LLM-Based SQL Generation: Prompting, Self-Refinement, and Adaptive Weighted Majority Voting
Pith reviewed 2026-05-16 10:56 UTC · model grok-4.3
The pith
A self-refinement and voting pipeline on an existing text-to-SQL model reaches over 85 percent execution accuracy on Spider benchmarks without ground-truth data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that layering single-agent self-refinement with weighted majority voting and its randomized variant onto a PET-SQL base produces the reported benchmark accuracies without requiring ground-truth labels, and that extending the idea into a collaborative ReCAPAgent-SQL framework with specialized agents for planning, knowledge retrieval, critique, action, refinement, schema linking, and validation improves handling of real-world enterprise database tasks as measured on Spider 2.0-Lite.
What carries the argument
The Single-Agent Self-Refinement with Ensemble Voting (SSEV) pipeline, which generates multiple SQL candidates, applies iterative self-correction to each, then selects the final output through weighted majority voting.
Load-bearing premise
The accuracy gains come mainly from adding self-refinement and voting steps rather than from the underlying base model or the particular large language model used.
What would settle it
Running the identical base generator on the Spider 1.0 development set both with and without the self-refinement and voting layers and checking whether the accuracy difference remains large.
Figures



















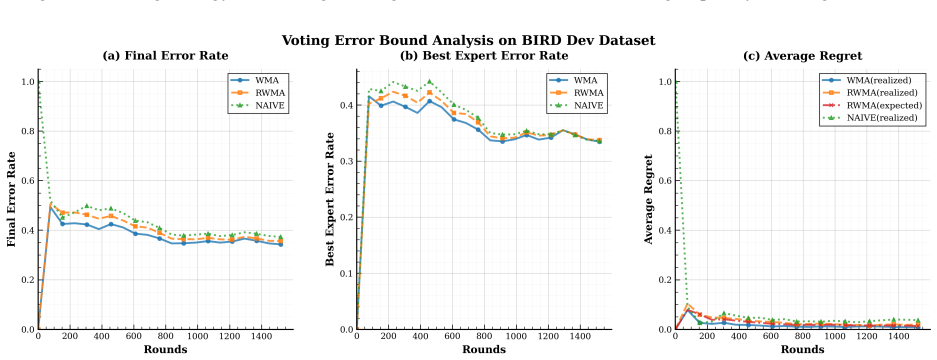

read the original abstract
Text-to-SQL has emerged as a prominent research area, particularly with the rapid advancement of large language models (LLMs). By enabling users to query databases through natural language rather than SQL, this technology significantly lowers the barrier to data analysis. However, generating accurate SQL from natural language remains challenging due to ambiguity in user queries, the complexity of schema linking, limited generalization across SQL dialects, and the need for domain-specific