Recognition: no theorem link
Empirical Evaluation of Structured Synthetic Data Privacy Metrics: Novel experimental framework
Pith reviewed 2026-05-16 21:40 UTC · model grok-4.3
The pith
A framework evaluates tabular synthetic data privacy metrics by deliberately inserting known risks and measuring detection under no-box conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that deliberately inserting specific privacy risks into synthetic tabular data, then testing whether quantification methods detect them, provides an empirical way to assess the efficacy of those methods under no-box threat models on publicly available datasets.
What carries the argument
Controlled deliberate risk insertion into synthetic tabular data to test privacy quantification methods.
If this is right
- Privacy metrics can be ranked by their ability to detect deliberately inserted risks across multiple datasets.
- The framework supplies a repeatable benchmark for comparing synthetic data generators on privacy grounds.
- Legal compliance arguments for synthetic data can be grounded in empirical detection rates rather than theoretical properties alone.
- No-box threat models become testable rather than assumed, allowing direct measurement of residual identification risk.
Where Pith is reading between the lines
- The same insertion approach could be adapted to test privacy metrics on non-tabular data such as time series or graphs.
- If insertion patterns match known real-world breach vectors, regulators could adopt the framework as a certification test for privacy-enhancing technologies.
- Extending the method to measure utility loss alongside risk detection would reveal trade-offs that current single-metric evaluations miss.
Load-bearing premise
Deliberately inserting specific risks into synthetic data accurately models real-world privacy threats under no-box conditions.
What would settle it
Run the framework on a dataset where the inserted risks are known to be undetectable by any metric or where real-world attacks succeed despite the metrics reporting low risk; mismatch between inserted risks and metric scores would falsify the framework's validity.
Figures























read the original abstract
Synthetic data generation is gaining traction as a privacy enhancing technology (PET). When properly generated, synthetic data preserve the analytic utility of real data while avoiding the retention of information that would allow the identification of specific individuals. However, the concept of data privacy remains elusive, making it challenging for practitioners to evaluate and benchmark the degree of privacy protection offered by synthetic data. In this paper, we propose a framework to empirically assess the efficacy of tabular synthetic data privacy quantification methods through controlled, deliberate risk insertion. To demonstrate this framework, we survey existing approaches to synthetic data privacy quantification and the related legal theory. We then apply the framework to the main privacy quantification methods with no-box threat models on publicly available datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an empirical framework for assessing the efficacy of tabular synthetic data privacy quantification methods by using controlled, deliberate risk insertion to create ground-truth labels for benchmarking under no-box threat models. It surveys existing privacy quantification approaches and legal theory, then applies the framework to main methods on public datasets.
Significance. If the framework is shown to be valid, it would be significant for the field by providing a practical method to empirically evaluate and compare privacy metrics for synthetic data, helping to address the elusive nature of privacy assessment in privacy-enhancing technologies.
major comments (2)
- [Proposed framework] The framework's reliance on deliberate risk insertion to simulate no-box attacker capabilities is a load-bearing assumption that lacks justification. Inserting risks requires knowledge of original records or generator internals, which is unavailable in a true no-box setting where only the synthetic table is provided; this may cause the inserted signals to be either undetectable by realistic attacks or detectable only due to procedural artifacts, undermining the ground-truth mapping.
- [Abstract] Although the abstract states that the framework is applied to main privacy quantification methods, no concrete results, validation steps, or error analysis are provided, leaving the central empirical claim without demonstrated support.
minor comments (1)
- [Survey of approaches] The survey of existing approaches to synthetic data privacy quantification and legal theory would benefit from clearer integration with how they inform the design of the proposed framework.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying the framework design and manuscript content while committing to targeted revisions for improved justification and clarity.
read point-by-point responses
-
Referee: [Proposed framework] The framework's reliance on deliberate risk insertion to simulate no-box attacker capabilities is a load-bearing assumption that lacks justification. Inserting risks requires knowledge of original records or generator internals, which is unavailable in a true no-box setting where only the synthetic table is provided; this may cause the inserted signals to be either undetectable by realistic attacks or detectable only due to procedural artifacts, undermining the ground-truth mapping.
