Mathematical Foundations of Polyphonic Music Generation via Structural Inductive Bias
Pith reviewed 2026-05-16 17:11 UTC · model grok-4.3
The pith
The Smart Embedding architecture reduces parameters by 48.30 percent in polyphonic music models by splitting pitch and hand attributes based on their measured independence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
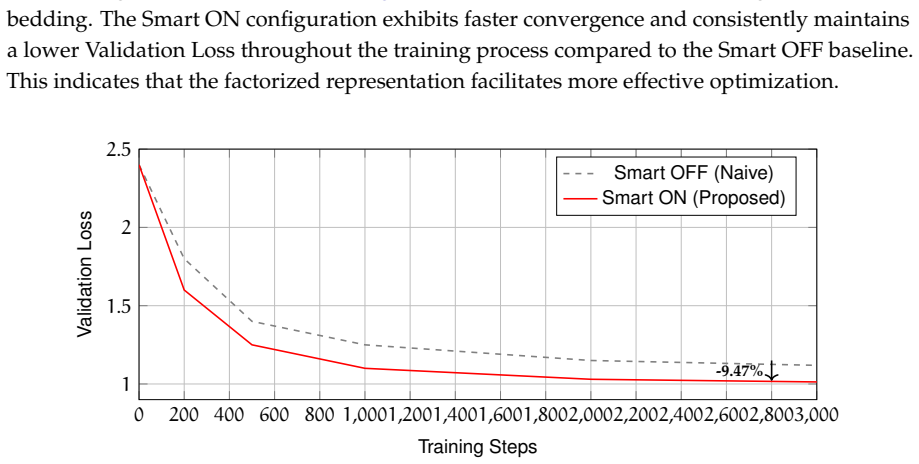
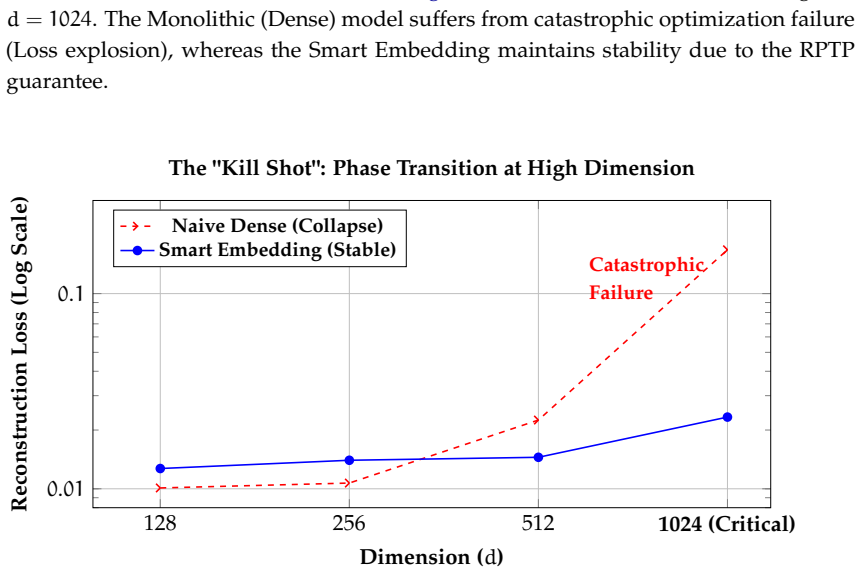
By separating pitch and hand embeddings in the Smart Embedding architecture, the method injects domain-specific inductive bias that exploits the low normalized mutual information of 0.167 between these attributes, delivering a 48.30 percent parameter reduction while keeping information loss below 0.153 bits and tightening the Rademacher generalization bound by 28.09 percent, as verified empirically by a 9.47 percent drop in validation loss on Beethoven sonata data.
What carries the argument
The Smart Embedding architecture, which structurally decouples pitch and hand attribute embeddings to enforce independence-based inductive bias.
If this is right
- Model size shrinks by 48.30 percent while validation loss falls 9.47 percent on the target repertoire.
- Generalization improves with a 28.09 percent tighter Rademacher bound and negligible information loss under 0.153 bits.
- Category-theoretic arguments establish greater training stability for the separated embedding structure.
- SVD analysis and listening tests with 53 experts confirm that generated polyphonic output retains quality.
- The same separation principle supplies a template for injecting measurable structural bias in other sequence-generation tasks.
