Recognition: no theorem link
Perspective-Equivariant Fine-tuning for Multispectral Demosaicing without Ground Truth
Pith reviewed 2026-05-15 18:26 UTC · model grok-4.3
The pith
Perspective-equivariant fine-tuning recovers full-resolution multispectral images from mosaiced captures alone by adapting pretrained 1-3 channel models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
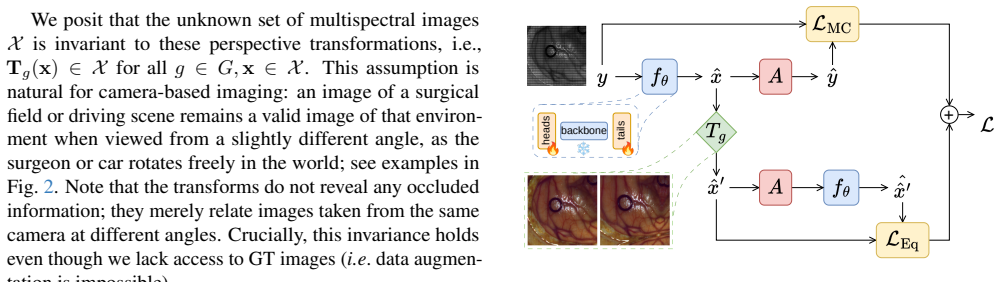
PEFD learns multispectral demosaicing without ground truth by combining two elements: it leverages the projective geometry of camera-based imaging to supply a richer group structure that recovers more null-space information from mosaiced measurements, and it efficiently adapts pretrained foundation models designed for 1-3 channel data to the multispectral setting through perspective-equivariant fine-tuning.
What carries the argument
Perspective-Equivariant Fine-tuning (PEFD), which adapts 1-3 channel foundation models by exploiting the projective transformation group of camera imaging systems to recover missing spectral information from mosaiced measurements.
If this is right
- Real-time multispectral imaging becomes feasible in dynamic environments such as operating rooms and vehicles without requiring paired line-scan ground truth.
- Fine spatial details and spectral fidelity can be preserved simultaneously in snapshot captures, closing much of the gap to supervised reconstruction quality.
- The same fine-tuning procedure applies directly to unprocessed data from existing commercial multispectral sensors.
- Unsupervised demosaicing performance improves over prior methods by using the richer projective group structure instead of smaller transformation sets.
Where Pith is reading between the lines
- Similar projective-equivariant adaptation could apply to other snapshot imaging inverse problems where camera geometry supplies extra structure.
- Lowering the ground-truth barrier may enable multispectral cameras in settings where line-scanning calibration is impractical.
- The transfer from RGB foundation models suggests that existing large-scale pretraining investments can be reused across spectral modalities with modest additional compute.
Load-bearing premise
The projective geometry of ordinary camera systems supplies enough additional structure to recover the missing information in mosaiced multispectral data, and that fine-tuning from 1-3 channel models transfers effectively without any ground-truth supervision.
What would settle it
On a held-out dataset of raw multispectral mosaics, if PEFD fails to restore blood-vessel-scale detail or introduces spectral distortions larger than those produced by classical interpolation methods, the claim of effective null-space recovery without ground truth would be refuted.
