Recognition: no theorem link
Indirect Question Answering in English, German and Bavarian: A Challenging Task for High- and Low-Resource Languages Alike
Pith reviewed 2026-05-15 10:25 UTC · model grok-4.3
The pith
Indirect question answering stays hard for multilingual models even in English, with GPT-generated data adding little help.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Indirect Question Answering, the task of determining whether an indirect response affirms or denies a question, yields low performance and severe overfitting for multilingual transformers on both high-resource languages and Bavarian. GPT-4o-mini generated training data fails to improve results because the model does not capture the required pragmatic nuances in any of the three languages tested.
What carries the argument
The InQA+ hand-annotated evaluation set and GenIQA GPT-generated training set, used to train and test polarity classification on indirect answers with mBERT, XLM-R, and mDeBERTa.
If this is right
- Larger amounts of training data improve IQA performance.
- The task remains difficult in both high-resource and low-resource languages.
- Label ambiguity and dataset size are key factors driving the observed low results.
- The same challenges and suggested remedies apply to other pragmatic classification tasks.
Where Pith is reading between the lines
- Current large language models may need additional mechanisms for handling non-literal meaning rather than relying on scale alone.
- Creating reliable training data for pragmatic phenomena may require human annotation or hybrid approaches instead of pure LLM generation.
- Similar performance gaps could appear in related tasks such as implicature detection or sarcasm classification.
Load-bearing premise
Hand-annotated polarity labels accurately reflect pragmatic indirectness and GPT-4o-mini outputs serve as a usable proxy for real-world indirect answers.
What would settle it
Collect a new test set of naturally occurring indirect answers from real conversations and measure whether model accuracy rises substantially above the reported low levels.
Figures






read the original abstract
Indirectness is a common feature of daily communication, yet is underexplored in NLP research for both low-resource as well as high-resource languages. Indirect Question Answering (IQA) aims at classifying the polarity of indirect answers. In this paper, we present two multilingual corpora for IQA of varying quality that both cover English, Standard German and Bavarian, a German dialect without standard orthography: InQA+, a small high-quality evaluation dataset with hand-annotated labels, and GenIQA, a larger training dataset, that contains artificial data generated by GPT-4o-mini. We find that IQA is a pragmatically hard task that comes with various challenges, based on several experiment variations with multilingual transformer models (mBERT, XLM-R and mDeBERTa). We suggest and employ recommendations to tackle these challenges. Our results reveal low performance, even for English, and severe overfitting. We analyse various factors that influence these results, including label ambiguity, label set and dataset size. We find that the IQA performance is poor in high- (English, German) and low-resource languages (Bavarian) and that it is beneficial to have a large amount of training data. Further, GPT-4o-mini does not possess enough pragmatic understanding to generate high-quality IQA data in any of our tested languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces InQA+, a small hand-annotated evaluation corpus, and GenIQA, a larger training corpus generated by GPT-4o-mini, for the task of classifying polarity in indirect answers. Both cover English, Standard German, and Bavarian. Experiments with mBERT, XLM-R, and mDeBERTa show low performance even on English, severe overfitting, and sensitivity to label ambiguity, label set, and dataset size. The authors conclude that IQA remains pragmatically difficult across resource levels and that GPT-4o-mini lacks sufficient pragmatic understanding to generate high-quality IQA data.
Significance. If the central empirical claims are supported by validated data, the work would usefully document the difficulty of pragmatic indirectness for both high- and low-resource languages and supply the first public multilingual resources for IQA, thereby motivating more careful use of LLM-generated data in pragmatics tasks.
major comments (3)
- [Dataset Construction and Evaluation] The central claim that GPT-4o-mini lacks pragmatic understanding is inferred from low downstream performance and overfitting when models are trained on GenIQA and evaluated on InQA+. This inference requires that GenIQA polarity labels are sufficiently accurate and that InQA+ hand labels constitute a stable gold standard, yet the manuscript reports neither human validation scores for GenIQA nor inter-annotator agreement for InQA+.
- [Experimental Results] No ablation is presented that isolates the contribution of generator error from task-inherent ambiguity, label-set effects, or distribution shift between GenIQA and InQA+. Without such controls, the observed performance gap cannot be unambiguously attributed to an intrinsic limitation of GPT-4o-mini.
