ECHO: Event-Centric Hypergraph Operations via Multi-Agent Collaboration for Multimedia Event Extraction
Pith reviewed 2026-05-15 17:19 UTC · model grok-4.3
The pith
ECHO reframes multimedia event extraction as explicit operations on a shared hypergraph using multi-agent collaboration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
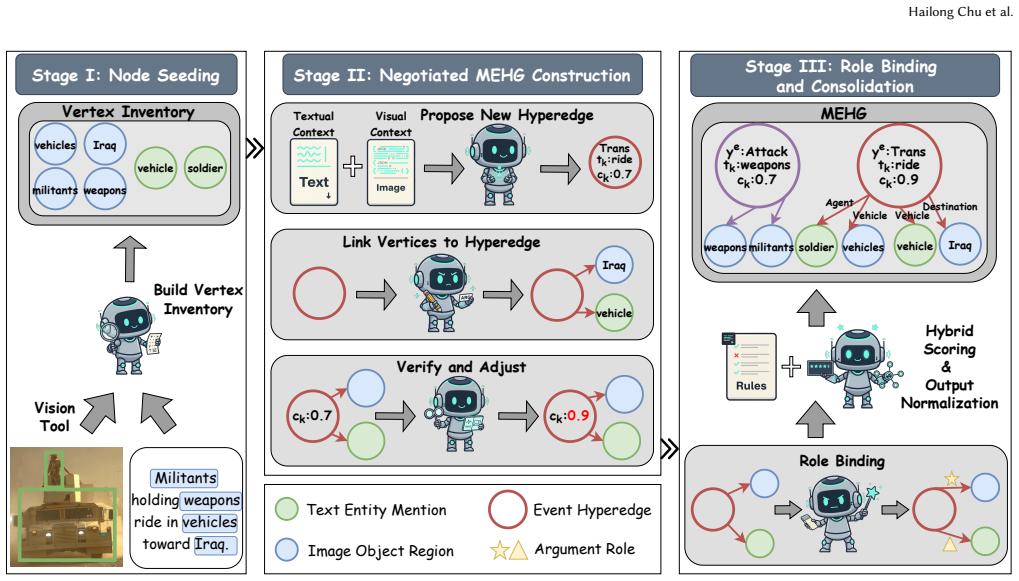
ECHO treats multimedia event extraction as iterative refinement over an explicit Multimedia Event Hypergraph (MEHG) via multi-agent collaboration, replacing implicit linear generation with auditable atomic updates; a Link-then-Bind strategy decouples event-argument linking from role binding to avoid premature semantic commitments.
What carries the argument
The Multimedia Event Hypergraph (MEHG), an explicit shared structure that records events, arguments, and relations so agents can perform revisable atomic operations instead of generating opaque text sequences.
If this is right
- Event mention detection improves by 7.3 F1 points over prior state-of-the-art.
- Argument role labeling improves by 15.5 F1 points over prior state-of-the-art.
- Intermediate event hypotheses become inspectable and correctable during inference.
- Predictions remain schema-consistent while allowing revision before final output.
Where Pith is reading between the lines
- The same hypergraph-plus-agent pattern could be tested on other structured prediction tasks that currently rely on end-to-end text generation.
- If coordination overhead stays low, the framework might scale to larger numbers of modalities or longer documents without proportional increases in model size.
- Decoupling linking from binding may generalize to other domains where premature commitment causes cascading errors.
Load-bearing premise
The explicit hypergraph representation and the Link-then-Bind decoupling will reduce error propagation from early mistakes without creating new failure modes from multi-agent coordination.
What would settle it
A controlled test that injects early-stage errors into the pipeline and measures whether ECHO's reported F1 gains on event mention and argument role disappear or reverse compared with baseline methods.
