Recognition: 2 theorem links
· Lean TheoremNeural Luenberger state observer for nonautonomous nonlinear systems
Pith reviewed 2026-05-15 18:43 UTC · model grok-4.3
The pith
Neural networks trained on data can implement state observers for nonlinear systems with external inputs and provide guaranteed error bounds on new trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an extended KKL observer for nonautonomous nonlinear systems can be realized by two feedforward neural networks: one that learns the input-affine term driving the linear observer dynamics, and one that learns the nonlinear map from observer states back to system states; when these networks are trained offline on state-input data, the composite observer is guaranteed to produce state estimates with bounded error on previously unseen input sequences.
What carries the argument
Extended KKL observer whose linear dynamics are augmented by a learned input-affine term, with a second neural network inverting the resulting injective state map.
If this is right
- State observers for complex plants can be synthesized directly from historical or simulation data rather than from first-principles equations.
- The observer can be deployed online on any new input sequence whose distribution is covered by the training set, with a priori error bounds.
- The same data-driven construction applies to any system that satisfies the extended KKL injectivity condition, including chemical reactors and biological processes.
- Offline training decouples observer design from real-time computation, allowing the networks to run at the speed of the plant sampling rate.
Where Pith is reading between the lines
- The method implicitly learns a coordinate change that linearizes the observer error dynamics, suggesting possible links to data-driven Koopman or embedding techniques.
- If the training data are collected under closed-loop operation, the resulting observer could serve as a building block for subsequent data-driven controller design.
- The guaranteed bound could be tightened by enriching the dataset with trajectories near the boundary of the operating region, offering a practical way to improve performance without changing the network architecture.
Load-bearing premise
The underlying nonlinear system must admit an extended KKL observer structure whose required functions can be approximated to sufficient accuracy by the chosen neural networks from the available training data.
What would settle it
A concrete counter-example would be a nonautonomous nonlinear system for which no choice of input-affine term produces an injective mapping from true states to observer states, or a trained network pair that, on a new validation trajectory, produces state errors larger than the bound stated in the convergence theorem.
Figures






read the original abstract
This work proposes a method for model-free synthesis of a state observer for nonlinear systems with manipulated inputs, where the observer is trained offline using a historical or simulation dataset of state measurements. We use the structure of the Kazantzis-Kravaris/Luenberger (KKL) observer, extended to nonautonomous systems by adding an additional input-affine term to the linear time-invariant (LTI) observer-state dynamics, which determines a nonlinear injective mapping of the true states. Both this input-affine term and the nonlinear mapping from the observer states to the system states are learned from data using fully connected feedforward multi-layer perceptron neural networks. Furthermore, we theoretically prove that trained neural networks, when given new input-output data, can be used to observe the states with a guaranteed error bound. To validate the proposed observer synthesis method, case studies are performed on a bioreactor and a Williams-Otto reactor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a model-free neural-network-based state observer for nonautonomous nonlinear systems. It extends the KKL observer by adding an input-affine term to the LTI observer dynamics, approximates both the nonlinear state mapping T and the input-affine function via MLPs trained offline on state-measurement datasets, proves that the resulting observer yields a guaranteed state-error bound on new input-output data, and validates the method on a bioreactor and the Williams-Otto reactor.
Significance. If the error-bound proof can be made rigorous for finite-data approximations, the work would supply a practical route to guaranteed-performance observers without requiring an explicit system model, which is valuable for process-control applications. The two reactor case studies illustrate applicability to realistic nonlinear dynamics.
major comments (1)
- [§4, main theorem] §4, main theorem on the error bound: the derivation assumes that the trained MLPs exactly realize the KKL mapping T and the input-affine function (i.e., zero approximation error). Because the networks are obtained from finite data, the residual approximation error is neither bounded nor absorbed into the contraction rate; consequently the claimed guarantee does not automatically transfer to the deployed observer.
minor comments (2)
- [Abstract] The abstract and introduction should explicitly list the standing assumptions (e.g., existence of a KKL structure, Lipschitz constants, training-data coverage) under which the bound is proved.
