Recognition: unknown
Attention Sparsity is Input-Stable: Training-Free Sparse Attention for Video Generation via Offline Sparsity Profiling and Online QK Co-Clustering
Pith reviewed 2026-05-15 08:52 UTC · model grok-4.3
The pith
Attention sparsity in video diffusion transformers stays nearly constant per layer no matter the input video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We uncover a critical insight: attention sparsity is an intrinsic layer-wise property, with only minor variation across different inputs. Motivated by this observation, we propose SVOO, a training-free sparse attention framework for fast video generation via offline layer-wise sparsity profiling and online bidirectional co-clustering.
What carries the argument
Offline layer-wise sensitivity profiling that fixes per-layer pruning ratios, combined with online bidirectional query-key co-clustering that partitions attention blocks for sparse computation.
Load-bearing premise
The small observed differences in sparsity across inputs are small enough that a single fixed per-layer profile works for all practical videos without large quality loss.
What would settle it
Profiling optimal sparsity on a wide range of video inputs and finding that the best pruning ratio for any given layer shifts by more than a few percent would disprove the input-stability claim.
Figures











read the original abstract
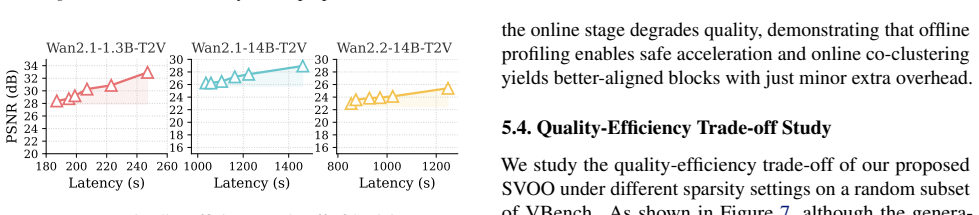
Diffusion Transformers (DiTs) achieve strong video generation quality but suffer from high inference cost due to dense 3D attention, motivating sparse attention techniques for improving efficiency. However, existing training-free sparse attention methods for video generation still face two unresolved limitations: ignoring layer heterogeneity in attention pruning and ignoring query-key coupling in block partitioning, which hinder a better quality-speedup trade-off. In this work, we uncover a critical insight: attention sparsity is an intrinsic layer-wise property, with only minor variation across different inputs. Motivated by this observation, we propose SVOO, a training-free sparse attention framework for fast video generation via offline layer-wise sparsity profiling and online bidirectional co-clustering. Specifically, SVOO adopts a two-stage paradigm: (i) offline layer-wise sensitivity profiling to derive intrinsic per-layer pruning levels, and (ii) online block-wise sparse attention via a bidirectional co-clustering algorithm. Extensive experiments on seven widely used video generation models demonstrate that SVOO achieves a superior quality-speedup trade-off over state-of-the-art methods, delivering up to 1.93x speedup while maintaining a PSNR of up to 29 dB on Wan2.1. Code is available at: https://github.com/Mutual-Luo/SVOO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SVOO, a training-free sparse attention framework for Diffusion Transformer-based video generation. It rests on the empirical observation that attention sparsity is an intrinsic per-layer property exhibiting only minor variation across inputs. This enables a two-stage approach: offline layer-wise sensitivity profiling to set fixed per-layer pruning ratios, followed by online block-wise sparse attention using a bidirectional QK co-clustering algorithm. Experiments across seven video generation models report up to 1.93× speedup while maintaining PSNR values up to 29 dB, claiming a better quality-speedup trade-off than prior training-free sparse attention methods.
Significance. If the input-stability of layer-wise sparsity is robustly confirmed, the work offers a practical route to accelerate inference in high-quality video DiT models without retraining. By explicitly handling layer heterogeneity and query-key coupling (limitations noted in existing methods), it could improve efficiency for deployment of video generation systems, with the multi-model evaluation providing reasonable evidence of generality within current architectures.
major comments (2)
- [Experiments] The central claim that 'attention sparsity is an intrinsic layer-wise property, with only minor variation across different inputs' is load-bearing for the offline profiling stage, yet the experiments section reports only aggregate speedup and PSNR metrics across seven models. No per-layer variance statistics, standard deviations, or sensitivity curves across diverse or out-of-distribution video inputs are provided to quantify the 'minor variation' or bound the risk of over-/under-pruning.
