Recognition: no theorem link
Text-Based Personas for Simulating User Privacy Decisions
Pith reviewed 2026-05-15 08:50 UTC · model grok-4.3
The pith
Synthetic personas grounded in past privacy behaviors let LLMs predict user decisions with up to 87 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
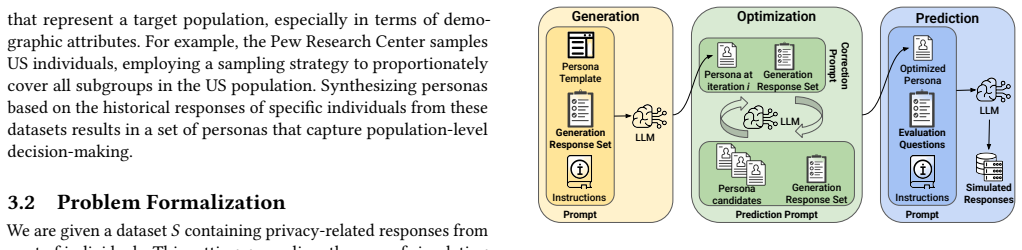
Narriva generates text-based synthetic privacy personas by compressing prior user privacy decisions from survey data into concise, theory-structured summaries; when used as LLM prompts these personas achieve up to 87 percent predictive accuracy on individual decisions, outperform non-personalized baselines by 6-17 points, reduce token usage by 80-95 percent relative to raw-example prompting, and reproduce population-level distributions from different studies.
What carries the argument
Narriva personas: concise, human-readable text summaries of an individual's past privacy decisions, derived from survey data and organized according to established privacy theories for direct use in LLM prompts.
If this is right
- Large-scale privacy user studies can be run at low cost by substituting LLM simulations for real participants.
- Autonomous agents can receive more precise alignment with individual privacy preferences through auditable persona prompts.
- Prompt engineering for behavioral simulation becomes far more token-efficient while retaining or improving accuracy.
- Privacy behavior models can be transferred across independent datasets without retraining on raw examples.
Where Pith is reading between the lines
- The same grounding technique could be tested for simulating decisions in adjacent domains such as health data sharing or financial privacy.
- Developers might embed these personas into privacy-setting wizards to preview how different user types would respond to new options.
- Periodic re-grounding of personas on fresh survey waves could track how population privacy attitudes shift over time.
Load-bearing premise
Personas synthesized from one survey dataset can faithfully reproduce the decision processes and statistical distributions of entirely different studies without overfitting to survey-specific wording or population traits.
What would settle it
Synthesize personas from one privacy survey dataset, apply them to predict outcomes on a held-out dataset from a completely different study, and test whether the predicted aggregate distributions match the observed responses within statistical error bounds.
Figures











read the original abstract
The ability to simulate human privacy decisions has significant implications for aligning autonomous agents with individual intent and conducting cost-effective, large-scale privacy-centric user studies. Prior approaches prompt Large Language Models (LLMs) with natural language user statements, data-sharing histories, or demographic attributes to simulate privacy decisions. These approaches, however, fail to balance individual-level accuracy, human auditability, token efficiency, and population-level representation. We present Narriva, an approach that generates text-based synthetic privacy personas to address these shortcomings. Narriva grounds persona generation in prior user privacy decisions, such as those from large-scale survey datasets, rather than purely relying on demographic stereotypes. It compresses this data into concise, human-readable summaries structured by established privacy theories. Through benchmarking across five diverse datasets, we analyze the characteristics of Narriva's synthetic personas in modeling both individual and population-level privacy preferences. We find that grounding personas in past privacy behaviors achieves up to 87% predictive accuracy, improving over a non-personalized LLM baseline by 6-17 percentage points across datasets, while yielding an 80-95% reduction in prompt tokens compared to in-context learning with raw examples. Finally, we demonstrate that personas synthesized from a single survey can reproduce the aggregate privacy behaviors and statistical distributions of entirely different studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Narriva, a method to generate text-based synthetic privacy personas by grounding them in users' prior privacy decisions from survey datasets and structuring the summaries according to established privacy theories. These personas are benchmarked on five datasets for both individual-level prediction and population-level reproduction, with claims of up to 87% predictive accuracy (6-17 percentage points above a non-personalized LLM baseline), 80-95% token reduction versus in-context learning, and successful reproduction of aggregate behaviors and statistical distributions from entirely different studies.
