Bloom Filter Encoding for Machine Learning
Pith reviewed 2026-05-16 20:40 UTC · model grok-4.3
The pith
Bloom filter encodings let machine learning models reach accuracy close to raw data while using less memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Bloom filter encoding maps each sample to a compact bit-array feature space via hash functions, yielding a fixed-length representation that supports classification accuracy comparable to raw data or conventional reductions while delivering consistent memory savings and optional obfuscation of original values.
What carries the argument
Bloom filter transform that hashes sample features into a fixed-length bit array.
Load-bearing premise
The hash-based encoding must retain enough similarity structure and discriminative information from the original features for standard classifiers to reach comparable accuracy without domain-specific adjustments.
What would settle it
A new dataset or classifier where Bloom-encoded inputs produce clearly lower accuracy than raw data while standard reductions maintain performance would show the encoding fails to preserve necessary structure in general.
Figures






read the original abstract
We present a method that uses a Bloom filter transform to preprocess data for machine learning. Each sample is encoded into a compact bit-array representation using hash-based encoding, producing a fixed-length feature space that reduces memory usage and obfuscates original feature values. The encoding does not rely on keyed hashing; however, a key can optionally be used to control the mapping and would be required to reproduce the representation. We evaluate the approach on six datasets spanning text, time-series, tabular, and image domains: SMS Spam Collection, ECG200, Adult 50K, CDC Diabetes, MNIST, and Fashion MNIST. Four classifiers are considered: Extreme Gradient Boosting, Deep Neural Networks, Convolutional Neural Networks, and Logistic Regression. Results show that models trained on Bloom filter encodings achieve performance comparable to models trained on raw data or standard dimensionality reduction techniques across several datasets, while providing consistent memory savings. These findings suggest that Bloom filter encodings can serve as an efficient, general-purpose pre-processing representation that preserves useful similarity structure for learning tasks while providing a degree of data obfuscation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Bloom filter transform to encode ML samples into compact fixed-length bit arrays via hash-based encoding. This preprocessing step is intended to reduce memory usage and provide feature obfuscation while preserving enough similarity structure for standard classifiers to achieve performance comparable to raw data or conventional dimensionality reduction. The method is tested empirically on six datasets (SMS Spam, ECG200, Adult, CDC Diabetes, MNIST, Fashion MNIST) with four classifiers (XGBoost, DNN, CNN, logistic regression).
Significance. If the central empirical claim holds after proper controls, the technique could supply a lightweight, general-purpose preprocessing representation that delivers consistent memory savings together with a modest privacy benefit through one-way hashing. Its simplicity and domain-agnostic nature would make it attractive for resource-limited or privacy-sensitive deployments, provided the encoding demonstrably retains discriminative information without dataset-specific tuning.
major comments (3)
- [Method] Method section: the encoding procedure for non-set data (continuous tabular features in Adult/Diabetes, pixel intensities in MNIST) is not specified, including tokenization into hashable elements and whether standard or locality-sensitive hash families are employed. This detail is load-bearing because Bloom filters supply no distance-preservation guarantee; without it, comparable accuracy cannot be attributed to the transform rather than favorable collision rates.
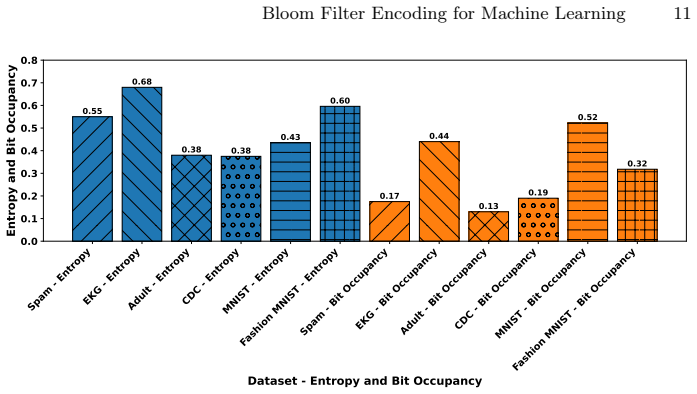
- [Experiments] Experiments/Results: no values are reported for Bloom-filter length m or hash count k on any dataset, nor any analysis of resulting false-positive rates or collision statistics. The headline claim of 'comparable performance' therefore cannot be evaluated or reproduced, as these parameters directly control information loss.
- [Results] Results section: the abstract asserts 'comparable performance' and 'consistent memory savings' yet supplies neither numerical accuracies, standard deviations, nor statistical tests against raw-data and dimensionality-reduction baselines. Without these metrics the central empirical claim remains unverified.
minor comments (2)
- [Abstract] Abstract: the phrase 'a key can optionally be used' should clarify whether the key is required for experimental reproducibility and how it affects the reported results.
