Recognition: no theorem link
MMLANDMARKS: a Cross-View Instance-Level Benchmark for Geo-Spatial Understanding
Pith reviewed 2026-05-16 20:46 UTC · model grok-4.3
The pith
The MMLandmarks dataset supplies instance-level matches across aerial images, ground views, text, and coordinates for 18,557 US landmarks to support multimodal geo-spatial model training and benchmarking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMLandmarks establishes one-to-one landmark correspondences across four modalities, enabling models to address cross-view Ground-to-Satellite retrieval, ground and satellite geolocalization, Text-to-Image retrieval, and Text-to-GPS retrieval. Current models cannot trivially solve these tasks, revealing a gap that multimodal aligned datasets can fill for broader geo-spatial understanding.
What carries the argument
The instance-level one-to-one correspondence between the four modalities for each landmark, which carries the argument by providing aligned training signals across views.
If this is right
- Cross-view Ground-to-Satellite retrieval can be trained directly using the matched image pairs.
- Ground and satellite geolocalization benefit from joint training on aligned modalities.
- Text-to-Image and Text-to-GPS retrieval tasks become benchmarkable with the provided correspondences.
- A CLIP-style model trained on MMLandmarks achieves broad generalization across the geo-spatial tasks.
Where Pith is reading between the lines
- Applications in mapping and navigation could integrate satellite and street-level data more effectively with such alignments.
- The identified performance gap may encourage creation of similar multimodal datasets for other geographic regions or object types.
- Future work could test whether scaling the dataset size further closes the gap for foundation models in this domain.
- Instance-level alignment might prove more critical than model architecture choices for advancing geo-spatial multimodal learning.
Load-bearing premise
The collected images, text, and coordinates correspond to the same physical landmarks at the instance level with sufficient quality and diversity for meaningful cross-modal training.
What would settle it
A verification process that finds many mismatched landmarks across modalities or shows that models trained on the dataset perform no better than separate-modality models on the defined tasks would falsify the central claim.
Figures













read the original abstract
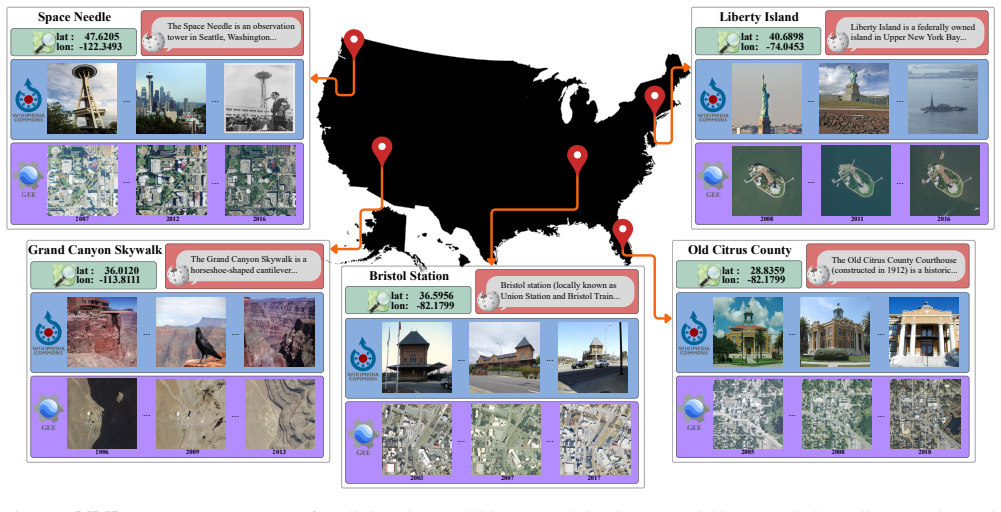
Geo-spatial analysis of our world benefits from a multimodal approach, as every single geographic location can be described in numerous ways (images from various viewpoints, textual descriptions, geographic coordinates, etc.). Current benchmarks have limited coverage across modalities, leading to specialized models that perform well in their respective domains, but do not fully take advantage of other geo-spatial modalities. We introduce the Multi-Modal Landmark dataset (MMLandmarks), a benchmark composed of four modalities: 197k high-resolution aerial images, 329k ground-view images, textual information, and geographic coordinates for 18.557 distinct landmarks in the United States. The MMLandmarks dataset has a one-to-one landmark level correspondence across every modality, which enables training and benchmarking models for various geo-spatial tasks, including cross-view Ground-to-Satellite retrieval, ground and satellite geolocalization, Text-to-Image, and Text-to-GPS retrieval. We show that current specialized and off-the-shelf foundation models cannot be trivially used to solve this variety of geo-spatial tasks, illustrating a gap where multimodal datasets lead to broader geo-spatial