Figures







read the original abstract
Multispectral demosaicing is crucial to reconstruct full-resolution spectral images from snapshot mosaiced measurements, enabling real-time imaging from neurosurgery to autonomous driving. Classical methods are blurry, while supervised learning requires costly ground truth (GT) obtained from slow line-scanning systems. We propose Perspective-Equivariant Fine-tuning for Demosaicing (PEFD), a framework that learns multispectral demosaicing from mosaiced measurements alone. PEFD a) exploits the projective geometry of camera-based imaging systems to leverage a richer group structure than previous demosaicing methods to recover more null-space information, and b) learns efficiently without GT by adapting pretrained foundation models designed for 1-3 channel imaging. On surgical and automotive datasets, PEFD recovers fine details such as blood vessels and preserves spectral fidelity, substantially outperforming recent approaches, nearing supervised performance. Furthermore, the performance of PEFD is demonstrated on raw, unprocessed data from a commercial multispectral sensor. Code is at https://github.com/Andrewwango/pefd.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Perspective-Equivariant Fine-tuning for Demosaicing (PEFD), a self-supervised framework for reconstructing full-resolution multispectral images from snapshot mosaiced measurements. It exploits the projective geometry of camera systems to obtain a richer group structure than prior demosaicing methods, thereby recovering additional null-space information, and adapts pretrained 1-3 channel foundation models without requiring ground truth. The work reports qualitative gains on surgical and automotive datasets (recovering fine details such as blood vessels while preserving spectral fidelity), performance nearing supervised baselines, and successful application to raw data from a commercial multispectral sensor.
Significance. If the central claims hold under quantitative scrutiny, the result would be significant for real-time multispectral imaging in constrained settings such as neurosurgery and autonomous driving. By grounding self-supervised adaptation in projective geometry rather than generic regularization and by transferring from existing foundation models, the method could reduce dependence on expensive line-scanning ground truth while maintaining spectral fidelity.
major comments (2)
- [Abstract and §3 (Method)] The assertion that projective geometry supplies a richer group structure enabling recovery of additional null-space information (Abstract) is load-bearing for the novelty claim, yet the manuscript provides no explicit quantification—such as null-space dimension under projective versus Euclidean or affine groups, information-theoretic bounds, or an ablation that isolates the projective component from general self-supervised regularization.
- [Abstract and §4 (Experiments)] The claim of performance “nearing supervised” and “substantially outperforming recent approaches” (Abstract) rests on qualitative descriptions alone; no quantitative metrics, error bars, PSNR/SSIM tables, or ablation studies isolating the contribution of perspective equivariance are supplied, undermining assessment of the central empirical result.
minor comments (2)
- [§3] The description of how 1-3 channel foundation models are adapted to multispectral data (fine-tuning protocol, channel expansion strategy, loss formulation) would benefit from additional implementation details to support reproducibility.
- [§4] Figure captions and axis labels in the experimental results should explicitly state the quantitative metrics being visualized, even if the primary comparison is qualitative.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback. We address each major comment point by point below and will revise the manuscript to incorporate the suggested additions.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] The assertion that projective geometry supplies a richer group structure enabling recovery of additional null-space information (Abstract) is load-bearing for the novelty claim, yet the manuscript provides no explicit quantification—such as null-space dimension under projective versus Euclidean or affine groups, information-theoretic bounds, or an ablation that isolates the projective component from general self-supervised regularization.
Authors: We thank the referee for highlighting this point. The projective group is richer because planar homographies have 8 degrees of freedom, encompassing a larger set of geometry-preserving transformations than the Euclidean group (3 dof) or affine group (6 dof); these additional degrees of freedom align with the camera model and permit recovery of more components in the null space of the mosaicing operator. While the submitted manuscript does not contain explicit dimension calculations or isolating ablations, we will add a short theoretical subsection in §3 deriving the relevant null-space dimensions for each group together with an ablation comparing projective-equivariant fine-tuning against Euclidean-equivariant and non-equivariant baselines. These additions will quantify the extra information recovered and strengthen the novelty argument. revision: yes
-
Referee: [Abstract and §4 (Experiments)] The claim of performance “nearing supervised” and “substantially outperforming recent approaches” (Abstract) rests on qualitative descriptions alone; no quantitative metrics, error bars, PSNR/SSIM tables, or ablation studies isolating the contribution of perspective equivariance are supplied, undermining assessment of the central empirical result.
