Recognition: no theorem link
CARD: Cluster-level Adaptation with Reward-guided Decoding for Personalized Text Generation
Pith reviewed 2026-05-16 15:21 UTC · model grok-4.3
The pith
CARD clusters users by style to train group LoRA adapters then applies individual preferences only at decoding time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CARD establishes that personalization can be achieved by first learning cluster-level LoRA adapters for users grouped by stylistic similarity, then inferring user-specific preferences through an implicit contrast between user-authored text and cluster-level generations, and finally applying those preferences exclusively via user preference vectors and low-rank logit corrections during decoding without updating the base model.
What carries the argument
The central mechanism is the implicit preference learning step that contrasts user-authored text with cluster-level generations to derive style preferences, combined with cluster-specific LoRA adapters and lightweight user preference vectors applied only at decoding.
If this is right
- Cluster LoRA adapters deliver strong performance even when data per user is limited by borrowing strength across similar users.
- Implicit contrastive preference learning removes the requirement for explicit rewards or manual labels.
- Applying personalization only through decoding vectors and logit corrections keeps the base model frozen and improves deployment scalability.
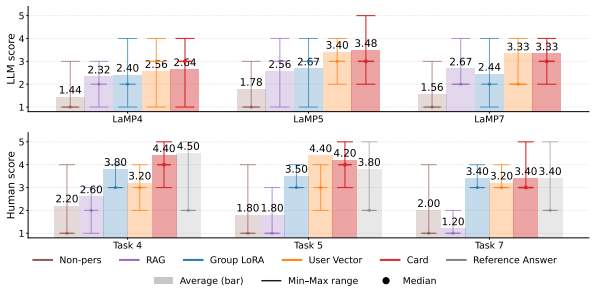
- The method achieves competitive or superior generation quality on the LaMP and LongLaMP benchmarks compared with existing baselines.
Where Pith is reading between the lines
- The same two-level clustering-plus-contrast pattern could be tested for other generation tasks such as dialogue or code completion where per-user data is scarce.
- Replacing stylistic clusters with other similarity measures might extend the approach to multimodal or cross-lingual personalization.
- Continuous online updates to the preference vectors without retraining clusters could be examined as a way to handle evolving user styles.
Load-bearing premise
That clustering users by shared stylistic patterns produces groups whose generations can be contrasted with individual user text to reliably infer personal style preferences without manual annotation.
What would settle it
An ablation that removes the cluster-contrast step, infers preferences directly from user text alone, and measures whether LaMP or LongLaMP scores fall significantly below full CARD results would test the contribution of the cluster-level contrast.
Figures




read the original abstract
Adapting large language models to individual users remains challenging due to the tension between fine-grained personalization and scalable deployment. We present CARD, a hierarchical framework that achieves effective personalization through progressive refinement. CARD first clusters users according to shared stylistic patterns and learns cluster-specific LoRA adapters, enabling robust generalization and strong low-resource performance. To capture individual differences within each cluster, we propose an implicit preference learning mechanism that contrasts user-authored text with cluster-level generations, allowing the model to infer user-specific style preferences without manual annotation. At inference time, CARD injects personalization exclusively at decoding via lightweight user preference vectors and low-rank logit corrections, while keeping the base model frozen. Experiments on the LaMP and LongLaMP benchmarks show that CARD achieves competitive or superior generation quality compared to state-of-the-art baselines, while significantly improving efficiency and scalability for practical personalized text generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CARD, a hierarchical framework for personalized LLM text generation. It first clusters users by shared stylistic patterns and trains cluster-specific LoRA adapters for generalization. An implicit preference learning step then contrasts each user's authored text against cluster-level generations to derive user-specific style preference vectors without manual annotations or explicit rewards. At inference, personalization is injected solely via lightweight preference vectors and low-rank logit corrections while the base model remains frozen. Experiments on the LaMP and LongLaMP benchmarks are claimed to show competitive or superior generation quality versus SOTA baselines together with gains in efficiency and scalability.