- [§3] §3 (online stage): The bidirectional co-clustering algorithm is introduced to partition blocks while respecting query-key coupling, but the manuscript provides no analysis, approximation bounds, or ablation quantifying information loss relative to dense attention. This leaves the quality preservation (e.g., the reported 29 dB PSNR) without a clear link to the clustering design.
minor comments (2)
- [Abstract] The abstract states 'PSNR of up to 29 dB on Wan2.1' but does not specify the exact video resolution, sequence length, or baseline comparison for this peak value, which would aid interpretation of the quality-speedup trade-off.
- Figure captions and legends in the experimental results could be expanded to explicitly label all compared methods and metrics for quicker cross-reference with the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comments point by point below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] The central claim that 'attention sparsity is an intrinsic layer-wise property, with only minor variation across different inputs' is load-bearing for the offline profiling stage, yet the experiments section reports only aggregate speedup and PSNR metrics across seven models. No per-layer variance statistics, standard deviations, or sensitivity curves across diverse or out-of-distribution video inputs are provided to quantify the 'minor variation' or bound the risk of over-/under-pruning.
Authors: We agree that explicit quantification of the minor variation in layer-wise sparsity across inputs would better support the offline profiling approach. While the aggregate results across seven models provide indirect evidence of stability, we will revise the experiments section to include per-layer variance statistics, standard deviations, and sensitivity curves. These will be computed over a range of video inputs, including some out-of-distribution examples, to quantify the variation and assess pruning risks. revision: yes
-
Referee: [§3] §3 (online stage): The bidirectional co-clustering algorithm is introduced to partition blocks while respecting query-key coupling, but the manuscript provides no analysis, approximation bounds, or ablation quantifying information loss relative to dense attention. This leaves the quality preservation (e.g., the reported 29 dB PSNR) without a clear link to the clustering design.
Authors: We acknowledge that the manuscript lacks a direct analysis linking the co-clustering design to information loss and quality preservation. The reported PSNR values serve as an empirical demonstration, but to strengthen this, we will add ablations in the revised manuscript. These will include comparisons of attention map fidelity and quality metrics for different clustering strategies, providing a clearer connection between the bidirectional QK co-clustering and the maintained generation quality. revision: yes
Circularity Check
No circularity: empirical stability claim and profiling method are self-contained
full rationale
The paper's central insight that attention sparsity is an intrinsic layer-wise property with minor input variation is presented as an empirical observation validated by experiments across seven models, not as a mathematical derivation that reduces to its own inputs by construction. Offline sensitivity profiling determines per-layer pruning ratios from measured data, and the online co-clustering step operates on query-key pairs without re-using fitted values as predictions. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing premises. The approach is a standard two-stage empirical pipeline whose correctness rests on external experimental outcomes rather than internal definitional loops.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
HASTE: Training-Free Video Diffusion Acceleration via Head-Wise Adaptive Sparse Attention
HASTE delivers up to 1.93x speedup on Wan2.1 video DiTs via head-wise adaptive sparse attention using temporal mask reuse and error-guided per-head calibration while preserving video quality.
-
Ride the Wave: Precision-Allocated Sparse Attention for Smooth Video Generation
PASA uses curvature-aware dynamic budgeting, grouped approximations, and stochastic attention routing to accelerate video diffusion transformers while eliminating temporal flickering from sparse patterns.