Authors: We agree that quantitative metrics are required to substantiate the performance claims. The current version emphasizes qualitative visualizations of fine-detail recovery (e.g., blood vessels) on surgical and automotive data. In the revision we will add tables reporting PSNR and SSIM values with standard deviations across multiple test images, together with direct comparisons to supervised baselines and recent self-supervised methods. We will also include ablations that isolate the contribution of perspective equivariance. These quantitative results and ablations will be placed in §4 and referenced in the abstract, allowing readers to assess how closely PEFD approaches supervised performance. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central derivation relies on external projective geometry properties of camera systems (richer group structure for null-space recovery) and adaptation of independently pretrained 1-3 channel foundation models. These are not defined in terms of the target demosaicing output or fitted parameters from the same data. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations that reduce claims to tautology appear in the abstract or described method. Empirical results on surgical, automotive, and commercial sensor datasets serve as independent validation rather than circular confirmation. This matches the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Projective geometry of camera-based imaging systems provides a richer group structure than previous demosaicing methods for recovering null-space information.
Reference graph
Works this paper leans on
-
[1]
NTIRE 2017 Chal- lenge on Single Image Super-Resolution: Dataset and Study
Eirikur Agustsson and Radu Timofte. NTIRE 2017 Chal- lenge on Single Image Super-Resolution: Dataset and Study. In2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1122–1131, 2017. ISSN: 2160-7516. 2
work page 2017
-
[2]
NTIRE 2022 Spectral Demosaicing Challenge and Data Set
Boaz Arad, Radu Timofte, Rony Yahel, Nimrod Morag, Amir Bernat, Yaqi Wu, Xun Wu, Zhihao Fan, Chenjie Xia, Feng Zhang, Shuai Liu, Yongqiang Li, Chaoyu Feng, Lei Lei, Ming- wei Zhang, Kai Feng, Xun Zhang, Jiaxin Yao, Yongqiang Zhao, Suina Ma, Fan He, Yangyang Dong, Shufang Yu, Difa Qiu, Jinhui Liu, Mengzhao Bi, Beibei Song, WenFang Sun, Jiesi Zheng, Bowen Z...
work page 2022
-
[3]
Com- putational spectral imaging: a contemporary overview.JOSA A, 40(4):C115–C125, 2023
Jorge Bacca, Emmanuel Martinez, and Henry Arguello. Com- putational spectral imaging: a contemporary overview.JOSA A, 40(4):C115–C125, 2023. 1
work page 2023
-
[4]
A color filter array based mul- tispectral camera
Johannes Brauers and Til Aach. A color filter array based mul- tispectral camera. InProc. Workshop Farbbildverarbeitung, pages 5–6, Ilmenau, Germany, 2006. 2, 6
work page 2006
-
[5]
An introduction to continuous optimization for imaging.Acta Numerica, 25: 161–319, 2016
Antonin Chambolle and Thomas Pock. An introduction to continuous optimization for imaging.Acta Numerica, 25: 161–319, 2016. 2
work page 2016
-
[6]
Sneha Chand, Karthik Namasivayam, Janak Dave, S. P. Preejith, Sadaksharam Jayachandran, and Mohanasankar Sivaprakasam. In-vivo non-contact multispectral oral dis- ease image dataset with segmentation.Scientific Data, 11(1): 1298, 2024. 1, 6, 8
work page 2024
-
[7]
Dongdong Chen, Julián Tachella, and Mike E. Davies. Equiv- ariant Imaging: Learning Beyond the Range Space. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 2, 3, 4, 6, 8, 1
