Recognition: unknown
On the Nature of Attention Sink that Shapes Decoding Strategy in Omni-LLMs
Pith reviewed 2026-05-15 11:36 UTC · model grok-4.3
The pith
The sink value vector acts as a shared bias added to every token output and organizes representations in Omni-LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
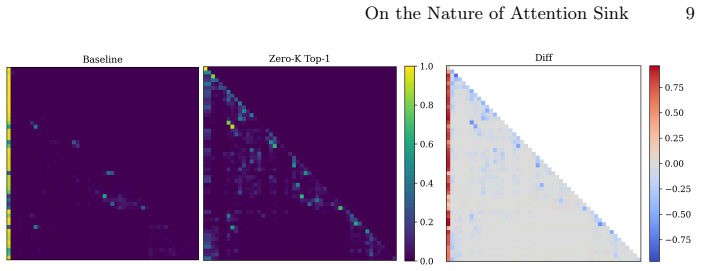
The sink value vector acts as a shared bias added to every token's output, serving as a global signal that organises the representation as a whole. Systematic analysis shows high sink attention is not simply a marker of redundant heads; instead the sink value supplies a functional bias that shapes decoding strategy across modalities.
What carries the argument
The sink value vector, which functions as a shared additive bias to every token output and thereby organises the overall representation space.
If this is right
- Aligning non-sink token representations with the sink in feature space sharpens the global bias signal used by the decoder.
- Relaxing the causal mask on sink tokens at an early layer lets the shared bias form before later layers proceed.
- These edits raise accuracy on seven video QA benchmarks while keeping decoding overhead to 1.1 times normal.
- The method works without access to attention maps or any additional forward passes.
Where Pith is reading between the lines
- The same sink-bias alignment might be tried in text-only LLMs to check whether the organizing effect holds outside multimodal settings.
- Combining the early-layer mask relaxation with other inference edits such as logit scaling could produce further gains.
- If the shared bias proves general, it could be used to stabilize decoding in long-context or high-token-count regimes beyond the paper's video QA focus.
Load-bearing premise
The observed sink bias is causally responsible for better reasoning and that aligning non-sink tokens to it will improve rather than disrupt decoding across modalities.
What would settle it
An experiment that forces non-sink token representations away from the sink value vector and measures whether video QA accuracy drops would test whether the bias is causally helpful.
Figures






read the original abstract
The goal of this paper is to strengthen the reasoning of Omnimodal Large Language Models (Omni-LLMs) at inference time, without additional training. These models jointly process video, audio, and text, and given the large number of tokens they consume, how attention is routed across them is central to their behaviour. We focus specifically on attention sinks, tokens that absorb a disproportionate share of attention mass regardless of their semantic content, to understand how this routing unfolds. To this end, we conduct a systematic analysis of sink behaviour in Omni-LLMs. Our analysis yields two key findings: (i) high sink attention does not solely indicate head redundancy, suggesting that sink value representations play additional functional roles; (ii) the sink value vector acts as a shared bias added to every token's output, serving as a global signal that organises the representation as a whole. Building on this, we propose OutRo, which correspondingly aligns non-sink token representations with the sink in feature space, and relaxes the causal mask for sink tokens at an early layer to sharpen this bias before the rest of decoding proceeds. This design enhances the reasoning process without requiring additional forward passes or access to attention maps. Based on extensive experiments, OutRo consistently improves performance on seven video QA benchmarks and demonstrates strong generalisation, while incurring only a 1.1x decoding overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes attention sink behavior in Omni-LLMs, finding that high sink attention is not merely redundancy and that the sink value vector functions as a shared bias added to every token output to organize representations globally. It proposes OutRo, which aligns non-sink token features to this sink bias and relaxes the causal mask on sink tokens at an early layer, yielding consistent gains on seven video QA benchmarks at 1.1x decoding cost without training or extra forward passes.
Significance. If validated, the work provides a practical, training-free intervention for improving reasoning in omnimodal models by leveraging an intrinsic attention property. The systematic sink analysis and benchmark improvements across video QA tasks represent a concrete contribution to understanding and steering decoding strategies in large multimodal models.
major comments (3)
- [§4] §4 (OutRo): The method jointly applies non-sink alignment to the sink value vector and early-layer causal-mask relaxation on sink tokens. No ablation isolating alignment alone or mask relaxation alone is reported, so the performance gains on the seven benchmarks cannot be unambiguously attributed to the claimed sink-bias mechanism rather than the mask change.