- [Analysis of Results] The analysis of factors influencing results (label ambiguity, label set, dataset size) is presented without quantitative metrics (e.g., Krippendorff’s alpha on InQA+, precision of GPT-generated labels) that would allow readers to assess how much of the low performance is attributable to label noise versus model capability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that additional quantitative validation and controls would strengthen the manuscript's claims regarding the limitations of GPT-4o-mini for IQA data generation. Below we respond point-by-point to the major comments and indicate the revisions we will implement.
read point-by-point responses
-
Referee: The central claim that GPT-4o-mini lacks pragmatic understanding is inferred from low downstream performance and overfitting when models are trained on GenIQA and evaluated on InQA+. This inference requires that GenIQA polarity labels are sufficiently accurate and that InQA+ hand labels constitute a stable gold standard, yet the manuscript reports neither human validation scores for GenIQA nor inter-annotator agreement for InQA+.
Authors: We acknowledge this limitation in the current manuscript. In the revised version we will report inter-annotator agreement (Krippendorff’s alpha) for InQA+ based on a second independent annotation pass and provide human validation scores (precision/recall against expert judgments) for a stratified sample of 200 GenIQA instances per language. These additions will allow readers to assess the reliability of both the gold standard and the generated labels before interpreting the performance gap as evidence of GPT-4o-mini’s pragmatic shortcomings. revision: yes
-
Referee: No ablation is presented that isolates the contribution of generator error from task-inherent ambiguity, label-set effects, or distribution shift between GenIQA and InQA+. Without such controls, the observed performance gap cannot be unambiguously attributed to an intrinsic limitation of GPT-4o-mini.
Authors: We agree that stronger isolation of error sources is desirable. In the revision we will add two targeted ablations: (1) training on a human-corrected subset of GenIQA (where GPT labels are overridden by expert annotation) and (2) evaluating models on a matched-distribution subset of InQA+ that mirrors GenIQA’s label distribution and length statistics. We will also explicitly discuss the inherent difficulty of fully disentangling generator error from pragmatic ambiguity, as the task definition itself involves underspecified indirect answers; this limitation will be stated more clearly rather than claimed to be fully resolved. revision: partial
-
Referee: The analysis of factors influencing results (label ambiguity, label set, dataset size) is presented without quantitative metrics (e.g., Krippendorff’s alpha on InQA+, precision of GPT-generated labels) that would allow readers to assess how much of the low performance is attributable to label noise versus model capability.
Authors: We will incorporate the requested quantitative metrics in the revised manuscript. Specifically, we will report Krippendorff’s alpha for label ambiguity on InQA+, precision of GPT-generated labels on the human-validated GenIQA sample, and performance curves across varying training sizes with confidence intervals. These numbers will be integrated into the existing factor analysis section to help readers quantify the relative contributions of label noise and model limitations. revision: yes
Circularity Check
No circularity: purely empirical evaluation without derivations or reductions
full rationale
The paper is an empirical NLP study that constructs two datasets (hand-annotated InQA+ and GPT-4o-mini-generated GenIQA) and reports direct model performance metrics for mBERT, XLM-R, and mDeBERTa across English, German, and Bavarian. No equations, derivations, fitted parameters, or predictions appear; results are presented as raw experimental outcomes on polarity classification. Central claims about low performance, overfitting, and GPT-4o-mini's pragmatic limitations rest on these observable metrics and dataset comparisons, with no load-bearing steps that reduce by construction to self-defined inputs, self-citations, or ansatzes. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
with a Fleiss’ Kappa of 0.61. Figure 1 (top left) shows that we have the most agreement for cases that are either clearlyYesor Noand low agreement for every other label. Our IAA is κ = 0 .57forremappedand κ = 0 .70for yesno
-
[2]
GenIQA: Artificial Training Dataset As the availability of IQA data is limited, espe- cially for low-resource languages, we experiment with LLM-generated training data. We create Gen- IQA,whichconsistsof1,500question-answerpairs which we generate with GPT-4o-mini (OpenAI,
-
[3]
The data statement can be found in Appendix A.2
in English, Standard German and Bavarian. The data statement can be found in Appendix A.2. All languages were generated independently and not translated. The pairs were annotated by the modelatgenerationtimewiththesamelabelsetas InQA+ (§3.1). The label distribution per language is found in Table 3. As preliminary experiments showed high lan- guage quality...
work page 2024
-
[4]
Experimental Setups We explore the effect of data quantity and quality with three fine-tuneable multilingual models in their 5The ratings are higher when only considering an- swers by respondents from the region that the translator is from (refer to Figure 7 in Appendix D for more details). Parameter Grid Seach Random Search Learning Rate [1e-4, 1e-5, 1e-...