work page 2021
-
[8]
Dongdong Chen, Julián Tachella, and Mike E. Davies. Robust Equivariant Imaging: a fully unsupervised framework for learning to image from noisy and partial measurements. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2, 3, 6
work page 2022
-
[9]
Matteo Ciotola, Giovanni Poggi, and Giuseppe Scarpa. Unsu- pervised Deep Learning-Based Pansharpening With Jointly Enhanced Spectral and Spatial Fidelity.IEEE Transactions on Geoscience and Remote Sensing, 61:1–17, 2023. 2
work page 2023
-
[10]
Clancy, Geoffrey Jones, Lena Maier-Hein, Daniel S
Neil T. Clancy, Geoffrey Jones, Lena Maier-Hein, Daniel S. Elson, and Danail Stoyanov. Surgical spectral imaging.Med- ical Image Analysis, 63:101699, 2020. 1
work page 2020
-
[11]
Ac- celerated MRI with Un-trained Neural Networks, 2021
Mohammad Zalbagi Darestani and Reinhard Heckel. Ac- celerated MRI with Un-trained Neural Networks, 2021. arXiv:2007.02471 [eess]. 3, 6
-
[12]
Mohammad Zalbagi Darestani, Jiayu Liu, and Reinhard Heckel. Test-Time Training Can Close the Natural Distri- bution Shift Performance Gap in Deep Learning Based Com- pressed Sensing. InProceedings of the 39th International Conference on Machine Learning, pages 4754–4776. PMLR,
-
[13]
Joint Demosaicking and Denoising by Fine-Tuning of Bursts of Raw Images
Thibaud Ehret, Axel Davy, Pablo Arias, and Gabriele Fac- ciolo. Joint Demosaicking and Denoising by Fine-Tuning of Bursts of Raw Images. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 8867–8876,
-
[14]
Piñeiro, Silvester Kabwama, Aruma J- O’Shanahan, Harry Bulstrode, Sara Bisshopp, B
Himar Fabelo, Samuel Ortega, Adam Szolna, Diederik Bulters, Juan F. Piñeiro, Silvester Kabwama, Aruma J- O’Shanahan, Harry Bulstrode, Sara Bisshopp, B. Ravi Kiran, Daniele Ravi, Raquel Lazcano, Daniel Madroñal, Coralia Sosa, Carlos Espino, Mariano Marquez, María De La Luz Plaza, Rafael Camacho, David Carrera, María Hernández, Gustavo M. Callicó, Jesús Mor...
work page 2019
-
[15]
Kai Feng, Haijin Zeng, Yongqiang Zhao, Seong G. Kong, and Yuanyang Bu. Unsupervised Spectral Demosaicing With Lightweight Spectral Attention Networks.IEEE Transactions on Image Processing, 33:1655–1669, 2024. 2, 4, 6, 7, 8
work page 2024
-
[16]
Self-Supervised Low-Light Quantum RGB Image Demosaicing
Diego Garcia-Barajas, Kebin Contreras, Brayan Monroy, and Jorge Bacca. Self-Supervised Low-Light Quantum RGB Image Demosaicing. In2025 XXV Symposium of Image, Signal Processing, and Artificial Vision (STSIVA), pages 1–5,
-
[17]
Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Networks. arXiv:1406.2661 [cs, stat], 2014. arXiv: 1406.2661. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Deep Convolutional Networks For Snapshot Hy- percpectral Demosaicking
Tewodros Amberbir Habtegebrial, Gerd Reis, and Didier Stricker. Deep Convolutional Networks For Snapshot Hy- percpectral Demosaicking. In2019 10th Workshop on Hyper- spectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), pages 1–5, 2019. ISSN: 2158-6276. 2
work page 2019
-
[19]
Cambridge University Press, Cambridge, 2 edition, 2004
Richard Hartley and Andrew Zisserman.Multiple View Ge- ometry in Computer Vision. Cambridge University Press, Cambridge, 2 edition, 2004. 3
work page 2004
- [20]
-
[21]
Spectral imaging with deep learning.Light: Science & Appli- cations, 11(1):61, 2022