understanding. We employ a simple CLIP-inspired baseline that reflects versatility and broad generalization when trained with MMLandmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MMLandmarks, a multimodal benchmark with 197k aerial images, 329k ground-view images, text, and GPS coordinates for 18,557 US landmarks claiming one-to-one instance-level correspondences across modalities. It evaluates cross-view Ground-to-Satellite retrieval, geolocalization, Text-to-Image, and Text-to-GPS tasks, showing that specialized and off-the-shelf foundation models cannot trivially solve them, while a simple CLIP-inspired baseline exhibits better versatility when trained on the dataset.
Significance. If the claimed correspondences hold with high accuracy and diversity, the dataset would fill an important gap by providing a unified multimodal resource for geo-spatial tasks, enabling training of more general models beyond domain-specialized ones and supporting reproducible benchmarking in computer vision and multimodal learning.
major comments (2)
- [Dataset construction] Dataset construction section: The pipeline for web-sourced image and text collection with one-to-one landmark matching is described only at high level and reports no quantitative validation such as precision/recall for correspondences, inter-annotator agreement, or error rates on ambiguous ground-aerial pairings. This directly undermines the central claim that the dataset supports reliable training and benchmarking, as even modest mismatch rates would induce spurious associations.
- [Experiments] Experiments section: The reported failure of existing models and success of the CLIP baseline are only weakly supported without details on train/test splits, handling of potential noisy alignments, or ablation studies quantifying the effect of correspondence quality on task performance.
minor comments (2)
- [Abstract] Abstract: '18.557' is a typographical error and should read '18,557'.
- [Abstract] Abstract: The scale and task list are stated clearly, but a one-sentence summary of collection methodology and verification steps would improve completeness without lengthening the paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the manuscript. We address each major point below and will revise the paper to incorporate additional details and validations as outlined.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: The pipeline for web-sourced image and text collection with one-to-one landmark matching is described only at high level and reports no quantitative validation such as precision/recall for correspondences, inter-annotator agreement, or error rates on ambiguous ground-aerial pairings. This directly undermines the central claim that the dataset supports reliable training and benchmarking, as even modest mismatch rates would induce spurious associations.
Authors: We agree that a high-level description alone is insufficient to fully substantiate the one-to-one correspondences. In the revised manuscript, we will expand the Dataset Construction section with quantitative validation results, including precision/recall from manual verification on a sampled subset of landmarks, inter-annotator agreement scores, and error analysis for ambiguous ground-aerial pairings. These additions will directly address concerns about potential mismatch rates and their impact on training reliability. revision: yes
-
Referee: [Experiments] Experiments section: The reported failure of existing models and success of the CLIP baseline are only weakly supported without details on train/test splits, handling of potential noisy alignments, or ablation studies quantifying the effect of correspondence quality on task performance.