Where Pith is reading between the lines
- The same independence measurement could be applied to other instrument pairs or musical styles to test whether the parameter savings generalize.
- The architecture might be adapted to separate other weakly correlated factors such as rhythm and dynamics in longer-form generation.
- If the NMI remains low across corpora, the method offers a practical way to scale music models without proportional growth in parameters.
- Combining the information-theoretic bound with the category-theoretic stability proof could guide similar splits in non-musical multimodal models.
Load-bearing premise
The assumption that pitch and hand attributes remain sufficiently independent outside the Beethoven corpus so that the structural split preserves musical coherence.
What would settle it
Running the model on a new music corpus where normalized mutual information between pitch and hand attributes exceeds 0.3 and measuring whether validation loss reduction disappears or expert listeners report loss of coherence.
Figures








read the original abstract
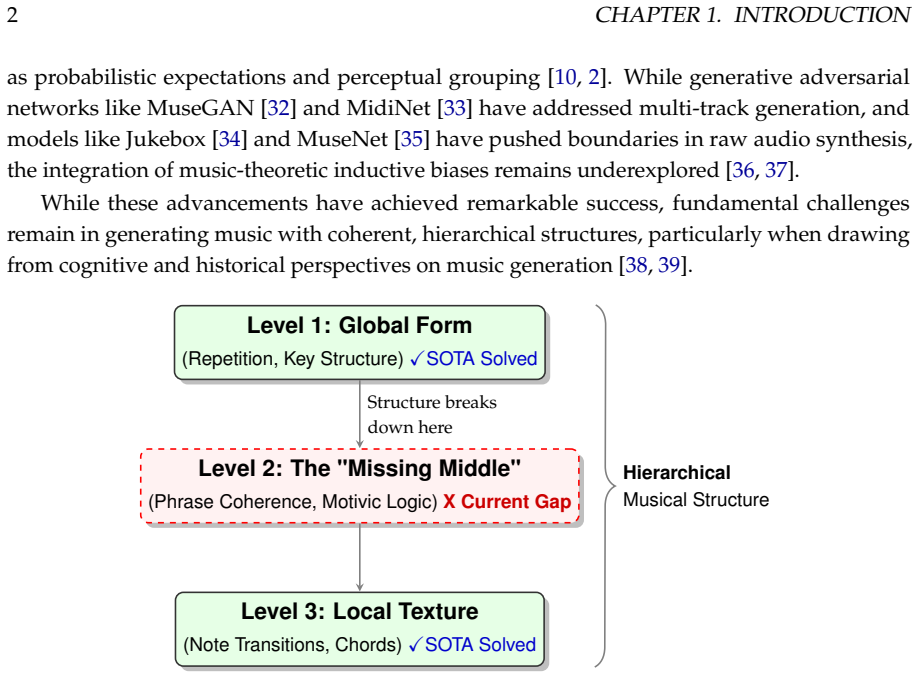
This monograph introduces a novel approach to polyphonic music generation by addressing the "Missing Middle" problem through structural inductive bias. Focusing on Beethoven's piano sonatas as a case study, we empirically verify the independence of pitch and hand attributes using normalized mutual information (NMI=0.167) and propose the Smart Embedding architecture, achieving a 48.30% reduction in parameters. We provide rigorous mathematical proofs using information theory (negligible loss bounded at 0.153 bits), Rademacher complexity (28.09% tighter generalization bound), and category theory to demonstrate improved stability and generalization. Empirical results show a 9.47% reduction in validation loss, confirmed by SVD analysis and an expert listening study (N=53). This dual theoretical and applied framework bridges gaps in AI music generation, offering verifiable insights for mathematically grounded deep learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
