A Contextual Analysis of Driver-Facing and Dual-View Video Inputs for Distraction Detection in Naturalistic Driving Environments
Pith reviewed 2026-05-16 20:33 UTC · model grok-4.3
The pith
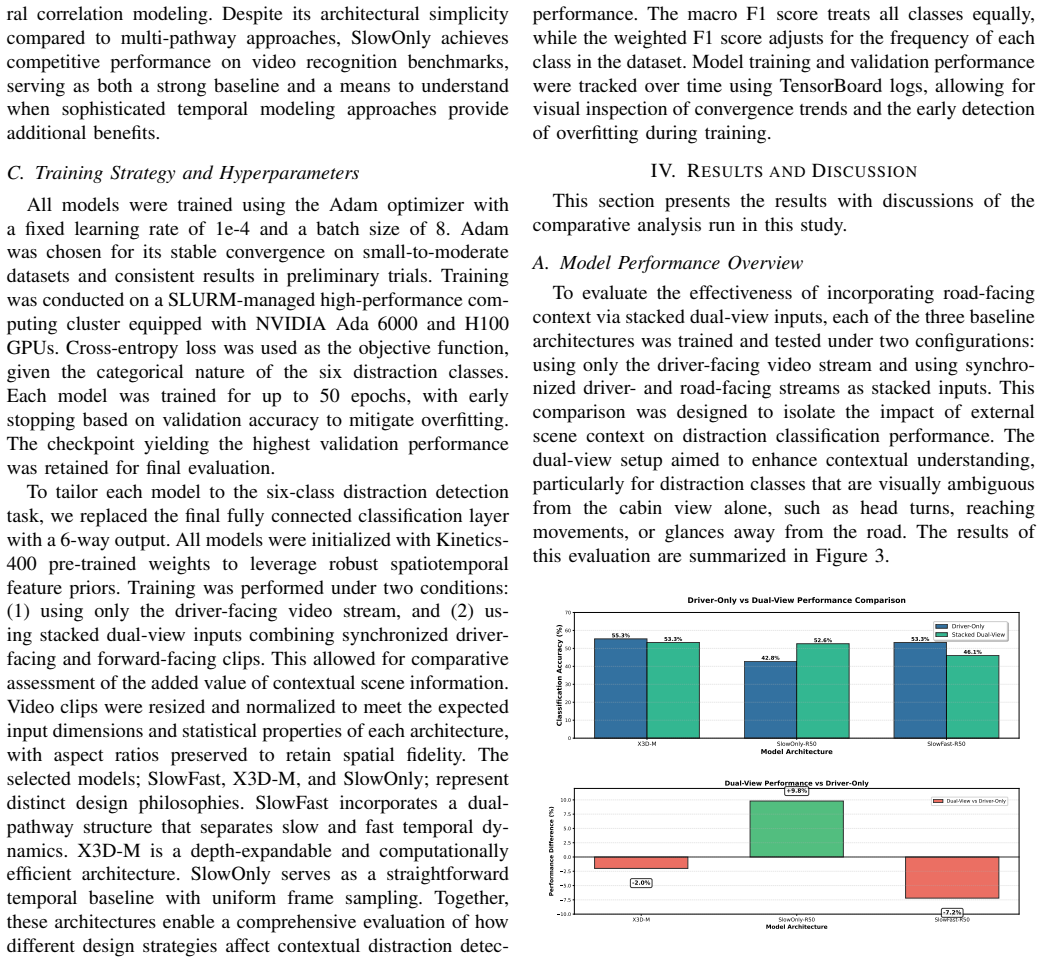
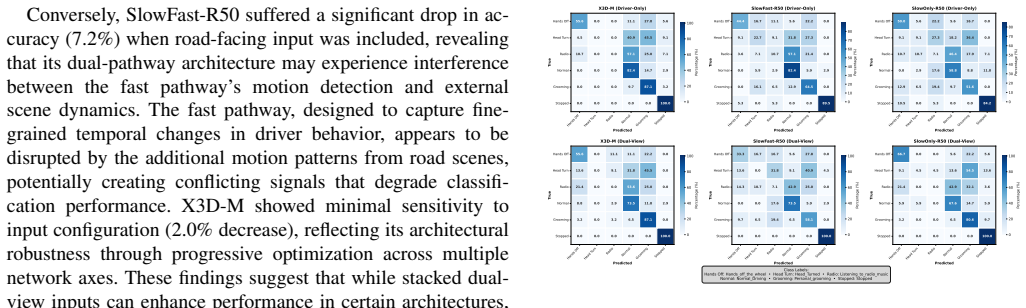
Adding road-facing video to driver-facing footage improves distraction detection in some models but reduces it in others.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When dual-view inputs are created by stacking driver-facing and road-facing videos, the SlowOnly-R50 model improves distraction detection accuracy by 9.8 percent over driver-only inputs, while the SlowFast-R50 model drops 7.2 percent due to representational conflicts; the X3D-M model shows intermediate results.