Figures




read the original abstract
Multimedia event extraction (M2E2) aims to predict triggers, ground arguments across text and images, and then assemble them into schema-consistent event records. Recent LLM-based approaches have shown strong potential for M2E2, but their intermediate event hypotheses often remain implicit, and event-argument linking is still tightly coupled with role binding. This leaves little opportunity to inspect or revise intermediate event hypotheses and makes predictions brittle to early errors. To bridge this gap, we present ECHO, a multi-agent framework that reframes M2E2 as iterative refinement over an explicit Multimedia Event Hypergraph (MEHG). Instead of relying on implicit linear generation, ECHO performs auditable atomic updates over a shared hypergraph, making intermediate event structures explicit and revisable. Furthermore, we introduce a Link-then-Bind strategy that decouples event-argument linking from role binding, reducing premature semantic commitment during structured prediction. Extensive experiments on the M2E2 benchmark show that ECHO consistently outperforms prior state-of-the-art approaches, achieving gains of 7.3 and 15.5 F1 points on event mention and argument role, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ECHO, a multi-agent framework for multimedia event extraction (M2E2) that reframes the task as iterative refinement over an explicit Multimedia Event Hypergraph (MEHG). It proposes a Link-then-Bind strategy to decouple event-argument linking from role binding, aiming to make intermediate event structures explicit and revisable, thereby reducing brittleness to early errors in LLM-based approaches. The central claim is that ECHO outperforms prior state-of-the-art methods on the M2E2 benchmark, with reported gains of 7.3 F1 points on event mention detection and 15.5 F1 points on argument role labeling.
Significance. If the reported performance gains hold under rigorous evaluation, this work could significantly impact the field by providing a more auditable and modular approach to structured multimedia event extraction, potentially improving robustness and interpretability in multi-modal NLP tasks.
major comments (2)
- [Experimental Evaluation] The abstract reports benchmark gains of 7.3 and 15.5 F1 points but supplies no experimental details, baselines, statistical tests, or error analysis. This makes it impossible to assess support for the central claim of consistent outperformance.
- [Link-then-Bind Strategy] The Link-then-Bind decoupling is claimed to reduce premature semantic commitment, but no ablation or analysis is provided to demonstrate that the multi-agent coordination does not introduce new failure modes, which is load-bearing for the robustness argument.
minor comments (1)
- [Method] The definition and operations on the Multimedia Event Hypergraph (MEHG) would benefit from a more formal mathematical specification, including explicit notation for hyperedges and update rules.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and positive assessment of the potential impact of our work. We address each major comment below and plan to revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Experimental Evaluation] The abstract reports benchmark gains of 7.3 and 15.5 F1 points but supplies no experimental details, baselines, statistical tests, or error analysis. This makes it impossible to assess support for the central claim of consistent outperformance.
Authors: We appreciate this observation. The detailed experimental setup, including all baselines (e.g., prior SOTA methods on M2E2), statistical significance tests, and error analysis, are provided in Section 4 of the manuscript. To make this more accessible, we will revise the abstract to briefly summarize the evaluation methodology and key results with references to the full details in the paper. revision: yes
-
Referee: [Link-then-Bind Strategy] The Link-then-Bind decoupling is claimed to reduce premature semantic commitment, but no ablation or analysis is provided to demonstrate that the multi-agent coordination does not introduce new failure modes, which is load-bearing for the robustness argument.
Authors: We agree that an ablation study is necessary to validate the Link-then-Bind strategy and to show that the multi-agent setup does not introduce additional failure modes. In the revised version, we will add comprehensive ablations comparing the decoupled approach to a joint Link-and-Bind baseline, along with an analysis of coordination failures and how the iterative refinement mitigates them. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces the ECHO multi-agent framework for M2E2, reframing the task as iterative refinement over an explicit Multimedia Event Hypergraph with a Link-then-Bind strategy. All central claims rest on empirical benchmark results (7.3 and 15.5 F1 gains on M2E2) rather than any derivation, equation, or prediction that reduces by construction to fitted inputs, self-citations, or renamed ansatzes. No load-bearing step matches the enumerated circularity patterns; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based M2E2 methods suffer from implicit hypotheses and coupled linking-role binding that cause brittle predictions
invented entities (1)
-
Multimedia Event Hypergraph (MEHG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
ECHO performs auditable atomic updates over a shared hypergraph... Link-then-Bind strategy that decouples event-argument linking from role binding
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iterative refinement over an explicit Multimedia Event Hypergraph (MEHG)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mahdi Abavisani, Liwei Wu, Shengli Hu, Joel Tetreault, and Alejandro Jaimes. 2020. Multimodal Categorization of Crisis Events in Social Media. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, Washington, USA, 14679–14689. https: //openaccess.thecvf.com/content_CVPR_2020/html/Abavisani_Multimodal_ C...
