Recognition: 1 theorem link
· Lean TheoremInterpreting Context-Aware Human Preferences for Multi-Objective Robot Navigation
Pith reviewed 2026-05-15 09:17 UTC · model grok-4.3
The pith
A pipeline uses vision and language models to translate spoken human preferences into adjustments for a robot's multi-objective navigation policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By extracting structured context from a VLM and turning natural language feedback into persistent rules via an LLM, the preference translation module generates vectors that parameterize a pretrained MORL policy, enabling controllable adaptation of navigation behavior to human intent across varied indoor environments.
What carries the argument
The preference translation module that maps VLM context and LLM-generated rules into numerical preference vectors for the MORL policy.
If this is right
- The robot can change speed, path choice, or caution level on the fly when rules specify context like avoiding crowds.
- Rule memory allows preferences to persist and update across multiple interactions without policy retraining.
- Quantitative checks confirm the generated vectors remain consistent for the same context and feedback.
- Real-world deployments maintain safe low-level control while adding high-level adaptability in diverse rooms.
- The pipeline improves transparency because the stored rules make the adapted behavior interpretable to users.
Where Pith is reading between the lines
- The same structure could support other robot skills if suitable multi-objective policies are available for those tasks.
- Performance will rise automatically as newer vision-language and language models improve context extraction.
- Rule memory could be expanded to learn and refine preferences automatically over repeated sessions.
Load-bearing premise
The VLM and LLM outputs are accurate and consistent enough to produce preference vectors that correctly and safely steer the pretrained MORL policy.
What would settle it
A robot executing an unsafe trajectory or ignoring a clear user instruction in one of the tested indoor scenarios would show the translation step failed to produce valid vectors.
Figures





read the original abstract
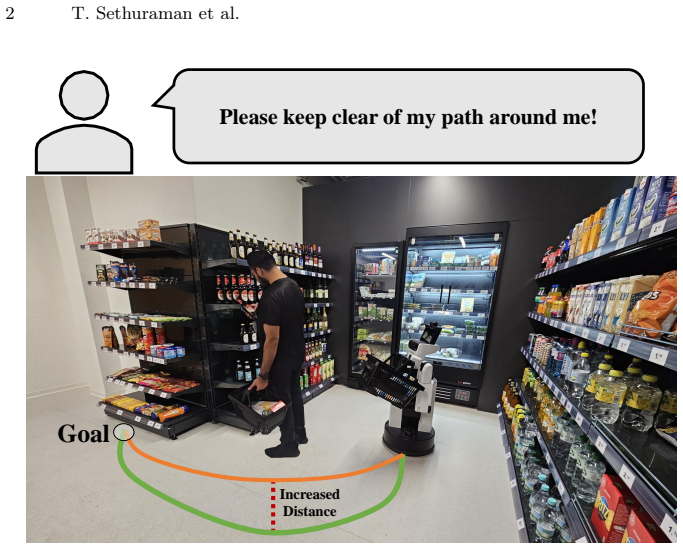
Robots operating in human-shared environments must not only achieve task-level navigation objectives such as safety and efficiency, but also adapt their behavior to human preferences. However, as human preferences are typically expressed in natural language and depend on environmental context, it is difficult to directly integrate them into low-level robot control policies. In this work, we present a pipeline that enables robots to understand and apply context-dependent navigation preferences by combining foundational models with a Multi-Objective Reinforcement Learning (MORL) navigation policy. Thus, our approach integrates high-level semantic reasoning with low-level motion control. A Vision-Language Model (VLM) extracts structured environmental context from onboard visual observations, while Large Language Models (LLM) convert natural language user feedback into interpretable, context-dependent behavioral rules stored in a persistent but updatable rule memory. A preference translation module then maps contextual information and stored rules into numerical preference vectors that parameterize a pretrained MORL policy for real-time navigation adaptation. We evaluate the proposed framework through quantitative component-level evaluations, a user study, and real-world robot deployments in various indoor environments. Our results demonstrate that the system reliably captures user intent, generates consistent preference vectors, and enables controllable behavior adaptation across diverse contexts. Overall, the proposed pipeline improves the adaptability, transparency, and usability of robots operating in shared human environments, while maintaining safe and responsive real-time control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a pipeline integrating a Vision-Language Model (VLM) to extract structured context from visual observations, Large Language Models (LLM) to translate natural-language user feedback into context-dependent behavioral rules stored in persistent memory, and a preference translation module that converts this information into numerical vectors parameterizing a pretrained Multi-Objective Reinforcement Learning (MORL) navigation policy. The system is evaluated via component-level quantitative tests, a user study, and real-world indoor deployments, with the central claim that it reliably captures user intent, produces consistent preference vectors, and enables controllable, safe behavior adaptation across contexts.