- [§3] §3 (Sink Analysis): The assertion that the sink value vector 'acts as a shared bias added to every token's output' is supported by attention-pattern observations but lacks explicit controls (e.g., counterfactual interventions or representation-distance measurements) that would isolate this bias effect from other multimodal token interactions.
- [§5] §5 (Experiments): Results on the seven video QA benchmarks are presented without reported statistical significance tests, variance across runs, or baselines that hold the mask fixed while varying only the alignment component, weakening the causal link between the proposed bias alignment and the observed reasoning improvements.
minor comments (2)
- [§3] Notation for the sink value vector and its addition to token outputs should be introduced with an explicit equation in §3 to improve clarity.
- Figure captions could more explicitly state which layers and heads are visualized to aid reproducibility of the sink-pattern observations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the empirical support for our claims regarding the sink bias mechanism and OutRo method.
read point-by-point responses
-
Referee: [§4] §4 (OutRo): The method jointly applies non-sink alignment to the sink value vector and early-layer causal-mask relaxation on sink tokens. No ablation isolating alignment alone or mask relaxation alone is reported, so the performance gains on the seven benchmarks cannot be unambiguously attributed to the claimed sink-bias mechanism rather than the mask change.
Authors: We agree that separate ablations would help isolate the contributions. In the revised manuscript, we will report results for alignment alone (with standard causal masking) and mask relaxation alone (without alignment), allowing clearer attribution of gains to the sink-bias alignment. revision: yes
-
Referee: [§3] §3 (Sink Analysis): The assertion that the sink value vector 'acts as a shared bias added to every token's output' is supported by attention-pattern observations but lacks explicit controls (e.g., counterfactual interventions or representation-distance measurements) that would isolate this bias effect from other multimodal token interactions.
Authors: Our analysis relies on consistent attention patterns observed across models and tasks. To address the request for explicit controls, we will include additional representation-distance measurements (e.g., cosine similarity between sink value vectors and non-sink token outputs) in the revised §3 to quantify the bias effect. revision: yes
-
Referee: [§5] §5 (Experiments): Results on the seven video QA benchmarks are presented without reported statistical significance tests, variance across runs, or baselines that hold the mask fixed while varying only the alignment component, weakening the causal link between the proposed bias alignment and the observed reasoning improvements.
Authors: We will update the experimental section to include multiple runs with different random seeds, reporting mean performance and standard deviation, along with statistical significance tests (e.g., paired t-tests). We will also add baselines that apply only the alignment while keeping the causal mask unchanged to isolate its effect. revision: yes
Circularity Check
No circularity: empirical observations and independent validation
full rationale
The paper conducts a systematic empirical analysis of attention sink behavior in Omni-LLMs, derives two key findings from direct observation of attention patterns and value representations, and proposes the OutRo method as a heuristic motivated by those findings. The central claims about the sink value vector as a shared bias are grounded in data inspection rather than any self-definitional loop, fitted parameter renamed as prediction, or self-citation chain. OutRo is then tested on external video QA benchmarks with reported performance gains, keeping the derivation self-contained and falsifiable outside its own inputs. No load-bearing step reduces by construction to the paper's own definitions or prior self-references.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard self-attention computation in decoder-only transformer models
Forward citations
Cited by 1 Pith paper
-
SinkRouter: Sink-Aware Routing for Efficient Long-Context Decoding in Large Language and Multimodal Models
SinkRouter identifies attention sinks as training-derived fixed points and routes around them to skip redundant KV-cache loads, delivering up to 2.03x decoding speedup on long-context benchmarks.