work page 2020
-
[2]
Firoj Alam, Ferda Ofli, and Muhammad Imran. 2018. CrisisMMD: Multimodal Twitter Datasets from Natural Disasters. InProceedings of the Twelfth Interna- tional AAAI Conference on Web and Social Media. AAAI Press, Stanford, California, USA, 465–473. https://ojs.aaai.org/index.php/ICWSM/article/view/14983
work page 2018
-
[3]
Jianwei Cao, Yanli Hu, Zhen Tan, and Xiang Zhao. 2025. Cross-modal Multi-task Learning for Multimedia Event Extraction. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 11454–11462. doi:10.1609/aaai.v39i11.33246
-
[4]
Justin Chen, Swarnadeep Saha, and Mohit Bansal. 2024. ReConcile: Round- Table Conference Improves Reasoning via Consensus among Diverse LLMs. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 7066–7085. doi:10.18653/v1/2024.acl-long.381
-
[5]
Zilin Du, Yunxin Li, Xu Guo, Yidan Sun, and Boyang Li. 2023. Training Multime- dia Event Extraction With Generated Images and Captions. InProceedings of the 31st ACM International Conference on Multimedia. Association for Computing Machinery, Ottawa, ON, Canada, 5504–5513. doi:10.1145/3581783.3612526
-
[6]
Simon Gottschalk and Elena Demidova. 2018. EventKG: A Multilingual Event- Centric Temporal Knowledge Graph. InThe Semantic Web: 15th International Conference, ESWC 2018. Springer, Heraklion, Crete, Greece, 272–287. doi:10.1007/ 978-3-319-93417-4_18
work page 2018
-
[7]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber
-
[8]
InThe Twelfth International Conference on Learning Representations (ICLR 2024)
MetaGPT: Meta Programming for A Multi-Agent Collaborative Frame- work. InThe Twelfth International Conference on Learning Representations (ICLR 2024). OpenReview.net, Vienna, Austria. https://openreview.net/forum?id= VtmBAGCN7o
work page 2024
-
[9]
Jinhao Jiang, Kun Zhou, Wayne Xin Zhao, Yang Song, Chen Zhu, Hengshu Zhu, and Ji-Rong Wen. 2025. KG-Agent: An Efficient Autonomous Agent Framework for Complex Reasoning over Knowledge Graph. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, a...
work page 2025
-
[10]
doi:10.18653/v1/2025.acl-long.468
-
[11]
Shichao Jiao, Zonghan Wei, Xuzhen Lin, Yongsheng Yu, and Jing Jiang. 2024. Text2DB: Integrating Instruction Fine-Tuning and Database Updating for Text-to- Database Learning. InFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, Bangkok, Thailand. doi:10. 18653/v1/2024.findings-acl.12
work page 2024
-
[12]
Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, San Diego, Califor...
