Cluster-Based Generalized Additive Models Informed by Random Fourier Features
Pith reviewed 2026-05-21 17:02 UTC · model grok-4.3
The pith
Cluster-based generalized additive models using random Fourier features improve regression on heterogeneous data
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing a response-informed spectral feature map from a fitted random Fourier feature regression, compressing it via principal component analysis, and applying a Gaussian mixture model for soft regime discovery, the method enables the fitting of cluster-specific generalized additive models with spline smooths. The predictor is then a weighted combination of these local models, which the authors show improves upon global interpretable methods and competes with black-box models on benchmark datasets.
What carries the argument
Response-informed spectral feature map from random Fourier features compressed by PCA and partitioned by Gaussian mixture model to enable localized generalized additive models
Load-bearing premise
The low-dimensional embedding from the spectral features contains separable structure that a Gaussian mixture model can use to define regimes where local additive models provide meaningful improvements.
What would settle it
Demonstrating that on the benchmark regression datasets, a single global generalized additive model achieves similar or better performance than the proposed clustered version.
Figures



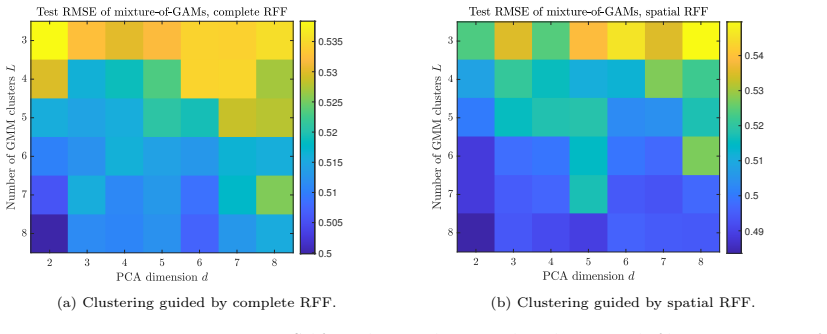









read the original abstract
In developing data-driven modeling methodologies, there is an ongoing need to reconcile the strong predictive performance of opaque black-box models with the transparency required for critical applications. This work introduces an interpretable and computationally tractable regression framework for heterogeneous data by combining response-informed spectral representation learning with localized additive modeling. The method first fits a random Fourier feature regression model and constructs a spectral feature map from the learned amplitudes and adaptively resampled frequencies, so that the representation reflects predictive variation in the data. This representation is then compressed by principal component analysis to obtain a low-dimensional latent embedding, in which a Gaussian mixture model performs soft regime discovery. Within each regime, a cluster-specific generalized additive model captures nonlinear covariate effects through interpretable spline-based univariate smooth functions. The final predictor is formed as a soft mixture of these local additive models, enabling flexible modeling of a nonlinear, heterogeneous structure while preserving interpretability. Numerical experiments across several benchmark regression datasets show that the proposed method consistently improves upon classical globally interpretable baselines while remaining competitive with more flexible black-box models. Overall, the framework provides a unified approach to heterogeneous regression that combines predictive adaptivity with interpretable local covariate effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a regression framework that integrates response-informed random Fourier features with principal component analysis and Gaussian mixture modeling to discover regimes, followed by fitting cluster-specific generalized additive models whose predictions are combined via soft weighting. The central claim is that this approach yields improved predictive performance over global interpretable baselines on benchmark regression datasets while remaining competitive with black-box models and preserving interpretability through local spline-based effects.
Significance. If the empirical results hold after addressing the noted gaps, the work provides a constructive pipeline for interpretable modeling of heterogeneous regression data, bridging global GAMs and flexible mixtures. The use of response-informed spectral features to guide the latent embedding is a positive design choice that merits further validation.
major comments (2)
- [Numerical Experiments] Numerical Experiments section: the reported benchmark improvements lack an ablation that isolates the contribution of the PCA-GMM regime discovery from the baseline capacity of a soft mixture of GAMs. Without this comparison, it remains unclear whether gains derive from meaningful structure in the response-informed embedding or simply from the added flexibility of multiple local models, directly impacting the central claim.
- [Method] Method section (around the GMM and PCA steps): the free parameters (number of mixture components, retained principal components, spline degrees and knots) are acknowledged but the manuscript provides no systematic selection rule or sensitivity analysis tied to the performance tables. This weakens the assertion of consistent improvements across datasets.
minor comments (2)
- [Abstract] Abstract and introduction: the phrase 'adaptively resampled frequencies' is introduced without a precise algorithmic description; a short pseudocode or equation reference would improve clarity.
- [Notation] Notation: ensure consistent use of symbols for the spectral feature map and the soft weights across equations and text to avoid minor reader confusion.