Authors: The framework deliberately separates the experimental setup (controlled risk insertion by the evaluator to establish ground-truth labels) from the threat model under which the metrics are tested (strictly no-box, with metrics receiving only the synthetic table). This is analogous to standard benchmarking practices in privacy research, such as membership inference evaluations that use known labels for ground truth while testing black-box attacks. We acknowledge that the manuscript would benefit from explicit discussion of this distinction, potential procedural artifacts, and limitations in simulating realistic no-box conditions. We will revise the methodology section to provide this justification and analysis. revision: yes
-
Referee: [Abstract] Although the abstract states that the framework is applied to main privacy quantification methods, no concrete results, validation steps, or error analysis are provided, leaving the central empirical claim without demonstrated support.
Authors: The abstract is intentionally concise and summarizes the application at a high level. Concrete results—including quantitative comparisons of privacy metrics, validation across public datasets, and error analysis—are detailed in the experimental sections of the full manuscript. To improve accessibility, we will revise the abstract to include a brief mention of key empirical outcomes and validation approach. revision: yes
Circularity Check
No circularity: empirical framework applies existing methods without self-referential reduction
full rationale
The paper proposes an empirical evaluation framework that inserts controlled privacy risks into synthetic tabular data and then applies existing no-box privacy quantification methods to public datasets. No equations, derivations, fitted parameters, or uniqueness theorems are present. The central claim rests on the methodological design of risk insertion and benchmarking rather than any reduction to self-citations, self-definitions, or renamed known results. The approach is self-contained as an application of prior independent quantification techniques, with no load-bearing step that collapses to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption No-box threat models are appropriate for assessing synthetic data privacy risks
- domain assumption Deliberate insertion of known risks can serve as a valid ground truth for metric evaluation
Reference graph
Works this paper leans on
-
[1]
Mauro Giuffrè and Dennis Shung. Harnessing the power of synthetic data in healthcare: innovation, application, and privacy.npj Digital Medicine, 6, 10 2023
work page 2023
-
[2]
Generation and evaluation of synthetic patient data.BMC Medical Research Methodology, 2020
Andre Goncalves, Priyadip Ray, Braden Soper, Jennifer Stevens, Linda Coyle, and Anna Paula Slaes. Generation and evaluation of synthetic patient data.BMC Medical Research Methodology, 2020
work page 2020
-
[3]
Vamsi K. Potluru, Daniel Borrajo, Andrea Coletta, Niccolò Dalmasso, Yousef El-Laham, Elizabeth Fons, Mohsen Ghassemi, Sriram Gopalakrishnan, Vikesh Gosai, Eleonora Kreaˇci´c, Ganapathy Mani, Saheed Obitayo, Deepak Paramanand, Natraj Raman, Mikhail Solonin, Srijan Sood, Svitlana Vyetrenko, Haibei Zhu, Manuela Veloso, and Tucker Balch. Synthetic data applic...