work page 2016
-
[13]
Hongbing Li, Bo Xiao, Linyi Yang, Xinran Wang, and Qi Li. 2025. Multi-Grained Alignment for Visual Grounding. In2025 IEEE International Conference on Multi- media and Expo (ICME). IEEE, 1–6
work page 2025
-
[14]
Hongbing Li, Linhui Xiao, Zihan Zhao, Qi Shen, Yixiang Huang, Bo Xiao, and Zhanyu Ma. 2026. BARE: Towards Bias-Aware and Reasoning-Enhanced One- Tower Visual Grounding.IEEE Transactions on Circuits and Systems for Video Technology(2026), 1–1. doi:10.1109/TCSVT.2026.3679114
-
[15]
Manling Li, Ruochen Xu, Shuohang Wang, Luowei Zhou, Xudong Lin, Chen- guang Zhu, Michael Zeng, Heng Ji, and Shih-Fu Chang. 2022. CLIP-Event: Con- necting Text and Images with Event Structures. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE/CVF, 16420– 16429. doi:10.1109/CVPR52688.2022.01593
-
[16]
Manling Li, Alireza Zareian, Qi Zeng, Spencer Whitehead, Di Lu, Heng Ji, and Shih-Fu Chang. 2020. Cross-media Structured Common Space for Multimedia Event Extraction. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online, 2559–2570. doi:10.18653/v1/2020.acl-main.230
-
[17]
Weixin Liang, Wen Wang, Zhi Jin, Lizhou Wang, Xinyu Luo, and Percy Liang
-
[18]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.-N
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, Florida, 17837–17857. doi:10.18653/v1/2024.emnlp-main.992
-
[19]
Ying Lin, Heng Ji, Fei Huang, and Lingfei Wu. 2020. A Joint Neural Model for Information Extraction with Global Features. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 7999–8009. doi:10.1865...
-
[20]
Jian Liu, Yufeng Chen, and Jinan Xu. 2022. Multimedia Event Extraction From News With a Unified Contrastive Learning Framework. InProceedings of the 30th ACM International Conference on Multimedia. Association for Computing Machinery, Lisboa, Portugal, 1945–1953. doi:10.1145/3503161.3548132
-
[21]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Bhargavi Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
-
[22]
Yang Liu, Fang Liu, Licheng Jiao, Qianyue Bao, Long Sun, Shuo Li, Lingling Li, and Xu Liu. 2024. Multi-Grained Gradual Inference Model for Multimedia Event Extraction.IEEE Transactions on Circuits and Systems for Video Technology34, 10 (2024), 10507–10520. doi:10.1109/TCSVT.2024.3402242
-
[23]
Meng Lu, Yuzhang Xie, Zhenyu Bi, Shuxiang Cao, and Xuan Wang. 2025. CROSSAGENTIE: Cross-Type and Cross-Task Multi-Agent LLM Collaboration for Zero-Shot Information Extraction. InFindings of the Association for Computa- tional Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computat...
-
[24]
Aman Madaan, Shuyuan Yu, Aidan O’Brien, Shaurya Garg, Suresh Kumar, Yun- feng Bai, Dan Friedman, Aaron Chan, Yuandong Tian, and Annie Zhang. 2023. Self-Refine: Iterative Refinement with Self-Feedback. InAdvances in Neural In- formation Processing Systems. https://proceedings.neurips.cc/paper_files/paper/ 2023/hash/91edff07232fb1b55a505a9e9f6c0ff3-Abstract...
work page 2023
-
[25]
Eric Müller-Budack, Jonas Theiner, Sebastian Diering, Maximilian Idahl, Sherzod Hakimov, and Ralph Ewerth. 2021. Multimodal News Analytics Using Measures of Cross-Modal Entity and Context Consistency.International Journal of Multimedia Information Retrieval10, 2 (2021), 111–125. doi:10.1007/s13735-021-00207-4
-
[26]
Bangze Pan, Yang Li, Suge Wang, Xiaoli Li, Deyu Li, Jian Liao, and Jianxing Zheng. 2024. Document-Level Event Extraction via Information Interaction Based on Event Relation and Argument Correlation. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Nicoletta Calzola...
work page 2024
-
[27]
O'Brien and Carrie Jun Cai and Meredith Ringel Morris and Percy Liang and Michael S
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. Association for Computing Machinery. doi:10.1145/3586183.3606763
-
[28]
Philipp Seeberger, Dominik Wagner, and Korbinian Riedhammer. 2024. MMUTF: Multimodal Multimedia Event Argument Extraction with Unified Template Fill- ing. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 6539–65...
