StructAlign: Structured Cross-Modal Alignment for Continual Text-to-Video Retrieval
Pith reviewed 2026-05-16 10:37 UTC · model grok-4.3
The pith
StructAlign uses simplex ETF geometry and cross-modal relation preservation to reduce catastrophic forgetting in continual text-to-video retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
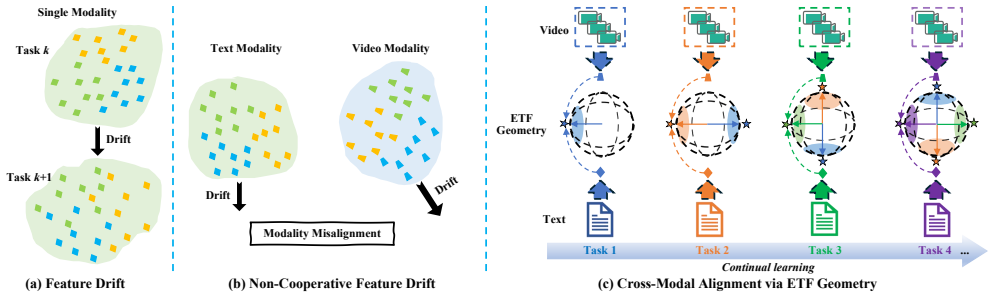
By imposing a simplex Equiangular Tight Frame geometry as a unified geometric prior and aligning both text and video features to category-level ETF prototypes via a cross-modal ETF alignment loss, while also applying a Cross-modal Relation Preserving loss that leverages complementary modalities to maintain similarity relations, StructAlign jointly counters non-cooperative cross-modal drift and intra-modal drift, thereby alleviating catastrophic forgetting in continual text-to-video retrieval.
What carries the argument
Simplex ETF geometry as a unified prior for cross-modal alignment, enforced by an ETF alignment loss on category prototypes and backed by a relation-preserving loss that supplies stable supervision across modalities.
Load-bearing premise
That imposing simplex ETF geometry on category prototypes will reliably counteract both intra-modal and cross-modal drift without introducing new misalignment or overfitting to the geometric prior.
What would settle it
A controlled ablation that removes the cross-modal ETF alignment loss while keeping all other components and then measures the increase in forgetting rate across a sequence of new category batches on a standard CTVR benchmark.
Figures







read the original abstract
Continual Text-to-Video Retrieval (CTVR) is a challenging multimodal continual learning setting, where models must incrementally learn new semantic categories while maintaining accurate text-video alignment for previously learned ones, thus making it particularly prone to catastrophic forgetting. A key challenge in CTVR is feature drift, which manifests in two forms: intra-modal feature drift caused by continual learning within each modality, and non-cooperative feature drift across modalities that leads to modality misalignment. To mitigate these issues, we propose StructAlign, a structured cross-modal alignment method for CTVR. First, StructAlign introduces a simplex Equiangular Tight Frame (ETF) geometry as a unified geometric prior to mitigate modality misalignment. Building upon this geometric prior, we design a cross-modal ETF alignment loss that aligns text and video features with category-level ETF prototypes, encouraging the learned representations to form an approximate simplex ETF geometry. In addition, to suppress intra-modal feature drift, we design a Cross-modal Relation Preserving loss, which leverages complementary modalities to preserve cross-modal similarity relations, providing stable relational supervision for feature updates. By jointly addressing non-cooperative feature drift across modalities and intra-modal feature drift, StructAlign effectively alleviates catastrophic forgetting in CTVR. Extensive experiments on benchmark datasets demonstrate that our method consistently outperforms state-of-the-art continual retrieval approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes StructAlign for Continual Text-to-Video Retrieval (CTVR), introducing a simplex Equiangular Tight Frame (ETF) geometry as a unified prior to align text and video features to category prototypes via a cross-modal ETF alignment loss, together with a Cross-modal Relation Preserving loss that uses complementary modalities to stabilize similarity relations and suppress intra-modal drift. The central claim is that jointly addressing non-cooperative cross-modal drift and intra-modal drift alleviates catastrophic forgetting, with consistent outperformance over state-of-the-art continual retrieval methods on benchmark datasets.