Authors: We acknowledge the need for greater experimental rigor. The revised Experiments section will include explicit details on the train/test splits (with leakage prevention measures), a description of how noisy alignments were handled during training, and new ablation studies that quantify performance sensitivity to varying levels of correspondence quality. These changes will provide stronger empirical support for the baseline's versatility relative to existing models. revision: yes
Circularity Check
No circularity: dataset construction paper with independent empirical claims
full rationale
The paper's core contribution is the MMLandmarks dataset itself, which defines instance-level one-to-one correspondences across aerial images, ground images, text, and GPS for 18,557 landmarks. No mathematical derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. Claims that existing models cannot trivially solve the tasks are supported by direct empirical evaluation on the new benchmark, not by self-referential fitting or self-citation chains. The collection pipeline is described at a high level without reducing any result to prior fitted quantities from the same authors.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self- supervised material and texture representation learning for remote sensing tasks
Peri Akiva, Matthew Purri, and Matthew Leotta. Self- supervised material and texture representation learning for remote sensing tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8203–8215, 2022. 1, 3
work page 2022
-
[2]
Jean-Baptiste Alayrac, Adria Recasens, Rosalia Schneider, Relja Arandjelovi ´c, Jason Ramapuram, Jeffrey De Fauw, Lucas Smaira, Sander Dieleman, and Andrew Zisserman. Self-supervised multimodal versatile networks.Advances in neural information processing systems, 33:25–37, 2020. 3
work page 2020
-
[3]
Relja Arandjelovic and Andrew Zisserman. Look, listen and learn. InProceedings of the IEEE international confer- ence on computer vision, pages 609–617, 2017. 3
work page 2017
-
[4]
Netvlad: Cnn architecture for weakly supervised place recognition
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pa- jdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016. 3
work page 2016
-
[5]
Openstreetview-5m: The many roads to global visual geolocation
Guillaume Astruc, Nicolas Dufour, Ioannis Siglidis, Con- stantin Aronssohn, Nacim Bouia, Stephanie Fu, Romain Loiseau, Van Nguyen Nguyen, Charles Raude, Elliot Vin- cent, et al. Openstreetview-5m: The many roads to global visual geolocation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 21967–21977, 2024. 1, 3, 7
work page 2024
-
[6]
Geography-aware self-supervised learning
Kumar Ayush, Burak Uzkent, Chenlin Meng, Kumar Tan- may, Marshall Burke, David Lobell, and Stefano Ermon. Geography-aware self-supervised learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10181–10190, 2021. 1, 3
work page 2021
-
[7]
Data2vec: A general frame- work for self-supervised learning in speech, vision and lan- guage
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data2vec: A general frame- work for self-supervised learning in speech, vision and lan- guage. InInternational conference on machine learning, pages 1298–1312. PMLR, 2022. 3
work page 2022
-
[8]
Satlaspretrain: A large- scale dataset for remote sensing image understanding
Favyen Bastani, Piper Wolters, Ritwik Gupta, Joe Ferdi- nando, and Aniruddha Kembhavi. Satlaspretrain: A large- scale dataset for remote sensing image understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16772–16782, 2023. 3
work page 2023
-
[9]
Megaloc: One re- trieval to place them all
Gabriele Berton and Carlo Masone. Megaloc: One re- trieval to place them all. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2861– 2867, 2025. 1, 3
work page 2025
-
[10]
Eigenplaces: Training viewpoint robust models for visual place recognition
Gabriele Berton, Gabriele Trivigno, Barbara Caputo, and Carlo Masone. Eigenplaces: Training viewpoint robust models for visual place recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11080–11090, 2023. 1
work page 2023
-
[11]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021. 6
work page 2021
-
[12]