-
[29]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Re- inforcement Learning. InAdvances in Neural Information Processing Systems. https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1b44b878bb782e6954cd888628510e90-Abstract-Conference.html
work page 2023
-
[30]
Lin Sun, Kai Zhang, Qingyuan Li, and Renze Lou. 2024. UMIE: Unified Multi- modal Information Extraction with Instruction Tuning. InThirty-Eighth AAAI Conference on Artificial Intelligence (AAAI 2024). AAAI Press, 19062–19070. doi:10.1609/AAAI.V38I17.29873
-
[31]
Nikos Voskarides, Edgar Meij, Sabrina Sauer, and Maarten de Rijke. 2022. News Article Retrieval in Context for Event-Centric Narrative Creation. InProceedings of the First Workshop on Intelligent and Interactive Writing Assistants (In2Writing 2022). Association for Computational Linguistics, Dublin, Ireland, 85–91. doi:10. 18653/v1/2022.in2writing-1.10
work page 2022
-
[32]
David Wadden, Ulme Wennberg, Yi Luan, and Hannaneh Hajishirzi. 2019. Entity, Relation, and Event Extraction with Contextualized Span Representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang,...
-
[33]
Xiaoyu Wang, Tao Sun, Gengchen Liu, Zhi Yang, Jiahui Liu, and Zimeng Xu. 2025. MGFSG-EE: A Method based on Multi-grained Fusion and Scene Graph Enhance- ment for Event Extraction(CIKM ’25). Association for Computing Machinery, New York, NY, USA, 3103–3112. doi:10.1145/3746252.3761235
-
[34]
Zheng Wang, Zhongyang Li, Zeren Jiang, Dandan Tu, and Wei Shi. 2024. Craft- ing Personalized Agents through Retrieval-Augmented Generation on Editable Memory Graphs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, ...
-
[35]
Zhen Wang, Xu Shan, Xiangxie Zhang, and Jie Yang. 2022. N24News: A New Dataset for Multimodal News Classification. InProceedings of the Thirteenth Language Resources and Evaluation Conference. European Language Resources Association, Marseille, France, 6793–6800. https://aclanthology.org/2022.lrec- 1.729/
work page 2022
-
[36]
Yilin Wen, Zifeng Wang, and Jimeng Sun. 2024. MindMap: Knowledge Graph Prompting Sparks Graph of Thoughts in Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thai...
-
[37]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. InICLR 2024 Workshop on LLM Agents (LLMAgents). https://openreview.net/forum?id=uAjxFFing2
work page 2024
-
[38]
Runxin Xu, Tianyu Liu, Lei Li, and Baobao Chang. 2021. Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Pro- cessing (Volume 1: Long Papers), Chengqing Zong...
-
[39]
Ting Xu, Haiqin Yang, Fei Zhao, Zhen Wu, and Xinyu Dai. 2024. A Two-Agent Game for Zero-shot Relation Triplet Extraction. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 7510–7527. doi:10.18653/v1/2024.findings-acl.446
-
[40]
Vikas Yadav and Steven Bethard. 2018. A Survey on Recent Advances in Named Entity Recognition from Deep Learning Models. InProceedings of the 27th International Conference on Computational Linguistics. Association for Computational Linguistics, Santa Fe, New Mexico, USA, 2145–2158. https: //aclanthology.org/C18-1182/
work page 2018
-
[41]
Zhaohui Yan, Songlin Yang, Wei Liu, and Kewei Tu. 2023. Joint Entity and Relation Extraction with Span Pruning and Hypergraph Neural Networks. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 7512–7526. doi:10.18...