Longqian Huang, Ruichen Luo, Xu Liu, and Xiang Hao. Spectral imaging with deep learning.Light: Science & Appli- cations, 11(1):61, 2022. 1
work page 2022
-
[22]
Neighbor2Neighbor: Self-Supervised De- noising from Single Noisy Images
Tao Huang, Songjiang Li, Xu Jia, Huchuan Lu, and Jianzhuang Liu. Neighbor2Neighbor: Self-Supervised De- noising from Single Noisy Images. In2021 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 14776–14785, 2021. 2, 4
work page 2021
-
[23]
Oral and Dental Spectral Image Database—ODSI-DB.Applied Sciences, 10(20):7246, 2020
Joni Hyttinen, Pauli Fält, Heli Jäsberg, Arja Kullaa, and Markku Hauta-Kasari. Oral and Dental Spectral Image Database—ODSI-DB.Applied Sciences, 10(20):7246, 2020. 1, 2
work page 2020
-
[24]
Noise2V oid - Learning Denoising From Single Noisy Im- ages
Alexander Krull, Tim-Oliver Buchholz, and Florian Jug. Noise2V oid - Learning Denoising From Single Noisy Im- ages. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2124–2132, 2019. 2 9
work page 2019
-
[25]
Edwin Kurniawan, Yunjin Park, and Sukho Lee. Noise- Resistant Demosaicing with Deep Image Prior Network and Random RGBW Color Filter Array.Sensors, 22(5):1767,
-
[26]
Deep plug-and-play prior for hyperspectral image restoration.Neurocomputing, 481:281–293, 2022
Zeqiang Lai, Kaixuan Wei, and Ying Fu. Deep plug-and-play prior for hyperspectral image restoration.Neurocomputing, 481:281–293, 2022. 3
work page 2022
-
[27]
Pierre-Jean Lapray, Xingbo Wang, Jean-Baptiste Thomas, and Pierre Gouton. Multispectral Filter Arrays: Recent Advances and Practical Implementation.Sensors, 14(11):21626–21659,
-
[28]
Cruz- Guerrero, Daniel Ulises Campos-Delgado, Adam Szolna, Juan F
Raquel Leon, Himar Fabelo, Samuel Ortega, Ines A. Cruz- Guerrero, Daniel Ulises Campos-Delgado, Adam Szolna, Juan F. Piñeiro, Carlos Espino, Aruma J. O’Shanahan, Maria Hernandez, David Carrera, Sara Bisshopp, Coralia Sosa, Fran- cisco J. Balea-Fernandez, Jesus Morera, Bernardino Clavo, and Gustavo M. Callico. Hyperspectral imaging benchmark based on machi...
work page 2023
-
[29]
Jinyang Li, Jia Hao, Geng Tong, Shahid Karim, Xu Sun, and Yiting Yu. Unsupervised demosaicking network using the recurrent renovation and the pixel-wise guidance.Optics Letters, 47(16):4008–4011, 2022. 3
work page 2022
-
[30]
Peichao Li, Michael Ebner, Philip Noonan, Conor Horgan, Anisha Bahl, Sébastien Ourselin, Jonathan Shapey, and Tom Vercauteren. Deep learning approach for hyperspectral image demosaicking, spectral correction and high-resolution RGB reconstruction.Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, 10(4): 409–417, 2022. 1, 5
work page 2022
-
[31]
Peichao Li, Muhammad Asad, Conor Horgan, Oscar MacCor- mac, Jonathan Shapey, and Tom Vercauteren. Spatial gradient consistency for unsupervised learning of hyperspectral de- mosaicking: application to surgical imaging.International Journal of Computer Assisted Radiology and Surgery, 18(6): 981–988, 2023. 2, 6, 7, 8
work page 2023
-
[32]
Peichao Li, Oscar MacCormac, Jonathan Shapey, and Tom Vercauteren. A self-supervised and adversarial approach to hyperspectral demosaicking and RGB reconstruction in surgi- cal imaging. InProceedings of BMVC 2024, Glasgow, 2024. BMV A. arXiv:2407.19282 [eess]. 2
-
[33]
Joint Demosaicing And Denoising With Double Deep Image Priors
Taihui Li, Anish Lahiri, Yutong Dai, and Owen Mayer. Joint Demosaicing And Denoising With Double Deep Image Priors. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4005–4009, 2024. 2, 3, 4