Significance. If the reported accuracy gains and cross-dataset reproduction hold under proper statistical controls, the work would provide a practical advance in simulating privacy decisions for AI alignment and scalable user studies, improving on prior prompting approaches by balancing individual accuracy, human auditability, and efficiency.
major comments (2)
- [Abstract] Abstract and evaluation description: the reported accuracy improvements of 6-17 percentage points are presented without error bars, details on data splits, statistical significance tests, or controls for LLM output variability; these omissions make it impossible to assess whether the gains are robust or attributable to the persona grounding.
- [Abstract] Cross-dataset reproduction claim (Abstract): the central demonstration that personas synthesized from a single survey reproduce aggregate behaviors and statistical distributions of different studies is load-bearing, yet the abstract supplies no concrete metrics (e.g., distributional distances, decision-rate errors) or controls for survey-specific wording, response scales, or demographic correlations; without these the reproduction could arise from superficial similarity rather than transferable decision rules.
minor comments (2)
- [Abstract] The abstract introduces 'Narriva' without a concise definition of its core pipeline (persona synthesis, theory structuring, and inference steps) before stating results.
- [Abstract] Clarify how token counts for the 80-95% reduction are measured (e.g., whether they include the persona summary itself or only the decision prompt).
Simulated Author's Rebuttal
We thank the referee for their constructive feedback highlighting the need for greater statistical detail and metric specificity in the abstract. We have revised the manuscript to address these points directly while preserving the core claims supported by the full evaluation.
read point-by-point responses
-
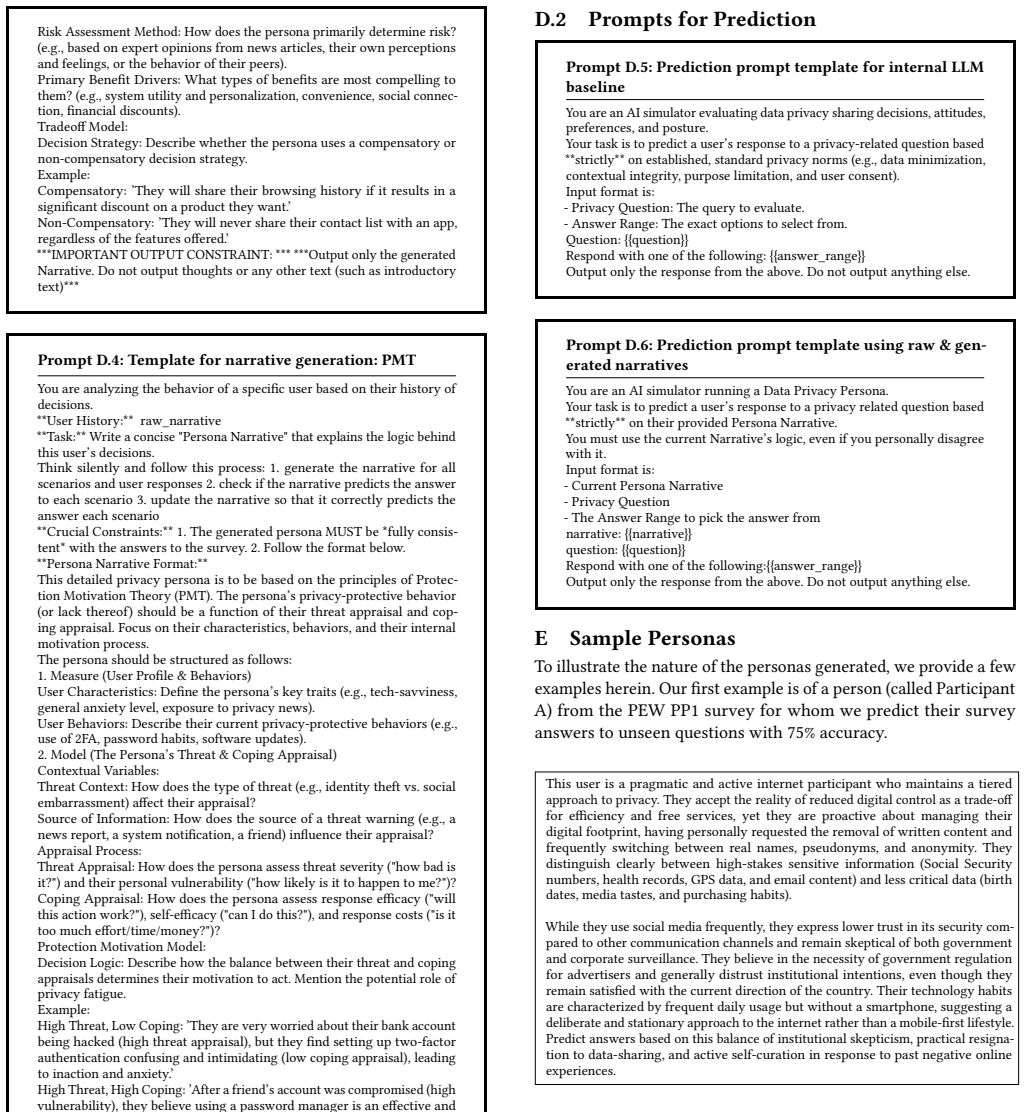
Referee: [Abstract] Abstract and evaluation description: the reported accuracy improvements of 6-17 percentage points are presented without error bars, details on data splits, statistical significance tests, or controls for LLM output variability; these omissions make it impossible to assess whether the gains are robust or attributable to the persona grounding.