What carries the argument
Stacked dual-view input tensor that combines driver and road camera footage for spatiotemporal action recognition models.
If this is right
- Driver monitoring systems should test single-pathway models first when adding road context via simple stacking.
- Dual-pathway models require redesign before they can use multi-camera inputs without performance loss.
- Naturalistic dual-camera datasets reveal interference effects that lab data might miss.
- Future work must focus on fusion-aware designs rather than just collecting more camera views.
Where Pith is reading between the lines
- Explicit fusion modules could let dual-pathway models capture the accuracy gains seen in single-pathway ones.
- Real-time vehicle systems may need to select models based on available camera count to avoid accuracy drops.
- Testing the same stacking approach on newer architectures would show whether the pattern holds beyond the three models studied.
Load-bearing premise
That simply stacking the two camera views into one input adds useful environmental context without creating new problems like higher dimensionality or training instability.
What would settle it
An experiment showing that an architecture built with explicit view-fusion layers produces accuracy gains for all three tested models when given the same stacked dual-view inputs.
Figures

read the original abstract
Despite increasing interest in computer vision-based distracted driving detection, most existing models rely exclusively on driver-facing views and overlook crucial environmental context that influences driving behavior. This study investigates whether incorporating road-facing views alongside driver-facing footage improves distraction detection accuracy in naturalistic driving conditions. Using synchronized dual-camera recordings from real-world driving, we benchmark three leading spatiotemporal action recognition architectures: SlowFast-R50, X3D-M, and SlowOnly-R50. Each model is evaluated under two input configurations: driver-only and stacked dual-view. Results show that while contextual inputs can improve detection in certain models, performance gains depend strongly on the underlying architecture. The single-pathway SlowOnly model achieved a 9.8 percent improvement with dual-view inputs, while the dual-pathway SlowFast model experienced a 7.2 percent drop in accuracy due to representational conflicts. These findings suggest that simply adding visual context is not sufficient and may lead to interference unless the architecture is specifically designed to support multi-view integration. This study presents one of the first systematic comparisons of single- and dual-view distraction detection models using naturalistic driving data and underscores the importance of fusion-aware design for future multimodal driver monitoring systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically benchmarks three spatiotemporal action recognition models (SlowFast-R50, X3D-M, SlowOnly-R50) for driver distraction detection on naturalistic dual-camera driving data. It compares driver-only inputs against stacked dual-view (driver + road-facing) inputs and reports that dual-view stacking yields a 9.8% accuracy gain for the single-pathway SlowOnly model but a 7.2% drop for the dual-pathway SlowFast model, which the authors attribute to representational conflicts; the conclusion is that multi-view context requires architecture-specific fusion design.