work page 2024
-
[34]
LS- DIR: A Large Scale Dataset for Image Restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Deman- dolx, Rakesh Ranjan, Radu Timofte, and Luc Van Gool. LS- DIR: A Large Scale Dataset for Image Restoration. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1775–1787, 2023. 2
work page 2023
-
[35]
Enhanced Deep Residual Networks for Single Image Super-Resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced Deep Residual Networks for Single Image Super-Resolution. In2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1132–1140, 2017. ISSN: 2160-7516. 6
work page 2017
-
[36]
Chang Liu, Songze He, Jiajun Xu, and Jia Li. Fine-Tuning for Bayer Demosaicking Through Periodic-Consistent Self- Supervised Learning.IEEE Signal Processing Letters, 31: 989–993, 2024. 3, 6, 8
work page 2024
-
[37]
Xiangchao Meng, Yiming Xiong, Feng Shao, Huanfeng Shen, Weiwei Sun, Gang Yang, Qiangqiang Yuan, Randi Fu, and Hongyan Zhang. A Large-Scale Benchmark Data Set for Evaluating Pansharpening Performance: Overview and Imple- mentation.IEEE Geoscience and Remote Sensing Magazine,
-
[38]
Sofiane Mihoubi, Olivier Losson, Benjamin Mathon, and Ludovic Macaire. Multispectral Demosaicing Using Pseudo- Panchromatic Image.IEEE Transactions on Computational Imaging, 3(4):982–995, 2017. 2, 6, 8
work page 2017
-
[39]
Charles Millard and Mark Chiew. Clean self-supervised MRI reconstruction from noisy, sub-sampled training data with Robust SSDU, 2024. arXiv:2210.01696 [eess]. 2, 3
-
[40]
General- ized Recorrupted-to-Recorrupted: Self-Supervised Learning Beyond Gaussian Noise
Brayan Monroy, Jorge Bacca, and Julián Tachella. General- ized Recorrupted-to-Recorrupted: Self-Supervised Learning Beyond Gaussian Noise. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28155–28164, 2025. 2, 3, 4
work page 2025
-
[41]
Yunjin Park, Sukho Lee, Byeongseon Jeong, and Jungho Yoon. Joint Demosaicing and Denoising Based on a Varia- tional Deep Image Prior Neural Network.Sensors, 20(10): 2970, 2020. 3, 6
work page 2020
-
[42]
U-Net: Convolutional Networks for Biomedical Image Segmenta- tion
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmenta- tion. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, 2015. 3
work page 2015
-
[43]
Self-Supervised Learning for Image Super- Resolution and Deblurring, 2023
Jérémy Scanvic, Mike Davies, Patrice Abry, and Julián Tachella. Self-Supervised Learning for Image Super- Resolution and Deblurring, 2023. arXiv:2312.11232 [cs, eess]. 3, 4
-
[44]
Charles M. Stein. Estimation of the Mean of a Multivariate Normal Distribution.The Annals of Statistics, 9(6):1135– 1151, 1981. 3
work page 1981
-
[45]
UN- SURE: self-supervised learning with Unknown Noise level and Stein’s Unbiased Risk Estimate, 2025
Julián Tachella, Mike Davies, and Laurent Jacques. UN- SURE: self-supervised learning with Unknown Noise level and Stein’s Unbiased Risk Estimate, 2025. arXiv:2409.01985 [stat]. 2, 4
-
[46]
Liaudat, Maxime Song, Johannes Hertrich, Sebastian Neu- mayer, and Georg Schramm
Julián Tachella, Matthieu Terris, Samuel Hurault, Andrew Wang, Leo Davy, Jérémy Scanvic, Victor Sechaud, Romain V o, Thomas Moreau, Thomas Davies, Dongdong Chen, Nils Laurent, Brayan Monroy, Jonathan Dong, Zhiyuan Hu, Minh- Hai Nguyen, Florian Sarron, Pierre Weiss, Paul Escande, Mathurin Massias, Thibaut Modrzyk, Brett Levac, Tobías I. Liaudat, Maxime Son...
