ComMark: Covert and Robust Black-Box Model Watermarking with Compressed Samples
Pith reviewed 2026-05-16 22:21 UTC · model grok-4.3
The pith
ComMark embeds watermarks in black-box models by compressing samples through frequency-domain high-frequency filtering to achieve both covertness and robustness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ComMark introduces a black-box model watermarking framework that uses frequency-domain transformations to generate compressed watermark samples by filtering high-frequency information, combined with simulated attack scenarios and a similarity loss during training, to deliver state-of-the-art covertness and robustness across diverse datasets and architectures.
What carries the argument
Frequency-domain transformations that filter high-frequency information to produce compressed watermark samples, augmented by simulated attacks and similarity loss during training.
Load-bearing premise
That filtering high-frequency information from watermark samples and training against simulated attacks will preserve model utility while making the watermark resistant to both detection and real-world removal attempts.
What would settle it
An experiment showing that an unsimulated attack such as targeted fine-tuning or high-frequency perturbation removes the watermark while model accuracy on the original task stays high would falsify the robustness claim.
Figures



















read the original abstract
The rapid advancement of deep learning has turned models into highly valuable assets due to their reliance on massive data and costly training processes. However, these models are increasingly vulnerable to leakage and theft, highlighting the critical need for robust intellectual property protection. Model watermarking has emerged as an effective solution, with black-box watermarking gaining significant attention for its practicality and flexibility. Nonetheless, existing black-box methods often fail to better balance covertness (hiding the watermark to prevent detection and forgery) and robustness (ensuring the watermark resists removal)-two essential properties for real-world copyright verification. In this paper, we propose ComMark, a novel black-box model watermarking framework that leverages frequency-domain transformations to generate compressed, covert, and attack-resistant watermark samples by filtering out high-frequency information. To further enhance watermark robustness, our method incorporates simulated attack scenarios and a similarity loss during training. Comprehensive evaluations across diverse datasets and architectures demonstrate that ComMark achieves state-of-the-art performance in both covertness and robustness. Furthermore, we extend its applicability beyond image recognition to tasks including speech recognition, sentiment analysis, image generation, image captioning, and video recognition, underscoring its versatility and broad applicability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ComMark, a black-box model watermarking framework that leverages frequency-domain transformations to generate compressed watermark samples by filtering high-frequency information. Simulated attack scenarios and a similarity loss are incorporated during training to enhance robustness. Evaluations across diverse datasets, architectures, and tasks (image recognition, speech recognition, sentiment analysis, image generation, image captioning, video recognition) claim state-of-the-art performance in both covertness and robustness.
Significance. If the empirical results hold under broader testing, the work could advance practical IP protection for deep learning models by improving the covertness-robustness trade-off and demonstrating applicability beyond image tasks. The frequency-domain compression plus attack simulation approach offers a concrete direction for black-box watermarking, provided the simulations prove representative.
major comments (3)
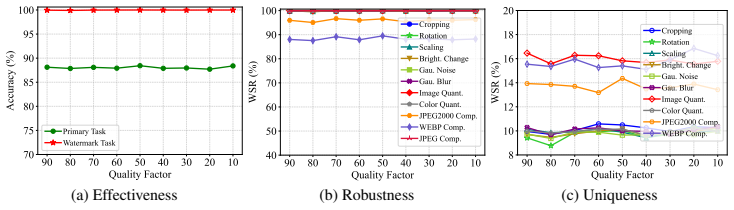
- [§4] §4 (Experiments): Robustness is demonstrated only against the specific simulated attacks used in training; no results are reported for adaptive or unsimulated removal strategies such as model extraction, quantization-aware fine-tuning, or unseen pruning, which directly undermines the SOTA robustness claim.
- [§3.2] §3.2 (Method): The frequency-domain high-frequency filtering is presented as preserving model utility, but no ablation on cutoff thresholds or their quantitative effect on task accuracy is provided, leaving the central utility-robustness balance unverified.
- [Table 3] Table 3 (Results): Performance metrics lack error bars, standard deviations, or statistical significance tests against baselines, making it impossible to confirm the claimed improvements are reliable rather than artifacts of specific seeds or post-hoc tuning.
minor comments (2)
- [§3] Notation for the similarity loss is introduced without an explicit equation reference in the main text, requiring cross-reference to the appendix for full understanding.