work page 2024
-
[4]
Michal S. Gal and Orla Lynskey. Synthetic data: Legal implications of the data-generation revolution.Iowa Law Review, 109(1087):1087–1154, 2024
work page 2024
-
[5]
Synthetic data: A look back and a look forward.Trans
Jerome P Reiter. Synthetic data: A look back and a look forward.Trans. Data Priv., 16(1):15–24, 2023
work page 2023
-
[6]
Ana Beduschi. Synthetic data protection: Towards a paradigm change in data regulation?Big Data & Society, 11(1):20539517241231277, 2024
work page 2024
-
[7]
Steven M. Bellovin, K. Dutta, Preetam, and N. Reitinger. Privacy and synthetic datasets.Stanford Technology Law Review, 2018
work page 2018
-
[8]
Practical privacy metrics for synthetic data, 2024
Gillian M Raab, Beata Nowok, and Chris Dibben. Practical privacy metrics for synthetic data, 2024
work page 2024
-
[9]
Ferraris, Daniele Panfilo, Vanessa Cocca, Sabrina Zinutti, Karel Schepper, and Carlo Chauvenet
Alexander Boudewijn, Andrea F. Ferraris, Daniele Panfilo, Vanessa Cocca, Sabrina Zinutti, Karel Schepper, and Carlo Chauvenet. Privacy measurement in tabular synthetic data: State of the art and future research directions. 10 2023. 19 APREPRINT- DECEMBER19, 2025
work page 2023
-
[10]
A unified framework for quantifying privacy risk in synthetic data, 2022
Matteo Giomi, Franziska Boenisch, Christoph Wehmeyer, and Borbála Tasnádi. A unified framework for quantifying privacy risk in synthetic data, 2022
work page 2022
-
[11]
A. Gonzales, G. Guruswamy, and S. R. Smith. Synthetic data in health care: A narrative review.PLOS Digital Health, 2(1):e0000082, 2023
work page 2023
-
[12]
M. Giuffrè and D. L. Shung. Harnessing the power of synthetic data in healthcare: Innovation, application, and privacy.NPJ Digital Medicine, 6(1):186, 2023
work page 2023
-
[13]
James Jordon, Lukasz Szpruch, Florimond Houssiau, Mirko Bottarelli, Giovanni Cherubin, Carsten Maple, Samuel N. Cohen, and Adrian Weller. Synthetic data - what, why and how? 2022
work page 2022
- [14]
-
[15]
Morgan Guillaudeux, Olicia Rousseau, Julien Petot, Zineb Bennis, Charles-Axel Dein, Thomas Goronflot, Nicolas Vince, Sophie Limou, Matilde Karakachoff, Matthieu Wargny, and Pierre-Antoine Gourraud. Patient-centric synthetic data generation, no reason to risk reidentification in biomedical data analysis.NPJ Digital Medicine, (6(37)), 2023
work page 2023
-
[16]
Buckeridge, and Khaled El Emam
Jean-Francois Rajotte, Robert Bergen, David L. Buckeridge, and Khaled El Emam. Synthetic data as an enabler for machine learning applications in medicine.iScience, 25(11):105331, 2022
work page 2022
-
[17]
A. Boudewijn and A. F. Ferraris. Legal and regulatory perspectives on synthetic data as an anonymization strategy. Journal of Personal Data Protection Law, 1:17–31, 2024
work page 2024
-
[18]
James Jordon, Lukasz Szpruch, Florimond Houssiau, Mirko Bottarelli, Giovanni Cherubin, Carsten Maple, Samuel N. Cohen, and Adrian Weller. Synthetic data – what, why and how?, 2022
work page 2022
-
[19]
Survey on synthetic data generation, evaluation methods and gans.Mathematics, 10(15), 2022
Alvaro Figueira and Bruno Vaz. Survey on synthetic data generation, evaluation methods and gans.Mathematics, 10(15), 2022
work page 2022
-
[20]
A survey on generative adversarial networks: Variants, applications, and training, 2020