Significance. If the experimental claims hold under scrutiny, the work offers a structured geometric approach to cross-modal alignment in continual settings that could influence multimodal continual learning more broadly, moving beyond replay or standard regularization by enforcing an equiangular prototype structure and relation preservation.
major comments (2)
- [Abstract and §4] Abstract and §4 (method): the central claim that the simplex ETF prior plus relation-preserving loss reliably counters both non-cooperative cross-modal drift and intra-modal drift rests on the untested assumption that the rigid equiangular geometry matches evolving category semantics; no direct measurement of drift (e.g., per-category change in cross-modal cosine similarity across tasks) or ablation isolating the ETF alignment loss from the relation loss is reported.
- [§5] §5 (experiments): the assertion of consistent outperformance lacks reported quantitative results, ablation tables, or failure-mode analysis in the visible sections, so it is not possible to verify whether the proposed losses actually support the forgetting-mitigation claim or whether the ETF component introduces new misalignment on semantically uneven categories.
minor comments (2)
- [§3] Notation for the ETF prototypes and the two losses should be introduced with explicit equations early in §3 or §4 to clarify the equiangular and norm constraints.
- [§5] Figure captions and axis labels in the experimental plots could be expanded to indicate which loss variant corresponds to each curve.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and have revised the paper to incorporate additional analyses where needed.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (method): the central claim that the simplex ETF prior plus relation-preserving loss reliably counters both non-cooperative cross-modal drift and intra-modal drift rests on the untested assumption that the rigid equiangular geometry matches evolving category semantics; no direct measurement of drift (e.g., per-category change in cross-modal cosine similarity across tasks) or ablation isolating the ETF alignment loss from the relation loss is reported.
Authors: We acknowledge that explicit per-category drift measurements and an isolated ablation of the two losses were not included in the initial submission. In the revised manuscript we add these in Section 5: (i) plots and tables of per-category cross-modal cosine similarity change across tasks that quantify the reduction in both intra- and cross-modal drift, and (ii) a new ablation table that reports performance when each loss is used alone versus jointly. These results show that the ETF geometry remains stable as categories evolve and that the two losses are complementary, thereby supporting the central claim. revision: yes
-
Referee: [§5] §5 (experiments): the assertion of consistent outperformance lacks reported quantitative results, ablation tables, or failure-mode analysis in the visible sections, so it is not possible to verify whether the proposed losses actually support the forgetting-mitigation claim or whether the ETF component introduces new misalignment on semantically uneven categories.
Authors: We apologize that the quantitative tables and analyses were not sufficiently highlighted. The full manuscript already contains Tables 1–3 with retrieval metrics (mAP, Recall@K) on ActivityNet, MSR-VTT and YouCook2 demonstrating consistent gains over prior continual retrieval methods. We have now expanded Section 5 with (i) a detailed ablation table (new Table 4) isolating each loss component and (ii) a failure-mode subsection that examines performance on semantically uneven categories, including cases of potential ETF misalignment, together with mitigation strategies. These additions make the forgetting-mitigation evidence verifiable. revision: yes
Circularity Check
No significant circularity; derivation relies on external geometric prior and independent losses
full rationale