Authors: We agree that the abstract omits key statistical details. The main text describes the evaluation protocol, including per-dataset train/test splits, multiple LLM sampling runs to quantify output variability, and significance testing of accuracy gains. In the revised version we will update the abstract to concisely report error bars on the 6-17 point improvements, reference the split methodology, and note the controls for variability. revision: yes
-
Referee: [Abstract] Cross-dataset reproduction claim (Abstract): the central demonstration that personas synthesized from a single survey reproduce aggregate behaviors and statistical distributions of different studies is load-bearing, yet the abstract supplies no concrete metrics (e.g., distributional distances, decision-rate errors) or controls for survey-specific wording, response scales, or demographic correlations; without these the reproduction could arise from superficial similarity rather than transferable decision rules.
Authors: We acknowledge that the abstract lacks explicit reproduction metrics and controls. The body of the paper quantifies reproduction via distributional distances and decision-rate errors while applying scale normalization and demographic matching to mitigate wording and correlation confounds. We will revise the abstract to include representative metrics and a brief statement on these standardization steps. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical approach (Narriva) that generates personas from survey data and benchmarks predictive accuracy (up to 87%) plus cross-dataset reproduction on five external studies. All reported results are measured against held-out behaviors and independent datasets rather than reducing to fitted parameters or self-referential definitions. No equations, self-citations, or ansatzes are invoked in a load-bearing way that collapses the central claims back to the inputs by construction. The reproduction demonstration is framed as an external validation step, consistent with standard empirical ML evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Established privacy theories provide a valid and sufficient structure for summarizing user privacy decisions from survey data
Forward citations
Cited by 2 Pith papers
-
PrivacySIM: Evaluating LLM Simulation of User Privacy Behavior
PrivacySIM shows that conditioning LLMs on user personas like demographics and attitudes improves simulation of privacy choices but reaches only 40.4% accuracy against real responses from 1,000 users.
-
An AI Agent Execution Environment to Safeguard User Data
GAAP guarantees confidentiality of private user data for AI agents by enforcing user-specified permissions deterministically through persistent information flow tracking, without trusting the agent or requiring attack...
Reference graph
Works this paper leans on
-
[1]
Noura Abdi, Xiao Zhan, Kopo M. Ramokapane, and Jose Such. 2021. Privacy Norms for Smart Home Personal Assistants. InProceedings of the 2021 CHI Con- ference on Human Factors in Computing Systems(Yokohama, Japan)(CHI ’21). Association for Computing Machinery, New York, NY, USA, Article 558, 14 pages. https://doi.org/10.1145/3411764.3445122 12
-
[2]
Alessandro Acquisti. 2004. Privacy in electronic commerce and the economics of immediate gratification. InProceedings of the 5th ACM Conference on Electronic Commerce(New York, NY, USA)(EC ’04). Association for Computing Machinery, New York, NY, USA, 21–29. https://doi.org/10.1145/988772.988777
-
[3]
Alessandro Acquisti, Laura Brandimarte, and George Loewenstein. 2015. Privacy and human behavior in the age of information.Science347, 6221 (2015), 509–514
work page 2015
-
[4]
A. Acquisti and J. Grossklags. 2005. Privacy and rationality in individual decision making.IEEE Security & Privacy3, 1 (2005), 26–33. https://doi.org/10.1109/MSP. 2005.22
work page doi:10.1109/msp 2005
-
[5]
Jacy Anthis, Ryan Liu, Sean Richardson, Austin Kozlowski, Bernard Koch, Erik Brynjolfsson, James Evans, and Michael Bernstein. 2025. Position: LLM Social Simulations Are a Promising Research Method. InForty-second International Conference on Machine Learning Position Paper Track. https://icml.cc/virtual/ 2025/poster/40125
work page 2025
-
[6]
Brooke Auxier, Lee Rainie, Monica Anderson, Andrew Perrin, Madhu Kumar, and Erica Turner. 2019.Americans and Privacy: Concerned, Confused and Feeling Lack of Control Over Their Personal Information. Technical Report. Pew Research Center. www.pewresearch.org
work page 2019
-
[7]
Austin A. Barr, Eddie Guo, Brij S. Karmur, and Emre Sezgin. 2025. Synthetic neurosurgical data generation with generative adversarial networks and large language models:an investigation on fidelity, utility, and privacy.Neurosurgical Focus59, 1 (July 2025), E17. https://doi.org/10.3171/2025.4.focus25225
-
[8]
Ngoc Bui, Hieu Trung Nguyen, Shantanu Kumar, Julian Theodore, Weikang Qiu, Viet Anh Nguyen, and Rex Ying. 2025. Mixture-of-Personas Language Models for Population Simulation. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computation...