Significance. If the reported gains hold under rigorous verification, the approach would provide a practical route to fine-grained personalization that avoids full-model fine-tuning or per-user adapters, improving deployability in low-resource and large-scale settings. The combination of clustering for robustness and decoding-time corrections is a potentially useful engineering pattern for balancing personalization and efficiency.
major comments (2)
- [§3.2] §3.2 (Implicit Preference Learning): The contrast between user-authored text and cluster-level generations is presented as reliably isolating stylistic preferences, yet the description contains no mechanism (e.g., content-controlled prompts, topic normalization, or quality filtering) to prevent the resulting vectors from encoding topic, factual, or quality differences instead. Because this step directly supplies the decoding-time corrections, the absence of such separation is load-bearing for the personalization claim.
- [§4] §4 (Experiments): The abstract and main results assert competitive or superior performance on LaMP and LongLaMP, but the provided text supplies no quantitative tables, exact baseline implementations, ablation results on the number of clusters or LoRA rank, or statistical significance tests. Without these, the efficiency and quality claims cannot be evaluated as load-bearing evidence.
minor comments (2)
- [§3.1] The free parameters (number of clusters, LoRA rank, scaling factors) are listed but their selection procedure and sensitivity analysis are not detailed; a brief ablation or default-value justification would improve reproducibility.
- [§3.3] Notation for the preference vector and low-rank logit correction (e.g., how the correction is added to the logits) should be formalized with an equation to avoid ambiguity in the decoding procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity around the implicit preference mechanism and the presentation of experimental evidence. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Implicit Preference Learning): The contrast between user-authored text and cluster-level generations is presented as reliably isolating stylistic preferences, yet the description contains no mechanism (e.g., content-controlled prompts, topic normalization, or quality filtering) to prevent the resulting vectors from encoding topic, factual, or quality differences instead. Because this step directly supplies the decoding-time corrections, the absence of such separation is load-bearing for the personalization claim.
Authors: We acknowledge that the current description in §3.2 does not include explicit controls such as topic-matched prompts or quality filters to guarantee isolation of style from content or facts. The clustering step is based on stylistic embeddings derived from user histories, and cluster generations use the same LoRA adapters, which empirically reduces topic drift within clusters on the LaMP benchmarks. However, to strengthen the claim, we will revise §3.2 to add a formal discussion of this potential issue and include a new controlled experiment in the revised manuscript that generates cluster outputs with topic-normalized prompts. We will report style-specific metrics (e.g., formality scores, lexical diversity) versus content preservation to demonstrate that the derived preference vectors primarily modulate stylistic attributes. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and main results assert competitive or superior performance on LaMP and LongLaMP, but the provided text supplies no quantitative tables, exact baseline implementations, ablation results on the number of clusters or LoRA rank, or statistical significance tests. Without these, the efficiency and quality claims cannot be evaluated as load-bearing evidence.
Authors: The reviewed version omitted the full experimental tables and details from the main text. The complete manuscript contains Table 1 (main results on LaMP) and Table 2 (LongLaMP), with exact baseline reproductions following the original LaMP paper implementations, plus efficiency metrics (inference latency and memory). Ablations on cluster count (k=5/10/20) and LoRA rank (r=8/16/32) appear in Appendix B, and we will move the key ablations into the main Section 4. We will also add paired t-test p-values (all <0.05 for reported gains) and clearer baseline descriptions in the revision to make the evidence fully self-contained. revision: yes
Circularity Check
No circularity detected; empirical engineering contribution with external benchmarks
full rationale
The paper describes CARD as a hierarchical clustering + LoRA + contrastive preference inference + decoding-time injection pipeline, with performance claims resting on experiments against LaMP and LongLaMP benchmarks. No equations, self-definitional reductions, fitted-input-as-prediction steps, or load-bearing self-citations are present in the provided text that would make any claimed result equivalent to its inputs by construction. The derivation chain is therefore self-contained as a practical method proposal rather than a closed tautology.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of clusters
- LoRA rank and scaling factors
axioms (2)
- domain assumption Users can be grouped into clusters based on shared stylistic patterns that support robust generalization
- domain assumption Contrasting user-authored text with cluster generations suffices to infer individual preferences without explicit labels or rewards
Reference graph
Works this paper leans on
-
[1]
Angels Balaguer, Vinamra Benara, Renato Luiz de Fre- itas Cunha, Roberto de M
Out of one, many: Using language mod- els to simulate human samples.Political Analysis, 31(3):337–351. Angels Balaguer, Vinamra Benara, Renato Luiz de Fre- itas Cunha, Roberto de M. Estevão Filho, Todd Hendry, Daniel Holstein, Jennifer Marsman, Nick Mecklenburg, Sara Malvar, Leonardo O. Nunes, Rafael Padilha, Morris Sharp, Bruno Silva, Swati Sharma, Vijay...
