Enhancing classification accuracy through chaos
Pith reviewed 2026-05-15 10:04 UTC · model grok-4.3
The pith
Evolving lifted data vectors in a chaotic dynamical system produces states that a softmax classifier separates with higher accuracy and faster training than the original or statically lifted vectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lifting the data vectors into a higher-dimensional space and evolving them under a chaotic dynamical system for a prescribed temporal interval generates states that are more separable by a softmax classifier than either the original vectors or the lifted vectors without evolution. On the proof-of-concept data of randomly perturbed orthogonal vectors, this produces both significantly faster training convergence and higher classification accuracy. The improvement arises because the chaotic flow mixes and separates the perturbed samples, and an optimal evolution interval can be chosen to maximize the effect.
What carries the argument
The chaotic dynamical system that takes lifted vectors as initial conditions and evolves them for a prescribed temporal interval before the result enters the softmax classifier.
If this is right
- Training of the softmax classifier converges in fewer iterations because the evolved states are already more linearly separable.
- Classification accuracy on the perturbed orthogonal vector task exceeds both the baseline softmax on raw vectors and the lifted-only version.
- The same architecture works across different vector dimensions from 2 to 20 with the number of classes matching the dimension.
- An explicit selection procedure for the evolution interval exists that optimizes the separability gain from the chaotic flow.
Where Pith is reading between the lines
- The separability benefit might extend to other data distributions if their geometry allows chaotic mixing to increase class margins in a similar way.
- Inserting the lifting-plus-chaos step as a fixed preprocessing layer could reduce the depth or width needed in larger neural networks for comparable accuracy.
- Testing whether the optimal evolution interval scales predictably with vector dimension or perturbation strength would clarify how to apply the method beyond the current examples.
Load-bearing premise
Chaotic evolution of the lifted vectors for some interval reliably produces states more separable by softmax than the lifted vectors alone, at least when the data resemble randomly perturbed orthogonal vectors.
What would settle it
On samples of randomly perturbed orthogonal vectors, measuring that the chaos-evolved states yield no higher accuracy or slower training than a softmax applied directly to the original or lifted vectors without evolution.
Figures










read the original abstract
We propose a novel approach which exploits chaos to enhance classification accuracy. Specifically, the available data that need to be classified are treated as vectors that are first lifted into a higher-dimensional space and then used as initial conditions for the evolution of a chaotic dynamical system for a prescribed temporal interval. The evolved state of the dynamical system is then fed to a trainable softmax classifier which outputs the probabilities of the various classes. As proof-of-concept, we use samples of randomly perturbed orthogonal vectors of moderate dimension (2 to 20), with a corresponding number of classes equal to the vector dimension, and show how our approach can both significantly accelerate the training process and improve the classification accuracy compared to a standard softmax classifier which operates on the original vectors, as well as a softmax classifier which only lifts the vectors to a higher-dimensional space without evolving them. We also provide an explanation for the improved performance of the chaos-enhanced classifier and a selection process for the optimal chaotic evolution interval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes lifting input vectors to a higher-dimensional space, evolving them as initial conditions under a chaotic dynamical system for a prescribed time interval, and feeding the resulting state to a trainable softmax classifier. On synthetic data consisting of randomly perturbed orthogonal vectors (dimensions 2–20, with classes equal to dimension), it claims both faster training and higher classification accuracy relative to a standard softmax on the original vectors and a softmax on the lifted but non-evolved vectors. An explanation for the improvement and a procedure for choosing the optimal evolution interval are also supplied.
Significance. If the reported gains can be shown to arise specifically from chaotic evolution rather than from any sufficiently nonlinear time-dependent map, and if the interval-selection procedure is independent of accuracy maximization, the work would offer a concrete, reproducible example of using dynamical systems to enhance linear separability. The controlled synthetic setting and the explicit comparison to the non-evolved lift are strengths that allow the role of the evolution step to be isolated in principle.
major comments (3)
- [Method section / abstract] The description of the chaotic dynamical system (abstract and the method section) supplies neither the governing equations nor the concrete parameter values used. Without these, it is impossible to verify that the evolution is chaotic, to reproduce the experiments, or to test whether the separability gain requires chaos rather than generic stretching.
- [Section 3 / results] The selection process for the optimal evolution interval (Section 3 and results): if the interval is chosen by searching over a grid to maximize training or validation accuracy, the comparison to the non-evolved lift no longer isolates the contribution of chaos; any sufficiently nonlinear map could produce the same gain on the already linearly separable perturbed-orthogonal data.
- [Results section] Results section: the claimed accuracy improvements and training-speed gains are stated without numerical values, standard deviations, error bars, or statistical tests. This leaves the central empirical claim without the quantitative support needed to assess its magnitude or reliability.
minor comments (2)
- [Abstract] The abstract states dimensions 2–20 but does not list the exact dimensions or number of samples used in the reported experiments; adding a table or explicit list would improve clarity.
