Recognition: no theorem link
Annotating Dimensions of Social Perception in Text: A Sentence-Level Dataset of Warmth and Competence
Pith reviewed 2026-05-16 15:30 UTC · model grok-4.3
The pith
The first sentence-level dataset annotates warmth and competence in social media text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Warmth and Competence Sentences (W&C-Sent), the first sentence-level dataset annotated for warmth and competence. The dataset includes over 1,600 English sentence-target pairs annotated along three dimensions: trust and sociability (components of warmth), and competence. The sentences in W&C-Sent are social media posts that express attitudes and opinions about specific individuals or social groups.
What carries the argument
W&C-Sent, a sentence-level annotation resource that labels social media text for the psychological dimensions of trust, sociability, and competence.
If this is right
- NLP systems can now model contextual expression of social perceptions instead of relying only on word-level lexicons.
- Large language models can be evaluated and improved on the specific task of detecting trust, sociability, and competence.
- Computational social science gains a new tool for studying how language encodes attitudes toward individuals and groups.
- The dataset supports development of applications that analyze social media for expressions of these dimensions.
Where Pith is reading between the lines
- Models trained on the data could flag stereotypical language in online discussions about social groups.
- The same annotation approach could be applied to longer texts or multi-turn conversations to study how perceptions evolve.
- Cross-cultural or cross-platform extensions of the dataset would allow comparisons of how warmth and competence are expressed in different societies.
Load-bearing premise
Crowd-worker sentence annotations reliably and validly reflect the established psychological constructs of warmth and competence.
What would settle it
If inter-annotator agreement scores are low or if the labels show no correlation with independent psychological measures of warmth and competence, the dataset would fail to capture the intended constructs.
Figures







read the original abstract
Warmth (W) (often further broken down intoTrust (T) and Sociability (S)) and Competence (C) are central dimensions along which people evaluate individuals and social groups (Fiske, 2018). While these constructs are well established in social psychology, they are only starting to get attention in NLP research through word-level lexicons, which do not fully capture their contextual expression in larger text units and discourse. In this work, we introduce Warmth and Competence Sentences (W&C-Sent), the first sentence-level dataset annotated for warmth and competence. The dataset includes over 1,600 English sentence--target pairs annotated along three dimensions: trust and sociability (components of warmth), and competence. The sentences in W&C-Sent are social media posts that express attitudes and opinions about specific individuals or social groups (the targets of our annotations). We describe the data collection, annotation, and quality-control procedures in detail, and evaluate a range of large language models (LLMs) on their ability to identify trust, sociability, and competence in text. W&C-Sent provides a new resource for analyzing warmth and competence in language and supports future research at the intersection of NLP and computational social science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces W&C-Sent, the first sentence-level dataset of over 1,600 English sentence-target pairs drawn from social media posts and annotated for trust, sociability (as components of warmth), and competence; it details the data collection, annotation, and quality-control procedures and reports evaluations of LLMs on identifying these dimensions in text.
Significance. If the annotations prove reliable, the dataset would constitute a useful new resource that moves beyond existing word-level lexicons to contextual sentence-level annotations of established social-psychology constructs, supporting future work at the intersection of NLP and computational social science on social perception and bias in language.
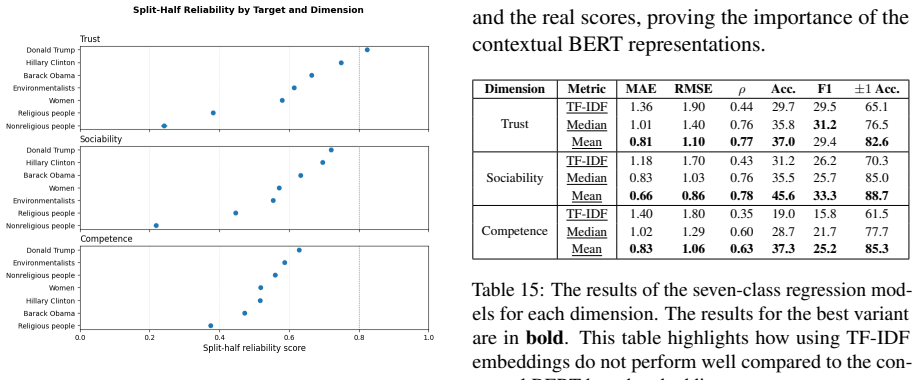
major comments (1)
- [Abstract] Abstract: the description of annotation and quality-control procedures provides no quantitative inter-annotator agreement scores (e.g., Cohen's kappa or Krippendorff's alpha), no validation against established psychological scales, and no statement on dataset release status; these omissions leave the central claim that the annotations reliably capture the warmth and competence constructs only moderately supported.
minor comments (1)
- [Abstract] Abstract: replace the approximate size 'over 1,600' with the exact count of sentence-target pairs.