- [Results] The manuscript should include a table or figure quantifying memory reduction (bits per sample) relative to the original feature dimensionality for each dataset.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us strengthen the clarity and reproducibility of the manuscript. We address each major point below and have made corresponding revisions.
read point-by-point responses
-
Referee: [Method] Method section: the encoding procedure for non-set data (continuous tabular features in Adult/Diabetes, pixel intensities in MNIST) is not specified, including tokenization into hashable elements and whether standard or locality-sensitive hash families are employed. This detail is load-bearing because Bloom filters supply no distance-preservation guarantee; without it, comparable accuracy cannot be attributed to the transform rather than favorable collision rates.
Authors: We agree that the original manuscript did not provide sufficient detail on the encoding of non-set data. In the revised version we have added an explicit subsection describing the procedure: continuous tabular features are discretized into equal-width bins and each bin is treated as a distinct token; pixel intensities in MNIST/Fashion-MNIST are hashed individually after optional 2x2 patch aggregation. We use standard non-cryptographic hash families (MurmurHash3) rather than locality-sensitive hashes. We acknowledge that Bloom filters provide no formal distance preservation and have added a short discussion clarifying that the observed performance is an empirical result, now supported by the newly reported collision statistics. revision: yes
-
Referee: [Experiments] Experiments/Results: no values are reported for Bloom-filter length m or hash count k on any dataset, nor any analysis of resulting false-positive rates or collision statistics. The headline claim of 'comparable performance' therefore cannot be evaluated or reproduced, as these parameters directly control information loss.
Authors: We accept this criticism. The revised manuscript now contains a dedicated table listing the exact m and k values chosen for each of the six datasets, the resulting theoretical false-positive rate, and empirical collision counts measured on the encoded training sets. These parameters were selected to keep the false-positive rate below 0.05 while respecting the memory budget; the new table makes the experimental configuration fully reproducible. revision: yes
-
Referee: [Results] Results section: the abstract asserts 'comparable performance' and 'consistent memory savings' yet supplies neither numerical accuracies, standard deviations, nor statistical tests against raw-data and dimensionality-reduction baselines. Without these metrics the central empirical claim remains unverified.
Authors: We agree that the original results section was insufficiently quantitative. We have expanded it with two new tables: one reporting mean accuracy and standard deviation (over 10 random seeds) for Bloom-filter, raw, and PCA-encoded versions of each dataset; the second showing memory footprint in bytes per sample. We also added paired t-test p-values comparing Bloom-filter performance against the raw-data baseline. These additions directly support the claims made in the abstract. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or fitted predictions
full rationale
The paper describes a Bloom filter encoding method and reports direct experimental results on six public datasets using four standard classifiers. No equations, derivations, uniqueness theorems, or parameter-fitting steps are present that could reduce a claimed prediction back to the input by construction. Performance comparability is measured via standard accuracy metrics on held-out test sets, making the evaluation self-contained and falsifiable against external benchmarks without reliance on self-citations or ansatzes.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bloom filter length and hash function count
axioms (1)
- domain assumption Hash-based encoding into a fixed bit array preserves task-relevant similarity structure across text, time-series, tabular, and image data.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Results show that models trained on Bloom filter encodings achieve performance comparable to models trained on raw data...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Privacy-Preserving Distributed Learning in IoT Systems: A Unified Threat Model and Evaluation Framework
A unified threat model and evaluation framework is developed to compare privacy-preserving methods for distributed learning in IoT, showing trade-offs in privacy robustness and system efficiency with Bloom filter enco...
Reference graph
Works this paper leans on
-
[1]
RobustBF: A High Accuracy and Memory Efficient 2D Bloom Filter,
S. Nayak and R. Patgiri, “RobustBF: A High Accuracy and Memory Efficient 2D Bloom Filter,”arXiv preprint, 2021, arXiv:2106.04365
-
[2]
A Privacy Model for Classical & Learned Bloom Filters,
H. Tirmazi, “A Privacy Model for Classical & Learned Bloom Filters,”arXiv preprint, 2025, arXiv:2501.15751
-
[3]
Space/time trade-offs in hash coding with allowable errors,