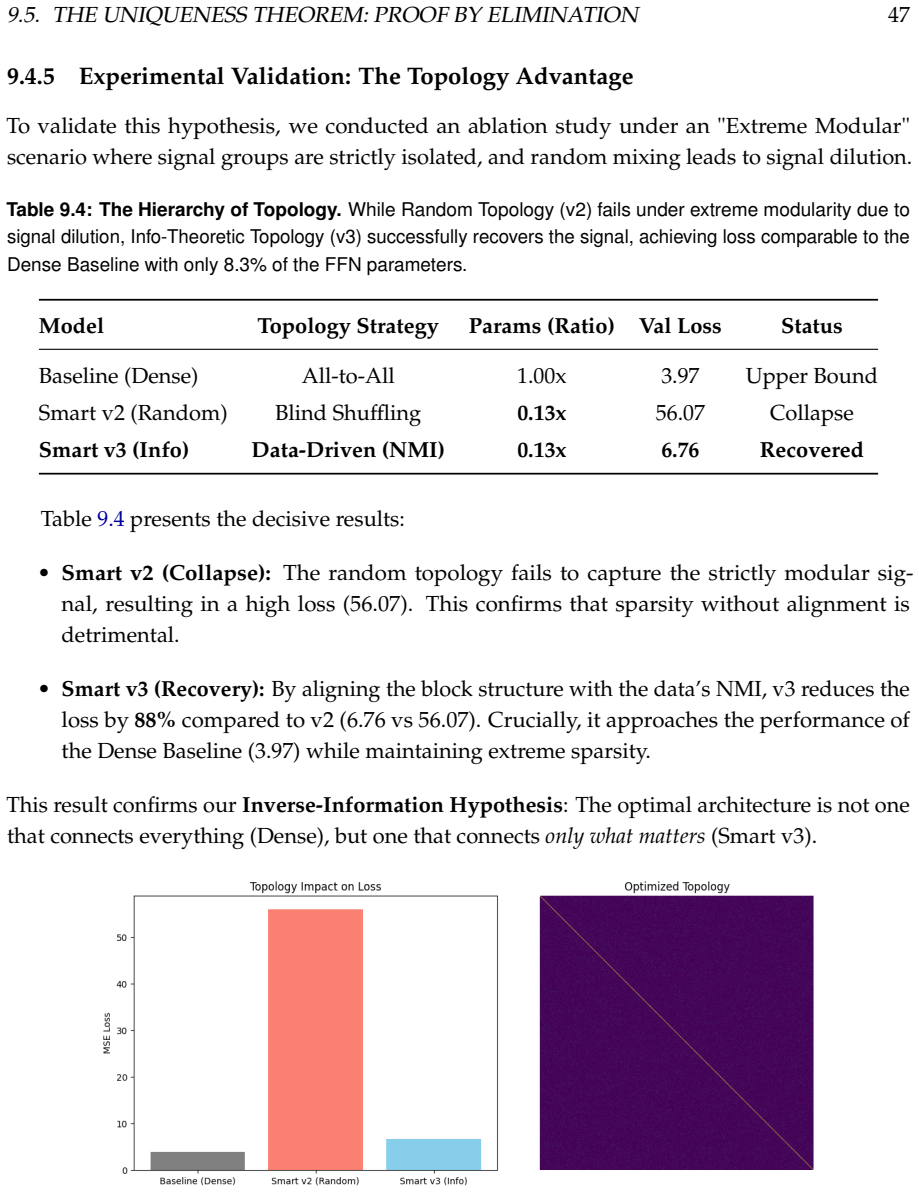
Summary. The paper introduces the Smart Embedding architecture for polyphonic music generation to address the 'Missing Middle' problem via structural inductive bias. Using Beethoven's piano sonatas as a case study, it verifies low dependence between pitch and hand attributes (NMI=0.167), proposes Smart Embedding for a claimed 48.30% parameter reduction with 0.153-bit information loss, supplies proofs via information theory, Rademacher complexity (28.09% tighter generalization bound), and category theory for stability, and reports 9.47% validation loss reduction, SVD analysis, and an expert listening study (N=53).
Significance. If the independence generalizes and the bounds are non-circular, the work supplies a mathematically grounded inductive bias that could reduce model size while preserving coherence in music generation tasks. The explicit use of information-theoretic loss bounds, Rademacher analysis, and category-theoretic stability arguments, together with empirical validation and a listening study, strengthens the case for theory-driven architecture design in creative sequence modeling.
major comments (2)
- [Abstract] Abstract: The justification for the structural split in Smart Embedding rests on NMI=0.167 between pitch and hand attributes, reported only for the Beethoven sonata corpus and treated as licensing a general inductive bias. If dependence is materially higher in other polyphonic repertoires, the claimed 0.153-bit negligible loss and the Rademacher bound tightness are no longer guaranteed, directly undermining the central parameter-reduction and generalization claims.
