Leveraging BART to Assess CS1 C++ Programming Assignments using Rubric-based Criteria
Pith reviewed 2026-06-28 09:38 UTC · model grok-4.3
The pith
Multitask BART fine-tuned with rubric context and boundary-based soft labels produces lower mean absolute error and better grade-distribution alignment than single-task or code-only baselines on CS1 C++ assignments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multitask BART with boundary-based soft labels and rubric context achieves lower mean absolute error and stronger grade-distribution alignment than single-task, hard-label, or code-only baselines.
What carries the argument
BART encoder-decoder with LoRA adaptation, trained jointly to predict numeric grades and grade buckets using boundary-based soft labels plus a distribution-matching loss, conditioned on unified sequences that include assignment rubrics.
If this is right
- Multitask training on both numeric scores and grade buckets improves both error metrics and distributional match relative to single-task models.
- Boundary-based soft labels produce stronger alignment with instructor behavior than hard one-hot labels.
- Conditioning on rubric text reduces numeric error compared with code-only inputs.
- Fully fine-tuned T5 models can further improve distributional fidelity beyond the BART results.
- Pairwise pretraining lowers numeric error but reduces sensitivity on minority grade classes.
Where Pith is reading between the lines
- The same rubric-plus-distribution-matching approach could be tested on non-programming subjects where grading involves both quantitative scores and qualitative categories.
- If the distribution-matching term proves robust, it might become a default component in automated assessment tools to prevent systematic grade inflation or deflation.
- Future datasets could include multiple instructors per assignment to measure how well the model captures consensus versus individual variation.
- The method might generalize to other languages if comparable rubric-annotated submission sets are collected.
Load-bearing premise
The multi-semester CS1 C++ dataset paired with rubrics is representative enough that models trained on it will produce instructor-like behavior on future assignments or with different instructors.
What would settle it
Apply the best-performing model to a fresh semester of C++ submissions from a different instructor and check whether mean absolute error stays as low and the predicted grade distribution remains as closely aligned as on the original test set.
Figures
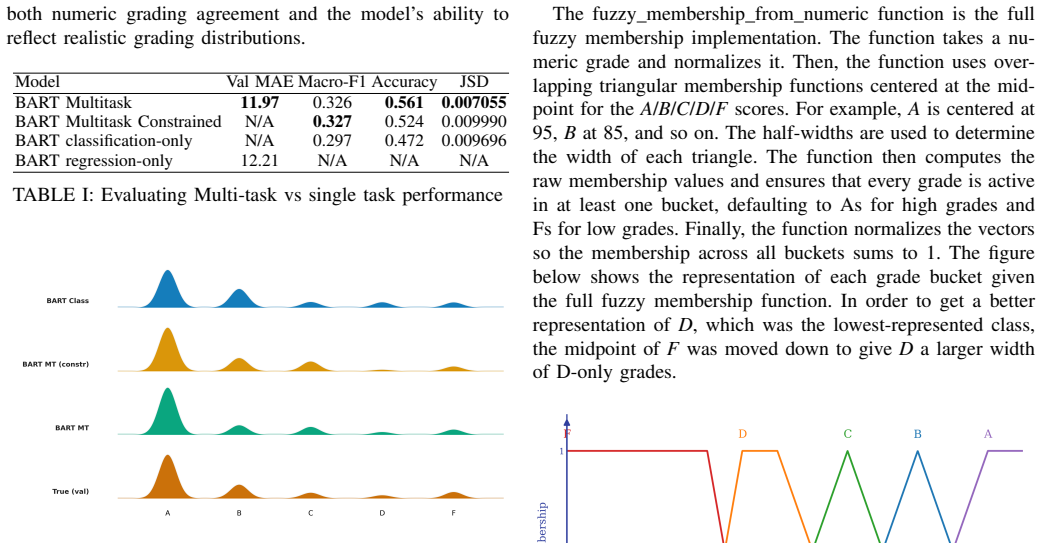