Axiom & Free-Parameter Ledger
free parameters (3)
- number of Gaussian mixture components
- number of principal components retained
- spline basis degrees and knot placements
axioms (1)
- domain assumption The data-generating process exhibits heterogeneous structure that is recoverable as soft clusters in the response-informed spectral feature space.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The method first fits a random Fourier feature regression model and constructs a spectral feature map from the learned amplitudes and adaptively resampled frequencies... This representation is then compressed by principal component analysis... a Gaussian mixture model performs soft regime discovery. Within each regime, a cluster-specific generalized additive model captures nonlinear covariate effects through interpretable spline-based univariate smooth functions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Numerical experiments across several benchmark regression datasets show that the proposed method consistently improves upon classical globally interpretable baselines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Avron, H., Kapralov, M., Musco, C., Musco, C., Velingker, A., Zandieh, A.,Random Fourier Features for Kernel Ridge Regression: Approximation Bounds and Statistical Guarantees, Pro- ceedings of the 34th International Conference on Machine Learning, PMLR, 70, 253–262, 2017
work page 2017
-
[2]
Bach, F.,On the Equivalence between Kernel Quadrature Rules and Random Feature Expan- sions, Journal of Machine Learning Research, 18, 1–38, 2017
work page 2017
-
[3]
Bach, F.,Learning Theory from First Principles, Adaptive Computation and Machine Learning series, The MIT Press, 2024
work page 2024
-
[4]
Bishop, C.M.,Pattern Recognition and Machine Learning (Information Science and Statistics). Springer-Verlag, 2006
work page 2006
-
[5]
Springer-Verlag New York, 1978
de Boor, C.,A Practical Guide to Splines. Springer-Verlag New York, 1978
work page 1978
-
[6]
Machine Learning, 45, 5–32, 2001
Breiman, L.,Random Forests. Machine Learning, 45, 5–32, 2001
work page 2001
-
[7]
NASA Reference Publication 1218, 1989
Brooks, T.F., Pope, D.S., and Marcolini, M.A.,Airfoil Self-Noise and Prediction. NASA Reference Publication 1218, 1989
work page 1989
-
[8]
Caruana, R., Lou, Y., Gehrke, J., Koch, P., Sturm, M., and Elhadad, N.,Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2015
work page 2015
-
[9]
and Guestrin, C.,XGBoost: A scalable tree boosting system
Chen, T. and Guestrin, C.,XGBoost: A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016
work page 2016
-
[10]
Proceedings of the 2012 IEEE 12th International Conference on Data Mining, 161–170, 2012
Chitta, R., Jin, R., and Jain, A.K.Efficient Kernel Clustering Using Random Fourier Features. Proceedings of the 2012 IEEE 12th International Conference on Data Mining, 161–170, 2012
work page 2012
-
[11]
Cambridge University Press, 2020
Deisenroth, M.P., Faisal, A.A., and Ong, C.S.,Mathematics for Machine Learning. Cambridge University Press, 2020
work page 2020
-
[12]
Proceedings of the International Congress of Mathematicians, 2, 914–954, 2022
E, W.,A Mathematical Perspective of Machine Learning. Proceedings of the International Congress of Mathematicians, 2, 914–954, 2022
work page 2022
-
[13]
Progress in Artificial Intelligence, 2, 113–127, 2014
Fanaee-T,H., Gama, J.Event Labeling Combining Ensemble Detectors and Background Knowl- edge. Progress in Artificial Intelligence, 2, 113–127, 2014
work page 2014
-
[14]
Pattern Recognition, 134:109057, 2023
Fang, K., Liu, F., Huang, X., and Yang, Y.,End-to-End Kernel Learning via Generative Random Fourier Features. Pattern Recognition, 134:109057, 2023. 28
work page 2023
-
[15]
The Annals of Statistics, 19, 1–67, 1991
Friedman, J.H.,Multivariate Adaptive Regression Splines. The Annals of Statistics, 19, 1–67, 1991
work page 1991
-
[16]
The Annals of Statistics, 29, 1189–1232, 2001
Friedman, J.H.Greedy Function Approximation: A Gradient Boosting Machine. The Annals of Statistics, 29, 1189–1232, 2001
work page 2001
-
[17]
Goodfellow, I., Bengio, Y., and Courville, A.Deep Learning. The MIT Press, 2016
work page 2016
-
[18]
and Tibshirani, R.,Generalized Additive Models
Hastie, T. and Tibshirani, R.,Generalized Additive Models. Chapman and Hall, New York, 1990
work page 1990
-
[19]
Hastie, T., Tibshirani, R., and Friedman, J.H.,The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer New York, NY, 2009
work page 2009
-
[20]
Hodges, J.,Richly Parametrized Linear Models: Additive, Time Series, and Spatial Models Using Random Effects, Boca Raton: Chapman & Hall/CRC Texts in Statistical Science, 2014
work page 2014
-
[21]
Convergence for adaptive resampling of random Fourier features