-
[42]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: deliberate problem solving with large language models. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’23). Curran Associates Inc., Red Hook, NY, USA, Artic...
work page 2023
-
[43]
Huiling You, Lilja Vrelid, and Samia Touileb. 2023. JSEEGraph: Joint Structured Event Extraction as Graph Parsing. InProceedings of the 12th Joint Conference on Lexical and Computational Semantics (*SEM 2023), Alexis Palmer and Jose Camacho-collados (Eds.). Association for Computational Linguistics, Toronto, Canada, 115–127. doi:10.18653/v1/2023.starsem-1.11
-
[44]
Jiaao Yu, Yijing Lin, Zhipeng Gao, Xuesong Qiu, and Lanlan Rui. 2025. Mul- timedia Event Extraction with LLM Knowledge Editing. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Chris- tos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou,...
-
[45]
Li Yuan, Yi Cai, Xudong Shen, Qing Li, Qingbao Huang, Zikun Deng, and Tao Wang. 2025. Collaborative Multi-LoRA Experts with Achievement-based Multi- Tasks Loss for Unified Multimodal Information Extraction. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI- 25, James Kwok (Ed.). International Joint Confere...
-
[46]
Xiang Yuan, Xinrong Chen, Haochen Li, Hang Yang, Guanyu Wang, Weiping Li, and Tong Mo. 2025. Stepwise Schema-Guided Prompting Framework with Parameter Efficient Instruction Tuning for Multimedia Event Extraction. In 2025 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6. doi:10.1109/icme59968.2025.11210082
-
[47]
Tengda Zhou, Shaoyang Men, Jingxian Liang, Baoxian Yu, Han Zhang, and Xiaomu Luo
Shuo Zhang, Jinsong Zhang, Zhejun Zhang, and Lei Li. 2025. Multimodal Mixture of Low-Rank Experts for Sentiment Analysis and Emotion Recognition. In2025 IEEE International Conference on Multimedia and Expo (ICME). 1–6. doi:10.1109/ ICME59968.2025.11210197 ECHO: Event-Centric Hypergraph Operations via Multi-Agent Collaboration for Multimedia Event Extracti...
-
[48]
**JSON Format**: Output valid JSON only, matching exactly: {output_example}
-
[49]
* Image inputs: Trigger must be a **single-word** visual descriptor (or`""`if not applicable)
**Trigger Constraints**: * Text inputs: Trigger must be **one token**, copied verbatim from the text. * Image inputs: Trigger must be a **single-word** visual descriptor (or`""`if not applicable). # Extraction Rules
-
[50]
**Evidence Discipline**: Output only events/ arguments directly supported by the provided evidence (no speculation)
-
[51]
**Role Fidelity**: Use the exact role names defined in the schema
-
[52]
# Visual Grounding & Bounding Box Discipline
**Argument Salience**: Include only the most salient arguments for each event. # Visual Grounding & Bounding Box Discipline
-
[53]
**Format**: Bounding boxes are integers`[x_min, y_min, x_max, y_max]`
-
[54]
**Requirement**: Every entry in`image_arguments` must include a grounded bounding box
-
[55]
Direct Prompting (LVLM + Image + Visual Tool Outputs)
**Instances/Groups**: Use separate boxes for distinct instances; otherwise use one tight box covering the group. Direct Prompting (LVLM + Image + Visual Tool Outputs). LVLM baselines process the raw image 𝐼 alongside the text 𝑇 . Cru- cially, to maintain a strictly controlled comparison, they are addi- tionally provided with the exact same vision tool out...