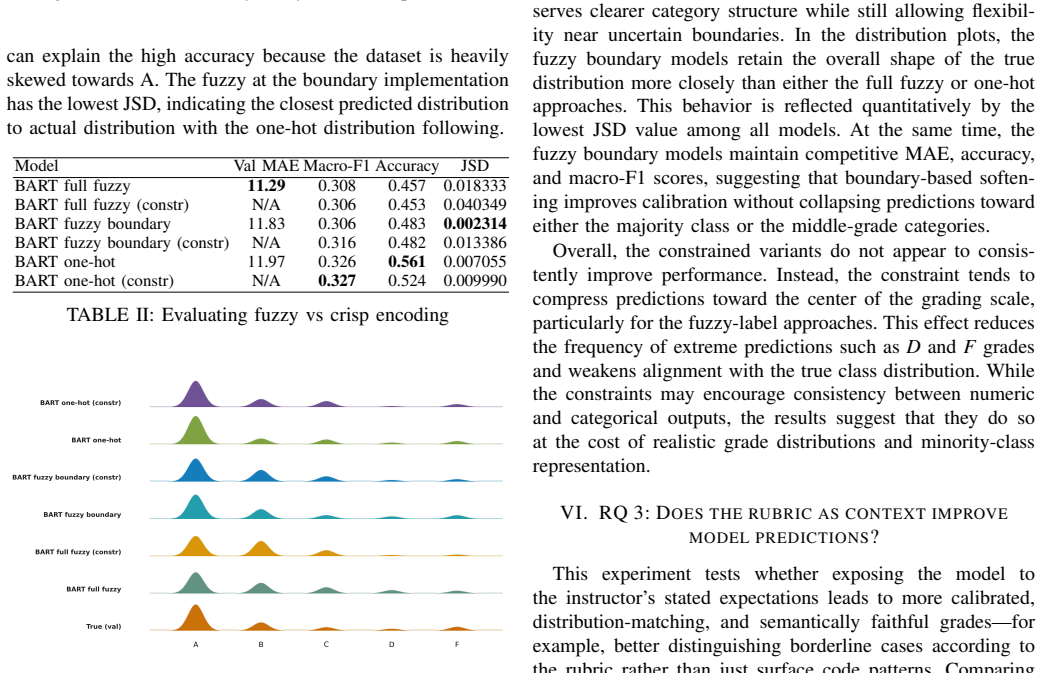
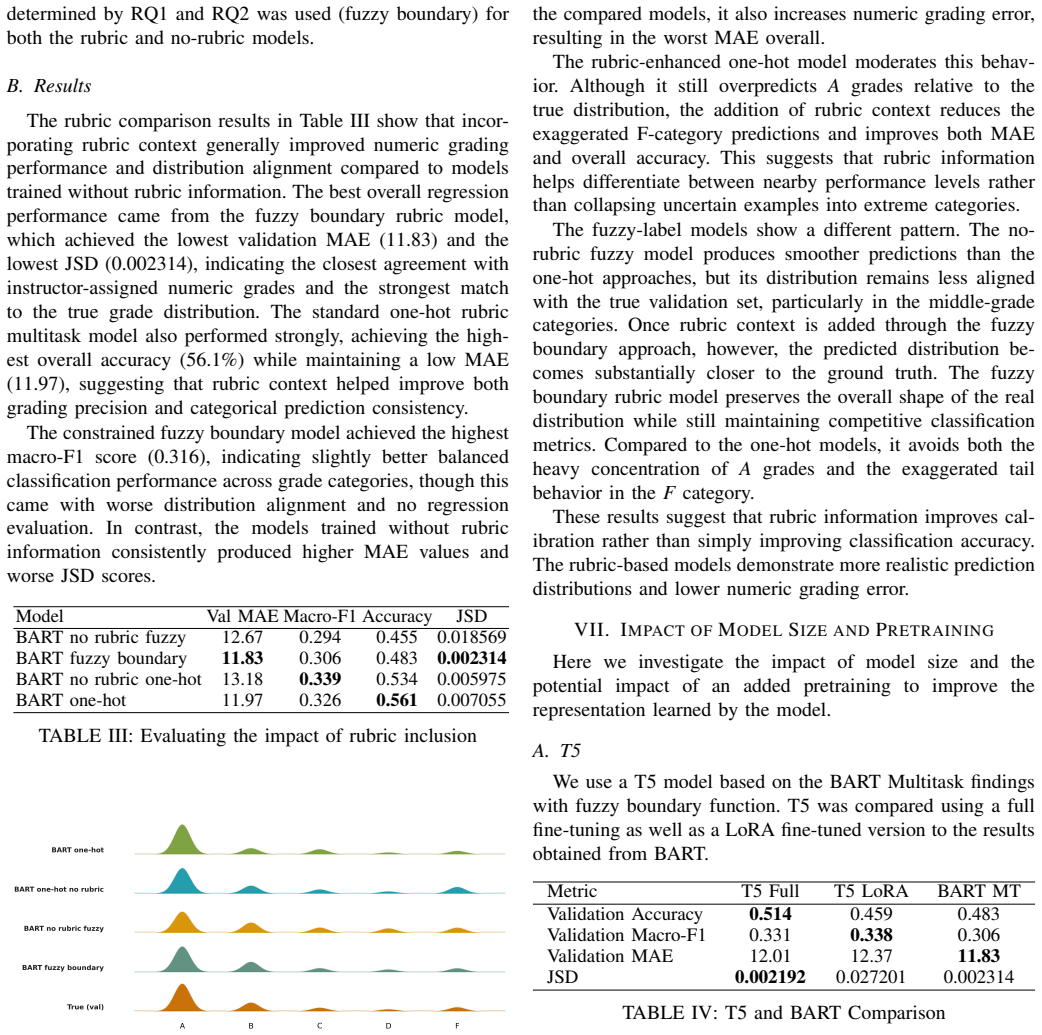
read the original abstract
This paper investigates rubric-aware, multitask fine-tuning of transformer models for automated grading of introductory C++ programming assignments, with the goal of producing grade predictions that better reflect instructor grading behavior than general-purpose LLMs. Using multi-semester CS1 data, student submissions are paired with numeric scores, letter-grade buckets, and assignment rubrics, then preprocessed into unified sequences for transformer input. A BART encoder-decoder with LoRA adaptation is trained to jointly predict numeric grades and grade buckets, augmented with a distribution-matching term to align predicted and empirical grade distributions, an evaluation dimension often overlooked in prior work. Experiments compare single-task and multitask training, hard one-hot versus fuzzy and boundary-based soft labels, and rubric versus no-rubric conditions, with additional T5 and pairwise-pretrained variants. Results show that multitask BART with boundary-based soft labels and rubric context achieves lower mean absolute error and stronger grade-distribution alignment than single-task, hard-label, or code-only baselines. Fully fine-tuned T5 further improves distributional fidelity, while pairwise pretraining reduces numeric error at the cost of minority-class sensitivity. Collectively, the findings suggest that calibration-aware, rubric-guided training produces more instructor-like grading behavior than accuracy-optimized alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates rubric-aware multitask fine-tuning of BART (with LoRA) on multi-semester CS1 C++ student submissions paired with numeric scores, letter-grade buckets, and assignment rubrics. It claims that jointly predicting numeric grades and buckets, using boundary-based soft labels and a distribution-matching term, yields lower mean absolute error and stronger alignment with empirical grade distributions than single-task, hard-label, code-only, or non-rubric baselines; additional variants with T5 and pairwise pretraining are compared.
Significance. If the central empirical claims hold and generalize, the work would offer a practical advance in automated assessment for introductory programming by incorporating rubric context and explicit distribution calibration, two elements often missing from prior LLM grading studies. The multitask and soft-label design choices address real instructor grading nuances.
major comments (2)