-
[5]
is a widely used baseline for many experi- mentsinalotofresearchpapers,forexampleinthe related Circa (Louis et al., 2020) and IndirectQA (Müller and Plank, 2024) research, sarcasm re- search of Jayaraman et al. (2022) and Zhang et al. (2021) and Bavarian tasks like slot and intent de- tection (van der Goot et al., 2021; Winkler et al., 2024). We complemen...
work page 2020
-
[6]
Results and Analysis Since the IQA task is challenging, we focus our ex- perimentsontheeffectsofdataqualityandquantity toseewhichismoreinfluentialtoreduceoverfitting. For the analysis of a difficult task, it is important to take multiple metrics into account, in our case: accuracy and F1 scores. The performance cannot always be read directly from the accu...
work page 2024
-
[7]
Discussion and Learnings Both our experiments and previous work achieve results around the majority class baseline, confirm- ing that IQA is highly challenging. Even in high- resource languages, the performance is low, and the gap widens in low-resource languages such as Bavarian. We thus share our learnings for IQA. Data quantity is important.A fundament...
-
[8]
Even GenIQA with a size of 1,500 instances is still too small to reach mean- ingful scores
and Friends-QIA (Damgaard et al., 2021) (615 + 5,930 instances). Even GenIQA with a size of 1,500 instances is still too small to reach mean- ingful scores. From previous research, we deduce that a dataset of at least a size between∼6,000 (Friends- QIA; Damgaard et al., 2021) and∼35,000 (Circa; Louis et al., 2020) might be necessary to learn enough pragma...
work page 2021
-
[9]
Conclusions We presented InQA+, a multilingual evaluation dataset, and GenIQA, an LLM-generated training corpus for IQA in English, German, and Bavarian. Our experiments confirm that IQA is pragmatically hard for high- and low-resource languages and we find that a large dataset is beneficial for good performance. Nevertheless, data quality and anno- tatio...
work page 2016
-
[10]
Bibliographical References Jamilu Awwalu, Saleh El-Yakub Abdullahi, and Abraham Eseoghene Evwiekpaefe. 2020. Parts of speech tagging: A review of techniques. FUDMA JOURNAL OF SCIENCES, 4(2):712– 721. Verena Blaschke, Barbara Kovačić, Siyao Peng, and Barbara Plank. 2024a. Maibaam annotation guidelines.arXiv preprint arXiv:2403.05902. Verena Blaschke, Barba...
-
[11]
MultiPICo: Multilingual perspectivist irony corpus. InProceedingsofthe62ndAnnualMeet- ing of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 16008– 16021, Bangkok, Thailand. Association for Com- putational Linguistics. Santiago Castro, Devamanyu Hazarika, Verónica Pérez-Rosas, Roger Zimmermann, Rada Mihal- cea, and Soujanya ...
work page 2019
-
[12]
International Confer- ence on Machine Learning and Data Engineer- ing
Deep learning-based parts-of-speech tag- ging in marathi language.Procedia Computer Science, 258:3771–3780. International Confer- ence on Machine Learning and Data Engineer- ing. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 201...
work page 2019
-
[13]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pos tagging of low-resource pashto lan- guage: annotated corpus and bert-based model. Lang Resources & Evaluation 59, pages 3243— -3265. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020. Deberta: Decoding- enhanced BERT with disentangled attention. CoRR, abs/2006.03654. Anders Holmberg. 2012. The syntax of negative questions and their answe...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Llämmlein: Compact and competitive german-only language models from scratch. BarbaraPlank.2022. The“problem”ofhumanlabel variation: On ground truth in data, modeling and evaluation. InProceedings of the 2022 Confer- ence on Empirical Methods in Natural Language Processing, pages 10671–10682, Abu Dhabi, United Arab Emirates. Association for Computa- tional...
work page 2022
-
[15]
Association for Computational Linguistics
Does ChatGPT resemble humans in pro- cessing implicatures? InProceedings of the 4th Natural Logic Meets Machine Learning Work- shop, pages 25–34, Nancy, France. Association for Computational Linguistics. Muhammad Reza Qorib, Geonsik Moon, and Hwee Tou Ng. 2024. Are decoder-only language models better than encoder-only language mod- els in understanding wo...
work page 2024
-
[16]
Understanding deep learning requires rethinking generalization
Seq vs seq: An open suite of paired en- coders and decoders. Miriam Winkler, Virginija Juozapaityte, Rob van der Goot, and Barbara Plank. 2024. Slot and in- tent detection resources for Bavarian and Lithua- nian: Assessing translations vs natural queries to digital assistants. InProceedings of the 2024 Joint International Conference on Computational Lingu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
The sentence structure and question-answer logic is correct, but the dialect does not make any sense
produced pseudo-Bavarian. The sentence structure and question-answer logic is correct, but the dialect does not make any sense. Llama’s (Meta, 2024) production is worse than Gemma’s as it only produced gibberish with the same sentence structure ofDo you have [...] - I have [...]. Unfortunately, we could not test generating with Model Name Instruction-tune...