Abdul Jabbar, Xi Li, and Bourahla Omar. A survey on generative adversarial networks: Variants, applications, and training, 2020. [21]Opinion 4/2007 on the concept of personal data, 2007
work page 2020
-
[21]
Opinion 05/2014 on anonymisation techniques, 2014
Article 29 Working Party on the Protection of Individuals with regard to the Processing of Personal Data. Opinion 05/2014 on anonymisation techniques, 2014
work page 2014
-
[22]
Cesar A.F. López and Abdullah Elbi. On the legal nature of synthetic data.Proceedings of the Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[23]
Advancing microdata privacy protection: A review of synthetic data, 2023
Jingchen Hu and Claire McKay Bowen. Advancing microdata privacy protection: A review of synthetic data, 2023
work page 2023
-
[24]
Failure modes in machine learning systems, 2019
Ram Shankar Siva Kumar, David O Brien, Kendra Albert, Salomé Viljöen, and Jeffrey Snover. Failure modes in machine learning systems, 2019
work page 2019
-
[25]
Synthetic data – anonymisation groundhog day, 2022
Theresa Stadler, Bristena Oprisanu, and Carmela Troncoso. Synthetic data – anonymisation groundhog day, 2022
work page 2022
-
[26]
Lisa Pilgram, Fida K. Dankar, Jorg Drechsler, Mark Elliot, Josep Domingo-Ferrer, Paul Francis, Murat Kantar- cioglu, Linglong Kong, Bradley Malin, Krishnamurty Muralidhar, Puja Myles, Fabian Prasser, Jean Louis Raisaro, Chao Yan, and Khaled El Emam. A consensus privacy metrics framework for synthetic data, 2025
work page 2025
-
[27]
Can we trust synthetic data in medicine? a scoping review of privacy and utility metrics, 11 2023
Bayrem Kaabachi, Jérémie Despraz, Thierry Meurers, Karen Otte, Mehmed Halilovic, Fabian Prasser, and Jean Louis Raisaro. Can we trust synthetic data in medicine? a scoping review of privacy and utility metrics, 11 2023
work page 2023
-
[28]
Pablo A Osorio-Marulanda, Gorka Epelde, Mikel Hernandez, Imanol Isasa, Nicolas Moreno Reyes, and An- doni Beristain Iraola. Privacy mechanisms and evaluation metrics for synthetic data generation: A systematic review.IEEE Access, 2024
work page 2024
-
[29]
Standardised metrics and methods for synthetic tabular data evaluation, 09 2021
Mikel Hernandez, Gorka Epelde, Ane Alberdi, Rodrigo Cilla, and Debbie Rankin. Standardised metrics and methods for synthetic tabular data evaluation, 09 2021
work page 2021
-
[30]
Chao Yan, Yao Yan, Zhiyu Wan, Ziqi Zhang, Larsson Omberg, Justin Guinney, Sean Mooney, and Bradley Malin. A multifaceted benchmarking of synthetic electronic health record generation models.Nature Communications, 13, 12 2022
work page 2022
-
[31]
Sure: A new privacy and utility assessment library for synthetic data
Dario Brunelli, Shalini Kurapati, and Luca Gilli. Sure: A new privacy and utility assessment library for synthetic data. In2024 IEEE International Conference on Blockchain (Blockchain), pages 643–648, 2024. 20 APREPRINT- DECEMBER19, 2025
work page 2024
-
[32]
Membership inference attacks against synthetic data through overfitting detection, 2023
Boris van Breugel, Hao Sun, Zhaozhi Qian, and Mihaela van der Schaar. Membership inference attacks against synthetic data through overfitting detection, 2023
work page 2023
-
[33]
Steven Golob.Privacy Vulnerabilities in Marginals-based Synthetic Data. PhD thesis, 2024
work page 2024
-
[34]
Achilles’ heels: Vulnerable record identification in synthetic data publishing, 2023