- [Abstract] Abstract and experimental description: the reported improvements in MAE and grade-distribution alignment are presented without dataset size, number of assignments/semesters, statistical tests, exact baseline code, or ablation controls, preventing verification of robustness.
- [Experimental description] Experimental description: all results are obtained from held-out data within the same multi-semester CS1 C++ collection; no temporal splits, new-assignment types, or different-instructor rubrics are described. This directly undermines the claim that the model produces 'instructor-like grading behavior on future assignments,' as the representativeness assumption remains untested.
minor comments (2)
- [Methods] Notation for the boundary-based soft labels and the weight on the distribution-matching term should be defined explicitly in the methods section to aid reproducibility.
- [Abstract] The abstract mentions 'fully fine-tuned T5' and 'pairwise pretraining' variants; a table summarizing all model configurations and hyper-parameters would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental transparency and clearer scoping of generalization claims. We will revise the manuscript to incorporate the requested details and to temper language regarding future assignments. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental description: the reported improvements in MAE and grade-distribution alignment are presented without dataset size, number of assignments/semesters, statistical tests, exact baseline code, or ablation controls, preventing verification of robustness.
Authors: We agree that the abstract and experimental description omit several details required for independent verification. In the revised version we will add the total number of submissions, semesters, and distinct assignments; report statistical significance (paired t-tests or Wilcoxon tests) for MAE differences; specify the exact baseline implementations (including the code-only BART configuration and hyper-parameters); and present the full set of ablation results in a dedicated table. These additions will be placed in both the abstract (concise form) and the experimental section. revision: yes
-
Referee: [Experimental description] Experimental description: all results are obtained from held-out data within the same multi-semester CS1 C++ collection; no temporal splits, new-assignment types, or different-instructor rubrics are described. This directly undermines the claim that the model produces 'instructor-like grading behavior on future assignments,' as the representativeness assumption remains untested.