Huang, X., Kammonen, A., Pandey, A., Sandberg, M., von Schwerin, E., Szepessy, A., and Tempone, R.,Convergence for Adaptive Resampling of Random Fourier Features. Preprint, https://doi.org/10.48550/arXiv.2509.03151, 2025
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.03151 2025
-
[22]
and Johnson, K.,Applied Predictive Modeling
Kuhn, M. and Johnson, K.,Applied Predictive Modeling. Springer New York, NY, 2013
work page 2013
-
[23]
Murphy, K.P.,Probabilistic Machine Learning: An introduction. The MIT Press, 2022
work page 2022
-
[24]
Proceedings of Machine Learning Research, 95, 129–144, 2018
Nguyen, K., Dam, N., Le, T., Nguyen, T.D., and Phung, D.,Clustering Induced Kernel Learning. Proceedings of Machine Learning Research, 95, 129–144, 2018
work page 2018
-
[25]
Preprint, https://doi.org/10.48550/arXiv.1909.09223, 2019
Nori, H., Jenkins, S., Koch, P., and Caruana, R.,InterpretML: A Unified Framework for Machine Learning Interpretability. Preprint, https://doi.org/10.48550/arXiv.1909.09223, 2019
-
[26]
and Barry, R.,Sparse Spatial Autoregressions
Pace, R.K. and Barry, R.,Sparse Spatial Autoregressions. Statistics & Probability Letters, 33(3), 291–297, 1997
work page 1997
-
[27]
The Annals of Math- ematical Statistics, 33, 1065–1076, 1962
Parzen, E.,On Estimation of a Probability Density Function and Mode. The Annals of Math- ematical Statistics, 33, 1065–1076, 1962
work page 1962
-
[28]
Journal of Machine Learning Research, 12, 2825–2830, 2011
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E.,Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12, 2825–2830, 2011
work page 2011
-
[29]
and Recht, B.,Random Features for Large-Scale Kernel Machines
Rahimi, A. and Recht, B.,Random Features for Large-Scale Kernel Machines. Advances in Neural Information Processing Systems, 2007
work page 2007
-
[30]
and Williams, C.K.I.,Gaussian Processes for Machine Learning, The MIT Press, 2006
Rasmussen, C.E. and Williams, C.K.I.,Gaussian Processes for Machine Learning, The MIT Press, 2006
work page 2006
-
[31]
Rastgoo, A. and Khajavi, H.,A Novel Study on Forecasting the Airfoil Self-Noise, Using a Hybrid Model Based on the Combination of CatBoost and Arithmetic Optimization Algorithm. Expert Systems with Applications, 229, 120576, 2023. 29
work page 2023
-
[32]
Proceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 25), 2025
Reddy, T.S., Saketh, V.N.S., and Chandran, M.,Interpretable Graph Neural Networks with Random Fourier Features. Proceedings of the 39th Conference on Neural Information Processing Systems (NeurIPS 25), 2025
work page 2025
-
[33]
Rosenblatt, M.,Remarks on Some Nonparametric Estimates of a Density Function.TheAnnals of Mathematical Statistics, 27, 832–837, 1956
work page 1956
-
[34]
Rudi, A. and Rosasco, L.,Generalization Properties of Learning with Random Features, Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS 17), 3218–3228, 2017
work page 2017
-
[35]
Rumelhart, D.E., Hinton, G.E., and Williams, R.J.,Learning representations by back- propagating errors, Nature, 323, 533–536, 1986
work page 1986
-
[36]
Schölkopf, B. and Smola, A.J.,Learning with Kernels: Support Vector Machines, Regulariza- tion, Optimization, and Beyond. The MIT Press, 2001
work page 2001
-
[37]
Seo, B. and Li, J.,Explainable Machine Learning by SEE-Net: Closing the Gap between Interpretable Models and DNNs. Scientific Reports, 14, 26302, 2024
work page 2024
-
[38]
Journal of Computational and Graphical Statistics, 31(4), 1303–1317, 2022
Seo, B., Lin, L., and Li, J.,Mixture of Linear Models Co-supervised by Deep Neural Networks. Journal of Computational and Graphical Statistics, 31(4), 1303–1317, 2022
work page 2022
-
[39]
and Brummitt, C.,pyGAM: Generalized Additive Models in Python(software), Version 0.4.1, Zenodo, 2018
Servén, D. and Brummitt, C.,pyGAM: Generalized Additive Models in Python(software), Version 0.4.1, Zenodo, 2018. doi:10.5281/zenodo.1208724
-
[40]
Journal of the Royal Statis- tical Society, Series B, 58, 267–288, 1996
Tibshirani, R.,Regression Shrinkage and Selection via the Lasso. Journal of the Royal Statis- tical Society, Series B, 58, 267–288, 1996
work page 1996
-
[41]
Cambridge University Press, 2004
Wendland, H.,Scattered Data Approximation. Cambridge University Press, 2004
work page 2004
-
[42]
Chapman & Hall/CRC Press, 2017
Wood, S.N.,Generalized Additive Models: An Introduction with R (2nd ed.). Chapman & Hall/CRC Press, 2017. Appendix A. Implementation and Hyperparameter Details Appendix A.1. Hyperparameters for the Mixture-of-GAMs Framework This subsection summarizes the hyperparameter choices used for training the proposed Mixture- of-GAMs framework, including the resamp...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.