The abstract introduces simplex ETF geometry explicitly as an external unified geometric prior rather than deriving it from the model's own outputs or data fits. The cross-modal ETF alignment loss and Cross-modal Relation Preserving loss are presented as designed components to address drift, with no equations shown that reduce any claimed prediction or performance metric back to quantities fitted from the same inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way within the provided text. The central claim of alleviating catastrophic forgetting therefore rests on the independent effectiveness of these losses rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simplex Equiangular Tight Frame geometry provides a suitable unified prior that mitigates modality misalignment in continual settings
Reference graph
Works this paper leans on
-
[1]
Hyojun Ahn, Jinseok Kwak, Suha Lim, and Hyunwoo J. Kim. Ss-il: Separated softmax for incremental learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 844–853, 2021
work page 2021
- [2]
-
[3]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, G ¨ul Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1708– 1718, 2021
work page 2021
-
[4]
Non-autoregressive cross- modal coherence modelling
Yi Bin, Wenhao Shi, Jipeng Zhang, Yujuan Ding, Yang Yang, and Heng Tao Shen. Non-autoregressive cross- modal coherence modelling. InProceedings of the ACM International Conference on Multimedia, page 3253–3261, 2022
work page 2022
-
[5]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 961–970, 2015
work page 2015
-
[6]
Massimo Caccia, Pau Rodriguez, Oleksiy Ostapenko, Fabrice Normandin, Min Lin, Alexandre Lacoste, Yoshua Bengio, and Jan-Willem van de Meent. Online fast adaptation and knowledge accumulation (osaka): A new approach to continual learning.Advances in Neural Information Processing Systems, 33:16532–16545, 2020
work page 2020
-
[7]
Yuliang Cai and Mohammad Rostami. Clumo: Cluster- based modality fusion prompt for continual learning in visual question answering.Journal of Artificial Intelligence Research, 83, 2025
work page 2025
-
[8]
Francisco M. Castro, Manuel J. Mar ´ın-Jim´enez, Nicolas Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. InEuropean Conference on Computer Vision, pages 233–248, 2018
work page 2018
-
[9]
Fine-grained video-text retrieval with hierarchical graph reasoning
Shizhe Chen, Yida Zhao, Qin Jin, and Qi Wu. Fine-grained video-text retrieval with hierarchical graph reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10638–10647, 2020
work page 2020
-
[10]
Vision- sensor attention based continual multimodal egocentric ac- tivity recognition
Shaoxu Cheng, Chiyuan He, Kailong Chen, Linfeng Xu, Hongliang Li, Fanman Meng, and Qingbo Wu. Vision- sensor attention based continual multimodal egocentric ac- tivity recognition. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, pages 6300–6304, 2024
work page 2024
-
[11]
Teachtext: Cross-modal generalized distillation for text-video retrieval
Ioana Croitoru, Simion-Vlad Bogolin, Marius Leordeanu, Hailin Jin, Andrew Zisserman, Samuel Albanie, and Yang Liu. Teachtext: Cross-modal generalized distillation for text-video retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11583– 11593, 2021
work page 2021
-
[12]
Don’t stop learning: Towards continual learning for the clip model,
Yuxuan Ding, Lingqiao Liu, Chunna Tian, Jingyuan Yang, and Haoxuan Ding. Don’t stop learning: Towards continual learning for the clip model.arXiv preprint arXiv:2207.09248, 2022
-
[13]
Podnet: Pooled outputs distillation for small-tasks incremental learning
Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled outputs distillation for small-tasks incremental learning. InEuropean Conference on Computer Vision, pages 86–102, 2020
work page 2020
-
[14]
A feature- space multimodal data augmentation technique for text- video retrieval
Alex Falcon, Giuseppe Serra, and Oswald Lanz. A feature- space multimodal data augmentation technique for text- video retrieval. InProceedings of the ACM International Conference on Multimedia, pages 4385–4394, 2022
work page 2022
-
[15]
Uatvr: Uncertainty-adaptive text-video retrieval