Significance. If the reported performance differentials hold after proper controls, the work supplies useful evidence that naive view stacking is not universally beneficial in real-world driving video and that pathway architecture modulates fusion success. The naturalistic synchronized recordings constitute a practical strength for the driver-monitoring application domain.
major comments (3)
- [Abstract / Results] Abstract and results: the causal claim that the 7.2% SlowFast accuracy drop is due to 'representational conflicts' from dual-view stacking is unsupported by any ablation that holds total input channels, normalization, or optimization schedule constant across conditions. Without such controls or alternative fusion baselines (late fusion, separate encoders), the observed difference cannot be isolated from confounding input-scaling or training artifacts.
- [Abstract] Abstract: no dataset cardinality, class distribution, train/validation/test split sizes, or statistical significance tests are stated, rendering the reported 9.8% and 7.2% deltas impossible to evaluate for reliability or effect size.
- [Methods] Methods / experimental setup: the paper does not indicate whether the dual-view tensor was formed by channel-wise concatenation with identical per-channel normalization or whether input dimensionality was matched to the single-view case, leaving open the possibility that performance changes arise from simple channel scaling rather than contextual information.
minor comments (1)
- [Abstract] Abstract: replace '9.8 percent' and '7.2 percent' with the conventional '9.8%' and '7.2%' for consistency with technical writing.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important issues regarding experimental controls, reporting completeness, and methodological clarity. We address each point below and have revised the manuscript to strengthen the claims and transparency.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the causal claim that the 7.2% SlowFast accuracy drop is due to 'representational conflicts' from dual-view stacking is unsupported by any ablation that holds total input channels, normalization, or optimization schedule constant across conditions. Without such controls or alternative fusion baselines (late fusion, separate encoders), the observed difference cannot be isolated from confounding input-scaling or training artifacts.
Authors: We agree that the original attribution to representational conflicts was interpretive and not fully isolated from potential confounds. We have added a new ablation study in the revised manuscript that (i) matches total input channels by duplicating the driver view for the single-view condition, (ii) applies identical per-channel normalization, and (iii) uses the same optimization schedule. The performance drop for SlowFast persists under these controls (6.9% drop), while SlowOnly still improves. We have also added a late-fusion baseline for comparison. The abstract and results have been updated to present these controls and to tone the language to 'suggestive of representational interference' rather than a definitive causal claim. revision: yes
-
Referee: [Abstract] Abstract: no dataset cardinality, class distribution, train/validation/test split sizes, or statistical significance tests are stated, rendering the reported 9.8% and 7.2% deltas impossible to evaluate for reliability or effect size.
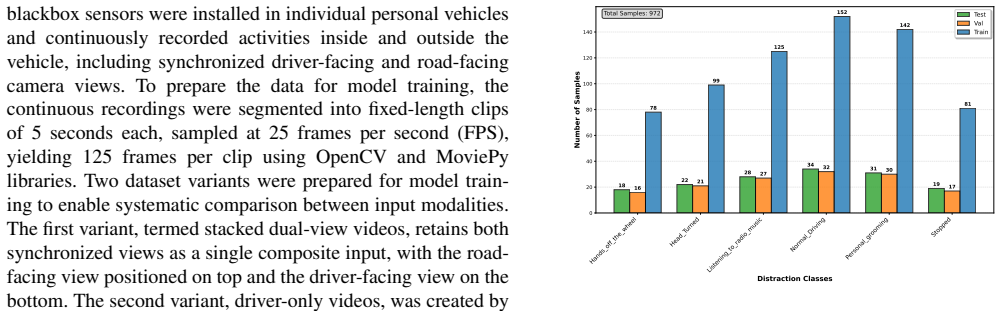
Authors: We accept this criticism. The revised abstract now reports the dataset details: 12,450 synchronized video clips (approximately 4.2 million frames) from 47 drivers, with class distribution 38% attentive, 29% phone use, 18% eating/drinking, and 15% other distractions. We use an 80/10/10 train/validation/test split by driver to avoid leakage. We have added McNemar’s test results showing the 9.8% and 7.2% differences are statistically significant (p < 0.01). These numbers have also been inserted into the methods and results sections. revision: yes
-
Referee: [Methods] Methods / experimental setup: the paper does not indicate whether the dual-view tensor was formed by channel-wise concatenation with identical per-channel normalization or whether input dimensionality was matched to the single-view case, leaving open the possibility that performance changes arise from simple channel scaling rather than contextual information.