Significance. If the empirical claims hold with proper validation, the work would demonstrate a practical bridge between high-level semantic reasoning from foundation models and low-level multi-objective control, improving transparency and usability for robots in human-shared environments without requiring policy retraining. The interpretable rule memory and direct parameterization approach could serve as a template for other preference-driven robotics tasks.
major comments (2)
- [§5] §5 (Evaluation): The abstract and evaluation description assert that quantitative component-level tests, a user study, and real-world deployments demonstrate reliable performance, yet no metrics (e.g., success rates, preference alignment scores, latency, or safety violations), baselines, statistical analysis, or failure cases are reported. This absence is load-bearing for the central claim of reliable intent capture and consistent vector generation.
- [§3.3] §3.3 (Preference Translation): The module maps VLM context and LLM rule outputs directly to scalarized preference vectors for the pretrained MORL policy with no intermediate verification, uncertainty bounds, or safety filter. Because VLM/LLM errors map straight into the objective weights, this direct feed-through is load-bearing for the safety and controllability claims in real-world deployments.
minor comments (1)
- [Abstract] Abstract: The claim of 'reliable' performance would be clearer if at least one concrete quantitative indicator were included rather than relying solely on qualitative assertions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that the evaluation section requires substantially more quantitative detail and that the preference translation module needs explicit safeguards. We will revise the manuscript to incorporate these changes and strengthen the supporting evidence for our claims.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The abstract and evaluation description assert that quantitative component-level tests, a user study, and real-world deployments demonstrate reliable performance, yet no metrics (e.g., success rates, preference alignment scores, latency, or safety violations), baselines, statistical analysis, or failure cases are reported. This absence is load-bearing for the central claim of reliable intent capture and consistent vector generation.
Authors: We acknowledge that the current version of the manuscript reports only high-level descriptions of the component tests, user study, and deployments without the specific numerical metrics, baselines, statistical tests, or failure-case analysis needed to substantiate the claims. In the revised manuscript we will add: (i) success rates and preference-alignment scores for the VLM context extraction and LLM rule generation modules, (ii) latency measurements for the full pipeline, (iii) counts of safety violations observed in real-world trials, (iv) explicit baseline comparisons (e.g., direct LLM-to-action mapping and non-contextual MORL), and (v) statistical significance tests together with a discussion of observed failure modes. These additions will be placed in an expanded §5 with accompanying tables and figures. revision: yes
-
Referee: [§3.3] §3.3 (Preference Translation): The module maps VLM context and LLM rule outputs directly to scalarized preference vectors for the pretrained MORL policy with no intermediate verification, uncertainty bounds, or safety filter. Because VLM/LLM errors map straight into the objective weights, this direct feed-through is load-bearing for the safety and controllability claims in real-world deployments.