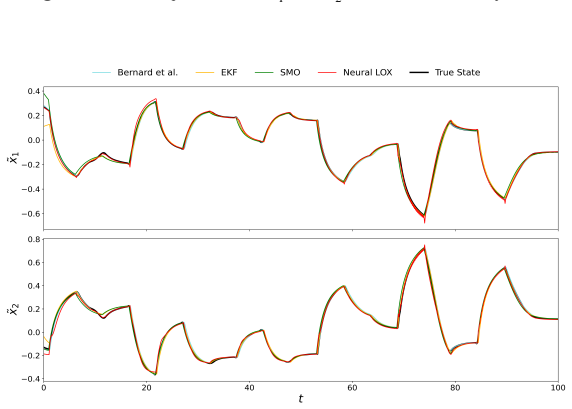
- [Section 5] Table 1 and the reactor simulation figures would benefit from reporting training-set size, validation MSE of the two networks, and a direct comparison against a model-based KKL observer or an EKF.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The primary concern regarding the rigor of the error-bound proof for finite-data neural network approximations is well-taken. We address this point below and will revise the manuscript to strengthen the theoretical result.
read point-by-point responses
-
Referee: [§4, main theorem] §4, main theorem on the error bound: the derivation assumes that the trained MLPs exactly realize the KKL mapping T and the input-affine function (i.e., zero approximation error). Because the networks are obtained from finite data, the residual approximation error is neither bounded nor absorbed into the contraction rate; consequently the claimed guarantee does not automatically transfer to the deployed observer.
Authors: We agree that the current statement of the main theorem in §4 assumes exact realization of the KKL mapping T and the input-affine term (zero approximation error). This ideal-case assumption is explicitly noted in the manuscript but, as the referee correctly observes, does not automatically extend to finite-data training without an explicit bound on the residual error. In the revised version we will augment the theorem with a small, quantifiable approximation error ε (arising from finite data and network capacity). Using standard results from neural approximation theory, we will derive a modified error bound of the form ||e(t)|| ≤ κ exp(-λt) ||e(0)|| + Cε/(1-ρ), where ρ < 1 is the contraction rate and C is a constant depending on system Lipschitz constants. We will also add a practical section on estimating ε from a held-out validation set and on choosing network depth/width to keep ε below a user-specified tolerance. These changes make the guarantee rigorous for the deployed observer while preserving the original contraction-based analysis for the ideal case. revision: yes
Circularity Check
Error bound is independent theoretical result assuming exact NN approximation of KKL structure
full rationale
The derivation chain begins with the standard KKL observer extended by an input-affine term, then replaces the exact mappings T and the affine function with MLP networks trained on state-measurement data. The central theorem proves a guaranteed state-error bound for new input-output trajectories under the assumption that these networks realize the required functions exactly (or with errors absorbed into the contraction rate). This bound is not obtained by substituting the trained weights back into the loss or by re-expressing the contraction constant in terms of empirical residuals; it remains a separate Lyapunov-style argument that holds when the universal-approximation premise is granted. No equation reduces the bound to a quantity defined solely by the finite training set, and no self-citation supplies the uniqueness or contraction property in a load-bearing way. The result is therefore self-contained against external benchmarks once the exact-representation hypothesis is accepted, yielding only a minor (score-2) caveat that finite-data residuals are not explicitly certified.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights and biases
axioms (1)
- domain assumption The nonlinear system class admits an injective mapping and observer dynamics of the extended KKL form
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use the structure of the Kazantzis-Kravaris/Luenberger (KKL) observer, extended to nonautonomous systems by adding an additional input-affine term... Both this input-affine term and the nonlinear mapping... are learned from data using fully connected feedforward multi-layer perceptron neural networks.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we theoretically prove that trained neural networks, when given new input-output data, can be used to observe the states with a guaranteed error bound
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
System identification—a survey. Automatica 7, 123–162. M. Woelk et al.:Preprint submitted to ElsevierPage 33 of 35 Nonautonomous KKL Observer Bernard,P.,Andrieu,V.,2018. Luenbergerobserversfornonautonomousnonlinearsystems. IEEETransactionsonAutomaticControl64,270–281. Bernard, P., Andrieu, V., Astolfi, D.,
work page 2018
-
[2]
Luenberger observers for discrete-time nonlinear systems, in: 2019 IEEE 58th Conference on Decision and Control (CDC), IEEE. pp. 3435–3440. Buisson-Fenet, M., Bahr, L., Morgenthaler, V., Di Meglio, F.,
work page 2019
-
[3]
IFAC-PapersOnLine 56, 4061–4067
Towards gain tuning for numerical KKL observers. IFAC-PapersOnLine 56, 4061–4067. deCarvalho,R.F.,Alvarez,L.A.,2020.SimultaneousprocessdesignandcontroloftheWilliams–Ottoreactorusinginfinitehorizonmodelpredictive control. Industrial & Engineering Chemistry Research 59, 15979–15989. Chen,B.,Zhang,H.,Liu,X.,Lin,C.,2017. Neuralobserverandadaptiveneuralcontrol...