Simulated Author's Rebuttal
We thank the referee for their careful review and recommendation for minor revision. We address the comment on the abstract below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of annotation and quality-control procedures provides no quantitative inter-annotator agreement scores (e.g., Cohen's kappa or Krippendorff's alpha), no validation against established psychological scales, and no statement on dataset release status; these omissions leave the central claim that the annotations reliably capture the warmth and competence constructs only moderately supported.
Authors: We agree that the abstract should include quantitative support for annotation reliability and a statement on data availability. The full manuscript reports inter-annotator agreement using Krippendorff's alpha for each dimension along with detailed quality-control procedures; we will summarize these scores in the revised abstract. We will also add that the dataset will be released publicly upon publication. Regarding validation against established psychological scales, the annotations follow the theoretical framework of warmth and competence from social psychology (Fiske, 2018), with guidelines developed to capture these constructs at sentence level. No additional empirical validation with scales was conducted in this work, as the contribution centers on creating the sentence-level resource and LLM evaluation; we will clarify this grounding in the abstract to strengthen the reliability claim. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces an annotated dataset (W&C-Sent) grounded in external social-psychology literature (Fiske 2018) and new crowd annotations on social-media sentences. No equations, parameter fitting, predictions, or self-citation chains appear; the central contribution is empirical data creation with described collection and quality-control steps. All load-bearing elements (construct definitions, annotation guidelines) reference independent prior work rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Warmth (trust and sociability) and competence are valid, measurable dimensions of social perception that can be reliably annotated at the sentence level.
Reference graph
Works this paper leans on
-
[1]
Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach
Facets of the Fundamental Content Dimen- sions: Agency with Competence and Assertive- ness—Communion with Warmth and Morality.Fron- tiers in Psychology, V olume 7 - 2016. Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. 2020. Language (technology) is power: A critical survey of “bias” in NLP. InPro- ceedings of the 58th Annual Meeting of ...
work page 2016
-
[2]
Lost in the Middle: How Language Models Use Long Contexts
Erratum in: J Pers Soc Psychol. 2024 Mar;126(3):412. Kathleen Fraser, Svetlana Kiritchenko, and Isar Ne- jadgholi. 2024. How does stereotype content differ across data sources? InProceedings of the 13th Joint Conference on Lexical and Computational Semantics (*SEM 2024), pages 18–34, Mexico City, Mexico. Association for Computational Linguistics. Gemma Te...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Gandalf Nicolas, Xuechunzi Bai, and Susan T
BERTweet: A pre-trained language model for English Tweets.Preprint, arXiv:2005.10200. Gandalf Nicolas, Xuechunzi Bai, and Susan T. Fiske
-
[4]
Comprehensive stereotype content dictionaries using a semi-automated method.European Journal of Social Psychology, 51(1):178–196. OpenAI. 2023. GPT-4 technical report.CoRR, abs/2303.08774. Nedjma Ousidhoum, Xinran Zhao, Tianqing Fang, Yangqiu Song, and Dit-Yan Yeung. 2021. Probing toxic content in large pre-trained language models. InProceedings of the 59...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Who is better at math, jenny or jingzhen? uncovering stereotypes in large language models. InProceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, pages 18601–18619, Miami, Florida, USA. Association for Computational Linguistics. Zoltán Gendler Szabó. 2024. Compositionality. In Edward N. Zalta and Uri Nodelman, editors,...
-
[6]
Countries.The first two screener sets se- lected were the “current country of residence" and the “country of birth". Since the success of the task hinges on fluency in English, the countries selected in this set were those that mainly speak English, so the following countries were selected in both sets: Antigua and Barbuda, Australia, Barbados, Belize, Ca...