-
[9]
Mary J. Culnan and Pamela K. Armstrong. 1999. Information Privacy Concerns, Procedural Fairness, and Impersonal Trust: An Empirical Investigation.Organi- zation Science10, 1 (1999), 104–115. http://www.jstor.org/stable/2640390
-
[10]
DataCebo. 2024. TVComplement - SDMetrics Documentation. https://docs.sdv. dev/sdmetrics/data-metrics/quality/tvcomplement. Accessed: 2026-03-10
work page 2024
-
[11]
Florian Dehling, Jan Tolsdorf, Hannes Federrath, and Luigi Lo Iacono. 2024. Internet Users’ Willingness to Disclose Biometric Data for Continuous Online Account Protection: An Empirical Investigation.PoPETs (Proceedings on Privacy Enhancing Technologies)2024, 2 (2024), 479 – 508. https://doi.org/10.56553/ popets-2024-0060
work page 2024
-
[12]
Cori Faklaris, Laura A. Dabbish, and Jason I. Hong. 2019. A Self-Report Measure of End-User Security Attitudes (SA-6). InFifteenth Symposium on Usable Privacy and Security (SOUPS 2019). USENIX Association, Santa Clara, CA, 61–77. https: //www.usenix.org/conference/soups2019/presentation/faklaris
work page 2019
-
[13]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy.Nature630, 8017 (06 2024), 625–630. https://doi.org/10.1038/s41586-024-07421-0
-
[14]
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. 2024. Promptbreeder: self-referential self-improvement via prompt evolution. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, Article 541, 64 pages
work page 2024
- [15]
-
[16]
Friederike Groschupp, Daniele Lain, Aritra Dhar, Lara Magdalena Lazier, and Srdjan Čapkun. 2025. Can LLMs Make (Personalized) Access Control Decisions? arXiv:2511.20284 [cs.CR] https://arxiv.org/abs/2511.20284
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Bart Knijnenburg, Elaine Raybourn, David Cherry, Daricia Wilkinson, Saadhika Sivakumar, and Henry Sloan. 2017. Death to the privacy calculus?A vailable at SSRN 2923806(2017)
work page 2017
- [18]
-
[19]
Robert S. Laufer and Maxine Wolfe. 1977. Privacy as a Concept and a Social Issue: A Multidimensional Developmental Theory.Journal of Social Issues33, 3 (1977), 22–42. https://spssi.onlinelibrary.wiley.com/doi/abs/10.1111/j.1540- 4560.1977.tb01880.x
- [20]
-
[21]
Lomotey, Sandra Kumi, Madhurima Ray, and Ralph Deters
Richard K. Lomotey, Sandra Kumi, Madhurima Ray, and Ralph Deters. 2024. Syn- thetic Data Digital Twins and Data Trusts Control for Privacy in Health Data Shar- ing. InProceedings of the 2024 ACM Workshop on Secure and Trustworthy Cyber- Physical Systems(Porto, Portugal)(SaT-CPS ’24). Association for Computing Machinery, New York, NY, USA, 1–10. https://do...
-
[22]
Yuxuan Lu, Bingsheng Yao, Hansu Gu, Jing Huang, Zheshen Jessie Wang, Yang Li, Jiri Gesi, Qi He, Toby Jia-Jun Li, and Dakuo Wang. 2025. UXAgent: An LLM Agent-Based Usability Testing Framework for Web Design. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association for Computing Machinery,...