Bo Fang, Wenhao Wu, Chang Liu, Yu Zhou, Yuxin Song, Weiping Wang, Xiangbo Shu, Xiangyang Ji, and Jingdong Wang. Uatvr: Uncertainty-adaptive text-video retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11583–11593, 2023
work page 2023
-
[16]
Han Fang, Pengfei Xiong, Luhui Xu, and Wenhan Luo. Transferring image-clip to video-text retrieval via temporal relations.IEEE Transactions on Multimedia, 25:7772–7785, 2023
work page 2023
-
[17]
Multi-modal transformer for video retrieval
Valentin Gabeur, Chen Sun, Karteek Alahari, and Cordelia Schmid. Multi-modal transformer for video retrieval. In European Conference on Computer Vision, pages 214–229, 2020
work page 2020
-
[18]
X-pool: Cross-modal language-video attention for text- video retrieval
Satya Krishna Gorti, No ¨el V ouitsis, Junwei Ma, Keyvan Golestan, Maksims V olkovs, Animesh Garg, and Guangwei Yu. X-pool: Cross-modal language-video attention for text- video retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5006– 5015, 2022
work page 2022
-
[19]
Dyson: Dynamic feature space self- organization for online task-free class incremental learning
Yuhang He, Yingjie Chen, Yuhan Jin, Songlin Dong, Xing Wei, and Yihong Gong. Dyson: Dynamic feature space self- organization for online task-free class incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23741–23751, 2024
work page 2024
-
[20]
Learning a unified classifier incrementally via rebalancing
Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a unified classifier incrementally via rebalancing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 831–839, 2019. 11
work page 2019
-
[21]
Qi Hu, Yizhou Gao, and Bo Cao. Curiosity-driven class- incremental learning via adaptive sample selection.IEEE Transactions on Circuits and Systems for Video Technology, 32(12):8660–8673, 2022
work page 2022
-
[22]
Distilling causal effect of data in class-incremental learning
Xinyu Hu, Kaihua Tang, Chunyan Miao, Xian-Sheng Hua, and Hanwang Zhang. Distilling causal effect of data in class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3957–3966, 2021
work page 2021
-
[23]
Neural collapse inspired federated learning with non-iid data
Chao Huang, Lingxi Xie, Yuhang Yang, Wenxuan Wang, Bin Lin, and Deng Cai. Neural collapse inspired federated learning with non-iid data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21043–21052, 2023
work page 2023
-
[24]
K. J. Joseph, S. Khan, F. S. Khan, et al. Energy-based latent aligner for incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7452–7461, 2022
work page 2022
-
[25]
D. Jung, D. Han, J. Bang, et al. Generating instance- level prompts for rehearsal-free continual learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11847–11857, 2023
work page 2023
-
[26]
Hybrid-tower: Fine-grained pseudo-query interaction and generation for text-to-video retrieval
Bangxiang Lan, Ruobing Xie, Ruixiang Zhao, Xingwu Sun, Zhanhui Kang, Gang Yang, and Xirong Li. Hybrid-tower: Fine-grained pseudo-query interaction and generation for text-to-video retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24497– 24506, 2025
work page 2025
-
[27]
Bakker, Nicu Sebe, and Michael S
Mingrui Lao, Nan Pu, Yu Liu, Zhun Zhong, Erwin M. Bakker, Nicu Sebe, and Michael S. Lew. Multi- domain lifelong visual question answering via self-critical distillation. InProceedings of the ACM International Conference on Multimedia, pages 4747–4758, 2023
work page 2023
-
[28]
Dynamic integration of task-specific adapters for class incremental learning
Jiashuo Li, Shaokun Wang, Bo Qian, Yuhang He, Xing Wei, Qiang Wang, and Yihong Gong. Dynamic integration of task-specific adapters for class incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 30545–30555, 2025
work page 2025
-
[29]
Multi-modal inductive framework for text-video retrieval
Qian Li, Yucheng Zhou, Cheng Ji, Feihong Lu, Jianian Gong, Shangguang Wang, and Jianxin Li. Multi-modal inductive framework for text-video retrieval. InProceedings of the ACM International Conference on Multimedia, page 2389–2398, 2024
work page 2024
-
[30]
Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2017
work page 2017