-
[7]
Languages.Prolific offers three screener sets related to the languages that annotators speak. Those are “first language", “primary language", and “fluent languages". Those were all set to “English". Prolific displays the number of eligible partic- ipants after each screener set is applied, and the number decreases with every additional filter
-
[8]
highest education level completed
Education.For most screener sets regard- ing “highest education level completed", eligible participants were limited to those with at least a technical or community college degree, ranging up through undergraduate, graduate, and doctoral qualifications
-
[9]
#SemST” was removed. “@tedcruz
Approval Rate and Participation.The ap- proval rate and previous participation criteria were also important in shaping the pool of annotators. By requiring a 99-100% approval rate, I attempted to minimize the risk of low-quality or careless re- sponses, admitting only participants with an al- most impeccable record who completed tasks to researchers’ sati...
work page 2000
-
[10]
Attempt these questions only if you are fluent in English
-
[11]
Your responses are confidential
-
[12]
Let your instinct guide you; don’t overthink it
There is a degree of subjectivity in this task. Let your instinct guide you; don’t overthink it
-
[13]
Consider the entire meaning of the sentence before attempting to give the relevant scores
-
[14]
Your views regarding any of the entities or topics in the texts (such as political parties, individuals, social groups) should not affect your scores
-
[15]
To ensure fairness and the validity of our scientific findings, some questions (typically unambiguous ones!) have predetermined answer ranges. While occasional deviations are acceptable given the subjectivity of this task, contributions may be rejected if a considerable number of these questions are answered incorrectly. Reading the guidelines below is th...
work page 2016
-
[16]
What is the degree of trust towards this tar- getthatthe authorof the text seems to ex- press? Doesthe authorseem to perceive the target as trustworthy or untrustworthy / moral or immoral / honest or dishonest?
-
[17]
What is the degree of sociability towards this targetthatthe authorof the text seems to express? Doesthe authorseem to perceive the target as sociable or antisocial? Helpful or unhelpful?
-
[18]
What is the degree of competence towards this targetthatthe authorseems to express? Doesthe authorseem to perceive the target as in control or out of control? Active or pas- sive? Powerful or weak? Notes:
-
[19]
There are select examples in the next page, accompanied by an explanation of the scores given for each example
- [20]
-
[21]
All sentences were carefully chosen5
There are no repeated sentences in this study. All sentences were carefully chosen5
-
[22]
3Only the relevant dimension was included in each dimension-specific guidelines
Even if the speaker is explicitly expressing opinions towards X, if the target listed is Y , then we want to know the degree of trust, so- ciability, and competence6 towards Y only. 3Only the relevant dimension was included in each dimension-specific guidelines.. 4This point only appeared in the competence-specific guidelines. 5This part was added after a...
-
[23]
Try to be objective. Your views regarding any of the entities or topics in the texts (such as political parties, individuals, social groups) should not affect your scores
-
[24]
You can add any comments, thoughts, or justifications you may have on the scores you gave
There is an optional free-form text field un- derneath each instance. You can add any comments, thoughts, or justifications you may have on the scores you gave
-
[25]
You will have these guidelines available to you at every stage of the task by pressing on “See task details" on the top right. Examples7 Example 1: Target: Women Text: “My wife is themost caringperson I’ve ever met ... she’s the only woman in a house full of testosterone . Shenever stops workingwhether it’s at home or being an RN .I cant keep upbut I try ...
-
[26]
One might say that “women suck" expresses a very negative sentiment towards women’s trustworthiness and social likeability. This might affect the scores accordingly
-
[27]
One might claim that the competence of women isn’t really addressed since the author frames the sister’s decision-making negatively rather than women as a group
-
[28]
Consider the fact that the gender of the author is not explicit. How might it affect your scores if the author of the post were a woman? That is up to you to decide. Example 5: Target: Women Text: “I need feminism because the United States is one of the only countries that doesn’t give paid maternity leave." Trust: 0 (neutral). The author’s statement is f...
-
[29]
This is another example that shows that your political views regarding Donald Trump must not influence your score. Supporters of Trump might see this as unfair or even read stubborn- ness as positive determination, while critics might view it as more damning commentary on his interpersonal difficulties
-
[30]
Other interpretations can be just as valid. One might argue that a 0 score for competence (neutral) is appropriate; generally speaking, stubbornness is a character trait that doesn’t directly relate to competence or incompetence. While it can sometimes imply determination (positive for competence), in this context it’s more about being inflexible or diffi...
work page 2000
-
[31]
MAE and RMSE, for error magnitude
-
[32]
Spearman ρ, for correlation with human rat- ings
-
[33]
Accuracy, to observe the exact matches
-
[34]
Macro F1 score, which measures the overall balance between precision and recall across all classes
-
[35]
And the within-1-bin accuracy, which mea- sures how often model predictions fall within one rating level of the true labels captures near-miss performance in ordinal tasks L Classification Models L.1 Experimental Setup As a classification task, this approach allows the models to directly learn decision thresholds be- tween categories. As previously shown ...
work page 2016
-
[37]
reason". Then, based on your justification, add your rating to a key called “label
Does the author seem to perceive { } as trustworthy or untrustworthy / moral or immoral / honest or dishonest? Remember: even if the speaker is explicitly targeting someone else, since the target is { }, your score should be an assessment of the trust towards { } only. In the format of a JSON file or a Python dictionary, you should provide your justificat...