understanding. In this study, we propose a Single-Agent Self-Refinement with Ensemble Voting (SSEV) pipeline built on PET-SQL that operates without ground-truth data, integrating self-refinement with Weighted Majority Voting (WMV) and its randomized variant (RWMA). Experimental results show that the SSEV achieves competitive performance across multiple benchmarks, attaining execution accuracies of 85.5% on Spider 1.0-Dev, 86.4% on Spider 1.0-Test, and 66.3% on BIRD-Dev. Building on insights from the SSEV pipeline, we further propose ReCAPAgent-SQL (Refinement-Critique-Act-Plan agent-based SQL framework) to address the growing complexity of enterprise databases and real-world Text-to-SQL tasks. The framework integrates multiple specialized agents for planning, external knowledge retrieval, critique, action generation, self-refinement, schema linking, and result validation, enabling iterative refinement of SQL predictions through agent collaboration. ReCAPAgent-SQL's WMA results achieve 31% execution accuracy on the first 100 queries of Spider 2.0-Lite, demonstrating significant improvements in handling real-world enterprise scenarios. Overall, our work facilitates the deployment of scalable Text-to-SQL systems in practical settings, supporting better data-driven decision-making at lower cost and with greater efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
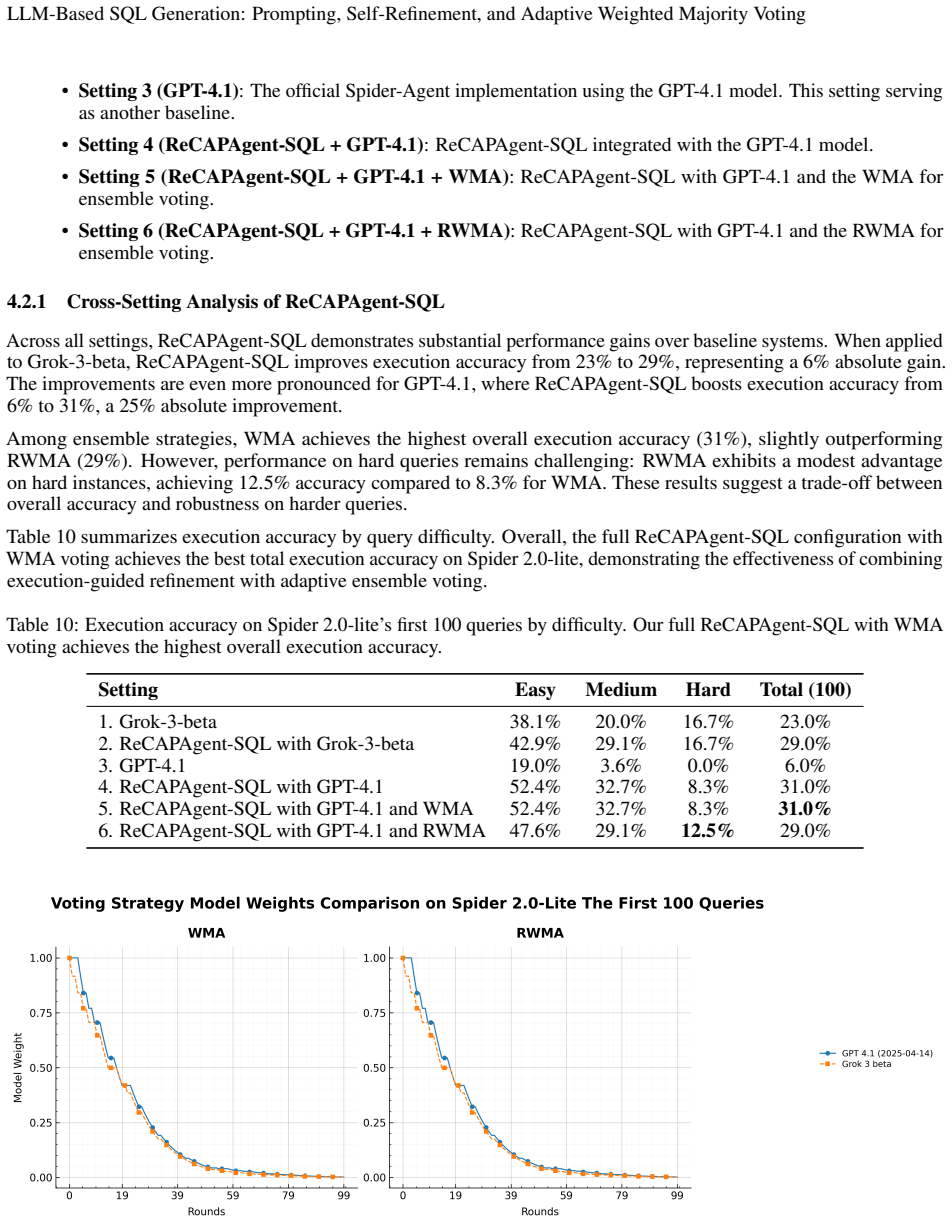
Summary. The manuscript proposes a Single-Agent Self-Refinement with Ensemble Voting (SSEV) pipeline built on PET-SQL that combines self-refinement with Weighted Majority Voting (WMV) and its randomized variant (RWMA) for Text-to-SQL generation without ground-truth data. It reports execution accuracies of 85.5% on Spider 1.0-Dev, 86.4% on Spider 1.0-Test, and 66.3% on BIRD-Dev. It further introduces ReCAPAgent-SQL, a multi-agent framework with specialized agents for planning, critique, action generation, self-refinement, schema linking, and validation, achieving 31% execution accuracy on the first 100 queries of Spider 2.0-Lite for enterprise scenarios.
