Recognition: 2 theorem links
· Lean TheoremAcceleration of multi-component multiple-precision arithmetic with branch-free algorithms and SIMD vectorization
Pith reviewed 2026-05-15 10:41 UTC · model grok-4.3
The pith
Branch-free algorithms accelerate multi-component multiple-precision arithmetic using hardware floating-point formats
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
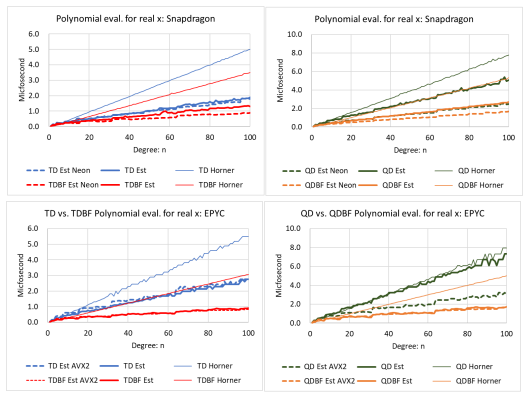
The paper establishes that multiple-precision floating-point branch-free algorithms significantly accelerate multi-component arithmetic implemented by combining hardware-based binary64 and binary32, particularly for triple- and quadruple-precision computations, with quantified accelerations in linear computations and polynomial evaluation on x86 and ARM CPU platforms.
What carries the argument
Branch-free algorithms that perform multiple-precision floating-point operations without conditional branches, enabling efficient combination of hardware binary64 and binary32 formats.
If this is right
- Triple- and quadruple-precision computations run faster in linear algebra routines.
- Polynomial evaluations see performance gains on both x86 and ARM architectures.
- SIMD vectorization can be integrated to further enhance the speedups.
- Multi-component arithmetic benefits from avoiding branch penalties in floating-point code.
Where Pith is reading between the lines
- These techniques might be adaptable to other numerical operations beyond linear computations and polynomial evaluation.
- Integration into general multiple-precision libraries could broaden their use in high-precision simulations.
- Potential energy savings in long-running computations due to reduced instruction overhead.
- Verification on additional CPU architectures would strengthen the platform-agnostic claims.
Load-bearing premise
The branch-free algorithms maintain numerical accuracy equivalent to standard implementations while delivering the reported speedups across platforms.
What would settle it
A test suite comparing outputs of the branch-free algorithms against conventional multiple-precision methods on random inputs; discrepancies larger than the precision's ulp would indicate failure of accuracy preservation.
Figures



read the original abstract
Multiple-precision floating-point branch-free algorithms can significantly accelerate multi-component arithmetic implemented by combining hardware-based binary64 and binary32, particularly for triple- and quadruple-precision computations. In this study, we achieved benchmark results on x86 and ARM CPU platforms to quantify the accelerations achieved in linear computations and polynomial evaluation by integrating these algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that branch-free algorithms for multi-component multiple-precision arithmetic, implemented by combining hardware binary64 and binary32 operations, can significantly accelerate triple- and quadruple-precision computations. It reports benchmark results on x86 and ARM platforms demonstrating speedups for linear algebra and polynomial evaluation tasks.
Significance. If the reported speedups are reproducible and accuracy is preserved, the work could offer practical performance gains for high-precision floating-point computations in scientific applications that can exploit SIMD vectorization, extending the utility of multi-component arithmetic beyond standard libraries.
major comments (1)
- [Abstract] Abstract: The benchmark results are presented without error bars, implementation details (such as compiler flags, rounding modes, or input ranges), or explicit verification of numerical accuracy against reference implementations. This directly undermines the central claim that the branch-free algorithms deliver speedups while maintaining equivalent accuracy, as the abstract provides no basis to assess these outcomes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional context on the experimental setup would strengthen the presentation of our claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The benchmark results are presented without error bars, implementation details (such as compiler flags, rounding modes, or input ranges), or explicit verification of numerical accuracy against reference implementations. This directly undermines the central claim that the branch-free algorithms deliver speedups while maintaining equivalent accuracy, as the abstract provides no basis to assess these outcomes.