Reference graph
Works this paper leans on
-
[1]
arXiv (2023)
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv (2023)
2023
-
[2]
arXiv (2023)
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv (2023)
2023
-
[3]
arXiv (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv (2025)
2025
-
[4]
arXiv (2025)
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-VL technical report. arXiv (2025)
2025
-
[5]
In: Proc
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. In: Proc. NeurIPS (2020)
2020
-
[6]
In: Proc
Chefer, H., Gur, S., Wolf, L.: Transformer interpretability beyond attention visu- alization. In: Proc. CVPR (2021)
2021
-
[7]
Cheng, J., Ge, Y., Wang, T., Ge, Y., Liao, J., Shan, Y.: Video-holmes: Can mllm think like holmes for complex video reasoning? arXiv (2025)
2025
-
[8]
arXiv (2024)
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., et al.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv (2024)
2024
-
[9]
In: Proc
Chowdhury, S., Nag, S., Dasgupta, S., Chen, J., Elhoseiny, M., Gao, R., Manocha, D.: Meerkat: Audio-visual large language model for grounding in space and time. In: Proc. ECCV (2024)
2024
-
[10]
In: Proc
Chuang, Y.S., Xie, Y., Luo, H., Kim, Y., Glass, J., He, P.: DoLa: Decoding by contrasting layers improves factuality in large language models. In: Proc. ICLR (2024)
2024
-
[11]
Journal of Machine Learning Research (2024)
Chung, H.W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., et al.: Scaling instruction-finetuned language models. Journal of Machine Learning Research (2024)
2024
-
[12]
arXiv (2025)
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv (2025)
2025
-
[13]
In: Proc
Dao, T.: Flashattention-2: Faster attention with better parallelism and work par- titioning. In: Proc. ICLR (2023)
2023
-
[14]
In: Proc
Dao, T., Fu, D.Y., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. In: Proc. NeurIPS (2022)
2022
-
[15]
In: Proc
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need reg- isters. In: Proc. NeurIPS (2024)
2024
-
[16]
int8 (): 8-bit matrix multiplication for transformers at scale
Dettmers, T., Lewis, M., Belkada, Y., Zettlemoyer, L.: Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. In: Proc. NeurIPS (2022)
2022
-
[17]
In: Proc
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proc. CVPR (2025)
2025
-
[18]
OpenReview (2025),https://openreview
Fu, Z., Zeng, W., Wang, R., Li, M.: Attention is not always needed: Attention sink forges a native moe in attention layers. OpenReview (2025),https://openreview. net/forum?id=dLeMTxzlh4 16 S.Yoo et al
2025
-
[19]
In: Proc
Gu, X., Pang, T., Du, C., Liu, Q., Zhang, F., Du, C., Wang, Y., Lin, M.: When attention sink emerges in language models: An empirical view. In: Proc. ICLR (2025)
2025
-
[20]
arXiv (2024)
Guo, T., Pai, D., Bai, Y., Jiao, J., Jordan, M.I., Mei, S.: Active-dormant atten- tion heads: Mechanistically demystifying extreme-token phenomena in llms. arXiv (2024)
2024
-
[21]
arXiv (2023)
Han, J., Zhang, R., Shao, W., Gao, P., Xu, P., Xiao, H., Zhang, K., Liu, C., Wen, S., Guo, Z., Lu, X., Ren, S., Wen, Y., Chen, X., Yue, X., Li, H., Qiao, Y.: Imagebind-llm: Multi-modality instruction tuning. arXiv (2023)
2023
-
[22]
arXiv (2020)
Henighan, T., Kaplan, J., Katz, M., Chen, M., Hesse, C., Jackson, J., Jun, H., Brown, T.B., Dhariwal, P., Gray, S., et al.: Scaling laws for autoregressive genera- tive modeling. arXiv (2020)
2020
-
[23]
In: Proc
Huo, F., Xu, W., Zhang, Z., Wang, H., Chen, Z., Zhao, P.: Self-introspective de- coding: Alleviating hallucinations for large vision-language models. In: Proc. ICLR (2025)
2025
-
[24]
In: Proc
Jiang, N., Dravid, A., Efros, A., Gandelsman, Y.: Vision transformers don’t need trained registers. In: Proc. NeurIPS (2025)