-
[23]
2014.Public Perceptions of Privacy and Security in the Post-Snowden Era
Mary Madden. 2014.Public Perceptions of Privacy and Security in the Post-Snowden Era. Technical Report. Pew Research Center. http://www.pewinternet.org/2014/ 11/12/public-privacy-perceptions/
work page 2014
-
[24]
Naresh Malhotra, Sung Kim, and James Agarwal. 2004. Internet Users’ Informa- tion Privacy Concerns (IUIPC): The Construct, the Scale, and a Causal Model. Information Systems Research15 (12 2004). https://doi.org/10.1287/isre.1040.0032
-
[25]
Colleen McClain, Michelle Faverio, Monica Anderson, and Eugenie Park. 2023. How Americans View Data Privacy. Technical Report. Pew Research Center. www.pewresearch.org
work page 2023
-
[26]
Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S. Bernstein
-
[27]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Generative Agent Simulations of 1,000 People. arXiv:2411.10109 [cs.AI] https://arxiv.org/abs/2411.10109
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng
-
[29]
Automatic Prompt Optimization with “Gradient Descent” and Beam Search. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 7957–7968. https://doi.org/10.18653/v1/ 2023.emnlp-main.494
-
[30]
Ronald W. Rogers. 1975. A Protection Motivation Theory of Fear Appeals and At- titude Change1.The Journal of Psychology91, 1 (1975), 93–114. https://doi.org/10. 1080/00223980.1975.9915803 arXiv:https://doi.org/10.1080/00223980.1975.9915803 PMID: 28136248
-
[31]
Joseph Suh, Erfan Jahanparast, Suhong Moon, Minwoo Kang, and Serina Chang
-
[32]
Language Model Fine-Tuning on Scaled Survey Data for Predicting Dis- tributions of Public Opinions. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanx- iang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austr...
- [33]
-
[34]
Lei Wang, Zikun Ye, and Jinglong Zhao. 2025. Efficient Inference Using Large Language Models with Limited Human Data: Fine-Tuning then Rectification. SSRN Electronic Journal(11 2025). https://doi.org/10.2139/ssrn.5763184
-
[35]
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. 2024. Large Language Models as Optimizers. InThe Twelfth International Conference on Learning Representations (ICLR). 13 A Detailed Results Below we report detailed results for the experiments described in Section 5.2. A.1 Impact of Optimizations Steps We assess ho...
work page 2024
-
[36]
Abdi et al. do not indicate the country of the respondents and the precise time of data collection. The scenarios are sampled from a larger set of 120 scenarios covering whether the smart assistant should share data with skills. These scenarios, constructed to cover 15 data types, have eight scenarios for each data type. The eight scenarios correspond to ...
work page 2014
-
[37]
Measure (User Profile & Behaviors) User Characteristics: Define the persona’s key demographic and psycho- graphic traits. User Behaviors: Describe the persona’s common privacy-related behaviors, especially those that appear habitual or automatic
-
[38]
Model (The Persona’s Decision-Making Heuristics) Contextual Variables: Choice Framing: How does the presentation of the data request (e.g., framed as a gain vs. a loss, complex vs. simple) affect their choice? Recipient Framing: How does the perceived authority or friendliness of the recipient trigger mental shortcuts (e.g., trust heuristics)? Risk & Bene...
-
[39]
Measure (User Profile & Behaviors) User Characteristics: Define the persona’s key demographic and psycho- graphic traits (e.g., age, occupation, tech-savviness, general attitude towards data privacy). User Behaviors: Describe the persona’s common privacy-related behaviors and digital footprint (e.g., what social media they use, how they shop online, their...
-
[40]
Model (The Persona’s Privacy Calculus) Contextual Variables: Data Sensitivity: How does their willingness to disclose information change based on the type of data being requested (e.g., email address vs. real-time location vs. biometric data)? Recipient Trust: How does their willingness to share change based on the recipient (e.g., a friend, their bank, a...
-
[41]
Measure (User Profile & Behaviors) User Characteristics: Define the persona’s key traits (e.g., tech-savviness, general anxiety level, exposure to privacy news). User Behaviors: Describe their current privacy-protective behaviors (e.g., use of 2FA, password habits, software updates)
-
[42]
Model (The Persona’s Threat & Coping Appraisal) Contextual Variables: Threat Context: How does the type of threat (e.g., identity theft vs. social embarrassment) affect their appraisal? Source of Information: How does the source of a threat warning (e.g., a news report, a system notification, a friend) influence their appraisal? Appraisal Process: Threat ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.