Authors: We agree that the direct mapping from VLM/LLM outputs to preference vectors without verification or safeguards is a limitation that weakens the safety argument. In the revision we will introduce: (i) an intermediate verification step that cross-checks generated rules against a small set of hand-crafted safety constraints, (ii) uncertainty bounds derived from the LLM’s token-level probabilities or ensemble sampling, and (iii) a lightweight safety filter that clips or rejects preference vectors whose resulting objective weights would violate hard safety thresholds (e.g., minimum collision-avoidance weight). These additions will be described in an updated §3.3 and evaluated in the expanded §5. revision: yes
Circularity Check
Low circularity: modular pipeline with external pretrained components
full rationale
The paper presents a compositional pipeline (VLM context extraction + LLM rule translation + preference vector mapping into a pretrained MORL policy) whose central claims rest on separate component evaluations, a user study, and real-world deployments. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are described; the MORL policy is explicitly pretrained externally and the preference vectors are generated from independent model outputs rather than from quantities defined inside the paper itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Outputs from VLM and LLM can be mapped to numerical preference vectors that correctly parameterize the MORL policy while preserving intent and safety.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A Vision-Language Model (VLM) extracts structured environmental context... LLM convert natural language user feedback into interpretable, context-dependent behavioral rules... preference translation module then maps... into numerical preference vectors that parameterize a pretrained MORL policy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Context Aware Robot Navigation using Interactively Built Semantic Maps
Cosgun, A., Christensen, H.: Context Aware robot navigation using interactively built semantic maps. arXiv preprint arXiv:1710.08682 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [3]
-
[4]
Doncieux, S., Chatila, R., Straube, S., Kirchner, F.: Human-centered AI and robotics. AI Perspectives4(1) (2022)
work page 2022
- [5]
-
[6]
In: Proceedings of the 31st International Con- ference on Computational Linguistics
Han, D., McInroe, T., Jelley, A., Albrecht, S.V., Bell, P., Storkey, A.: LLM- Personalize: Aligning LLM Planners with Human Preferences via Reinforced Self- Training for Housekeeping Robots. In: Proceedings of the 31st International Con- ference on Computational Linguistics. pp. 1465–1474 (2025)
work page 2025
-
[7]
arXiv preprint arXiv:2504.02477 (2025)
Han, X., Chen, S., Fu, Z., Feng, Z., Fan, L., An, D., Wang, C., Guo, L., Meng, W., Zhang, X., et al.: Multimodal fusion and vision-language models: A survey for robot vision. arXiv preprint arXiv:2504.02477 (2025)
- [8]
-
[9]
[Hwang, M., Weihs, L., Park, C., Lee, K., Kembhavi, A., Ehsani, K.: Promptable behaviors: Personalizing multi-objective rewards from human preferences
-
[10]
Jia, Y., Ramalingam, B., Mohan, R.E., Yang, Z., Zeng, Z., Veerajagadheswar, P.: Deep-learning-based context-aware multi-level information fusion systems for indoor mobile robots safe navigation. Sensors23(4) (2023)
work page 2023
-
[11]
Advanced Robotics38(18) (2024)
Kawaharazuka, K., , Tatsuya, M., , Andrew, G., , Jiaxian, G., , Chris, P., and Zeng, A.: Real-World Robot Applications of Foundation Models: A Review. Advanced Robotics38(18) (2024)
work page 2024
-
[12]
Kento Kawaharazuka and Jihoon Oh and Jun Yamada and Ingmar Posner and Yuke Zhu: Vision-Language-Action Models for Robotics: A Review Towards Real- World Applications. IEEE Access13 (2025)
work page 2025
-
[13]