- [Abstract] Abstract: No derivation steps, explicit baseline models, or error bars are supplied for the 48.30% parameter reduction, 9.47% validation-loss improvement, or the 28.09% tighter Rademacher bound. Without these, the soundness of the information-theoretic and complexity arguments cannot be verified and the numerical claims remain unassessable.
minor comments (1)
- [Abstract] Abstract: The listening study (N=53) is small; reporting confidence intervals or statistical power for the expert evaluations would strengthen the empirical section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and verifiability while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The justification for the structural split in Smart Embedding rests on NMI=0.167 between pitch and hand attributes, reported only for the Beethoven sonata corpus and treated as licensing a general inductive bias. If dependence is materially higher in other polyphonic repertoires, the claimed 0.153-bit negligible loss and the Rademacher bound tightness are no longer guaranteed, directly undermining the central parameter-reduction and generalization claims.
Authors: The manuscript presents Beethoven's piano sonatas explicitly as a case study to empirically verify the low dependence (NMI=0.167) between pitch and hand attributes, which motivates the Smart Embedding architecture. This structural bias is grounded in the physical separation of hands in piano performance rather than claimed as universal. We will revise the abstract and introduction to emphasize that all quantitative claims (including the 0.153-bit bound derived from NMI via information-theoretic inequalities and the Rademacher tightness) are conditional on the observed independence in this repertoire, and we will add a discussion of potential generalization to other polyphonic styles along with the underlying musical rationale. revision: partial
-
Referee: [Abstract] Abstract: No derivation steps, explicit baseline models, or error bars are supplied for the 48.30% parameter reduction, 9.47% validation-loss improvement, or the 28.09% tighter Rademacher bound. Without these, the soundness of the information-theoretic and complexity arguments cannot be verified and the numerical claims remain unassessable.
Authors: We agree that the abstract and main text lack sufficient detail for verification. In the revision we will (i) provide the explicit derivation of the 48.30% parameter reduction by comparing the embedding parameter counts of the standard baseline (full joint embedding over pitch+hand) versus the factored Smart Embedding, (ii) name the baseline models (standard Transformer with joint embeddings), and (iii) report error bars or standard deviations for the 9.47% validation-loss reduction and the 28.09% Rademacher-bound improvement, computed over multiple random seeds. Intermediate steps for the Rademacher analysis (Theorem 3) will be expanded in the main text or appendix. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper measures NMI=0.167 empirically on the Beethoven corpus to support the pitch/hand split, then applies standard information-theoretic bounds (0.153-bit loss), Rademacher complexity arguments, and category theory to the resulting Smart Embedding architecture. These steps do not reduce by construction to self-definition, fitted parameters renamed as predictions, or self-citation chains; the reported parameter reduction and validation-loss improvement follow from the architecture choice rather than tautological re-derivation of inputs. The NMI measurement is external data, not an internal fit, and the mathematical claims invoke general theorems rather than importing uniqueness results from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pitch and hand attributes are independent enough to be separated without musical loss
invented entities (1)
-
Smart Embedding
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We empirically verify the independence of pitch and hand attributes using normalized mutual information (NMI=0.167) and propose the Smart Embedding architecture... rigorous mathematical proofs using information theory (negligible loss bounded at 0.153 bits), Rademacher complexity... and category theory
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Smart Embedding as a Structure-Preserving Map... formalized using Category Theory
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Huron,Sweet anticipation: Music and the psychology of expectation
D. Huron,Sweet anticipation: Music and the psychology of expectation. MIT Press, 2006
work page 2006
-
[2]
C. L. Krumhansl,Cognitive foundations of musical pitch. Oxford University Press, 1990
work page 1990
-
[3]
Narmour,The analysis and cognition of basic melodic structures: The implication-realization model