Authors: We acknowledge that the abstract, as a concise summary, does not include these details. In the revised version we will expand the abstract to note the use of -O3 -march=native compilation, round-to-nearest-even mode, input ranges consisting of randomly generated values in [0,1] for polynomial evaluations and standard dense test matrices for linear algebra, and verification of results against the MPFR library showing agreement to the expected precision. Error bars derived from repeated runs will be added to the figures in Section 4, with a brief statement on reproducibility included in the abstract. The full implementation and verification procedures are already described in Sections 3 and 4; the revision will ensure the abstract adequately summarizes them. revision: yes
Circularity Check
No circularity detected in empirical benchmark claims
full rationale
The paper reports empirical speedups from branch-free algorithms and SIMD vectorization for multi-component multiple-precision arithmetic, validated through direct benchmarks on x86 and ARM platforms for linear algebra and polynomial evaluation. No derivation chain, equations, fitted parameters, or self-referential definitions are present; the central claims rest on measured performance and accuracy equivalence rather than any reduction to inputs by construction. This is a standard empirical result with no load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The BF algorithms for QW arithmetic (Algorithms 13 and 14) are remarkably concise and involve a substantially reduced operation count.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D.H. Bailey. QD.https://www.davidhbailey.com/dhbsoftware/
-
[2]
T. J. Dekker. A floating-point technique for extending the available preci- sion.Numerische Mathematik, Vol. 18, No. 3, pp. 224–242, Jun 1971
work page 1971
-
[3]
MPC.http: //www.multiprecision.org/mpc/
Andreas Enge, Philippe Théveny, and Paul Zimmermann. MPC.http: //www.multiprecision.org/mpc/
-
[4]
N. Fabiano, J-. M. Muller, and J. Picot. Algorithms for triple-word arith- metic.IEEE Trans. on Computers, Vol. 68, pp. 1573–1583, 2019
work page 2019
-
[5]
Granlaud and GMP development team
T. Granlaud and GMP development team. The GNU Multiple Precision arithmetic library.https://gmplib.org/
-
[6]
Avx acceleration of dd arithmetic between a sparse matrix and vector
Toshiaki Hishinuma, Akihiro Fujii, Teruo Tanaka, and Hidehiko Hasegawa. Avx acceleration of dd arithmetic between a sparse matrix and vector. In Roman Wyrzykowski, Jack Dongarra, Konrad Karczewski, and Jerzy Waśniewski, editors,Parallel Processing and Applied Mathematics, pp.622– 631, Berlin, Heidelberg, 2014. Springer Berlin Heidelberg. 16
work page 2014
-
[7]
T. Kotakemori, S. Fujii, H. Hasegawa, and A. Nishida. Lis: Library of iterative solvers for linear systems.https://www.ssisc.org/lis/
-
[8]
BNCmatmul.https://github.com/tkouya/ bncmatmul
Tomonori Kouya. BNCmatmul.https://github.com/tkouya/ bncmatmul
-
[9]
Tomonori Kouya. Acceleration of multiple precision matrix multiplication based on multi-component floating-point arithmetic using avx2. In Osvaldo Gervasi, Beniamino Murgante, Sanjay Misra, Chiara Garau, Ivan Blečić, David Taniar, Bernady O. Apduhan, Ana Maria A. C. Rocha, Eufemia Tarantino, and Carmelo Maria Torre, editors,Computational Science and Its A...
work page 2021
-
[10]
Performance evaluation of accelerated complex multiple- precision lu decomposition
Tomonori Kouya. Performance evaluation of accelerated complex multiple- precision lu decomposition. In Osvaldo Gervasi, Beniamino Murgante, Chiara Garau, David Taniar, Ana Maria A. C. Rocha, and Maria Noelia Faginas Lago, editors,Computational Science and Its Applications – ICCSA 2024 Workshops, pp. 3–19, Cham, 2024. Springer Nature Switzer- land
work page 2024
-
[11]
Marko Lange and Siegfried M. Rump. Faithfully rounded floating-point computations.ACM Trans. Math. Softw., Vol. 46, No. 3, July 2020
work page 2020
-
[12]
Supporting extended precision on graphics processors
Mian Lu, Bingsheng He, and Qiong Luo. Supporting extended precision on graphics processors. InProceedings of the Sixth International Workshop on Data Management on New Hardware, DaMoN ’10, pp. 19–26, New York, NY, USA, 2010. ACM
work page 2010
-
[13]
Multiple precision arithmetic LAPACK and BLAS.https://github.com/nakatamaho/mplapack
MPLAPACK/MPBLAS. Multiple precision arithmetic LAPACK and BLAS.https://github.com/nakatamaho/mplapack
-
[14]
Sparse iterative solvers using high- precision arithmetic with quasi multi-word algorithms
Daichi Mukunoki and Katsuhisa Ozaki. Sparse iterative solvers using high- precision arithmetic with quasi multi-word algorithms. In2025 IEEE 18th International Symposium on Embedded Multicore/Many-core Systems-on- Chip (MCSoC), pp. 33–40, 2025
work page 2025
-
[15]
The MPFR library.https://www.mpfr.org/
MPFR Project. The MPFR library.https://www.mpfr.org/
-
[16]
David K. Zhang and Alex Aiken. Automatic verification of floating-point accumulation networks. In Ruzica Piskac and Zvonimir Rakamarić, editors, Computer Aided Verification, pp. 215–237, Cham, 2025. Springer Nature Switzerland
work page 2025
-
[17]
High-performance branch-free algo- rithms for extended-precision floating-point arithmetic
David Kai Zhang and Alex Aiken. High-performance branch-free algo- rithms for extended-precision floating-point arithmetic. InProceedings of the International Conference for High Performance Computing, Network- ing, Storage and Analysis, SC ’25, p. 695–710, New York, NY, USA, 2025. Association for Computing Machinery. 17
work page 2025
-
[18]
Tomonori Kouya. Trial approach to accelerate multi-component-type multiple-precision basic linear computation with Arm neon intrinsics (in Japanese). Technical report, HPC, Sep 2025. 18
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.