Reference graph
Works this paper leans on
-
[1]
Chen, A., Dong, B., Li, J., Lin, J., Tian, K., Yao, Y ., and Wang, G. Rainfusion: Adaptive video generation accel- eration via multi-dimensional visual redundancy.arXiv preprint arXiv:2505.21036,
-
[2]
Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024
Lin, B., Ge, Y ., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y ., Yuan, S., Chen, L., et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131,
-
[3]
Draftattention: Fast video diffusion via low-resolution attention guidance
Shen, X., Han, C., Zhou, Y ., Xie, Y ., Gong, Y ., Wang, Q., Wang, Y ., Wang, Y ., Zhao, P., and Gu, J. Draftattention: Fast video diffusion via low-resolution attention guidance. arXiv preprint arXiv:2505.14708,
-
[4]
V orta: Efficient video diffusion via routing sparse attention.arXiv preprint arXiv:2505.18809,
Sun, W., Tu, R.-C., Ding, Y ., Jin, Z., Liao, J., Liu, S., and Tao, D. V orta: Efficient video diffusion via routing sparse attention.arXiv preprint arXiv:2505.18809,
-
[5]
Tan, X., Chen, Y ., Jiang, Y ., Chen, X., Yan, K., Duan, N., Zhu, Y ., Jiang, D., and Xu, H. Dsv: Exploiting dynamic sparsity to accelerate large-scale video dit training.arXiv preprint arXiv:2502.07590,
-
[6]
Team, H., Wang, Z., Liu, Y ., Wu, J., Gu, Z., Wang, H., Zuo, X., Huang, T., Li, W., Zhang, S., et al. Hunyuan- world 1.0: Generating immersive, explorable, and inter- active 3d worlds from words or pixels.arXiv preprint arXiv:2507.21809,
-
[7]
Wan: Open and Advanced Large-Scale Video Generative Models
URL https://github. com/hao-ai-lab/FastVideo. Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Vmoba: Mixture-of-block attention for video diffusion models.arXiv preprint arXiv:2506.23858,
Wu, J., Hou, L., Yang, H., Tao, X., Tian, Y ., Wan, P., Zhang, D., and Tong, Y . Vmoba: Mixture-of-block attention for video diffusion models.arXiv preprint arXiv:2506.23858,
-
[9]
Xi, H., Yang, S., Zhao, Y ., Xu, C., Li, M., Li, X., Lin, Y ., Cai, H., Zhang, J., Li, D., et al. Sparse videogen: Acceler- ating video diffusion transformers with spatial-temporal sparsity.arXiv preprint arXiv:2502.01776,
-
[10]
Xia, Y ., Ling, S., Fu, F., Wang, Y ., Li, H., Xiao, X., and Cui, B. Training-free and adaptive sparse attention for efficient long video generation.arXiv preprint arXiv:2502.21079,
-
[11]
Xattention: Block sparse attention with antidiagonal scoring.arXiv preprint arXiv:2503.16428,
9 Xu, R., Xiao, G., Huang, H., Guo, J., and Han, S. Xattention: Block sparse attention with antidiagonal scoring.arXiv preprint arXiv:2503.16428,
-
[12]
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
Yang, S., Xi, H., Zhao, Y ., Li, M., Zhang, J., Cai, H., Lin, Y ., Li, X., Xu, C., Peng, K., et al. Sparse videogen2: Accel- erate video generation with sparse attention via semantic- aware permutation.arXiv preprint arXiv:2505.18875,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y ., Hong, W., Zhang, X., Feng, G., et al. Cogvideox: Text-to-video diffusion models with an ex- pert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Ye, Z., Chen, L., Lai, R., Lin, W., Zhang, Y ., Wang, S., Chen, T., Kasikci, B., Grover, V ., Krishnamurthy, A., et al. Flash- infer: Efficient and customizable attention engine for llm inference serving.arXiv preprint arXiv:2501.01005,
-
[15]
Bidirectional sparse attention for faster video diffusion training.arXiv preprint arXiv:2509.01085,
Zhan, C., Li, W., Shen, C., Zhang, J., Wu, S., and Zhang, H. Bidirectional sparse attention for faster video diffusion training.arXiv preprint arXiv:2509.01085,
-
[16]
Spargeattention: Accurate and training-free sparse attention accelerating any model inference
Zhang, J., Xiang, C., Huang, H., Xi, H., Zhu, J., Chen, J., et al. Spargeattention: Accurate and training-free sparse attention accelerating any model inference. InF orty- second International Conference on Machine Learning. Zhang, J., Xiang, C., Huang, H., Wei, J., Xi, H., Zhu, J., and Chen, J. Spargeattn: Accurate sparse atten- tion accelerating any mod...
-
[17]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y ., Zhang, F., Gu, L., Zhang, Y ., He, J., Zheng, W.-S., et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y ., Li, T., and You, Y . Open-sora: Democratiz- ing efficient video production for all.arXiv preprint arXiv:2412.20404,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
As reported, SVOO consistently maintains high-fidelity generative performance across various architectures, including Wan2.1, Wan2.2, and HunyuanVideo. Notably, in metrics such as Temporal Flickering and Motion Smoothness, our method delivers results that are highly competitive with the original dense models while outperforming baselines. B.3. The Influen...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.