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sens- ing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 105(10):1865–1883, 2017. 3
work page 2017
-
[13]
Gordon Christie, Neil Fendley, James Wilson, and Ryan Mukherjee. Functional map of the world. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6172–6180, 2018. 3
work page 2018
-
[14]
Brandon Clark, Alec Kerrigan, Parth Parag Kulkarni, Vi- cente Vivanco Cepeda, and Mubarak Shah. Where we are and what we’re looking at: Query based worldwide image geo-localization using hierarchies and scenes. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23182–23190, 2023. 1, 3
work page 2023
-
[15]
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David Lobell, and Stefano Ermon. Satmae: Pre-training transformers for tem- poral and multi-spectral satellite imagery.Advances in Neu- ral Information Processing Systems, 35:197–211, 2022. 1, 3
work page 2022
-
[16]
Wildsat: Learning satel- lite image representations from wildlife observations
Rangel Daroya, Elijah Cole, Oisin Mac Aodha, Grant Van Horn, and Subhransu Maji. Wildsat: Learning satel- lite image representations from wildlife observations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6143–6154, 2025. 1, 3
work page 2025
-
[17]
Imagenet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical im- age database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009. 1
work page 2009
-
[18]
Sam- ple4geo: Hard negative sampling for cross-view geo- localisation
Fabian Deuser, Konrad Habel, and Norbert Oswald. Sam- ple4geo: Hard negative sampling for cross-view geo- localisation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 16847– 16856, 2023. 1, 3, 6, 7
work page 2023
-
[19]
Geobind: Binding text, im- age, and audio through satellite images
Aayush Dhakal, Subash Khanal, Srikumar Sastry, Adeel Ahmad, and Nathan Jacobs. Geobind: Binding text, im- age, and audio through satellite images. InIGARSS 2024- 2024 IEEE International Geoscience and Remote Sensing Symposium, pages 2729–2733. IEEE, 2024. 1, 3
work page 2024
-
[20]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 6
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[21]
Major tom: Ex- pandable datasets for earth observation
Alistair Francis and Mikolaj Czerkawski. Major tom: Ex- pandable datasets for earth observation. InIGARSS 2024- 2024 IEEE International Geoscience and Remote Sensing Symposium, pages 2935–2940. IEEE, 2024. 3
work page 2024
-
[22]
Omnivore: A single model for many visual modalities
Rohit Girdhar, Mannat Singh, Nikhila Ravi, Laurens Van Der Maaten, Armand Joulin, and Ishan Misra. Omnivore: A single model for many visual modalities. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16102–16112, 2022. 2
work page 2022
-
[23]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023. 3
work page 2023
-
[24]
9 Omnimae: Single model masked pretraining on images and videos
Rohit Girdhar, Alaaeldin El-Nouby, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 9 Omnimae: Single model masked pretraining on images and videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10406– 10417, 2023. 3
work page 2023
-
[25]
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, et al. Skysense: A multi-modal remote sens- ing foundation model towards universal interpretation for earth observation imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[26]
Audioclip: Extending clip to image, text and audio
Andrey Guzhov, Federico Raue, J ¨orn Hees, and Andreas Dengel. Audioclip: Extending clip to image, text and audio. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 976–980. IEEE, 2022. 3
work page 2022
-
[27]
Lukas Haas, Silas Alberti, and Michal Skreta. Learning generalized zero-shot learners for open-domain image ge- olocalization.arXiv preprint arXiv:2302.00275, 2023. 1, 3, 7
-
[28]
Pigeon: Predicting image geolocations
Lukas Haas, Michal Skreta, Silas Alberti, and Chelsea Finn. Pigeon: Predicting image geolocations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12893–12902, 2024. 1, 3, 7
work page 2024
-
[29]
James Hays and Alexei A. Efros. im2gps: estimating ge- ographic information from a single image. InProceedings of the IEEE Conf. on Computer Vision and Pattern Recog- nition (CVPR), 2008. 3
work page 2008
-
[30]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019. 3