work page 2020
-
[4]
IET Control Theory & Applications 1, 1672–1680
Observer-based strategies for actuator fault detection, isolation and estimation for certain class of uncertain nonlinear systems. IET Control Theory & Applications 1, 1672–1680. Choi,J.Y.,Farrell,J.A.,2001.Adaptiveobserverbacksteppingcontrolusingneuralnetworks.IEEETransactionsonNeuralNetworks12,1103–1112. Drakunov,S.,Utkin,V.,1995. Slidingmodeobservers.t...
work page 2001
-
[5]
International Journal of Robust and Nonlinear Control 24, 993–1015
High-gain observers in nonlinear feedback control. International Journal of Robust and Nonlinear Control 24, 993–1015. Korda,M.,Mezić,I.,2018. Linearpredictorsfornonlineardynamicalsystems:Koopmanoperatormeetsmodelpredictivecontrol. Automatica93, 149–160. Ledoux, M., Talagrand, M.,
work page 2018
-
[6]
IEEE Transactions on Military Electronics 8, 74–80
Observing the state of a linear system. IEEE Transactions on Military Electronics 8, 74–80. Mazzoleni,M.,Maurelli,L.,Formentin,S.,Previdi,F.,2024. AcomparisonofindirectanddirectfilterdesignsfromdataforLTIsystems:theeffect of unknown noise covariance matrices. IFAC-PapersOnLine 58, 133–138. Miao, K., Gatsis, K.,
work page 2024
-
[7]
arXiv preprint arXiv:2509.16744
Data-driven observer synthesis for autonomous limit cycle systems through estimation of Koopman eigenfunctions (ACC accepted). arXiv preprint arXiv:2509.16744 . Niazi,M.U.B.,Cao,J.,Sun,X.,Das,A.,Johansson,K.H.,2023. Learning-baseddesignofLuenbergerobserversforautonomousnonlinearsystems, in: 2023 American Control Conference (ACC), IEEE. pp. 3048–3055. Nova...
-
[8]
Deep learning-based Luenberger observer design for discrete-time nonlinear systems, in: 2021 60th IEEE Conference on Decision and Control (CDC), IEEE. pp. 4370–4375. Peralez,J.,Nadri,M.,2024. Deepmodel-freeKKLobserver:Aswitchingapproach,in:6thAnnualLearningforDynamics&ControlConference, PMLR. pp. 929–940. Petersen,C.D.,Fraanje,R.,Cazzolato,B.S.,Zander,A.C...
work page 2021
-
[9]
International Journal of Automation and Control 13, 469–497
Real-time implementation of nonlinear state and disturbance observer-based controller for twin rotor control system. International Journal of Automation and Control 13, 469–497. Ramos,L.d.C.,DiMeglio,F.,Morgenthaler,V.,daSilva,L.F.F.,Bernard,P.,2020. NumericaldesignofLuenbergerobserversfornonlinearsystems, in: 2020 59th IEEE Conference on Decision and Con...
work page 2020
-
[10]
Twin-in-the-loopstateestimationforvehicledynamicscontrol:Theoryandexperiments
Riva,G.,Formentin,S.,Corno,M.,Savaresi,S.M.,2024. Twin-in-the-loopstateestimationforvehicledynamicscontrol:Theoryandexperiments. IFAC Journal of Systems and Control 29, 100274. Shalev-Shwartz, S., Ben-David, S.,
work page 2024
-
[11]
Data-driven state observation for nonlinear systems based on online learning. AIChE Journal 69, e18224. M. Woelk et al.:Preprint submitted to ElsevierPage 34 of 35 Nonautonomous KKL Observer Tang,W.,2024. Synthesisofdata-drivennonlinearstateobserversusingLipschitz-boundedneuralnetworks,in:2024AmericanControlConference (ACC), IEEE. pp. 1713–1719. Tang, W.,
work page 2024
-
[12]
arXiv preprint arXiv:2503.18269
Koopman-Nemytskii operator: A linear representation of nonlinear controlled systems. arXiv preprint arXiv:2503.18269 . Teel, A., Praly, L.,
-
[13]
arXiv preprint arXiv:2509.09812
Edmd-based robust observer synthesis for nonlinear systems. arXiv preprint arXiv:2509.09812 . Zeng, C., Su, A., Chen, T., Chen, S.Z.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.