-
[31]
Hao Lin, Shikai Feng, Xiaobo Li, Guodong Xie, and Jing Huang. Anchor assisted experience replay for online class- incremental learning.IEEE Transactions on Circuits and Systems for Video Technology, 33(5):2217–2232, 2022
work page 2022
-
[32]
Peng Liu, Weizhen Yuan, Jing Fu, Weizhu Xiong, Xiang Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing.ACM Computing Surveys, 55(9):1–35, 2023
work page 2023
-
[33]
Use what you have: Video retrieval using representations from collaborative experts
Yang Liu, Samuel Albanie, Arsha Nagrani, and Andrew Zisserman. Use what you have: Video retrieval using representations from collaborative experts. InProceedings of the British Machine Vision Conference, page 279, 2019
work page 2019
-
[34]
Adaptive aggregation networks for class-incremental learning
Yaoyao Liu, Bernt Schiele, and Qianru Sun. Adaptive aggregation networks for class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2544–2553, 2021
work page 2021
-
[35]
Ts2-net: Token shift and selection transformer for text-video retrieval
Yuqi Liu, Pengfei Xiong, Luhui Xu, Shengming Cao, and Qin Jin. Ts2-net: Token shift and selection transformer for text-video retrieval. InEuropean Conference on Computer Vision, pages 319–335, 2022
work page 2022
-
[36]
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning
Huaishao Luo, Lei Ji, Ming Zhong, Yang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 508:293–304, 2022
work page 2022
-
[37]
X-clip: End-to-end multi-grained contrastive learning for video-text retrieval
Yiwei Ma, Guohai Xu, Xiaoshuai Sun, Ming Yan, Ji Zhang, and Rongrong Ji. X-clip: End-to-end multi-grained contrastive learning for video-text retrieval. InProceedings of the ACM International Conference on Multimedia, pages 638–647, 2022
work page 2022
-
[38]
Packnet: Adding multiple tasks to a single network by iterative pruning
Arun Mallya and Svetlana Lazebnik. Packnet: Adding multiple tasks to a single network by iterative pruning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7765–7773, 2018
work page 2018
-
[39]
Vardan Papyan, XY Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
work page 2020
- [40]
-
[41]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763, 2021
work page 2021
-
[42]
De Melo, Benjamin Van Durme, and Rama Chellappa
Arun Reddy, Alexander Martin, Eugene Yang, Andrew Yates, Kate Sanders, Kenton Murray, Reno Kriz, Celso M. De Melo, Benjamin Van Durme, and Rama Chellappa. Video-colbert: Contextualized late interaction for text-to- video retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19691– 19701, 2025
work page 2025
-
[43]
J. S. Smith, L. Karlinsky, V . Gutta, et al. Coda- prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11909–11919, 2023
work page 2023
-
[44]
Relation triplet construction for cross-modal text-to-video retrieval
Xue Song, Jingjing Chen, and Yu-Gang Jiang. Relation triplet construction for cross-modal text-to-video retrieval. InProceedings of the ACM International Conference on Multimedia, page 4759–4767, 2023
work page 2023
-
[45]
Spatial-temporal graphs for cross-modal text2video retrieval
Xue Song, Jingjing Chen, Zuxuan Wu, and Yu-Gang Jiang. Spatial-temporal graphs for cross-modal text2video retrieval. IEEE Transactions on Multimedia, 24:2914–2923, 2022
work page 2022
-
[46]
Learning endogenous attention for 12 incremental object detection
Xiang Song, Yuhang He, Jingyuan Li, Qiang Wang, and Yihong Gong. Learning endogenous attention for 12 incremental object detection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 30354– 30364, 2025
work page 2025
-
[47]
Feng Sun, Hong Liu, Chao Yang, and Bin Fang. Multimodal continual learning using online dictionary updating.IEEE Transactions on Cognitive and Developmental Systems, 13(1):171–178, 2020
work page 2020
-
[48]
Y . M. Tang, Y . X. Peng, and W. S. Zheng. When prompt- based incremental learning does not meet strong pretraining. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1706–1716, 2023
work page 2023
-
[49]
Topology-preserving class-incremental learning