Intelligent Service Robotics (2024)
Kim, Y., Kim, D., Choi, J., Park, J., Oh, N., Park, D.: A survey on integration of large language models with intelligent robots. Intelligent Service Robotics (2024)
work page 2024
-
[14]
In: Proceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction (2024)
Mahadevan, K., Chien, J., Brown, N., Xu, Z., Parada, C., Xia, F., Zeng, A., Takayama, L., Sadigh, D.: Generative expressive robot behaviors using large lan- guage models. In: Proceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction (2024)
work page 2024
-
[15]
In: Proceedings of the Annual Meeting of the Cognitive Science Society
Mannering, W., Ford, N., Harsono, J.J., Winder, J.: Generative artificial intelli- gence for behavioral intent prediction. In: Proceedings of the Annual Meeting of the Cognitive Science Society. vol. 46 (2024)
work page 2024
- [16]
-
[17]
ACM Transactions on Human-Robot Interaction12(3) (2023)
Mavrogiannis, C., Baldini, F., Wang, A., Zhao, D., Trautman, P., Steinfeld, A., Oh, J.: Core challenges of social robot navigation: A survey. ACM Transactions on Human-Robot Interaction12(3) (2023)
work page 2023
- [18]
- [19]
-
[20]
Ngo, T.D., Truong, X.T., et al.: Socially aware robot navigation framework: Where and how to approach people in dynamic social environments. IEEE Trans. on Automation Science and Engineering20(2) (2022)
work page 2022
- [21]
-
[22]
Othman, K.M., Rad, A.B.: SRIN: A new dataset for social robot indoor navigation. Glob. J. Eng. Sci4(10.33552) (2020)
work page 2020
-
[23]
Quattoni, A., Torralba, A.: Recognizing indoor scenes. In: In Proc. of the IEEE conf. on computer vision and pattern recognition. pp. 413–420. IEEE (2009)
work page 2009
-
[24]
Sathyamoorthy, A.J., Weerakoon, K., Elnoor, M., Zore, A., Ichter, B., Xia, F., Tan, J., Yu, W., Manocha, D.: ConVOI: Context-aware navigation using vision language models in outdoor and indoor environments. In: Proc. of the IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS) (2024)
work page 2024
-
[25]
arXiv preprint arXiv:2508.01539 (2025) Title Suppressed Due to Excessive Length 19
Seneviratne, G., An, J., Ellahy, S., Weerakoon, K., Elnoor, M.B., Kannan, J.D., Sunil, A.T., Manocha, D.: HALO: Human Preference Aligned Offline Reward Learning for Robot Navigation. arXiv preprint arXiv:2508.01539 (2025) Title Suppressed Due to Excessive Length 19
-
[26]
Song, Daeun and Liang, Jing and Payandeh, Amirreza and Raj, Amir Hossain and Xiao, Xuesu and Manocha, Dinesh: Vlm-social-nav: Socially aware robot naviga- tionthroughscoringusingvision-languagemodels.IEEERoboticsandAutomation Letters (RA-L)10(1) (2025)
work page 2025
-
[27]
Stefanini, E., Palmieri, L., Rudenko, A., Hielscher, T., Linder, T., Pallottino, L.: Efficientcontext-awaremodelpredictivecontrolforhuman-awarenavigation.IEEE Robotics and Automation Letters (RA-L) (2024)
work page 2024
-
[28]
Advanced Robotics 36(5-6) (2022)
Suzuki, M., Matsuo, Y.: A survey of multimodal deep generative models. Advanced Robotics 36(5-6) (2022)
work page 2022
-
[29]
arXiv preprint arXiv:2403.15648 (2024)
Wang, W., Mao, L., Wang, R., Min, B.C.: SRLM: Human-in-Loop Interactive Social Robot Navigation with Large Language Model and Deep Reinforcement Learning. arXiv preprint arXiv:2403.15648 (2024)
- [30]
-
[31]
Wu, J., Antonova, R., Kan, A., Lepert, M., Zeng, A., Song, S., Bohg, J., Rusinkiewicz,S.,Funkhouser,T.:Tidybot:Personalizedrobotassistancewithlarge language models. Autonomous Robots47(8) (2023)
work page 2023
-
[32]
Yamaguchi, U., Saito, F., Ikeda, K., Yamamoto, T.: HSR, human support robot as research and development platform. In: The Abstracts of the international confer- enceonadvancedmechatronics:towardevolutionaryfusionofITandmechatronics: ICAM 2015.6. The Japan Society of Mechanical Engineers (2015)
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.