Matthieu Meeus, Florent Guepin, Ana-Maria Cretu, and Yves-Alexandre de Montjoye. Achilles’ heels: Vulnerable record identification in synthetic data publishing, 2023
work page 2023
-
[35]
Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy.Foundations and Trends® in Theoretical Computer Science, 9(3–4):211–407, 2014
work page 2014
-
[36]
Differentially private synthetic data: Applied evaluations and enhancements, 2020
Lucas Rosenblatt, Xiaoyan Liu, Samira Pouyanfar, Eduardo de Leon, Anuj Desai, and Joshua Allen. Differentially private synthetic data: Applied evaluations and enhancements, 2020
work page 2020
-
[37]
Differentially private generative adversarial network, 2018
Liyang Xie, Kaixiang Lin, Shu Wang, Fei Wang, and Jiayu Zhou. Differentially private generative adversarial network, 2018
work page 2018
-
[38]
PATE-GAN: Generating synthetic data with differential privacy guarantees
Jinsung Yoon, James Jordon, and Mihaela van der Schaar. PATE-GAN: Generating synthetic data with differential privacy guarantees. InInternational Conference on Learning Representations, 2019
work page 2019
-
[39]
Geyer, Tassilo Klein, and Moin Nabi
Robin C. Geyer, Tassilo Klein, and Moin Nabi. Differentially private federated learning: A client level perspective, 2018
work page 2018
-
[40]
SDNist v2: Deidentified Data Report Tool, March 2023
Christine Task, Karan Bhagat, and Gary Howarth. SDNist v2: Deidentified Data Report Tool, March 2023
work page 2023
-
[41]
truly anonymous synthetic data
Georgi Ganev and Emiliano De Cristofaro. On the inadequacy of similarity-based privacy metrics: Reconstruction attacks against" truly anonymous synthetic data”.arXiv preprint arXiv:2312.05114, 2023
-
[42]
Gillian M. Raab. Utility and disclosure risk for differentially private synthetic categorical data. In Josep Domingo- Ferrer and Maryline Laurent, editors,Privacy in Statistical Databases, pages 250–265, Cham, 2022. Springer International Publishing
work page 2022
-
[43]
Smooth-gan: Towards sharp and smooth synthetic ehr data generation
Sina Rashidian, Fusheng Wang, Richard Moffitt, Victor Garcia, Anurag Dutt, Wei Chang, Vishwam Pandya, Janos Hajagos, Mary Saltz, and Joel Saltz. Smooth-gan: Towards sharp and smooth synthetic ehr data generation. In Martin Michalowski and Robert Moskovitch, editors,Artificial Intelligence in Medicine, pages 37–48, Cham,
-
[44]
Springer International Publishing
-
[45]
Cristóbal Esteban, Stephanie L. Hyland, and Gunnar Rätsch. Real-valued (medical) time series generation with recurrent conditional gans, 2017
work page 2017
-
[46]
A deep learning-based pipeline for the generation of synthetic tabular data
Daniele Panfilo, Alexander Boudewijn, Sebastiano Saccani, Andrea Coser, Borut Svara, Carlo Rossi Chauvenet, Ciro Antonio Mami, and Eric Medvet. A deep learning-based pipeline for the generation of synthetic tabular data. IEEE Access, pages 1–1, 2023
work page 2023
-
[47]
Holdout-based empirical assessment of mixed-type synthetic data
Michael Platzer and Thomas Reutterer. Holdout-based empirical assessment of mixed-type synthetic data. Frontiers in Big Data, 2021
work page 2021
-
[48]
Nfdi4health workflow and service for synthetic data generation, assessment and risk management, 2024
Sobhan Moazemi, Tim Adams, Hwei Geok NG, Lisa Kühnel, Julian Schneider, Anatol-Fiete Näher, Juliane Fluck, and Holger Fröhlich. Nfdi4health workflow and service for synthetic data generation, assessment and risk management, 2024