Xiaoyu Tao, Xinyuan Chang, Xiaopeng Hong, Songlin Dong, Xing Wei, and Yihong Gong. Topology-preserving class-incremental learning. InEuropean Conference on Computer Vision, pages 254–270, 2020
work page 2020
-
[50]
new” while consolidating “known
Xiaoyu Tao, Xiaopeng Hong, Xinyuan Chang, Songlin Dong, Xing Wei, and Yihong Gong. Bi-objective continual learning: Learning “new” while consolidating “known”. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5989–5996, 2020
work page 2020
-
[51]
Holistic features are almost sufficient for text-to- video retrieval
Kaibin Tian, Ruixiang Zhao, Zijie Xin, Bangxiang Lan, and Xirong Li. Holistic features are almost sufficient for text-to- video retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17138– 17147, 2024
work page 2024
-
[52]
Dualcp: Rehearsal- free domain-incremental learning via dual-level concept prototype
Qiang Wang, Yuhang He, Songlin Dong, Xiang Song, Jizhou Han, Haoyu Luo, and Yihong Gong. Dualcp: Rehearsal- free domain-incremental learning via dual-level concept prototype. InProceedings of the AAAI Conference on Artificial Intelligence, pages 21198–21206, 2025
work page 2025
-
[53]
Shaokun Wang, Weiwei Shi, Songlin Dong, Xinyuan Gao, Xiang Song, and Yihong Gong. Semantic knowledge guided class-incremental learning.IEEE Transactions on Circuits and Systems for Video Technology, 33(10):5921–5931, 2023
work page 2023
-
[54]
Non-exemplar class-incremental learning via adaptive old class reconstruction
Shaokun Wang, Weiwei Shi, Yuhang He, Yifan Yu, and Yihong Gong. Non-exemplar class-incremental learning via adaptive old class reconstruction. InProceedings of the ACM International Conference on Multimedia, page 4524–4534, 2023
work page 2023
-
[55]
T2vlad: Global-local sequence alignment for text-video retrieval
Xiaohan Wang, Linchao Zhu, and Yi Yang. T2vlad: Global-local sequence alignment for text-video retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5079–5088, 2021
work page 2021
-
[56]
Y . Wang, Z. Huang, and X. Hong. S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning.Advances in Neural Information Processing Systems, 35:5682–5695, 2022
work page 2022
-
[57]
Unified coarse-to-fine alignment for video-text retrieval
Ziyang Wang, Yi-Lin Sung, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Unified coarse-to-fine alignment for video-text retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2804– 2815, 2023
work page 2023
-
[58]
Z. Wang, Z. Zhang, S. Ebrahimi, et al. Dualprompt: Complementary prompting for rehearsal-free continual learning. InEuropean Conference on Computer Vision, pages 631–648, 2022
work page 2022
-
[59]
Z. Wang, Z. Zhang, C. Y . Lee, et al. Learning to prompt for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 139–149, 2022
work page 2022
-
[60]
Striking a balance between stability and plasticity for class-incremental learning
Guolei Wu, Shaogang Gong, and Pan Li. Striking a balance between stability and plasticity for class-incremental learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1124–1133, 2021
work page 2021
-
[61]
Large scale incremental learning
Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, and Yun Fu. Large scale incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 374–382, 2019
work page 2019
-
[62]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5288–5296, 2016
work page 2016
-
[63]
Clip-vip: Adapting pre- trained image-text model to video-language alignment
Hongwei Xue, Yuchong Sun, Bei Liu, Jianlong Fu, Ruihua Song, Houqiang Li, and Jiebo Luo. Clip-vip: Adapting pre- trained image-text model to video-language alignment. In The International Conference on Learning Representations, 2023
work page 2023
-
[64]
Der: Dynamically expandable representation for class incremental learning
Shipeng Yan, Jie Xie, and Xuming He. Der: Dynamically expandable representation for class incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3014–3023, 2021
work page 2021
-
[65]
Low-rank prompt interaction for continual vision-language retrieval
Weicai Yan, Ye Wang, Wang Lin, Zirun Guo, Zhou Zhao, and Tao Jin. Low-rank prompt interaction for continual vision-language retrieval. InProceedings of the ACM International Conference on Multimedia, page 8257–8266, 2024