Significance. If the performance claims hold after proper validation, the work could advance practical LLM-based Text-to-SQL systems by demonstrating how self-refinement and adaptive voting improve accuracy on established benchmarks and complex enterprise queries. The multi-agent ReCAPAgent-SQL framework addresses real-world challenges such as schema complexity and domain knowledge, potentially supporting more scalable and cost-effective data analysis tools.
major comments (3)
- [Abstract] Abstract: The headline execution accuracies (85.5% Spider-Dev, 86.4% Test, 66.3% BIRD) are presented as evidence that SSEV improves over prior work, yet the manuscript supplies no direct comparison of the base PET-SQL model (same LLM, same prompting budget, same schema linking) versus the full SSEV stack; without this delta the contribution of self-refinement and WMV/RWMA cannot be isolated.
- [Abstract] Abstract: No experimental protocol is described, including the specific LLM, number of self-refinement iterations, voting hyperparameters, number of runs, or statistical significance tests; this absence prevents verification that the reported numbers support the central performance claims.
- [ReCAPAgent-SQL description] ReCAPAgent-SQL section: The 31% WMA result on the first 100 queries of Spider 2.0-Lite is claimed to demonstrate significant improvements for enterprise scenarios, but the text provides neither comparisons to prior methods nor ablations of the individual agent components (planning, critique, validation), leaving the load-bearing role of the framework unassessed.
minor comments (2)
- Define all acronyms (SSEV, WMV, RWMA, ReCAPAgent-SQL) at first use and ensure consistent terminology throughout.
- Add an algorithm box or pseudocode for the adaptive weighted majority voting procedure to clarify implementation details.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the current manuscript lacks sufficient detail on experimental controls, protocols, and ablations, which limits the ability to assess the contributions of SSEV and ReCAPAgent-SQL. We will revise the manuscript to address these points directly, adding the requested comparisons, protocol descriptions, and component analyses while preserving the core claims supported by our existing results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline execution accuracies (85.5% Spider-Dev, 86.4% Test, 66.3% BIRD) are presented as evidence that SSEV improves over prior work, yet the manuscript supplies no direct comparison of the base PET-SQL model (same LLM, same prompting budget, same schema linking) versus the full SSEV stack; without this delta the contribution of self-refinement and WMV/RWMA cannot be isolated.
Authors: We agree that isolating the contribution of self-refinement and WMV/RWMA requires a direct head-to-head comparison against the unmodified PET-SQL baseline under matched conditions. In the revised version we will add a dedicated ablation table (and corresponding text in the abstract and experimental sections) reporting execution accuracy for base PET-SQL using the identical LLM, prompting budget, and schema linking procedure. This will allow readers to compute the precise delta attributable to the SSEV pipeline. revision: yes
-
Referee: [Abstract] Abstract: No experimental protocol is described, including the specific LLM, number of self-refinement iterations, voting hyperparameters, number of runs, or statistical significance tests; this absence prevents verification that the reported numbers support the central performance claims.
Authors: We acknowledge the omission. The revised manuscript will include a new “Experimental Setup” subsection that specifies the LLM (including version and temperature), exact number of self-refinement iterations, WMV/RWMA hyperparameters (weights, randomization seed, ensemble size), number of independent runs, and the statistical tests (e.g., McNemar or bootstrap confidence intervals) used to assess significance. These details will also be summarized concisely in the abstract. revision: yes
-
Referee: [ReCAPAgent-SQL description] ReCAPAgent-SQL section: The 31% WMA result on the first 100 queries of Spider 2.0-Lite is claimed to demonstrate significant improvements for enterprise scenarios, but the text provides neither comparisons to prior methods nor ablations of the individual agent components (planning, critique, validation), leaving the load-bearing role of the framework unassessed.