work page 2024
-
[49]
Edward Choi, Siddharth Biswal, Bradley Malin, Jon Duke, Walter F. Stewart, and Jimeng Sun. Generating multi-label discrete patient records using generative adversarial networks, 2018
work page 2018
-
[50]
M. Naldi G. D’Acquisto.Big Data e Privacy by design. Anonimizzazione, pseudonimizzazione, sicurezza. Giappichelli, 2017
work page 2017
-
[51]
Logan: Membership inference attacks against generative models, 2018
Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. Logan: Membership inference attacks against generative models, 2018
work page 2018
-
[52]
Gan-leaks: A taxonomy of membership inference attacks against generative models
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. Gan-leaks: A taxonomy of membership inference attacks against generative models. InProceedings of the 2020 ACM SIGSAC conference on computer and communications security, pages 343–362, 2020
work page 2020
-
[53]
Benjamin Hilprecht, Martin Härterich, and Daniel Bernau. Monte carlo and reconstruction membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019
work page 2019
-
[54]
Florimond Houssiau, James Jordon, Samuel N. Cohen, Owen Daniel, Andrew Elliott, James Geddes, Callum Mole, Camila Rangel-Smith, and Lukasz Szpruch. Tapas: a toolbox for adversarial privacy auditing of synthetic data, 2022
work page 2022
-
[55]
Rémy Chapelle and Bruno Falissard. Statistical properties and privacy guarantees of an original distance-based fully synthetic data generation method, 2023. 21 APREPRINT- DECEMBER19, 2025
work page 2023
-
[56]
Creating the best risk-utility profile : The synthetic data challenge, 2015
Mark Elliot. Creating the best risk-utility profile : The synthetic data challenge, 2015
work page 2015
-
[57]
Yingrui Chen, Jennifer Taub, and Mark Elliot. The trade-off between information utility and disclosure risk in a ga synthetic data generator.Joint UNECE/Eurostat Work Session on Statistical Data Confidentiality, 2019
work page 2019
-
[58]
The privacy onion effect: Memorization is relative, 2022
Nicholas Carlini, Matthew Jagielski, Chiyuan Zhang, Nicolas Papernot, Andreas Terzis, and Florian Tramer. The privacy onion effect: Memorization is relative, 2022
work page 2022
-
[59]
Membership inference attacks against gans by leveraging over-representation regions
Hailong Hu and Jun Pang. Membership inference attacks against gans by leveraging over-representation regions. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, CCS ’21, page 2387–2389, New York, NY , USA, 2021. Association for Computing Machinery
work page 2021
-
[60]
A linear reconstruction approach for attribute inference attacks against synthetic data, 2024
Meenatchi Sundaram Muthu Selva Annamalai, Andrea Gadotti, and Luc Rocher. A linear reconstruction approach for attribute inference attacks against synthetic data, 2024
work page 2024
-
[61]
Aivin V . Solatorio and Olivier Dupriez. Realtabformer: Generating realistic relational and tabular data using transformers, 2023
work page 2023
-
[62]
Beata Nowok, Gillian M. Raab, and Chris Dibben. Synthpop: Bespoke creation of synthetic data in r.Journal of Statistical Software, 74(11):1–26, 2016
work page 2016
-
[63]
The smartnoise system: Aim, 2024
Open Differential Privacy (OpenDP). The smartnoise system: Aim, 2024. https://github.com/opendp/ smartnoise-sdk
work page 2024
-
[64]
Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