Authors: We acknowledge the limitation. All reported results use random held-out splits drawn from the same multi-semester collection; no temporal, cross-assignment-type, or cross-instructor evaluations are present. We cannot retroactively create such splits without additional data. In revision we will (1) replace the phrase 'future assignments' with 'unseen submissions from the same course context' throughout the abstract, introduction, and conclusion, (2) add an explicit limitations paragraph stating that the current evaluation does not test temporal or cross-rubric generalization, and (3) outline planned future work on these dimensions. This keeps the claims commensurate with the evidence while preserving the contribution of rubric-aware multitask training within the studied distribution. revision: partial
Circularity Check
No circularity: empirical model comparisons on held-out data
full rationale
The paper's central results consist of standard machine-learning experiments: BART (and T5) models are fine-tuned on a multi-semester CS1 C++ dataset with rubric context and evaluated via MAE and grade-distribution metrics on held-out submissions. No derivation step reduces a reported prediction to a fitted parameter by construction, no self-citation supplies a uniqueness theorem or ansatz that the present work merely renames, and the evaluation protocol does not equate the output metric to an input label. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- weight on distribution-matching term
axioms (1)
- domain assumption Multi-semester CS1 C++ submissions paired with rubrics form a representative training distribution for instructor grading behavior.
Reference graph
Works this paper leans on
-
[1]
The widening gap: The benefits and harms of generative ai for novice programmers,
J. Prather, B. N. Reeves, J. Leinonen, S. MacNeil, A. S. Randrianasolo, B. A. Becker, B. Kimmel, J. Wright, and B. Briggs, “The widening gap: The benefits and harms of generative ai for novice programmers,” in Proceedings of the 2024 ACM Conference on International Computing Education Research-V olume 1, 2024, pp. 469–486
2024
-
[2]
Large language models (gpt) for automating feedback on programming assignments,
M. Pankiewicz and R. S. Baker, “Large language models (gpt) for automating feedback on programming assignments,”arXiv preprint arXiv:2307.00150, 2023
arXiv 2023
-
[3]
Intelligent assignment grading system based on bert for computer science course,
G. Jun and G. Y . Ting, “Intelligent assignment grading system based on bert for computer science course,” in2025 10th International Conference on Information and Network Technologies (ICINT). IEEE, 2025, pp. 168–174
2025
-
[4]
Codev-bench: How do llms understand developer-centric code completion?
Z. Pan, R. Cao, Y . Cao, Y . Ma, B. Li, F. Huang, H. Liu, and Y . Li, “Codev-bench: How do llms understand developer-centric code completion?”arXiv preprint arXiv:2410.01353, 2024
arXiv 2024
-
[5]
Evaluating large language models for criterion-based grading from agreement to consistency,
D.-W. Zhang, M. Boey, Y . Y . Tan, and A. H. S. Jia, “Evaluating large language models for criterion-based grading from agreement to consistency,”npj Science of Learning, vol. 9, no. 1, p. 79, 2024
2024
-
[6]
Begrading: large language models for enhanced feedback in programming education,
M. Yousef, K. Mohamed, W. Medhat, E. H. Mohamed, G. Khoriba, and T. Arafa, “Begrading: large language models for enhanced feedback in programming education,”Neural Computing and Applications, vol. 37, no. 2, pp. 1027–1040, 2025
2025
-
[7]
Rubric based automated short answer scoring using large language models (llms),
C. Senanayake and D. Asanka, “Rubric based automated short answer scoring using large language models (llms),” in2024 international re- search conference on smart computing and systems engineering (SCSE), vol. 7. IEEE, 2024, pp. 1–6
2024
-
[8]
Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics,
A. Pathak, R. Gandhi, V . Uttam, A. Ramamoorthy, P. Ghosh, A. R. Jindal, S. Verma, A. Mittal, A. Ased, C. Khatriet al., “Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics,” inProceedings of the 2025 ACM Conference on International Computing Education Research V . 1, 2025, pp. 181–195
2025
-
[9]
M. Lewis, Y . Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V . Stoyanov, and L. Zettlemoyer, “BART: denoising sequence-to- sequence pre-training for natural language generation, translation, and comprehension,”CoRR, vol. abs/1910.13461, 2019. [Online]. Available: http://arxiv.org/abs/1910.13461
Pith/arXiv arXiv 1910
-
[10]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[11]
How powerful are decoder-only transformer neural models?
J. Roberts, “How powerful are decoder-only transformer neural models?” in2024 International Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–8
2024
-
[12]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[13]
Multitask learning,
R. Caruana, “Multitask learning,”Machine learning, vol. 28, no. 1, pp. 41–75, 1997
1997
-
[14]
Application of fuzzy logic to approximate reasoning using linguistic synthesis,
Mamdani, “Application of fuzzy logic to approximate reasoning using linguistic synthesis,”IEEE transactions on computers, vol. 100, no. 12, pp. 1182–1191, 1977
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.