- [Figure 2] Figure 2 caption does not specify the exact frequency filter parameters used in the visualized samples.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, proposing revisions to strengthen the work where appropriate.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): Robustness is demonstrated only against the specific simulated attacks used in training; no results are reported for adaptive or unsimulated removal strategies such as model extraction, quantization-aware fine-tuning, or unseen pruning, which directly undermines the SOTA robustness claim.
Authors: We thank the referee for this observation. Our training incorporates simulated attacks to promote robustness against known removal strategies, consistent with standard practices in the watermarking literature. To better substantiate the robustness claims, we will add new experiments in the revised manuscript evaluating performance under adaptive attacks, including model extraction, quantization-aware fine-tuning, and unseen pruning, with corresponding detection rates reported. revision: yes
-
Referee: [§3.2] §3.2 (Method): The frequency-domain high-frequency filtering is presented as preserving model utility, but no ablation on cutoff thresholds or their quantitative effect on task accuracy is provided, leaving the central utility-robustness balance unverified.
Authors: We agree that a quantitative ablation on cutoff thresholds is needed to verify the utility-robustness trade-off. In the revised manuscript, we will include an ablation study across multiple cutoff frequencies for each task modality, reporting the resulting changes in task accuracy alongside watermark robustness metrics. revision: yes
-
Referee: [Table 3] Table 3 (Results): Performance metrics lack error bars, standard deviations, or statistical significance tests against baselines, making it impossible to confirm the claimed improvements are reliable rather than artifacts of specific seeds or post-hoc tuning.
Authors: We acknowledge the importance of statistical validation. We will rerun key experiments over multiple random seeds, add error bars and standard deviations to Table 3 and other result tables, and include statistical significance tests (e.g., t-tests) comparing ComMark against baselines in the revised manuscript. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation rather than self-referential derivations
full rationale
The paper introduces ComMark as a black-box watermarking method that applies frequency-domain filtering to create compressed samples, incorporates simulated attacks and a similarity loss during training, and reports SOTA covertness/robustness via evaluations on multiple datasets, architectures, and tasks (image recognition, speech, sentiment, generation, captioning, video). No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs (e.g., no fitted parameters renamed as predictions, no self-definitional loops, no load-bearing self-citations of uniqueness theorems). The robustness claim is supported by explicit simulation during training and cross-task testing, which is an independent empirical procedure rather than a tautology. This is the expected outcome for a method paper whose central assertions are falsifiable via external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-frequency filtering can separate watermark signals from model decision boundaries without destroying utility.
Reference graph
Works this paper leans on
-
[1]
Turning your weakness into a strength: Watermarking deep neural networks by backdooring
Yossi Adi, Carsten Baum, Moustapha Cisse, Benny Pinkas, and Joseph Keshet. Turning your weakness into a strength: Watermarking deep neural networks by backdooring. In27th USENIX security symposium (USENIX Security 18), pages 1615–1631, 2018. 1, 2, 5
work page 2018
-
[2]
Discrete cosine transform.IEEE transactions on Computers, 100(1): 90–93, 2006
Nasir Ahmed, T Natarajan, and Kamisetty R Rao. Discrete cosine transform.IEEE transactions on Computers, 100(1): 90–93, 2006. 3
work page 2006
-
[3]
News-topic-classification.https:// github
Ronit Akhariya. News-topic-classification.https:// github . com / Ronit33 / agnews - pytorch - lstm,
-
[4]
The jpeg image compression algorithm.Int
Muzhir Shaban Al-Ani and Fouad Hammadi Awad. The jpeg image compression algorithm.Int. J. Adv. Eng. Technol, 6 (3):1055–1062, 2013. 2
work page 2013
-
[5]
Survey on deep neural networks in speech and vision systems.Neuro- computing, 417:302–321, 2020