Authors: We agree that the current presentation does not sufficiently demonstrate the contribution of the multi-agent design. In revision we will (1) add baseline results from prior Text-to-SQL methods evaluated on the same first 100 Spider 2.0-Lite queries and (2) include an ablation study that systematically disables or replaces each agent (planning, critique, validation, etc.) while keeping the rest of the pipeline fixed. These additions will be placed in the ReCAPAgent-SQL section and summarized in the abstract. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks
full rationale
The paper reports execution accuracies measured directly on public external benchmarks (Spider 1.0-Dev/Test, BIRD-Dev, Spider 2.0-Lite) without any equations, fitted parameters, or self-referential definitions that reduce the claimed performance to quantities defined inside the same pipeline. The SSEV and ReCAPAgent-SQL pipelines are described as built on PET-SQL, but the results are presented as measured outcomes rather than predictions derived by construction from internal fits or self-citations. No load-bearing self-citation chains, ansatzes smuggled via prior work, or renaming of known results appear in the provided text. This is a standard empirical evaluation setup with no detectable circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can effectively self-refine SQL queries through iterative prompting without external ground truth
invented entities (2)
-
SSEV pipeline
no independent evidence
-
ReCAPAgent-SQL framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Revolutionize business intelligence with genbi, 2024
Wren AI. Revolutionize business intelligence with genbi, 2024. Accessed: 2025-05-21
work page 2024
-
[2]
How we built a text-to-sql ai agent to get instant answers from our data
Salesforce. How we built a text-to-sql ai agent to get instant answers from our data. https://www.salesforce. com/blog/text-to-sql-agent/, 2025. Accessed: 2025-06
work page 2025
-
[3]
Snowflake introduces cortex aisql and snowconvert ai: Analytics re- built for the ai era
Snowflake. Snowflake introduces cortex aisql and snowconvert ai: Analytics re- built for the ai era. https://www.snowflake.com/en/news/press-releases/ snowflake-introduces-cortex-aisql-and-snowconvert-ai-analytics-rebuilt-for-the-ai-era/ ,
-
[4]
Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows. InProceedings of the 12th International Conference on Learning R...
work page 2025
-
[5]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Quan Yao, and Dragomir Radev Roman. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3911–3921. Association ...
work page 2018
-
[6]
Chang, Fei Huang, Reynold Cheng, and Yongbin Li
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C.C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls.arXiv preprint arXiv:2305.03111, 2023
-
[7]
doi:10.48550/arXiv.2502.00675 , abstract =
Minghang Deng, Ashwin Ramachandran, Canwen Xu, Lanxiang Hu, Zhewei Yao, Anupam Datta, and Hao Zhang. ReFoRCE: A Text-to-SQL Agent with Self-Refinement, Consensus Enforcement, and Column Exploration.arXiv preprint arXiv:2502.00675, 2025
-
[8]
Mohammadreza Pourreza, Ruoxi Sun, Hailong Li, Lesly Miculicich, Tomas Pfister, and Sercan O Arik
Davood Rafiei Mohammadreza Pourreza. Din-sql: Decomposed in-context learning of text-to-sql with self- correction.arXiv preprint arXiv:2304.11015, 2023
-
[9]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. Text-to-sql empowered by large language models: A benchmark evaluation.arXiv preprint arXiv:2308.15363, 2023
-
[10]
arXiv preprint arXiv:2403.09732 , year=
Zhishuai Li, Xiang Wang, Jingjing Zhao, Sun Yang, Guoqing Du, Xiaoru Hu, Bin Zhang, Yuxiao Ye, Ziyue Li, Rui Zhao, and Hangyu Mao. PET-SQL: A Prompt-Enhanced Two-Round Refinement of Text-to-SQL with Cross-consistency.arXiv preprint arXiv:2403.09732, 2024
-
[11]
Next- generation database interfaces: A survey of llm-based text-to-sql.arXiv, 2024
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang. Next- generation database interfaces: A survey of llm-based text-to-sql.arXiv, 2024. 25 LLM-Based SQL Generation: Prompting, Self-Refinement, and Adaptive Weighted Majority V oting
work page 2024
-
[12]
Db-gpt: Empowering database interactions with private large language models.arXiv, 2023