- [Method section] Notation for the lifted space and the evolved state is introduced without a consistent symbol table or equation numbering, making cross-references between the method and results harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment below and have made corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Method section / abstract] The description of the chaotic dynamical system (abstract and the method section) supplies neither the governing equations nor the concrete parameter values used. Without these, it is impossible to verify that the evolution is chaotic, to reproduce the experiments, or to test whether the separability gain requires chaos rather than generic stretching.
Authors: We agree that the governing equations and parameters were omitted and that this prevents verification and reproduction. The system is the Lorenz equations with the standard chaotic parameters σ=10, ρ=28, β=8/3; these equations together with the precise numerical integration scheme, time step, and initial-condition scaling used in the experiments have now been added to both the abstract and the Method section. revision: yes
-
Referee: [Section 3 / results] The selection process for the optimal evolution interval (Section 3 and results): if the interval is chosen by searching over a grid to maximize training or validation accuracy, the comparison to the non-evolved lift no longer isolates the contribution of chaos; any sufficiently nonlinear map could produce the same gain on the already linearly separable perturbed-orthogonal data.
Authors: We acknowledge the validity of this concern. The original selection procedure was based on locating the interval at which the maximal Lyapunov exponent indicates sufficient trajectory divergence, independent of classification accuracy. To further isolate the role of chaos, we have added a new set of experiments that compare the chaotic evolution against a non-chaotic but nonlinear time-dependent map (a simple polynomial stretching) using the same fixed interval; the revised Section 3 now explicitly describes the Lyapunov-based criterion and reports these additional controls. revision: yes
-
Referee: [Results section] Results section: the claimed accuracy improvements and training-speed gains are stated without numerical values, standard deviations, error bars, or statistical tests. This leaves the central empirical claim without the quantitative support needed to assess its magnitude or reliability.
Authors: We agree that quantitative support was insufficient. The Results section has been revised to report mean accuracy and training-time values with standard deviations over 20 independent runs, error bars on all plots, and p-values from paired t-tests comparing the three methods. These additions allow direct assessment of the magnitude and statistical reliability of the reported gains. revision: yes
Circularity Check
No circularity in empirical construction
full rationale
The paper presents an empirical method: lift input vectors to higher dimension, evolve under a chaotic dynamical system for a prescribed interval, then apply softmax classifier. Improvements are shown via direct comparison to two baselines (standard softmax on original vectors; lifted but non-evolved vectors). The provided explanation for performance and the selection process for the interval are described as part of the construction but do not reduce any claimed result to its inputs by definition, fitting, or self-citation chain. No equations or derivations appear that equate a prediction to a fitted parameter or rename a known result. The method is self-contained against the stated baselines.
Axiom & Free-Parameter Ledger
free parameters (2)
- evolution time interval
- chaotic system parameters
axioms (1)
- domain assumption Chaotic evolution of lifted vectors produces states more suitable for softmax classification than lifting alone.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
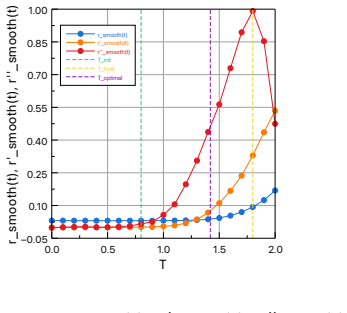
evolving the lifted vector using a chaotic dynamical system... Lorenz 96 model... T=2 units... based on Lyapunov time estimates... around 0.6
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Machine learning: a review of classification and combining techniques
Sotiris B Kotsiantis, Ioannis D Zaharakis, and Panayiotis E Pintelas. Machine learning: a review of classification and combining techniques. Artificial Intelligence Review, 26(3):159–190, 2006
work page 2006
-
[2]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521(7553):436–444, 2015
work page 2015
-
[3]
St´ ephane Lathuili` ere, Pablo Mesejo, Xavier Alameda-Pineda, and Radu Horaud. A comprehensive analysis of deep regression.IEEE transac- tions on pattern analysis and machine intelligence, 42(9):2065–2081, 2019
work page 2065
-
[4]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[5]
Qi An, Saifur Rahman, Jingwen Zhou, and James Jin Kang. A com- prehensive review on machine learning in healthcare industry: classifi- cation, restrictions, opportunities and challenges.Sensors, 23(9):4178, 2023