Mahbubul Alam, Manar D Samad, Lasitha Vidyaratne, Alexander Glandon, and Khan M Iftekharuddin. Survey on deep neural networks in speech and vision systems.Neuro- computing, 417:302–321, 2020. 1
work page 2020
-
[6]
Abdulsalam Alkholidi, Ayman Alfalou, and Habib Hamam. A new approach for optical colored image compression using the jpeg standards.Signal Processing, 87(4):569–583, 2007. 2
work page 2007
-
[7]
Extended models and tools for high-performance part-of-speech
Masayuki Asahara and Yuji Matsumoto. Extended models and tools for high-performance part-of-speech. InCOLING 2000 Volume 1: The 18th International Conference on Com- putational Linguistics, 2000. 5
work page 2000
-
[8]
Source code.https://github.com/ yangyunfei16/ComMark, 2025
The Authors. Source code.https://github.com/ yangyunfei16/ComMark, 2025. 2
work page 2025
-
[9]
Lennart Behme, Saravanan Thirumuruganathan, Alireza Rezaei Mahdiraji, Jorge-Arnulfo Quian ´e-Ruiz, and V olker Markl. The art of losing to win: Using lossy image compression to improve data loading in deep learning pipelines. In2023 IEEE 39th International Conference on Data Engineering (ICDE), pages 936–949. IEEE, 2023. 2
work page 2023
-
[10]
Neelanjan Bhowmik, Jack W Barker, Yona Falinie A Gaus, and Toby P Breckon. Lost in compression: the impact of lossy image compression on variable size object detection within infrared imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 369–378, 2022. 2
work page 2022
-
[11]
Franziska Boenisch. A systematic review on model wa- termarking for neural networks.Frontiers in big Data, 4: 729663, 2021. 1
work page 2021
-
[12]
Karlheinz Brandenburg. Mp3 and aac explained. InAudio Engineering Society Conference: 17th International Confer- ence: High-Quality Audio Coding. Audio Engineering Soci- ety, 1999. 5
work page 1999
-
[13]
Lof: identifying density-based local outliers
Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and J¨org Sander. Lof: identifying density-based local outliers. In SIGMOD, 2000. 2
work page 2000
-
[14]
Make lossy compression meaningful for low-light images
Shilv Cai, Liqun Chen, Sheng Zhong, Luxin Yan, Jiahuan Zhou, and Xu Zou. Make lossy compression meaningful for low-light images. InProceedings of the AAAI Conference on Artificial Intelligence, pages 8236–8245, 2024. 2
work page 2024
-
[15]
A survey of ai-generated content (aigc).ACM Computing Surveys, 57(5):1–38, 2025
Yihan Cao, Siyu Li, Yixin Liu, Zhiling Yan, Yutong Dai, Philip Yu, and Lichao Sun. A survey of ai-generated content (aigc).ACM Computing Surveys, 57(5):1–38, 2025. 1
work page 2025
-
[16]
Chin-Chen Chang, Tung-Shou Chen, and Lou-Zo Chung. A steganographic method based upon jpeg and quantization ta- ble modification.Information Sciences, 141(1-2):123–138,
-
[17]
Deepmarks: A secure fingerprinting framework for digital rights management of deep learning models
Huili Chen, Bita Darvish Rouhani, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. Deepmarks: A secure fingerprinting framework for digital rights management of deep learning models. InProceedings of the 2019 on International Con- ference on Multimedia Retrieval, pages 105–113, 2019. 2
work page 2019
-
[18]
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, An- dreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2024. 1
work page 2024
-
[19]
Francisco F Cunha, Valentin Bl ¨uml, Lydia M Zopf, Andreas Walter, Michael Wagner, Wolfgang J Weninger, Lucas A Thomaz, Lu´ıs MN Tavora, Luis A da Silva Cruz, and Ser- gio MM Faria. Lossy image compression in a preclinical multimodal imaging study.Journal of Digital Imaging, 36 (4):1826–1850, 2023. 2
work page 2023
-
[20]
Very deep convolutional neural networks for raw wave- forms
Wei Dai, Chia Dai, Shuhui Qu, Juncheng Li, and Samarjit Das. Very deep convolutional neural networks for raw wave- forms. InICASSP, 2017. 4
work page 2017
-
[21]
Conditional backdoor attack via jpeg com- pression
Qiuyu Duan, Zhongyun Hua, Qing Liao, Yushu Zhang, and Leo Yu Zhang. Conditional backdoor attack via jpeg com- pression. InProceedings of the AAAI Conference on Artifi- cial Intelligence, pages 19823–19831, 2024. 2
work page 2024
-
[22]
Benjamin Dwumah. Image-caption.https://github. com / Ben74x / Image - Captioning - on - MSCoco - Dataset, 2022. 5
work page 2022
-
[23]
Dimensional- ity reduction by learning an invariant mapping
Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensional- ity reduction by learning an invariant mapping. In2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), pages 1735–1742. IEEE, 2006. 4