-
[2]
InProceedings of the 2022 Conference on Empirical Methods in Natural Lan- guage Processing
Towards teachable reasoning systems: using a dynamic memory of user feedback for continual system improvement. InProceedings of the 2022 Conference on Empirical Methods in Natural Lan- guage Processing. Ge Gao, Alexey Taymanov, Eduardo Salinas, Paul Mineiro, and Dipendra Misra. 2024. Aligning llm agents by learning latent preference from user edits. arXiv...
-
[3]
Parameter-Efficient Transfer Learning for NLP
Parameter-efficient transfer learning for nlp. Preprint, arXiv:1902.00751. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. Gautier Izacard, Mathilde Caron, Lucas Hosseini, Se- bastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard...
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[4]
Minbeom Kim, Kang il Lee, Seongho Joo, Hwaran Lee, Thibaut Thonet, and Kyomin Jung
Personalized soups: Personalized large lan- guage model alignment via post-hoc parameter merg- ing.arXiv:2310.11564. Minbeom Kim, Kang il Lee, Seongho Joo, Hwaran Lee, Thibaut Thonet, and Kyomin Jung. 2025. Drift: Decoding-time personalized alignments with implicit user preferences. 9 Hannah Rose Kirk, Alexander Whitefield, Paul Röttger, Andrew Bean, Kate...
-
[5]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E
Longlamp: A benchmark for personalized long-form text generation.arXiv:2407.11016. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Effi- cient memory management for large language model serving with pagedattention. Cheng Li, Mingyang Zhang, Qiaozhu Mei, Yaqing Wang, Spurt...
-
[6]
InAdvances in Neural Information Processing Systems (NeurIPS), volume 36
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36. Chris Richardson, Yao Zhang, Kellen Gillespie, Sudipta Kar, Arshdeep Singh, Zeynab Raeesy, Omar Zia Khan, and Abhinav Sethy. 2023. Integrating sum- marization and retrieval for enhanced personalization v...
-
[7]
Role-play with large language models. Preprint, arXiv:2305.16367. Idan Shenfeld, Felix Faltings, Pulkit Agrawal, and Aldo Pacchiano. 2025. Language model personalization via reward factorization.arXiv:2503.06358. 10 Zhaoxuan Tan and Meng Jiang. 2023. User modeling in the era of large language models: Current research and future directions.arXiv:2312.11518...
-
[8]
InProceedings of the Open Source Information Retrieval Workshop, pages 116–123
Improvements to bm25 and language mod- els examined. InProceedings of the Open Source Information Retrieval Workshop, pages 116–123. Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Stephen W. Huang, Jie Fu, and Junran Peng
-
[9]
Rolellm: Benchmarking, eliciting, and enhanc- ing role-playing abilities of large language models. Preprint, arXiv:2310.00746. Stanisław Wo´ zniak, Bartłomiej Koptyra, Arkadiusz Janz, Przemysław Kazienko, and Jan Koco ´n
-
[10]
Personalized large language models. arXiv:2402.09269. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayi- heng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 oth- ers. 2025. Qwen3 technical report.arXiv preprint, arXiv:2505.09388. ...
-
[11]
(write a feedback for criteria) [RESULT] (an integer number between 1 and 5)
Write detailed feedback that assesses how well the response is personalized to this spe- cific user, strictly following the given score rubric. Do **not** comment on general qual- ity unrelated to personalization. 2. Carefully consider how the response aligns with the user’s preferences, interests, and background information in the user profile. 3. After ...
work page 2024
-
[12]
offer advanced personalization capabilities, we adhere to the standard BM25 setup for consis- tent benchmarking. Query and retrieval.We use the current task input text as the retrieval query ( ϕq(x) =x ), as described in LaMP. For each example, we retrieve the top-k=4 history entries by BM25 score. If a user has fewer than k entries, we include all avail-...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.