work page 2019
-
[31]
Marco Helbich, Matthew Danish, SM Labib, and Britta Ricker. To use or not to use proprietary street view images in (health and place) research? that is the question.Health & Place, 87:103244, 2024. 2, 5
work page 2024
-
[32]
Gaoshuang Huang, Yang Zhou, Luying Zhao, and Wenjian Gan. Cv-cities: Advancing cross-view geo-localization in global cities.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024. 1, 3, 4, 5
work page 2024
-
[33]
Satclip: Global, general- purpose location embeddings with satellite imagery
Konstantin Klemmer, Esther Rolf, Caleb Robinson, Lester Mackey, and Marc Rußwurm. Satclip: Global, general- purpose location embeddings with satellite imagery. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 4347–4355, 2025. 3
work page 2025
-
[34]
xView: Objects in Context in Overhead Imagery
Darius Lam, Richard Kuzma, Kevin McGee, Samuel Doo- ley, Michael Laielli, Matthew Klaric, Yaroslav Bulatov, and Brendan McCord. xview: Objects in context in overhead imagery.arXiv preprint arXiv:1802.07856, 2018. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Martha Larson, Mohammad Soleymani, Guillaume Gravier, Bogdan Ionescu, and Gareth JF Jones. The bench- marking initiative for multimedia evaluation: Mediaeval 2016.IEEE MultiMedia, 24(1):93–96, 2017. 3, 5, 8
work page 2016
-
[36]
Unleash- ing unlabeled data: A paradigm for cross-view geo- localization
Guopeng Li, Ming Qian, and Gui-Song Xia. Unleash- ing unlabeled data: A paradigm for cross-view geo- localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16719– 16729, 2024. 3
work page 2024
-
[37]
S2mae: A spatial-spectral pretraining foundation model for spectral remote sensing data
Xuyang Li, Danfeng Hong, and Jocelyn Chanussot. S2mae: A spatial-spectral pretraining foundation model for spectral remote sensing data. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 24088–24097, 2024. 1, 3
work page 2024
-
[38]
Masked angle-aware au- toencoder for remote sensing images
Zhihao Li, Biao Hou, Siteng Ma, Zitong Wu, Xianpeng Guo, Bo Ren, and Licheng Jiao. Masked angle-aware au- toencoder for remote sensing images. InEuropean Confer- ence on Computer Vision, pages 260–278. Springer, 2024. 3
work page 2024
-
[39]
Valerii Likhosherstov, Anurag Arnab, Krzysztof Choro- manski, Mario Lucic, Yi Tay, Adrian Weller, and Mostafa Dehghani. Polyvit: Co-training vision transformers on im- ages, videos and audio.arXiv preprint arXiv:2111.12993,
-
[40]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 1
work page 2014
-
[41]
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Remoteclip: A vision language foundation model for re- mote sensing.IEEE Transactions on Geoscience and Re- mote Sensing, 2024. 1, 3
work page 2024
-
[42]
Visual instruction tuning.Advances in neural infor- mation processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural infor- mation processing systems, 36:34892–34916, 2023. 5, 17
work page 2023
-
[43]
Lending orientation to neural networks for cross-view geo-localization
Liu Liu and Hongdong Li. Lending orientation to neural networks for cross-view geo-localization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5624–5633, 2019. 1, 3, 4, 5
work page 2019
-
[44]
Yang Long, Gui-Song Xia, Shengyang Li, Wen Yang, Michael Ying Yang, Xiao Xiang Zhu, Liangpei Zhang, and Deren Li. On creating benchmark dataset for aerial image interpretation: Reviews, guidances, and million-aid.IEEE Journal of selected topics in applied earth observations and remote sensing, 14:4205–4230, 2021. 3
work page 2021
-
[45]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Vision foundation models in remote sensing: A survey.IEEE Geoscience and Remote Sensing Magazine,
Siqi Lu, Junlin Guo, James R Zimmer-Dauphinee, Jor- dan M Nieusma, Xiao Wang, Steven A Wernke, Yuankai Huo, et al. Vision foundation models in remote sensing: A survey.IEEE Geoscience and Remote Sensing Magazine,
-
[47]
Junwei Luo, Zhen Pang, Yongjun Zhang, Tingzhu Wang, Linlin Wang, Bo Dang, Jiangwei Lao, Jian Wang, Jing- dong Chen, Yihua Tan, et al. Skysensegpt: A fine- grained instruction tuning dataset and model for remote sensing vision-language understanding.arXiv preprint arXiv:2406.10100, 2024. 3
-
[48]