work page 2024
-
[66]
Bo Yang, Ming Lin, Yifan Zhang, Bin Liu, Xiaodan Liang, Rongrong Ji, and Qixiang Ye. Dynamic support network for few-shot class incremental learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[67]
Taco: Token-aware cascade contrastive learning for video-text alignment
Jianwei Yang, Yonatan Bisk, and Jianfeng Gao. Taco: Token-aware cascade contrastive learning for video-text alignment. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11542–11552, 2021
work page 2021
-
[68]
Recent advances of multimodal contin- ual learning: A comprehensive survey,
Dianzhi Yu, Xinni Zhang, Yankai Chen, Aiwei Liu, Yifei Zhang, Philip S. Yu, and Irwin King. Recent advances of multimodal continual learning: A comprehensive survey. arXiv preprint arXiv:2410.05352, 2024
-
[69]
Boosting continual learning of vision-language models via mixture-of-experts adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23219–23230, 2024
work page 2024
-
[70]
A joint sequence fusion model for video question answering and retrieval
Youngjae Yu, Jongseok Kim, and Gunhee Kim. A joint sequence fusion model for video question answering and retrieval. InEuropean Conference on Computer Vision, pages 471–487, 2018
work page 2018
-
[71]
Bingqing Zhang, Zhuo Cao, Heming Du, Yang Li, Xue Li, Jiajun Liu, and Sen Wang. Quantifying and narrowing the unknown: Interactive text-to-video retrieval via uncertainty minimization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22120–22130, 2025
work page 2025
-
[72]
Mpt: Multi-grained prompt tuning for 13 text-video retrieval
Haonan Zhang, Pengpeng Zeng, Lianli Gao, Jingkuan Song, and Heng Tao Shen. Mpt: Multi-grained prompt tuning for 13 text-video retrieval. InProceedings of the ACM International Conference on Multimedia, page 1206–1214, 2024
work page 2024
-
[73]
Vqacl: A novel visual question answering continual learning setting
Xi Zhang, Feifei Zhang, and Changsheng Xu. Vqacl: A novel visual question answering continual learning setting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, page 19102–19112, 2023
work page 2023
-
[74]
Hanbin Zhao, Yanwei Fu, Ming Kang, Yu-Xiong Wang, and Yonggang Xu. Mgsvf: Multi-grained slow versus fast framework for few-shot class-incremental learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(3):1576–1588, 2024
work page 2024
-
[75]
Centerclip: Token clustering for efficient text-video retrieval
Shuai Zhao, Linchao Zhu, Xiaohan Wang, and Yi Yang. Centerclip: Token clustering for efficient text-video retrieval. InProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 970–981, 2022
work page 2022
-
[76]
Continual text-to-video retrieval with frame fusion and task-aware routing
Zecheng Zhao, Zhi Chen, Zi Huang, Shazia Sadiq, and Tong Chen. Continual text-to-video retrieval with frame fusion and task-aware routing. InProceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval, page 1011–1021, 2025
work page 2025
-
[77]
Preventing zero-shot transfer degradation in continual learning of vision-language models
Zangwei Zheng, Mingyuan Ma, Kai Wang, Ziheng Qin, Xiangyu Yue, and Yang You. Preventing zero-shot transfer degradation in continual learning of vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19125–19136, 2023
work page 2023
-
[78]
Understanding imbalanced semantic segmentation through neural collapse
Zhun Zhong, Jingyun Cui, Yifan Yang, Xudong Wu, Xiaojuan Qi, Xiangyu Zhang, and Jiaya Jia. Understanding imbalanced semantic segmentation through neural collapse. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19038–19048, 2023
work page 2023
-
[79]
D. W. Zhou, H. L. Sun, H. J. Ye, et al. Expandable subspace ensemble for pre-trained model-based class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23554– 23564, 2024
work page 2024
-
[80]
D. W. Zhou, H. J. Ye, and D. C. Zhan. Co-transport for class-incremental learning. InProceedings of the ACM International Conference on Multimedia, pages 1645–1654, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.