Siqiao Xue, Caigao Jiang, Wenhui Shi, Fangyin Cheng, Keting Chen, Hongjun Yang, Zhiping Zhang, Jianshan He, Hongyang Zhang, Ganglin Wei, Wang Zhao, Fan Zhou, Danrui Qi, Hong Yi, Shaodong Liu, and Faqiang Chen. Db-gpt: Empowering database interactions with private large language models.arXiv, 2023
work page 2023
-
[13]
Lecture 15: The weighted majority algorithm
Shai Shalev-Shwartz. Lecture 15: The weighted majority algorithm. https://www.cs.cmu.edu/~15850/ notes/lec15.pdf, 2022. Accessed: 2025-05-22
work page 2022
- [15]
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. Accessed: 2025-06
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024
work page 2024
-
[18]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, et al. Qwen2.5-coder technical report.arXiv preprint arXiv:2409.12186, 2024. Accessed: 2025-06
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Gpt-4o: Fast, intelligent, flexible gpt model
OpenAI. Gpt-4o: Fast, intelligent, flexible gpt model. https://platform.openai.com/docs/models/ gpt-4o, 2024. Accessed: 2025-06
work page 2024
-
[20]
Gpt-4.1 - flagship gpt model for complex tasks
OpenAI. Gpt-4.1 - flagship gpt model for complex tasks. https://platform.openai.com/docs/models/ gpt-4.1, 2025. Accessed: 2025-04-23
work page 2025
-
[21]
o3-mini - a small model alternative to o3.https://platform.openai.com/docs/models/o3-mini,
OpenAI. o3-mini - a small model alternative to o3.https://platform.openai.com/docs/models/o3-mini,
-
[22]
Gemini 2.5: Our most intelligent ai model
Google DeepMind. Gemini 2.5: Our most intelligent ai model. https://deepmind.google/technologies/ gemini, 2025. Accessed: 2025-06
work page 2025
-
[23]
Grok 3 beta — the age of reasoning agents.https://x.ai/news/grok-3, 2025
xAI. Grok 3 beta — the age of reasoning agents.https://x.ai/news/grok-3, 2025. Accessed: 2025-06. 26 LLM-Based SQL Generation: Prompting, Self-Refinement, and Adaptive Weighted Majority V oting Appendix A. Self-Refinement Prompt -- Target SQL Dialect: BIGQUERY [Project Information] Current Project ID: bigquery-public-data Important: Use these IDs in your ...
work page 2025
-
[24]
First, check the database structure: - Use ’ls’ to see all files and directories - Look for files ending in .sql, .ddl, or .schema - Check for any README.md or documentation files ... [Original SQL] WITH EngagementData AS ( SELECT user_pseudo_id, event_timestamp, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = ’engagement_time_msec’) AS enga...
-
[25]
Try simplifying query structure
-
[26]
Focus on filtering conditions
-
[27]
Try SELECT with minimal columns first
-
[28]
Explain your strategy choice and apply it to refine the SQL
Double-check all referenced schema components. Explain your strategy choice and apply it to refine the SQL. 27 LLM-Based SQL Generation: Prompting, Self-Refinement, and Adaptive Weighted Majority V oting [Expected Output Format] CSV Format: distinct_pseudo_users_count (integer) Ensure the output matches this format exactly. [Next Steps]
-
[29]
First verify the database structure and table names
-
[30]
If directory access fails, try alternative paths
-
[31]
Document any access issues encountered
-
[32]
Then refine the SQL query to resolve the issue
-
[33]
Ensure the output format matches the requirements [Required Action Format] You must output exactly one of the following actions (no other text): - Action: BIGQUERY_EXEC_SQL(sql_query="...", is_save=..., save_path=".../result.csv") - Action: Terminate(output=".../result.csv") Important: When dealing with numerical results, DO NOT round the numbers. Keep th...
work page 2021
-
[34]
First, check the database structure: - Use ’ls’ to see all files and directories - Look for files ending in ’.sql’, ’.ddl’, or ’.schema’ - Check for any README.md or documentation files
-
[35]
Verify table names and schema: - Open any ‘.sql‘ or ‘.ddl‘ files to see table definitions - Look for ‘CREATE TABLE‘ statements - Note the exact database and schema names - Check for any table aliases or views - If schema file not found, try other directories ...... [Current Plan] [’Identify the relevant table in the ‘ga4‘ dataset within the bigquery-publi...
-
[36]
**TIMESTAMP Functions and Timezone Handling**: I need documentation or examples on how to handle timestamps and timezones in BigQuery "description": "GoogleSQL for BigQuery supports the following timestamp functions.\n\n IMPORTANT: Before working with these functions", ......, ‘‘‘ ## specifically for filtering data within defined date ranges (e.g. DATE | ...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.