Change-aware sampling and contrastive learning for satel- lite images
Utkarsh Mall, Bharath Hariharan, and Kavita Bala. Change-aware sampling and contrastive learning for satel- lite images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5261– 5270, 2023. 3 10
work page 2023
-
[49]
Utkarsh Mall, Cheng Perng Phoo, Meilin Kelsey Liu, Carl V ondrick, Bharath Hariharan, and Kavita Bala. Remote sensing vision-language foundation models without an- notations via ground remote alignment.arXiv preprint arXiv:2312.06960, 2023. 1, 3
-
[50]
Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data
Oscar Manas, Alexandre Lacoste, Xavier Gir ´o-i Nieto, David Vazquez, and Pau Rodriguez. Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 9414–9423, 2021. 3
work page 2021
-
[51]
Aaron Maxwell, Timothy Warner, Brian Vanderbilt, and Christopher Ramezan. Land cover classification and fea- ture extraction from national agriculture imagery program (naip) orthoimagery: A review.Photogrammetric Engi- neering & Remote Sensing, 83:737–747, 2017. 3
work page 2017
-
[52]
Audio-visual instance discrimination with cross-modal agreement
Pedro Morgado, Nuno Vasconcelos, and Ishan Misra. Audio-visual instance discrimination with cross-modal agreement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12475– 12486, 2021. 3
work page 2021
-
[53]
Geolocation estimation of photos using a hierarchical model and scene classification
Eric Muller-Budack, Kader Pustu-Iren, and Ralph Ew- erth. Geolocation estimation of photos using a hierarchical model and scene classification. InProceedings of the Eu- ropean conference on computer vision (ECCV), pages 563– 579, 2018. 1, 3
work page 2018
-
[54]
Learning audio-video modalities from image captions
Arsha Nagrani, Paul Hongsuck Seo, Bryan Seybold, Anja Hauth, Santiago Manen, Chen Sun, and Cordelia Schmid. Learning audio-video modalities from image captions. In European Conference on Computer Vision, pages 407–426. Springer, 2022. 3
work page 2022
-
[55]
Mmearth: Ex- ploring multi-modal pretext tasks for geospatial representa- tion learning
Vishal Nedungadi, Ankit Kariryaa, Stefan Oehmcke, Serge Belongie, Christian Igel, and Nico Lang. Mmearth: Ex- ploring multi-modal pretext tasks for geospatial representa- tion learning. InEuropean Conference on Computer Vision, pages 164–182. Springer, 2024. 1, 3
work page 2024
-
[56]
Large-scale image retrieval with atten- tive deep local features
Hyeonwoo Noh, Andre Araujo, Jack Sim, Tobias Weyand, and Bohyung Han. Large-scale image retrieval with atten- tive deep local features. InProceedings of the IEEE inter- national conference on computer vision, pages 3456–3465,
-
[57]
Rethinking transformers pre-training for multi- spectral satellite imagery
Mubashir Noman, Muzammal Naseer, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Shah- baz Khan. Rethinking transformers pre-training for multi- spectral satellite imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27811–27819, 2024. 1, 3
work page 2024
-
[58]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[59]
Openstreetmap.https:// www.openstreetmap.org, 2024
OpenStreetMap contributors. Openstreetmap.https:// www.openstreetmap.org, 2024. 3, 4
work page 2024
-
[60]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervi- sion.arXiv preprint arXiv:2304.07193, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Where in the world is this image? transformer-based geo-localization in the wild
Shraman Pramanick, Ewa M Nowara, Joshua Gleason, Car- los D Castillo, and Rama Chellappa. Where in the world is this image? transformer-based geo-localization in the wild. InEuropean Conference on Computer Vision, pages 196–
-
[62]
Springer, 2022. 1, 3
work page 2022
-
[63]
Revisiting oxford and paris: Large-scale image retrieval benchmarking
Filip Radenovi ´c, Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, and Ond ˇrej Chum. Revisiting oxford and paris: Large-scale image retrieval benchmarking. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5706–5715, 2018. 1, 3
work page 2018
-
[64]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 3, 6, 7, 8
work page 2021
-
[65]
Elias Ramzi, Nicolas Audebert, Cl ´ement Rambour, Andr ´e Araujo, Xavier Bitot, and Nicolas Thome. Optimization of rank losses for image retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 3, 16