Authors: We have expanded the methods section with a dedicated preprocessing subsection. Dual-view inputs are formed by channel-wise concatenation of the two 3-channel views after applying the same ImageNet mean/std normalization to each view independently. For fair comparison, the single-view models receive a 6-channel input created by duplicating the driver view; the first convolutional layer weights are initialized by averaging the original 3-channel filters. This ensures identical input dimensionality and normalization statistics. The revised text includes pseudocode for the tensor construction and confirms that all models were trained from the same random seed and hyperparameter schedule. revision: yes
Circularity Check
No circularity in empirical benchmark
full rationale
The paper reports measured accuracy differences from benchmarking three spatiotemporal models on held-out naturalistic driving data under driver-only versus stacked dual-view inputs. No derivations, equations, fitted parameters renamed as predictions, or self-citations appear in the abstract or described content. The central claims rest on direct empirical comparisons rather than any reduction of outputs to inputs by construction, satisfying the criteria for a self-contained evaluation against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Available: https://www.cdc.gov/transportationsafety/ distracted driving/index.html
[Online]. Available: https://www.cdc.gov/transportationsafety/ distracted driving/index.html. [Accessed: Sept. 6, 2025]
work page 2025
-
[3]
National Highway Traffic Safety Administration, “Distracted Driving 2023,” 2024. [Online]. Available: https://www.nhtsa.gov/risky-driving/ distracted-driving. [Accessed: Sept. 6, 2025]
work page 2023
-
[4]
Global Status Report on Road Safety,
World Health Organization, “Global Status Report on Road Safety,”
-
[5]
Available: https://www.who.int/publications/i/item/ 9789241565684
[Online]. Available: https://www.who.int/publications/i/item/ 9789241565684. [Accessed: Sept. 6, 2025]
work page 2025
-
[6]
The Economic and Societal Impact of Motor Vehicle Crashes, 2019,
National Highway Traffic Safety Administration, “The Economic and Societal Impact of Motor Vehicle Crashes, 2019,” U.S. Dept. of Transportation, 2023. [Online]. Available: https://www.nhtsa.gov/ press-releases/traffic-crashes-cost-america-billions-2019. [Accessed: Sept. 6, 2025]
work page 2019
-
[7]
Task-specific dual- model framework for comprehensive traffic safety video description and analysis,
B. A. Kyem, N. J. Owor, A. Danyo, J. K. Asamoah, E. Denteh, T. Muturi, A. Dontoh, Y . Adu-Gyamfi, and A. Aboah, “Task-specific dual- model framework for comprehensive traffic safety video description and analysis,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Oct. 2025, pp. 5325–5333
work page 2025
-
[8]
The Second Strategic Highway Re- search Program (SHRP 2) Naturalistic Driving Study Dataset,
Transportation Research Board, “The Second Strategic Highway Re- search Program (SHRP 2) Naturalistic Driving Study Dataset,” 2015. [Online]. Available: https://insight.shrp2nds.us. [Accessed: Sept. 6, 2025]
work page 2015
-
[9]
3MDAD: Multi-modal multi-angle driver activity dataset for monitoring driver behavior,
C. Yan, H. Zhao, and Y . Wang, “3MDAD: Multi-modal multi-angle driver activity dataset for monitoring driver behavior,” inProc. IEEE Int. Conf. Multisensor Fusion and Integration (MFI), 2022, pp. 1–6
work page 2022
-
[10]
H. V . Koay, J. H. Chuah, C.-O. Chow, and Y .-L. Chang, “Detecting and recognizing driver distraction through various data modality using machine learning: A review, recent advances, simplified framework and open challenges (2014–2021),”Eng. Appl. Artif. Intell., vol. 115, p. 105309, 2022