work page 2006
-
[24]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5
work page 2016
-
[25]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 6, 1
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Ruitao Hou, Teng Huang, Hongyang Yan, Lishan Ke, and Weixuan Tang. A stealthy and robust backdoor attack via frequency domain transform.World Wide Web, 26(5):2767– 2783, 2023. 2
work page 2023
-
[27]
Quan Huynh-Thu and Mohammed Ghanbari. Scope of va- lidity of psnr in image/video quality assessment.Electronics letters, 44(13):800–801, 2008. 5
work page 2008
-
[28]
Entangled watermarks as a defense against model extraction
Hengrui Jia, Christopher A Choquette-Choo, Varun Chan- drasekaran, and Nicolas Papernot. Entangled watermarks as a defense against model extraction. In30th USENIX security symposium (USENIX Security 21), pages 1937–1954, 2021. 1, 6
work page 1937
-
[29]
Margin-based neural network watermark- ing
Byungjoo Kim, Suyoung Lee, Seanie Lee, Sooel Son, and Sung Ju Hwang. Margin-based neural network watermark- ing. InInternational Conference on Machine Learning, pages 16696–16711. PMLR, 2023. 1, 2, 5
work page 2023
-
[30]
Efficient frequency domain-based trans- formers for high-quality image deblurring
Lingshun Kong, Jiangxin Dong, Jianjun Ge, Mingqiang Li, and Jinshan Pan. Efficient frequency domain-based trans- formers for high-quality image deblurring. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 5886–5895, 2023. 2
work page 2023
-
[31]
Jesse D Kornblum. Using jpeg quantization tables to identify imagery processed by software.digital investigation, 5:S21– S25, 2008. 4
work page 2008
-
[32]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 5
work page 2009
-
[33]
Lamyanba Laishram, Muhammad Shaheryar, Jong Taek Lee, and Soon Ki Jung. Toward a privacy-preserving face recog- nition system: A survey of leakages and solutions.ACM Computing Surveys, 57(6):1–38, 2025. 1
work page 2025
-
[34]
Plmmark: a secure and robust black-box watermarking framework for pre-trained language models
Peixuan Li, Pengzhou Cheng, Fangqi Li, Wei Du, Haodong Zhao, and Gongshen Liu. Plmmark: a secure and robust black-box watermarking framework for pre-trained language models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 14991–14999, 2023. 2
work page 2023
-
[35]
Zheng Li, Chengyu Hu, Yang Zhang, and Shanqing Guo. How to prove your model belongs to you: A blind-watermark based framework to protect intellectual property of dnn. In Proceedings of the 35th annual computer security applica- tions conference, pages 126–137, 2019. 1, 2, 5
work page 2019
-
[36]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014. 5
work page 2014
-
[37]
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. InICDM, 2008. 2
work page 2008
-
[38]
Fre- quency domain model augmentation for adversarial attack
Yuyang Long, Qilong Zhang, Boheng Zeng, Lianli Gao, Xianglong Liu, Jian Zhang, and Jingkuan Song. Fre- quency domain model augmentation for adversarial attack. InEuropean conference on computer vision, pages 549–566. Springer, 2022. 2
work page 2022
-
[39]
Sok: How robust is image classification deep neu- ral network watermarking? InS&P, 2022
Nils Lukas, Edward Jiang, Xinda Li, and Florian Ker- schbaum. Sok: How robust is image classification deep neu- ral network watermarking? InS&P, 2022. 7, 2
work page 2022
-
[40]
Ssl-wm: A black-box watermarking ap- proach for encoders pre-trained by self-supervised learning
Peizhuo Lv, Pan Li, Shenchen Zhu, Shengzhi Zhang, Kai Chen, Ruigang Liang, Chang Yue, Fan Xiang, Yuling Cai, Hualong Ma, et al. Ssl-wm: A black-box watermarking ap- proach for encoders pre-trained by self-supervised learning. arXiv preprint arXiv:2209.03563, 2022. 2
-
[41]
Peizhuo Lv, Pan Li, Shengzhi Zhang, Kai Chen, Ruigang Liang, Hualong Ma, Yue Zhao, and Yingjiu Li. A robustness- assured white-box watermark in neural networks.IEEE Transactions on Dependable and Secure Computing, 20(6): 5214–5229, 2023. 1
work page 2023
-
[42]
Mea-defender: a robust watermark against model extraction attack
Peizhuo Lv, Hualong Ma, Kai Chen, Jiachen Zhou, Shengzhi Zhang, Ruigang Liang, Shenchen Zhu, Pan Li, and Yingjun Zhang. Mea-defender: a robust watermark against model extraction attack. In2024 IEEE Symposium on Security and Privacy (SP), pages 2515–2533. IEEE, 2024. 1, 2, 5, 6, 3
work page 2024
-
[43]
Learning word vec- tors for sentiment analysis
Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vec- tors for sentiment analysis. InProceedings of the 49th an- nual meeting of the association for computational linguis- tics: Human language technologies, pages 142–150, 2011. 5
work page 2011
-
[44]
Cao Mi. Audio-scene-classification.https : / / github.com/caomi8888/pytorch- for- Audio- Classification, 2024. 5
work page 2024
-
[45]
Robust watermarking of neu- ral network with exponential weighting
Ryota Namba and Jun Sakuma. Robust watermarking of neu- ral network with exponential weighting. InProceedings of the 2019 ACM Asia Conference on Computer and Commu- nications Security, pages 228–240, 2019. 2
work page 2019
-
[46]
Hewang Nie and Songfeng Lu. Fedcrmw: Federated model ownership verification with compression-resistant model wa- termarking.Expert Systems with Applications, 249:123776,
-
[47]
Hewang Nie, Songfeng Lu, Junjun Wu, and Jianxin Zhu. Deep model intellectual property protection with compression-resistant model watermarking.IEEE Transac- tions on Artificial Intelligence, 5(7):3362–3373, 2024. 1
work page 2024
-
[48]
Knockoff nets: Stealing functionality of black-box models
Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz. Knockoff nets: Stealing functionality of black-box models. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4954–4963, 2019. 6, 1
work page 2019
-
[49]
Kaiyi Pang, Tao Qi, Chuhan Wu, Minhao Bai, Minghu Jiang, and Yongfeng Huang. Modelshield: Adaptive and robust wa- termark against model extraction attack.IEEE Transactions on Information Forensics and Security, 2025. 2
work page 2025
-
[50]
Practi- cal black-box attacks against machine learning
Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami. Practi- cal black-box attacks against machine learning. InProceed- ings of the 2017 ACM on Asia conference on computer and communications security, pages 506–519, 2017. 6, 1
work page 2017
-
[51]
Omkar Parkhi, Andrea Vedaldi, and Andrew Zisserman. Deep face recognition. InBMVC 2015-Proceedings of the British Machine Vision Conference 2015. British Machine Vision Association, 2015. 5
work page 2015
-
[52]
Language models are unsu- pervised multitask learners.OpenAI blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsu- pervised multitask learners.OpenAI blog, 2019. 5
work page 2019
-
[53]
264 and MPEG-4 video compression: video coding for next-generation multimedia
Iain E Richardson.H. 264 and MPEG-4 video compression: video coding for next-generation multimedia. John Wiley & Sons, 2004. 5
work page 2004
-
[54]
A dataset and taxonomy for urban sound research
Justin Salamon, Christopher Jacoby, and Juan Pablo Bello. A dataset and taxonomy for urban sound research. InPro- ceedings of the 22nd ACM international conference on Mul- timedia, pages 1041–1044, 2014. 5
work page 2014
-
[55]
Wojciech Samek, Gr ´egoire Montavon, Sebastian La- puschkin, Christopher J Anders, and Klaus-Robert M ¨uller. Explaining deep neural networks and beyond: A review of methods and applications.Proceedings of the IEEE, 109(3): 247–278, 2021. 1
work page 2021
-
[56]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 5
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[57]
Image-generation.https : / / github
Taarun Srinivas. Image-generation.https : / / github . com / Taarun - Srinivas / Fashion - MNIST- classification- using- autoencoders,
-
[58]
The german traffic sign recognition bench- mark: a multi-class classification competition
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. The german traffic sign recognition bench- mark: a multi-class classification competition. InThe 2011 international joint conference on neural networks, pages 1453–1460. IEEE, 2011. 4
work page 2011
-
[59]
Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, and Joel S Emer. Efficient processing of deep neural networks: A tutorial and survey.Proceedings of the IEEE, 105(12):2295–2329, 2017. 1
work page 2017
-
[60]
Deep neural network watermarking against model extraction attack
Jingxuan Tan, Nan Zhong, Zhenxing Qian, Xinpeng Zhang, and Sheng Li. Deep neural network watermarking against model extraction attack. InProceedings of the 31st ACM international conference on multimedia, pages 1588–1597,
-
[61]
Exposing model theft: A robust and transferable watermark for thwarting model extraction attacks
Ruixiang Tang, Hongye Jin, Mengnan Du, Curtis Wiging- ton, Rajiv Jain, and Xia Hu. Exposing model theft: A robust and transferable watermark for thwarting model extraction attacks. InProceedings of the 32nd ACM International Con- ference on Information and Knowledge Management, pages 4315–4319, 2023. 6