work page 2025
-
[47]
Reconstruct Anything Model: a lightweight foundation model for computational imaging,
Matthieu Terris, Samuel Hurault, Maxime Song, and Julian Tachella. Reconstruct Anything Model: a lightweight foundation model for computational imaging,
- [48]
-
[49]
Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Deep Image Prior. InProceedings of the IEEE Conference on 10 Computer Vision and Pattern Recognition, pages 9446–9454,
-
[50]
Licciardi, Rocco Restaino, and Lucien Wald
Gemine Vivone, Luciano Alparone, Jocelyn Chanussot, Mauro Dalla Mura, Andrea Garzelli, Giorgio A. Licciardi, Rocco Restaino, and Lucien Wald. A Critical Comparison Among Pansharpening Algorithms.IEEE Transactions on Geoscience and Remote Sensing, 53(5):2565–2586, 2015. 6
work page 2015
-
[51]
Perspective-Equivariance for Unsupervised Imaging with Camera Geometry, 2024
Andrew Wang and Mike Davies. Perspective-Equivariance for Unsupervised Imaging with Camera Geometry, 2024. arXiv:2403.09327 [cs, eess]. 2, 3, 4
-
[52]
Bench- marking Self-Supervised Learning Methods for Accelerated MRI Reconstruction, 2025
Andrew Wang, Steven McDonagh, and Mike Davies. Bench- marking Self-Supervised Learning Methods for Accelerated MRI Reconstruction, 2025. arXiv:2502.14009 [eess]. 2
-
[53]
HyKo: A Spectral Dataset for Scene Understand- ing
Christian Winkens, Florian Sattler, Veronika Adams, and Diet- rich Paulus. HyKo: A Spectral Dataset for Scene Understand- ing. In2017 IEEE International Conference on Computer Vision Workshops (ICCVW), pages 254–261, 2017. 2, 6, 7, 8, 1
work page 2017
-
[54]
xiSpec2 hyperspectral imaging camera series techni- cal documentation
Ximec. xiSpec2 hyperspectral imaging camera series techni- cal documentation. Technical report, Ximea, 2021. 6
work page 2021
-
[55]
W. Yu. Colour demosaicking method using adaptive cubic convolution interpolation with sequential averaging.IEE Proceedings - Vision, Image and Signal Processing, 153(5): 666–676, 2006. 2
work page 2006
-
[56]
Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising.IEEE Transactions on Image Processing, 26(7):3142–3155, 2017. 2, 6
work page 2017
-
[57]
Kai Zhang, Yawei Li, Wangmeng Zuo, Lei Zhang, Luc Van Gool, and Radu Timofte. Plug-and-Play Image Restora- tion With Deep Denoiser Prior.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):6360–6376, 2022. 3
work page 2022
-
[58]
PIDSR: Complementary Polarized Image Demosaicing and Super-Resolution
Shuangfan Zhou, Chu Zhou, Youwei Lyu, Heng Guo, Zhanyu Ma, Boxin Shi, and Imari Sato. PIDSR: Complementary Polarized Image Demosaicing and Super-Resolution. In 2025 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 16081–16090, 2025. ISSN: 2575-7075. 2 11 Perspective-Equivariant Fine-tuning for Multispectral Demosaicing withou...
work page 2025
-
[59]
Ablation analysis results We present the quantitative and qualitative results of the ablation analysis in Tab. 2 and Fig. 8. We refer the reader to the main paper Sec. 4.3 for discussion. Table 2. Ablation study on the HELICoiD [14] and HyKo [52] datasets. Best self-supervised result inbold. (a) HELICoiD dataset. Method PSNR↑SSIM↑SAM↓ERGAS↓ RAM zero-shot ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.