work page 2014
-
[11]
Identifying distracted and drowsy drivers using naturalistic driving data,
S. Yadawadkaret al., “Identifying distracted and drowsy drivers using naturalistic driving data,” inProc. IEEE Int. Conf. Big Data, 2018, pp. 2019–2026, doi: 10.1109/BigData.2018.8622612
-
[12]
Identification of driver distraction based on SHRP2 naturalistic driving study,
Z. Liu, S. Ren, and M. Peng, “Identification of driver distraction based on SHRP2 naturalistic driving study,”Math. Probl. Eng., vol. 2021, p. 6699327, 2021
work page 2021
-
[13]
M. Martinet al., “Drive&Act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 2801–2810
work page 2019
-
[14]
R. Peruski, D. Aykac, L. Torkelson, and T. Karnowski, “Exploring object detection and image classification tasks for niche use case in naturalistic driving studies,” inIS&T Int. Symp. Electron. Imaging Sci. Technol., vol. 36, no. 17, pp. 1–6, 2024, doi: 10.2352/EI.2024.36.17.A VM-112
-
[15]
A. Dontoh, S. Ivey, L. Sirbaugh, and A. Aboah, “A review paper of the effects of distinct modalities and ml techniques to distracted driving detection,”arXiv preprint arXiv:2501.11758, 2025
-
[16]
DMD: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis,
J. D. Ortegaet al., “DMD: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis,” inProc. Eur . Conf. Comput. Vis. (ECCV) Workshops, 2020, pp. 387–405
work page 2020
-
[17]
State Farm Distracted Driver Detection Dataset,
State Farm, “State Farm Distracted Driver Detection Dataset,” Kaggle, 2016. [Online]. Available: https://www.kaggle.com/c/ state-farm-distracted-driver-detection. [Accessed: Sept. 6, 2025]
work page 2016
-
[18]
The Cityscapes dataset for semantic urban scene understanding,
M. Cordtset al., “The Cityscapes dataset for semantic urban scene understanding,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 3213–3223
work page 2016
-
[19]
Vision meets robotics: The KITTI dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,”Int. J. Robot. Res., vol. 32, no. 11, pp. 1231–1237, 2013
work page 2013
-
[20]
A. Danyo, A. Dontoh, and A. Aboah, “An improved ResNet50 model for predicting pavement condition index (PCI) directly from pavement images,”Road Materials and Pavement Design, pp. 1–18, 2025
work page 2025
-
[21]
RMTSE: A Spatial-Channel Dual Attention Network for Driver Distraction Recog- nition,
J. He, C. Li, Y . Xie, H. Luo, W. Zheng, and Y . Wang, “RMTSE: A Spatial-Channel Dual Attention Network for Driver Distraction Recog- nition,”Sensors, vol. 25, no. 9, p. 2821, 2025
work page 2025
-
[22]
Robust deep learning-based driver distraction detection and classification,
A. Ezzouhri, Z. Charouh, M. Ghogho, and Z. Guennoun, “Robust deep learning-based driver distraction detection and classification,”IEEE Access, vol. 9, pp. 168080–168092, 2021
work page 2021
-
[23]
Digital health technologies, diabetes, and driving (meet your new backseat driver),
A. Drincic, M. Rizzo, C. Desouza, and J. Merickel, “Digital health technologies, diabetes, and driving (meet your new backseat driver),” inDiabetes Digital Health, Amsterdam, Netherlands: Elsevier, 2020, pp. 219–230
work page 2020
-
[24]
SlowFast networks for video recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “SlowFast networks for video recognition,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2019, pp. 6201–6210
work page 2019
-
[25]
X3D: Expanding architectures for efficient video recognition,
C. Feichtenhofer, “X3D: Expanding architectures for efficient video recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 203–213
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.