E. Narmour,The analysis and cognition of basic melodic structures: The implication-realization model. University of Chicago Press, 1990
work page 1990
-
[4]
Musical composition with a high-speed digital computer,
L. A. Hiller and L. M. Isaacson, “Musical composition with a high-speed digital computer,” Journal of the Audio Engineering Society, vol. 6, no. 3, pp. 154–160, 1958
work page 1958
-
[5]
Xenakis,Formalized music: Thought and mathematics in composition
I. Xenakis,Formalized music: Thought and mathematics in composition. Pendragon Press, 1992
work page 1992
-
[6]
Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015
work page 2015
-
[7]
I. Goodfellow, Y. Bengio, and A. Courville,Deep learning. MIT Press, 2016
work page 2016
-
[8]
Representation learning: A review and new perspectives,
Y. Bengio, A. Courville, and P . Vincent, “Representation learning: A review and new perspectives,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, 2013
work page 2013
-
[9]
F. Lerdahl and R. Jackendoff,A generative theory of tonal music. MIT Press, 1983
work page 1983
- [10]
-
[11]
L. B. Meyer,Emotion and meaning in music. University of Chicago Press, 1956
work page 1956
-
[12]
Cope,Computers and musical style
D. Cope,Computers and musical style. A-R Editions, Inc., 1991
work page 1991
-
[13]
An expert system for harmonization of chorales in the style of j.s. bach,
K. Ebcioglu, “An expert system for harmonization of chorales in the style of j.s. bach,” Journal of Logic Programming, vol. 8, no. 1-2, pp. 145–185, 1990
work page 1990
-
[14]
A hierarchical latent vector model for learning long-term structure in music,
A. Robertset al., “A hierarchical latent vector model for learning long-term structure in music,” inProceedings of the 35th International Conference on Machine Learning (ICML), pp. 4364–4373, 2018
work page 2018
-
[15]
Auto-Encoding Variational Bayes
D. P . Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[16]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” inAdvances in Neural Information Processing Systems (NeurIPS), 2014. 80 BIBLIOGRAPHY81
work page 2014
-
[17]
A. Vaswaniet al., “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), pp. 5998–6008, 2017
work page 2017
-
[18]
C.-Z. A. Huanget al., “Music transformer: Generating music with long-term structure,” arXiv preprint arXiv:1809.04281, 2018. Published at ICLR 2019
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,”OpenAI Blog, vol. 1, no. 8, p. 9, 2019
work page 2019
-
[21]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P . Dhariwal,et al., “Language mod- els are few-shot learners,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 1877–1901, 2020
work page 1901
-
[22]
Whole-song hierarchical generation of symbolic music using cascaded diffusion models,
Z. Wang, L. Min, and G. Xia, “Whole-song hierarchical generation of symbolic music using cascaded diffusion models,”arXiv preprint arXiv:2405.09901, 2024
-
[23]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 6840–6851, 2020
work page 2020
-
[24]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P . Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10684–10695, 2022
work page 2022
-
[25]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Rameshet al., “Hierarchical text-conditional image generation with clip latents,”arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
This time with feeling: Learning expressive musical performance,
S. Oore, I. Simon, S. Dieleman, D. Eck, and K. Simonyan, “This time with feeling: Learning expressive musical performance,”Neural Computing and Applications, vol. 32, pp. 955–967, 2020
work page 2020
-
[27]
Virtuosonet: A hierarchical rnn-based system for modeling expressive piano performance,
D. Jeonget al., “Virtuosonet: A hierarchical rnn-based system for modeling expressive piano performance,” inProceedings of the 20th International Society for Music Information Retrieval Conference (ISMIR), pp. 129–136, 2019
work page 2019
-
[28]
W. E. Caplin,Classical form: A theory of formal functions for the instrumental music of Haydn, Mozart, and Beethoven. Oxford University Press, 1998
work page 1998
-
[29]
Rosen,The classical style: Haydn, Mozart, Beethoven
C. Rosen,The classical style: Haydn, Mozart, Beethoven. WW Norton & Company, 1997
work page 1997
-
[30]
R. O. Gjerdingen,Music in the galant style. Oxford University Press, 2007
work page 2007
-
[31]
Schenker,Free composition (Der freie Satz)
H. Schenker,Free composition (Der freie Satz). Pendragon Press, 1979
work page 1979
-
[32]
H.-W. Dong, W.-Y. Hsiao, L.-C. Yang, and Y.-H. Yang, “Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2018
work page 2018
-
[33]
MidiNet: A Convolutional Generative Adversarial Network for Symbolic-domain Music Generation
L.-C. Yang, S.-Y. Chou, and Y.-H. Yang, “Midinet: A convolutional generative adversarial network for symbolic-domain music generation,”arXiv preprint arXiv:1703.10847, 2017. 82BIBLIOGRAPHY