B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,”Commu- nications of the ACM, vol. 13, no. 7, pp. 422–426, 1970, doi: 10.1145/362686.362692
-
[4]
M. Mitzenmacher, “Compressed Bloom Filters,”IEEE/ACM Transactions on Net- working, vol. 10, no. 5, pp. 604–612, 2002, doi: 10.1109/TNET.2002.803823
-
[5]
Network Applications of Bloom Filters: A Sur- vey,
A. Broder and M. Mitzenmacher, “Network Applications of Bloom Filters: A Sur- vey,”Internet Mathematics, vol. 1, no. 4, pp. 485–509, 2005, doi: 10.1080/15427951. 2004.10129096
-
[6]
DGA Detection Using Similarity-Preserving Bloom Encod- ings,
L. Nitz and A. Mandal, “DGA Detection Using Similarity-Preserving Bloom Encod- ings,” inProc. European Interdisciplinary Cybersecurity Conference (EICC), Sta- vanger, Norway, June 14-15 2023, pp. 116-120, doi:10.1145/3590777.3590795
-
[7]
A blinded evaluation of privacy pre- serving record linkage with Bloom filters,
S. Randall, H. Wichmann, A. Brownet al., “A blinded evaluation of privacy pre- serving record linkage with Bloom filters,”BMC Medical Research Methodology, vol. 22, no. 1, Art. 22, Jan. 2022, doi: 10.1186/s12874-022-01510-2. 14 J. Cartmell et al
-
[8]
UCI Machine Learning Repository, “SMS Spam Collection Dataset,” Kaggle, 2011
work page 2011
-
[9]
R. Olszewski,Generalized Feature Extraction for Structural Pattern Recognition in Time-Series Data, Ph.D. dissertation, Carnegie Mellon University, 2001
work page 2001
-
[10]
UCI Machine Learning Repository: Adult Data Set,
D. Dua and C. Graff, “UCI Machine Learning Repository: Adult Data Set,” 1996
work page 1996
-
[11]
Diabetes Health Indicators Dataset,
Centers for Disease Control and Prevention (CDC), “Diabetes Health Indicators Dataset,” 2020
work page 2020
-
[12]
MNIST Handwritten Digit Database,
Y. LeCun and C. Cortes, “MNIST Handwritten Digit Database,” 1998
work page 1998
-
[13]
Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms,
X. Xiao, K. Rasul, and R. Vollgraf, “Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms,” 2017
work page 2017
-
[14]
T. Chen and C. Guestrin, “XGBoost: A Scalable Tree Boosting System,” inPro- ceedings of the 22nd ACM SIGKDD International Conference on Knowledge Dis- covery and Data Mining (KDD), San Francisco, CA, USA, 2016, pp. 785-794, doi: 10.1145/2939672.2939785
-
[15]
W., et al., 2019, Science, DOI: 10.1126/sci- ence.aaw5903 Barsdell et al., 2010, MNRAS, 408,
G. E. Hinton and R. R. Salakhutdinov, “Reducing the Dimensionality of Data with Neural Networks,”Science, vol. 313, no. 5786, pp. 504–507, 2006, doi: 10.1126/sci- ence.1127647
-
[16]
ImageNet Classification with Deep Convolutional Neural Networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” inAdvances in Neural Information Processing Sys- tems (NeurIPS), vol. 25, 2012
work page 2012
-
[17]
The Regression Analysis of Binary Sequences,
D. R. Cox, “The Regression Analysis of Binary Sequences,”Journal of the Royal Statistical Society: Series B (Methodological), vol. 20, no. 2, pp. 215–242, 1958
work page 1958
-
[18]
Invertible Bloom Lookup Tables with Less Memory and Randomness,
N. Fleischhacker, K. G. Larsen, M. Obremski, and M. Simkin, “Invertible Bloom Lookup Tables with Less Memory and Randomness,” inProc. 32nd Annu. Eur. Symp. Algorithms (ESA 2024), Leibniz Int. Proc. Informatics (LIPIcs), vol. 308, pp. 54:1–54:17, 2024, doi: 10.4230/LIPIcs.ESA.2024.54
-
[19]
Sampling and Reconstruction Using Bloom Filters
N. Sengupta, A. Bagchi, S. Bedathur, and M. Ramanath, “Sampling and Recon- struction Using Bloom Filters,”arXiv preprint arXiv:1701.03308, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
HMAC: Keyed-hashing for mes- sage authentication,
H. Krawczyk, M. Bellare, and R. Canetti, “HMAC: Keyed-hashing for mes- sage authentication,”RFC 2104, Internet Eng. Task Force (IETF), 1997, doi: 10.17487/RFC2104
-
[21]
Improved visualization of high-dimensional data using the distance-of-distances transformation,
J. Liu and M. Vinck, “Improved visualization of high-dimensional data using the distance-of-distances transformation,”Journal of Big Data, vol. 9, no. 1, Art. 72, 2022, doi: 10.1186/s40537-022-00525-5
-
[22]
The use of multiple measurements in taxonomic problems,
R. A. Fisher, “The use of multiple measurements in taxonomic problems,”Annals of Eugenics, vol. 7, no. 2, pp. 179–188, 1936
work page 1936
-
[23]
I. T. Jolliffe,Principal Component Analysis, 2nd ed., Springer Series in Statistics. New York, NY, USA: Springer, 2002
work page 2002
-
[24]
F. Anowar, S. Sadaoui, and B. Selim, “Conceptual and empirical comparison of dimensionality reduction algorithms (PCA, KPCA, LDA, MDS, SVD, LLE, ISOMAP, LE, ICA, t-SNE),”Computer Science Review, vol. 40, p. 100378, 2021, doi: 10.1016/j.cosrev.2021.100378
-
[25]
Privacy- preserving record linkage using Bloom filters: A systematic literature review,
H. S. P. Vidanage, T. Ranbaduge, P. Christen, and D. Vatsalan, “Privacy- preserving record linkage using Bloom filters: A systematic literature review,” J. Inf. Secur. Appl., vol. 54, p. 102493, 2020, doi: 10.1016/j.jisa.2020.102493
-
[26]
M. Sönmez Turan and L. T. A. N. Brandão, “Keyed-Hash Message Authentication Code (HMAC): Specification and Recommendations (Initial Public Draft),” NIST Special Publication 800-224 (IPD), Jun. 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.