work page 2024
-
[18]
and the Bavarian adapter Betzerl (CAIDAS Uni Würzburg, 2024) as they are not instruction- tuned and thus not suitable for our purpose. C.2. Prompt wording testing For the generation of the full GenIQA datasets, we fine-tuned the prompt to better capture the beneficial features provided by OpenAI’s best practices (OpenAI, 2024). The following prompt is the...
work page 2024
-
[19]
Can I learn at your place? - As long as you (a) Information aboutifparticipants speak dialect
Kann ich bei dir lernen? - So lange du ned sabbelst, klar. Can I learn at your place? - As long as you (a) Information aboutifparticipants speak dialect. (b) Information abouthow oftenpar- ticipants speak dialect. (c) Distribution channels where the participants found the survey. Figure 4: Personal disclosures of the participants in the dialect quality su...
-
[20]
Have you seen the film yet? - I’ve only seen the ad
Hast du den Film schon gesehen? - I hob nur die Werbung gseh. Have you seen the film yet? - I’ve only seen the ad. Contains pseudo-dialect (gseh, eng. seen). Quality: Low
-
[21]
Is the boss in the office? - He may be on the move
Ist der Chef im Büro? - Möglicherweise is er unterwegs. Is the boss in the office? - He may be on the move. Only contains one dialect word (is, eng. is). Quality: Medium
-
[22]
Will you get up tomorrow? - I’ll see how I’m doing
Wirstdumorgenaufstehen? -Ischaumaamoi, wies mir geht. Will you get up tomorrow? - I’ll see how I’m doing. 8https://www.dwds.de/wb/sabbeln Wrong Bavarian grammar (ma(Bavarian ver- sion ofwe) exposes the sentence as fake di- alect as it is incorrect here). Quality: Low
-
[23]
Ist die Pizza fertig? - Es riecht schon ganz lecker! Is the pizza ready? - It already smells deli- cious! Standard German. Quality: Low
-
[24]
Did you book a table? - I forgot
Habt ihr einen Tisch reserviert? - I hab’s vergessen. Did you book a table? - I forgot. Only contains one dialectal word, but sounds authentic nonetheless. Quality: High
-
[25]
Do you often go to the cinema? - I prefer to watch films at home
Gehst du oft ins Kino? - Ich schau lieber Filme doheim. Do you often go to the cinema? - I prefer to watch films at home. Wrong dialect spelling (doheim, std. ger. da- heim, eng. at home). Quality: Low
-
[26]
Is the beer cold? - It’s in the fridge
Ist das Bier kalt? - Es steht’s im Kühlschrank. Is the beer cold? - It’s in the fridge. No expression of the intended meaning. The answer is Bavarian, but only with the interpre- tation ofYou (plural) are in the fridge. For the question, it does not hold the correct meaning. Quality: Low
-
[27]
Hast du schonmal Ente gekocht? - I kimm mid de Entn klar. Entspann di. Have you ever cooked duck? - I can handle the ducks. Relax. Manually translated answer by the annotator Quality: High
-
[28]
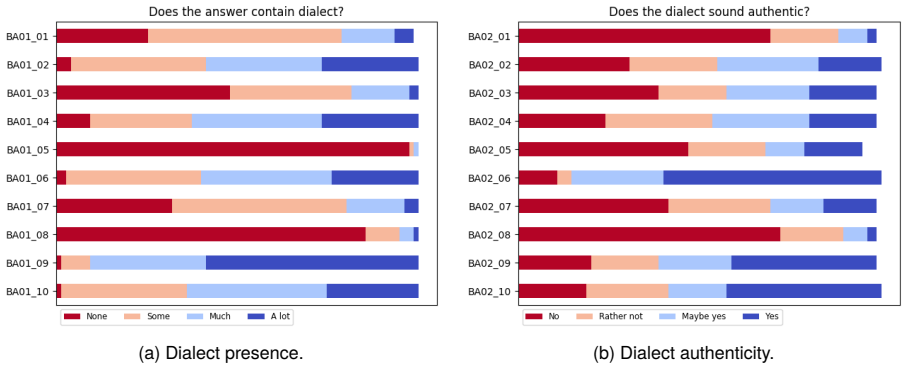
Isst du etwas Gesundes? - I hätt grad a Lust auf a Stück Pizza. (a) Dialect presence. (b) Dialect authenticity. Figure 6: Results of the dialect questions. (a) Authenticity rating in Upper Bavaria (author’s region). (b) Authenticity rating in Lower Bavaria. Figure 7: Results of the dialect questions per region. Are you eating something healthy? - I crave ...
work page 1929
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.