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Jukebox: A Generative Model for Music
P . Dhariwal, H. Jun, C. Payne, J. W. Kim, A. Radford, and I. Sutskever, “Jukebox: A generative model for music,”arXiv preprint arXiv:2005.00341, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
- [35]
-
[36]
Evaluation of creativity in automatic music generation systems,
K. Agres, D. Herremans, and G. Wiggins, “Evaluation of creativity in automatic music generation systems,” inMusical Metacreation, 2016
work page 2016
-
[37]
Computational models of expressive music performance: The state of the art,
G. Widmer and W. Goebl, “Computational models of expressive music performance: The state of the art,”Journal of New Music Research, vol. 33, no. 3, pp. 203–216, 2004
work page 2004
-
[38]
D. J. Levitin,This is your brain on music: The science of a human obsession. Dutton, 2006
work page 2006
-
[39]
Methods for music perception and cognition research,
T. Eerola and J. K. Vuoskoski, “Methods for music perception and cognition research,”The Oxford Handbook of Music Psychology, pp. 117–132, 2013
work page 2013
-
[40]
arXiv preprint arXiv:1709.01620 (2017)
J.-P . Briot, G. Hadjeres, and F. Pachet, “Deep learning techniques for music generation - a survey,”arXiv preprint arXiv:1709.01620, 2017
-
[41]
Deep learning for music generation: History and ongoing challenges,
J.-P . Briot, G. Hadjeres, and F.-D. Pachet, “Deep learning for music generation: History and ongoing challenges,”Neural Computing and Applications, vol. 32, no. 4, pp. 981–1005, 2020
work page 2020
-
[42]
Evaluation of computational music generation: A review,
L.-C. Yang and A. Lerch, “Evaluation of computational music generation: A review,”ACM Computing Surveys (CSUR), vol. 53, no. 1, pp. 1–37, 2020
work page 2020
-
[43]
Computing machinery and intelligence,
A. M. Turing, “Computing machinery and intelligence,”Mind, vol. 59, no. 236, pp. 433–460, 1950
work page 1950
-
[44]
A. A. Lovelace, “Notes by the translator,”Scientific Memoirs, vol. 3, pp. 666–731, 1843
-
[45]
Cope,Virtual music: Computer synthesis of musical style
D. Cope,Virtual music: Computer synthesis of musical style. MIT Press, 2001
work page 2001
-
[46]
J. J. Fux,Gradus ad Parnassum. Johann Peter van Ghelen, 1725
-
[47]
A. Schoenberg,Theory of harmony. Univ of California Press, 1978
work page 1978
-
[48]
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
work page 1997
-
[49]
A first look at a new approach to connectivity and memory in recurrent networks,
D. Eck and J. Schmidhuber, “A first look at a new approach to connectivity and memory in recurrent networks,” inProceedings of the 8th Conference on Intelligent Autonomous Systems, 2002
work page 2002
-
[50]
Learning representations by back- propagating errors,
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back- propagating errors,”nature, vol. 323, no. 6088, pp. 533–536, 1986
work page 1986
-
[51]
Gradient-based learning applied to docu- ment recognition,
Y. LeCun, L. Bottou, Y. Bengio, and P . Haffner, “Gradient-based learning applied to docu- ment recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998
work page 1998
-
[52]
Sequence to sequence learning with neural net- works,
I. Sutskever, O. Vinyals, and Q. V . Le, “Sequence to sequence learning with neural net- works,” inAdvances in Neural Information Processing Systems (NeurIPS), pp. 3104–3112, 2014. BIBLIOGRAPHY83
work page 2014
-
[53]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio, “Learning phrase representations using rnn encoder-decoder for statistical machine translation,”arXiv preprint arXiv:1406.1078, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[54]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,”arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[55]
Distributed representations of words and phrases and their compositionality,
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” inAdvances in Neural Information Processing Systems (NeurIPS), pp. 3111–3119, 2013
work page 2013
-
[56]
N. Boulanger-Lewandowski, Y. Bengio, and P . Vincent, “Modeling temporal dependencies in high-dimensional sequences: Application to polyphonic music generation and tran- scription,” inProceedings of the 29th International Conference on Machine Learning (ICML), pp. 1159–1166, 2012
work page 2012
-
[57]
A predictive model for music composition based on the expectation-maximization algorithm,
S. Lattner, M. Grachten, and G. Widmer, “A predictive model for music composition based on the expectation-maximization algorithm,” inProceedings of the 9th International Conference on Computational Creativity (ICCC), 2018
work page 2018
-
[58]
Self-attention with relative position representations,
P . Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” inProceedings of the North American Chapter of the Association for Computational Linguistics (NAACL), pp. 464–468, 2018