work page 2023
-
[62]
Embedding watermarks into deep neural networks
Yusuke Uchida, Yuki Nagai, Shigeyuki Sakazawa, and Shin’ichi Satoh. Embedding watermarks into deep neural networks. InProceedings of the 2017 ACM on international conference on multimedia retrieval, pages 269–277, 2017. 2
work page 2017
-
[63]
Visualizing data using t-sne.JMLR, 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.JMLR, 2008. 8
work page 2008
-
[64]
The jpeg still picture compression stan- dard.Communications of the ACM, 34(4):30–44, 1991
Gregory K Wallace. The jpeg still picture compression stan- dard.Communications of the ACM, 34(4):30–44, 1991. 2, 5
work page 1991
-
[65]
A comprehensive survey on robust image watermarking.Neurocomputing, 488:226–247, 2022
Wenbo Wan, Jun Wang, Yunming Zhang, Jing Li, Hui Yu, and Jiande Sun. A comprehensive survey on robust image watermarking.Neurocomputing, 488:226–247, 2022. 1
work page 2022
-
[66]
Riga: Covert and robust white-box watermarking of deep neural networks
Tianhao Wang and Florian Kerschbaum. Riga: Covert and robust white-box watermarking of deep neural networks. In Proceedings of the web conference 2021, pages 993–1004,
work page 2021
-
[67]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 5
work page 2004
-
[68]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
Pete Warden. Speech commands: A dataset for limited- vocabulary speech recognition.arXiv:1804.03209, 2018. 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[69]
Robust watermarking against arbitrary scaling and cropping attacks
Shaowu Wu, Wei Lu, Xiaolin Yin, and Rui Yang. Robust watermarking against arbitrary scaling and cropping attacks. Signal Processing, 226:109655, 2025. 2
work page 2025
-
[70]
Invisible dnn watermarking against model ex- traction attack.IEEE Transactions on Cybernetics, 2024
Zuping Xi, Zuomin Qu, Wei Lu, Xiangyang Luo, and Xi- aochun Cao. Invisible dnn watermarking against model ex- traction attack.IEEE Transactions on Cybernetics, 2024. 1
work page 2024
-
[71]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion- mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv:1708.07747, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[72]
Rethink- ing{White-Box}watermarks on deep learning models un- der neural structural obfuscation
Yifan Yan, Xudong Pan, Mi Zhang, and Min Yang. Rethink- ing{White-Box}watermarks on deep learning models un- der neural structural obfuscation. In32nd USENIX Security Symposium (USENIX Security 23), pages 2347–2364, 2023. 1
work page 2023
-
[73]
Sze Jue Yang, Quang Nguyen, Chee Seng Chan, and Khoa D Doan. Everyone can attack: Repurpose lossy compression as a natural backdoor attack.arXiv preprint arXiv:2308.16684,
-
[74]
In- visible backdoor attacks using data poisoning in frequency domain
Chang Yue, Peizhuo Lv, Ruigang Liang, and Kai Chen. In- visible backdoor attacks using data poisoning in frequency domain. InECAI 2023, pages 2954–2961. IOS Press, 2023. 2
work page 2023
-
[75]
Video-action-recognition.https : / / github
Jianfeng Zhang. Video-action-recognition.https : / / github . com / jfzhang95 / pytorch - video - recognition, 2018. 5
work page 2018
-
[76]
Protecting intel- lectual property of deep neural networks with watermarking
Jialong Zhang, Zhongshu Gu, Jiyong Jang, Hui Wu, Marc Ph Stoecklin, Heqing Huang, and Ian Molloy. Protecting intel- lectual property of deep neural networks with watermarking. InProceedings of the 2018 on Asia conference on computer and communications security, pages 159–172, 2018. 1, 2, 5
work page 2018
-
[77]
Model watermarking for image processing networks
Jie Zhang, Dongdong Chen, Jing Liao, Han Fang, Weim- ing Zhang, Wenbo Zhou, Hao Cui, and Nenghai Yu. Model watermarking for image processing networks. InProceed- ings of the AAAI conference on artificial intelligence, pages 12805–12812, 2020. 1
work page 2020
-
[78]
Jie Zhang, Dongdong Chen, Jing Liao, Weiming Zhang, Huamin Feng, Gang Hua, and Nenghai Yu. Deep model in- tellectual property protection via deep watermarking.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(8):4005–4020, 2021. 1
work page 2021
-
[79]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 5
work page 2018
-
[80]
Character- level convolutional networks for text classification.NeurIPS,
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character- level convolutional networks for text classification.NeurIPS,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.