-
[39]
reason". Then, based on your justification, add your rating to a key called “label
Does the author seem to perceive { } as sociable or antisocial? Helpful or unhelpful? Remember: even if the speaker is explicitly target- ing someone else, since the target is { }, your score should be an assessment of perceived sociability trust towards { } only. In the format of a JSON file or a Python dictionary, you should provide your justification s...
-
[41]
reason". Then, based on your justification, add your rating to a key called “label
Does the author seem to perceive { } in control or out of control? Active or passive? Powerful or weak? Remember: even if the speaker is explicitly tar- geting someone else, since the target is { }, your score should be an assessment of the competence towards { } only. In the format of a JSON file or a Python dictionary, you should provide your justificat...
-
[43]
reason". Then, based on your justification, add your rating to a key called “label
Does the author seem to perceive { } as trustworthy or untrustworthy / moral or immoral / honest or dishonest? Remember: even if the speaker is explicitly targeting someone else, since the target is { }, your score should be an assessment of the trust towards { } only. In the format of a JSON file or a Python dictionary, you should provide your justificat...
-
[45]
reason". Then, based on your justification, add your rating to a key called “label
Does the author seem to perceive { } as sociable or antisocial? Helpful or unhelpful? Remember: even if the speaker is explicitly target- ing someone else, since the target is { }, your score should be an assessment of perceived sociability trust towards { } only. In the format of a JSON file or a Python dictionary, you should provide your justification s...
-
[47]
reason". Then, based on your justification, add your rating to a key called “label
Does the author seem to perceive { } in control or out of control? Active or passive? Powerful or weak? Remember: even if the speaker is explicitly tar- geting someone else, since the target is { }, your score should be an assessment of the competence towards { } only. In the format of a JSON file or a Python dictionary, you should provide your justificat...
-
[49]
label". You should provide your label in a JSON object whose key is called
Does the author seem to perceive { } as trustworthy or untrustworthy / moral or immoral / honest or dishonest? Remember: even if the speaker is explicitly targeting someone else, since the target is { }, your score should be an assessment of the trust towards { } only. You should analyse the meaning, then, based on your analysis, add your rating to a key ...
-
[51]
la- bel". You should provide your label in a JSON object whose key is called
Does the author seem to perceive { } as sociable or antisocial? Helpful or unhelpful? Remember: even if the speaker is explicitly target- ing someone else, since the target is { }, your score should be an assessment of perceived sociability trust towards { } only. You should analyse the meaning, then, based on your analysis, add your rating to a key calle...
-
[53]
label". You should provide your label in a JSON object whose key is called
Does the author seem to perceive { } in control or out of control? Active or passive? Powerful or weak? Remember: even if the speaker is explicitly targeting someone else, since the target is { }, your score should be an assessment of the competence towards { } only. You should analyse the meaning, then, based on your analysis, add your rating to a key ca...
-
[54]
What is the degree of trust towards { } that the author of the text seems to express?
-
[55]
label". You should provide your label in a JSON object whose key is called
Does the author seem to perceive { } as trustworthy or untrustworthy / moral or immoral / honest or dishonest? Remember: even if the speaker is explicitly targeting someone else, since the target is { }, your score should be an assessment of the trust towards { } only. You should analyse the meaning, then, based on your analysis, add your rating to a key ...
-
[56]
What is the degree of sociability towards { } that the author of the text seems to express?
-
[57]
la- bel". You should provide your label in a JSON object whose key is called
Does the author seem to perceive { } as sociable or antisocial? Helpful or unhelpful? Remember: even if the speaker is explicitly target- ing someone else, since the target is { }, your score should be an assessment of perceived sociability trust towards { } only. You should analyse the meaning, then, based on your analysis, add your rating to a key calle...
-
[58]
What is the degree of competence towards { } that the author of the text seems to express?
-
[59]
label". You should provide your label in a JSON object whose key is called
Does the author seem to perceive { } in control or out of control? Active or passive? Powerful or weak? Remember: even if the speaker is explicitly targeting someone else, since the target is { }, your score should be an assessment of the competence towards { } only. You should analyse the meaning, then, based on your analysis, add your rating to a key ca...
work page 2040
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.