-
[56]
The output must exactly match: {output_example}
**JSON Format**: Respond with valid JSON only. The output must exactly match: {output_example}
-
[57]
**Trigger Constraints**: * When text is provided: Trigger must be a **single token** copied verbatim from the text. # Extraction Rules
-
[58]
**Evidence Discipline**: Emit only events/arguments directly supported by text or pixels (no speculation)
-
[59]
# Visual Grounding Constraints
**Role Fidelity**: Use the exact role names defined in the schema. # Visual Grounding Constraints
-
[60]
**Bounding Boxes**: Every entry in`image_arguments` must include a grounded integer box `[x_min, y_min, x_max, y_max]`
-
[61]
**Optional Object Name**:`object_name`may be included as an auxiliary descriptive field for readability. ECHO: Event-Centric Hypergraph Operations via Multi-Agent Collaboration for Multimedia Event Extraction ECHO.These prompts define each agent’s role, available multi- modal evidence, and the structured atomic operation format. Node Seeding # Task You ar...
-
[62]
* Assign unique IDs prefixed with`T`(e.g., T1, T2)
**Text Entities** (`text_entities`): * Extract concrete entity mentions that may serve as event arguments. * Assign unique IDs prefixed with`T`(e.g., T1, T2)
-
[63]
* Assign unique IDs prefixed with`O`(e.g., O1, O2)
**Visual Objects** (`image_objects`): * Extract concrete objects from the visual description that may serve as event arguments. * Assign unique IDs prefixed with`O`(e.g., O1, O2). Proposer # Task Act as an Event Hypothesis Proposer. Use the multimodal context and the current hypergraph state to propose new event hyperedges or signal convergence. # Context...
-
[64]
**Evidence Constraint**: Propose only events directly supported by the provided evidence
-
[65]
* Image-Only Mode: Use`""`or a concise visual descriptor
**Trigger Selection**: * Text Mode: Choose a **single token** copied verbatim from the source text. * Image-Only Mode: Use`""`or a concise visual descriptor
-
[66]
**State/History Awareness**: Do not propose events already in`<Current hypergraph>`or rejected in `<History>`. # Operations Output a JSON object`{"operations": [...]}`containing one of:
- [67]
-
[68]
**`no_op`**: Return when no new valid event remains. ```json {"operation": "no_op", "reason": "Converged"} ``` Linker # Task Act as a Node-Hyperedge Linker. Link or unlink candidate nodes to each event hyperedge based on explicit evidence, without assigning roles. # Context Data <Source sentence> {text_input} </Source> <Current hypergraph> {hypergraph} </...
-
[69]
**Evidence-Based Linking**: Link nodes only when there is clear textual or visual support; avoid weak/background associations
-
[70]
**Cross-Modal Consistency**: Prefer links that are mutually supported or non-contradictory across modalities. # Operations Output a JSON object`{"operations": [...]}`containing:
- [71]
- [72]
-
[73]
# Constraints * **History**: Do not repeat operations already recorded in`<History>`
**`no_op`**: Return when links are sufficient. # Constraints * **History**: Do not repeat operations already recorded in`<History>`. Verifier # Task Act as a Cross-Modal Verifier. Verify coherence between text and image evidence, calibrate hyperedge confidence, and prune invalid or redundant hyperedges. # Context Data <Source sentence> {text_input} </Sour...
-
[74]
**Cross-Modal Consistency**: Identify direct contradictions between modalities; only prune when a contradiction or clear invalidity is observed
-
[75]
**Confidence Calibration**: Adjust confidence based on the strength of supporting evidence across modalities
-
[76]
**Pruning**: Drop hyperedges that are empty, duplicated, or unsupported/hallucinated. # Operations Output a JSON object`{"operations": [...]}`containing:
- [77]
- [78]
-
[79]
# Constraints * **History**: Do not repeat operations already recorded in`<History>`
**`no_op`**: Return if no changes are needed. # Constraints * **History**: Do not repeat operations already recorded in`<History>`. Role Bind (textual vertices).The prompt below is used for textual role binding. Visual role candidates are obtained from the vision tool conditioned on the event hypothesis and then aligned to linked visual vertices by locali...
-
[80]
Use`Entity`only as a fallback for ambiguous participants
**Specificity Principle**: Always prioritize specific roles (e.g.,`Attacker`,`Target`) over the generic`Entity`role. Use`Entity`only as a fallback for ambiguous participants
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.