2025
-
[25]
arXiv (2025)
Jiao, P., Zhu, B., Chen, J., Ngo, C.W., Jiang, Y.G.: Don’t deceive me: Mitigating gaslighting through attention reallocation in lmms. arXiv (2025)
2025
-
[26]
arXiv (2025)
Jung, C., Jang, Y., Choi, J., Chung, J.S.: Fork-merge decoding: Enhancing multi- modal understanding in audio-visual large language models. arXiv (2025)
2025
-
[27]
In: Proc
Jung, C., Jang, Y., Chung, J.S.: Avcd: Mitigating hallucinations in audio-visual large language models through contrastive decoding. In: Proc. NeurIPS (2025)
2025
-
[28]
In: Proc
Kang, S., Kim, J., Kim, J., Hwang, S.J.: See what you are told: Visual attention sink in large multimodal models. In: Proc. ICLR (2025)
2025
-
[29]
arXiv (2020)
Kaplan, J., McCandlish, S., Henighan, T., Brown, T.B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., Amodei, D.: Scaling laws for neural language models. arXiv (2020)
2020
-
[30]
In: Proc
Kim, J., Kim, H., Yeonju, K., Ro, Y.M.: Code: Contrasting self-generated de- scription to combat hallucination in large multi-modal models. In: Proc. NeurIPS (2024)
2024
-
[31]
In: Proc
Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., Bing, L.: Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In: Proc. CVPR (2024)
2024
-
[32]
arXiv (2024)
Li, Y., Ma, Y., Zhang, G., Yuan, R., Zhu, K., Guo, H., Liang, Y., Liu, J., Wang, Z., Yang, J., et al.: Omnibench: Towards the future of universal omni-language models. arXiv (2024)
2024
-
[33]
In: Proc
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proc. EMNLP (2024)
2024
-
[34]
arXiv (2024)
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv (2024)
2024
-
[35]
In: Proc
Queipo-de Llano, E., Arroyo, Á., Barbero, F., Dong, X., Bronstein, M., LeCun, Y., Shwartz-Ziv, R.: Attention sinks and compression valleys in llms are two sides of the same coin. In: Proc. ICLR (2026)
2026
-
[36]
In: Proc
Luo, J., Fan, W.C., Wang, L., He, X., Rahman, T., Abolmaesumi, P., Sigal, L.: To sink or not to sink: Visual information pathways in large vision-language models. In: Proc. ICLR (2025)
2025
-
[37]
In: Proc
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: Proc. ACL (2024) On the Nature of Attention Sink 17
2024
-
[38]
arXiv (2022)
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., et al.: In-context learning and induction heads. arXiv (2022)
2022
-
[39]
In: Proc
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., et al.: Gated attention for large language models: Non- linearity, sparsity, and attention-sink-free. In: Proc. NeurIPS (2025)
2025
-
[40]
In: Proc
Sandoval-Segura, P., Wang, X., Panda, A., Goldblum, M., Basri, R., Goldstein, T., Jacobs, D.: Identifying and evaluating inactive heads in pretrained llms. In: Proc. ICLR (2026)
2026
-
[41]
In: Proc
Shah, J., Bikshandi, G., Zhang, Y., Thakkar, V., Ramani, P., Dao, T.: Flashattention-3: Fast and accurate attention with asynchrony and low-precision. In: Proc. NeurIPS (2024)
2024
-
[42]
arXiv (2026)
Sok, J., Yeom, J., Park, S., Park, J., Kim, T.: Garbage attention in large language models: Bos sink heads and sink-aware pruning. arXiv (2026)
2026
-
[43]
In: Proc
Sun, G., Yu, W., Tang, C., Chen, X., Tan, T., Li, W., Lu, L., Ma, Z., Wang, Y., Zhang, C.: video-salmonn: Speech-enhanced audio-visual large language models. In: Proc. ICLR (2024)
2024
-
[44]
In: Proc
Sun, M., Chen, X., Kolter, J.Z., Liu, Z.: Massive activations in large language models. In: Proc. COLM (2024)
2024
-
[45]
In: Proc
Sung-Bin,K.,Hyun-Bin,O.,Lee,J.,Senocak,A.,Chung,J.S.,Oh,T.H.:Avhbench: A cross-modal hallucination benchmark for audio-visual large language models. In: Proc. ICLR (2025)
2025
-
[46]
