization are presented as architectural choices whose benefits are tested empirically. No load-bearing self-citations appear in the abstract or described chain. The central claims therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
our design allows different experts to specialize automatically in varying operational conditions... expert specialization to different regimes
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
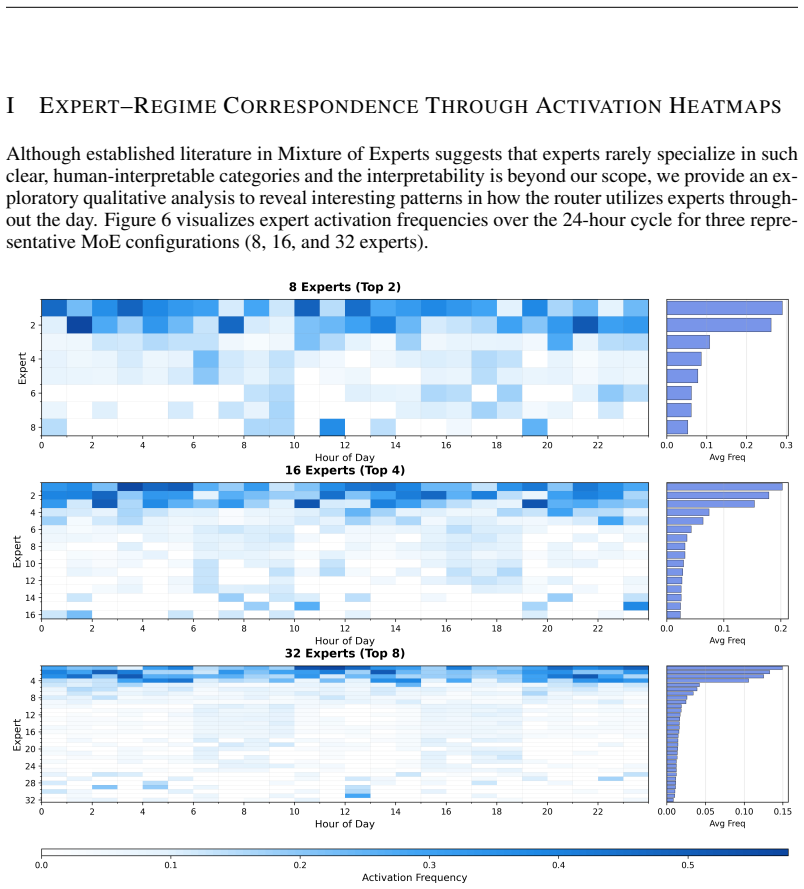
Regime-Aware Spatio-Temporal Mixture-of-Experts (RAST-MoE) framework... 16 experts and top-4 routing
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.