Nicolas Papernot, Martín Abadi, Ulfar Erlingsson, Ian Goodfellow, and Kunal Talwar. Semi-supervised knowledge transfer for deep learning from private training data.arXiv preprint arXiv:1610.05755, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[65]
Sure: A new privacy and utility assessment library for synthetic data
Dario Brunelli, Shalini Kurapati, and Luca Gilli. Sure: A new privacy and utility assessment library for synthetic data. In2024 IEEE International Conference on Blockchain (Blockchain), pages 643–648, 2024
work page 2024
-
[66]
Synthcity: facilitating innovative use cases of synthetic data in different data modalities, 2023
Zhaozhi Qian, Bogdan-Constantin Cebere, and Mihaela van der Schaar. Synthcity: facilitating innovative use cases of synthetic data in different data modalities, 2023
work page 2023
-
[67]
Jennifer Taub, Mark James Elliot, and Gillian M. Raab. Creating the best risk-utility profile : The synthetic data challenge. 2019
work page 2019
-
[68]
Block neural autoregressive flow
Nicola De Cao, Wilker Aziz, and Ivan Titov. Block neural autoregressive flow. InUncertainty in artificial intelligence, pages 1263–1273. PMLR, 2020
work page 2020
-
[69]
Barry Becker and Ronny Kohavi. Adult. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5XW20
-
[70]
Texas hospital discharge data pub- lic use data., 2005
Center for Health Statistics Texas Department of State Health Services. Texas hospital discharge data pub- lic use data., 2005. https://www.dshs.texas.gov/texas-health-care-information-collection/ general-public-information/hospital-discharge-data-public
work page 2005
-
[71]
Ipums usa: Version 8.0 extract of 1940 census for u.s
Steven Ruggles, Sarah Flood, Ronald Goeken, Josiah Grover, Erin Meyer, Jose Pacas, and Matthew Sobek. Ipums usa: Version 8.0 extract of 1940 census for u.s. census bureau disclosure avoidance research. minneapolis, mn: Ipums, 2008. DOI: https://doi.org/10.18128/D010.V8.0.EXT1940USCB
-
[72]
The secret sharer: Evaluating and testing unintended memorization in neural networks, 2019
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks, 2019
work page 2019
-
[73]
The dcr delusion: Measuring the privacy risk of synthetic data
Zexi Yao, Nataša Krˇco, Georgi Ganev, and Yves-Alexandre de Montjoye. The dcr delusion: Measuring the privacy risk of synthetic data. InEuropean Symposium on Research in Computer Security, pages 469–487. Springer, 2025
work page 2025
-
[74]
From isolation to identification
Giuseppe D’Acquisto, Aloni Cohen, Maurizio Naldi, and Kobbi Nissim. From isolation to identification. In Privacy in Statistical Databases: International Conference, PSD 2024, Antibes Juan-Les-Pins, France, September 25–27, 2024, Proceedings, page 3–17, Berlin, Heidelberg, 2024. Springer-Verlag
work page 2024
-
[75]
Texas”) [ 70], and the 1940 Census full enumeration from IPUMS USA (“Census
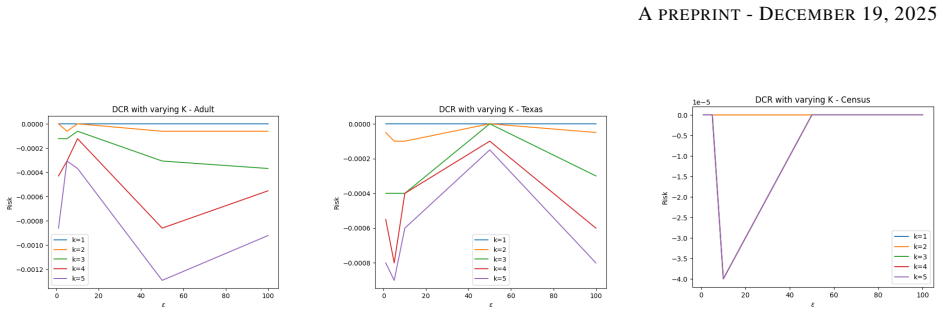
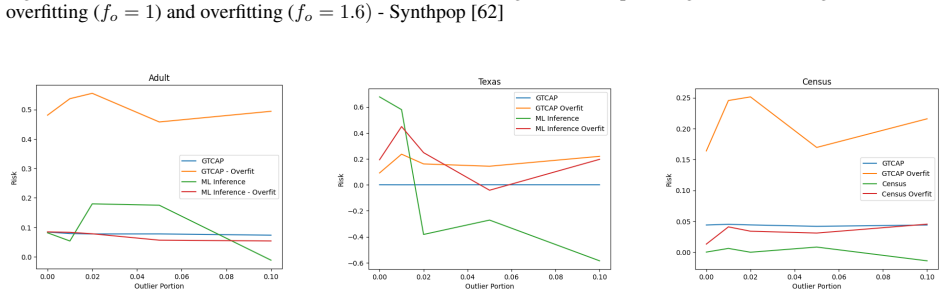
Milton Nicolás Plasencia Palacios, Sebastiano Saccani, Gabriele Sgroi, Alexander Boudewijn, and Luca Bortolussi. Contrastive learning-based privacy metrics in tabular synthetic datasets, 2025. 22 APREPRINT- DECEMBER19, 2025 A Complete experimental results Figure 2: Risk assessment methods evaluated using the leaky risk model Figure 3: Risk assessment meth...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.