arXiv (2025)
Tang, C., Li, Y., Yang, Y., Zhuang, J., Sun, G., Li, W., Ma, Z., Zhang, C.: video- SALMONN 2: Caption-enhanced audio-visual large language models. arXiv (2025)
2025
-
[47]
arXiv (2025)
Tang, L., Zhuang, X., Yang, B., Hu, Z., Li, H., Ma, L., Ru, J., Zou, Y.: Not all tokens and heads are equally important: Dual-level attention intervention for hallucination mitigation. arXiv (2025)
2025
-
[48]
In: Proc
Tong, B., Xia, J., Zhou, K.: Mitigating hallucination in multimodal llms with layer contrastive decoding. In: Proc. NAACL (2025)
2025
-
[49]
In: Proc
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Proc. NeurIPS (2017)
2017
-
[50]
In: Proc
Voita, E., Talbot, D., Moiseev, F., Sennrich, R., Titov, I.: Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In: Proc. ACL (2019)
2019
-
[51]
In: Findings of ACL (2024)
Wang, X., Pan, J., Ding, L., Biemann, C.: Mitigating hallucinations in large vision- language models with instruction contrastive decoding. In: Findings of ACL (2024)
2024
-
[52]
In: Findings of NAACL (2025)
Wang, Y., Das, K., Gao, X., Cui, W., Li, P., Zhang, J.: Gradient-guided attention map editing: Towards efficient contextual hallucination mitigation. In: Findings of NAACL (2025)
2025
-
[53]
arXiv (2024)
Wei,H.,Shi,Y.,Inoue,N.:Phasediagramofvisionlargelanguagemodelsinference: A perspective from interaction across image and instruction. arXiv (2024)
2024
-
[54]
In: Proc
Xiao, G., Tian, Y., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. In: Proc. ICLR (2024)
2024
-
[55]
arXiv (2025)
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., Zhang, B., Wang, X., Chu, Y., Lin, J.: Qwen2.5-omni technical report. arXiv (2025)
2025
-
[56]
In: Proc
Yang, Y., Zhuang, J., Sun, G., Tang, C., Li, Y., Li, P., Jiang, Y., Li, W., Ma, Z., Zhang, C.: Audio-centric video understanding benchmark without text shortcut. In: Proc. EMNLP (2025) 18 S.Yoo et al
2025
-
[57]
In: Proc
Yu, Z., Wang, Z., Fu, Y., Shi, H., Shaikh, K., Lin, Y.C.: Unveiling and harnessing hidden attention sinks: Enhancing large language models without training through attention calibration. In: Proc. ICML (2024)
2024
-
[58]
In: Proc
Yu, Z., Xu, D., Yu, J., Yu, T., Zhao, Z., Zhuang, Y., Tao, D.: Activitynet-qa: A dataset for understanding complex web videos via question answering. In: Proc. AAAI (2019)
2019
-
[59]
In: Proc
Yu, Z., Lee, Y.J.: How multimodal llms solve image tasks: A lens on visual ground- ing, task reasoning, and answer decoding. In: Proc. COLM (2025)
2025
-
[60]
In: Proc
Zhai, X., Kolesnikov, A., Houlsby, N., Beyer, L.: Scaling vision transformers. In: Proc. CVPR (2022)
2022
-
[61]
arXiv (2025)
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv (2025)
2025
-
[62]
In: Proc
Zhang, H., Chen, H., Chen, M., Zhang, T.: Active layer-contrastive decoding re- duces hallucination in large language model generation. In: Proc. EMNLP (2025)
2025
-
[63]
In: Proc
Zhang, X., Quan, Y., Shen, C., Gu, C., Yuan, X., Yan, S., Cao, J., Cheng, H., Wu, K., Ye, J.: Shallow focus, deep fixes: Enhancing shallow layers vision attention sinks to alleviate hallucination in LVLMs. In: Proc. EMNLP (2025)
2025
-
[64]
arXiv (2025)
Zhou, Z., Wang, R., Wu, Z.: Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities. arXiv (2025)
2025
-
[65]
Zuhri, Z.M., Fuadi, E.H., Aji, A.F.: Softpick: No attention sink, no massive acti- vations with rectified softmax. arXiv (2025) On the Nature of Attention Sink 19 On the Nature of Attention Sink that Shapes Decoding Strategy in MLLMs – Supplementary Material – Contents A Analysis for Sink Identification .................................. 20 A.1 Sink and O...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.