work page 2025
-
[66]
Esther Rolf, Konstantin Klemmer, Caleb Robinson, and Hannah Kerner. Mission critical–satellite data is a dis- tinct modality in machine learning.arXiv preprint arXiv:2402.01444, 2024. 1
-
[67]
Birdsat: Cross-view con- trastive masked autoencoders for bird species classification and mapping
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Di Huang, and Nathan Jacobs. Birdsat: Cross-view con- trastive masked autoencoders for bird species classification and mapping. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 7136– 7145, 2024. 3
work page 2024
-
[68]
Taxabind: A unified embed- ding space for ecological applications
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Adeel Ahmad, and Nathan Jacobs. Taxabind: A unified embed- ding space for ecological applications. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1765–1774. IEEE, 2025. 3
work page 2025
-
[69]
Michael Schmitt, Lloyd Haydn Hughes, Chunping Qiu, and Xiao Xiang Zhu. Sen12ms–a curated dataset of georefer- enced multi-spectral sentinel-1/2 imagery for deep learning and data fusion.arXiv preprint arXiv:1906.07789, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[70]
Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps
Paul Hongsuck Seo, Tobias Weyand, Jack Sim, and Bo- hyung Han. Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps. InProceedings of the European Conference on Computer Vision (ECCV), pages 536–551, 2018. 3
work page 2018
-
[71]
Akashah Shabbir, Mohammed Zumri, Mohammed Ben- namoun, Fahad S Khan, and Salman Khan. Geopixel: Pixel grounding large multimodal model in remote sensing.arXiv preprint arXiv:2501.13925, 2025. 3
-
[72]
Yujiao Shi, Liu Liu, Xin Yu, and Hongdong Li. Spatial- aware feature aggregation for cross-view image based geo- localization.Advances in Neural Information Processing Systems, 32, 2019. 3
work page 2019
-
[73]
Where am i looking at? joint location and orientation es- timation by cross-view matching
Yujiao Shi, Xin Yu, Dylan Campbell, and Hongdong Li. Where am i looking at? joint location and orientation es- timation by cross-view matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4064–4072, 2020. 1, 3
work page 2020
-
[74]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, 11 Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Bioclip: A vision foundation model for the tree of life
Samuel Stevens, Jiaman Wu, Matthew J Thompson, Eliza- beth G Campolongo, Chan Hee Song, David Edward Car- lyn, Li Dong, Wasila M Dahdul, Charles Stewart, Tanya Berger-Wolf, et al. Bioclip: A vision foundation model for the tree of life. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19412– 19424, 2024. 3
work page 2024
-
[76]
Bigearthnet: A large-scale benchmark archive for remote sensing image understanding
Gencer Sumbul, Marcela Charfuelan, Beg ¨um Demir, and V olker Markl. Bigearthnet: A large-scale benchmark archive for remote sensing image understanding. In IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2019. 3
work page 2019
-
[77]
Gencer Sumbul, Arne De Wall, Tristan Kreuziger, Filipe Marcelino, Hugo Costa, Pedro Benevides, Mario Caetano, Beg¨um Demir, and V olker Markl. Bigearthnet-mm: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets].IEEE Geoscience and Remote Sensing Mag- azine, 9(3):174–180, 2021. 3
work page 2021
-
[78]
Xian Sun, Peijin Wang, Zhiyuan Yan, Feng Xu, Ruiping Wang, Wenhui Diao, Jin Chen, Jihao Li, Yingchao Feng, Tao Xu, et al. Fair1m: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing im- agery.ISPRS Journal of Photogrammetry and Remote Sens- ing, 184:116–130, 2022. 3
work page 2022
-
[79]
Shamma, Gerald Friedland, Ben- jamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li
Bart Thomee, David A. Shamma, Gerald Friedland, Ben- jamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. Yfcc100m: the new data in multimedia re- search.Communications of the ACM, 59(2):64–73, 2016. 1, 3, 5
work page 2016
-
[80]
Con- trastive multiview coding
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Con- trastive multiview coding. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI 16, pages 776–794. Springer, 2020. 3
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.