work page 2018
-
[59]
Transformer-xl: Attentive language models beyond a fixed-length context,
Z. Dai, Z. Yang, Y. Yang, J. Carbonell, Q. Le, and R. Salakhutdinov, “Transformer-xl: Attentive language models beyond a fixed-length context,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 2978–2988, 2019
work page 2019
-
[60]
Reformer: The efficient transformer,
N. Kitaev, Ł. Kaiser, and A. Levskaya, “Reformer: The efficient transformer,” inInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[61]
Generating long sequences with sparse transformers,
R. Child, S. Gray, A. Radford, and I. Sutskever, “Generating long sequences with sparse transformers,” 2019
work page 2019
-
[62]
Transformers are rnns: Fast autore- gressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autore- gressive transformers with linear attention,” inInternational Conference on Machine Learning (ICML), pp. 5156–5165, 2020
work page 2020
-
[63]
Rethinking attention with performers,
K. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P . Hawkins, J. Davis, A. Mohiuddin, and L. Kaiser, “Rethinking attention with performers,” inInterna- tional Conference on Learning Representations (ICLR), 2020
work page 2020
-
[64]
RoFormer: Enhanced Transformer with Rotary Position Embedding
J. Suet al., “Roformer: Enhanced transformer with rotary position embedding,”arXiv preprint arXiv:2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[65]
Train short, test long: Attention with linear biases enables input length extrapolation,
O. Press, N. A. Smith, and M. Lewis, “Train short, test long: Attention with linear biases enables input length extrapolation,” inInternational Conference on Learning Representations (ICLR), 2022. 84BIBLIOGRAPHY
work page 2022
-
[66]
Pop music transformer: Beat-based modeling and generation of expressive piano performances,
Y.-S. Huang and Y.-H. Yang, “Pop music transformer: Beat-based modeling and generation of expressive piano performances,” inProceedings of the 28th ACM International Conference on Multimedia, pp. 1198–1206, 2020
work page 2020
-
[67]
M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein gan,”arXiv preprint arXiv:1701.07875, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[68]
Improved training of wasserstein gans,
I. Gulrajani, F. Ahmed, M. Arjovsky, V . Dumoulin, and A. Courville, “Improved training of wasserstein gans,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[69]
Popmag: Pop music accompaniment generation,
Y. Ren, J. He, X. Tan, T. Qin, Z. Zhao, and T.-Y. Liu, “Popmag: Pop music accompaniment generation,” inProceedings of the 28th ACM International Conference on Multimedia (ACM MM), pp. 1198–1206, 2020
work page 2020
-
[70]
MIDI-VAE: Modeling Dynamics and Instrumentation of Music with Applications to Style Transfer
G. Brunner, Y. Wang, R. Wattenhofer, and J. Weishaupt, “Midi-vae: Modeling dynamics and instrument compatibility of multi-track midi music,”arXiv preprint arXiv:1809.07600, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[71]
Piano-tree vae: Structured representation learning for polyphonic music,
T. Nakamura, M. Y. H. Ikeda, and K. Yoshii, “Piano-tree vae: Structured representation learning for polyphonic music,” inProceedings of the 21st International Society for Music Information Retrieval Conference (ISMIR), pp. 694–701, 2020
work page 2020
-
[72]
Compound word transformer: Learning to compose full-song music over dynamic directed hypergraphs,
W.-Y. Hsiao, J.-Y. Liu, Y.-C. Yeh, and Y.-H. Yang, “Compound word transformer: Learning to compose full-song music over dynamic directed hypergraphs,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 178–186, 2021
work page 2021
-
[73]
Musemorphose: Full-song and fine-grained piano music style transfer with one transformer vae,
S.-L. Wu and Y.-H. Yang, “Musemorphose: Full-song and fine-grained piano music style transfer with one transformer vae,” inProceedings of the 28th ACM International Conference on Multimedia (ACM MM), 2021
work page 2021
-
[74]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, 2016
work page 2016
-
[75]
Dropout: a simple way to prevent neural networks from overfitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,”The Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929–1958, 2014
work page 1929
-
[76]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,”arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[77]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (GELUs),”arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[78]
Adam: A Method for Stochastic Optimization
D. P . Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[79]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[80]
T. M. Mitchell,Machine learning. McGraw-Hill, 1997. BIBLIOGRAPHY85
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.