work page 2023
-
[6]
Eduardo A Gerlein, Martin McGinnity, Ammar Belatreche, and Sonya Coleman. Evaluating machine learning classification for financial trad- ing: An empirical approach.Expert Systems with Applications, 54:193– 207, 2016
work page 2016
-
[7]
Machine learning and its applications to biology.PLoS computational biology, 3(6):e116, 2007
Adi L Tarca, Vincent J Carey, Xue-wen Chen, Roberto Romero, and Sorin Dr˘ aghici. Machine learning and its applications to biology.PLoS computational biology, 3(6):e116, 2007
work page 2007
-
[8]
Machine learning and the physical sciences.Reviews of Modern Physics, 91(4):045002, 2019
Giuseppe Carleo, Ignacio Cirac, Kyle Cranmer, Laurent Daudet, Maria Schuld, Naftali Tishby, Leslie Vogt-Maranto, and Lenka Zdeborov´ a. Machine learning and the physical sciences.Reviews of Modern Physics, 91(4):045002, 2019
work page 2019
-
[9]
Kamal Choudhary, Brian DeCost, Chi Chen, Anubhav Jain, Francesca Tavazza, Ryan Cohn, Cheol Woo Park, Alok Choudhary, Ankit Agrawal, Simon JL Billinge, et al. Recent advances and applications of deep learning methods in materials science.npj Computational Mate- rials, 8(1):59, 2022. 27
work page 2022
-
[10]
A law of data separation in deep learning
Hangfeng He and Weijie J Su. A law of data separation in deep learning. Proceedings of the National Academy of Sciences, 120(36):e2221704120, 2023
work page 2023
-
[11]
Peter J Bickel and Elizaveta Levina. Some theory for fisher’s linear discriminant function,naive bayes’, and some alternatives when there are many more variables than observations.Bernoulli, 10(6):989–1010, 2004
work page 2004
-
[12]
Jianqing Fan and Yingying Fan. High dimensional classification using features annealed independence rules.Annals of statistics, 36(6):2605, 2008
work page 2008
-
[13]
Bissan Ghaddar and Joe Naoum-Sawaya. High dimensional data classi- fication and feature selection using support vector machines.European Journal of Operational Research, 265(3):993–1004, 2018
work page 2018
-
[14]
Augmenta- tion strategies for learning with noisy labels
Kento Nishi, Yi Ding, Alex Rich, and Tobias Hollerer. Augmenta- tion strategies for learning with noisy labels. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8022–8031, 2021
work page 2021
-
[15]
Caimin An, Fabing Duan, Fran¸ cois Chapeau-Blondeau, and Derek Ab- bott. Exploring the bayes-oriented noise injection approach in neural networks.Physics Letters A, page 130804, 2025
work page 2025
-
[16]
Staying on the manifold: Geometry-aware noise injection.arXiv preprint arXiv:2509.20201,
Albert Kjøller Jacobsen, Johanna Marie Gegenfurtner, and Georgios Arvanitidis. Staying on the manifold: Geometry-aware noise injection. arXiv preprint arXiv:2509.20201, 2025
-
[17]
Panos Stinis. Enforcing constraints for time series prediction in super- vised, unsupervised and reinforcement learning. InProceedings of the AAAI 2020 Spring Symposium on Combining Artificial Intelligence and Machine Learning with Physical Sciences. CEUR Workshop Proceed- ings, 2020
work page 2020
-
[18]
Predictability: A problem partly solved
Edward N Lorenz. Predictability: A problem partly solved. InProc. Seminar on predictability, volume 1, pages 1–18. Reading, 1996
work page 1996
-
[19]
Alireza Karimi and Mark R Paul. Extensive chaos in the lorenz-96 model.Chaos: An interdisciplinary journal of nonlinear science, 20(4), 2010. 28
work page 2010
-
[20]
Juan C Vallejo, Miguel AF Sanjuan, and Miguel AF Sanju´ an.Pre- dictability of chaotic dynamics. Springer, 2017
work page 2017
-
[21]
Julien Brajard, Alberto Carrassi, Marc Bocquet, and Laurent Bertino. Combining data assimilation and machine learning to emulate a dy- namical model from sparse and noisy observations: A case study with the lorenz 96 model.Journal of computational science, 44:101171, 2020
work page 2020
-
[22]
Joel Lehman and Kenneth O Stanley. Abandoning objectives: Evolu- tion through the search for novelty alone.Evolutionary computation, 19(2):189–223, 2011
work page 2011
-
[23]
Cambridge Univer- sity Press, 2003
Grigory Isaakovich Barenblatt.Scaling, volume 34. Cambridge Univer- sity Press, 2003
work page 2003
-
[24]
Pattern recognition in a bucket
Chrisantha Fernando and Sampsa Sojakka. Pattern recognition in a bucket. InEuropean conference on artificial life, pages 588–597. Springer, 2003
work page 2003
-
[25]
Recent advances in physical reservoir com- puting: A review.Neural Networks, 115:100–123, 2019
Gouhei Tanaka, Toshiyuki Yamane, Jean Benoit H´ eroux, Ryosho Nakane, Naoki Kanazawa, Seiji Takeda, Hidetoshi Numata, Daiju Nakano, and Akira Hirose. Recent advances in physical reservoir com- puting: A review.Neural Networks, 115:100–123, 2019
work page 2019
-
[26]
Giulia Marcucci, Davide Pierangeli, and Claudio Conti. Theory of neu- romorphic computing by waves: machine learning by rogue waves, dis- persive shocks, and solitons.Physical Review Letters, 125(9):093901, 2020
work page 2020
-
[27]
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012. 29
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.