Alignment Reduces Expressed but Not Encoded Gender Bias: A Unified Framework and Study
Pith reviewed 2026-05-15 00:36 UTC · model grok-4.3
The pith
Alignment reduces expressed gender bias in outputs but leaves measurable associations intact inside the model's representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that supervised fine-tuning aimed at gender-bias reduction lowers bias in generated outputs while gender-related associations remain present in the model's internal representations and can be reactivated under adversarial prompting; debiasing effects observed on structured benchmarks do not necessarily generalize to realistic settings such as story generation.
What carries the argument
A unified measurement framework that applies the same neutral prompts to extract latent gender information from internal representations and to quantify bias in generated outputs.
If this is right
- Alignment through fine-tuning reliably lowers bias in standard generated responses.
- Internal gender associations survive alignment and remain accessible.
- Adversarial prompting can restore the bias that alignment had suppressed.
- Bias reductions measured on fixed benchmarks do not automatically appear in open-ended generation tasks.
Where Pith is reading between the lines
- Evaluations of alignment success may need to include checks for internal representations in addition to output tests.
- True removal of encoded associations could require architectural changes beyond output-level fine-tuning.
- Safety testing for deployed models should incorporate adversarial prompt suites to detect hidden associations.
Load-bearing premise
The neutral prompts and extraction methods chosen for internal representations accurately reflect the model's genuine encoded gender associations rather than artifacts of prompt wording or measurement technique.
What would settle it
A direct test in which adversarial prompts applied after alignment produce no measurable increase in expressed gender bias, or in which internal extraction methods detect no remaining gender associations.
Figures















read the original abstract
During training, Large Language Models (LLMs) learn social regularities that can lead to gender bias in downstream applications. Most mitigation efforts focus on reducing bias in generated outputs, typically evaluated on structured benchmarks, which raises two concerns: output-level evaluation does not reveal whether alignment modifies the model's underlying representations, and structured benchmarks may not reflect realistic usage scenarios. We propose a unified framework to jointly analyze intrinsic and extrinsic gender bias in LLMs using identical neutral prompts, enabling direct comparison between gender-related information encoded in internal representations and bias expressed in generated outputs. Contrary to prior work reporting weak or inconsistent correlations, we find a consistent association between latent gender information and expressed bias when measured under the unified protocol. We further examine the effect of alignment through supervised fine-tuning aimed at reducing gender bias. Our results suggest that while the latter indeed reduces expressed bias, measurable gender-related associations are still present in internal representations, and can be reactivated under adversarial prompting. Finally, we consider two realistic settings and show that debiasing effects observed on structured benchmarks do not necessarily generalize, e.g., to the case of story generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified framework that applies identical neutral prompts to jointly measure intrinsic gender bias (via latent associations extracted from internal representations) and extrinsic gender bias (via generated outputs) in LLMs. It reports a consistent correlation between the two—contrary to prior weak or inconsistent findings—shows that supervised fine-tuning alignment reduces expressed bias while leaving measurable encoded associations intact and reactivatable via adversarial prompts, and demonstrates that debiasing gains on structured benchmarks fail to generalize to realistic tasks such as story generation.
Significance. If the measurements prove robust, the work is significant for establishing a more ecologically valid protocol than structured benchmarks alone and for showing that alignment techniques may suppress surface-level outputs without altering underlying representations. The unified comparison, reactivation results, and generalization failure provide concrete guidance for future debiasing research and highlight limitations in current evaluation practices.
major comments (3)
- [§4.1] §4.1 (Representation extraction): The method for isolating latent gender information from hidden states on neutral prompts requires explicit specification of the probe architecture, layer selection, and any statistical controls for prompt sensitivity; without these, the claim that encoded associations persist post-alignment and are not measurement artifacts cannot be fully evaluated, as this extraction is load-bearing for the central contrast with prior work.
- [§5.2] §5.2 (Adversarial reactivation): The adversarial prompts used to reactivate gender associations after SFT must be shown to remain within the neutral category or accompanied by controls demonstrating that reactivation reflects pre-existing encodings rather than prompt-induced amplification; this directly affects the interpretation that alignment leaves encodings unchanged.
- [§4] Results tables (e.g., correlation tables in §4): The reported consistent associations should include direct head-to-head comparisons with the specific methods and prompt sets from prior studies that found weak correlations, along with effect sizes and robustness across multiple random seeds, to substantiate the discrepancy.
minor comments (3)
- The full set of neutral prompts and adversarial variants should be included in an appendix to support reproducibility of the unified protocol.
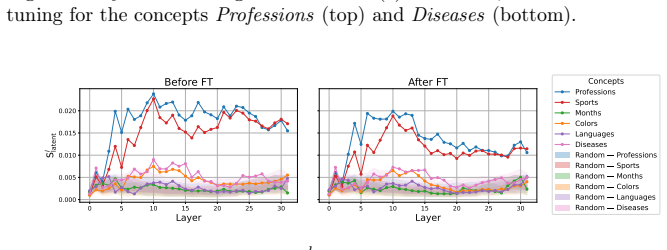
- [Figure 3] Figure captions for reactivation plots should explicitly state the number of samples and any error bars or confidence intervals used.
- [§3.1] Clarify the exact definition of 'neutral' prompts in §3.1 to avoid ambiguity in how they differ from structured benchmark prompts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for improving methodological transparency and empirical robustness. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.1] §4.1 (Representation extraction): The method for isolating latent gender information from hidden states on neutral prompts requires explicit specification of the probe architecture, layer selection, and any statistical controls for prompt sensitivity; without these, the claim that encoded associations persist post-alignment and are not measurement artifacts cannot be fully evaluated, as this extraction is load-bearing for the central contrast with prior work.
Authors: We agree that greater specificity on the representation extraction procedure is warranted to support reproducibility and evaluation of our central claims. In the revised manuscript, we will expand §4.1 with a dedicated paragraph specifying the probe as an L2-regularized logistic regression classifier, layer selection via cross-validated accuracy maximization across layers (with the final layer typically optimal), and statistical controls including label-permutation tests on neutral prompts to quantify and rule out prompt-sensitivity artifacts. These details will directly bolster the contrast with prior work. revision: yes
-
Referee: [§5.2] §5.2 (Adversarial reactivation): The adversarial prompts used to reactivate gender associations after SFT must be shown to remain within the neutral category or accompanied by controls demonstrating that reactivation reflects pre-existing encodings rather than prompt-induced amplification; this directly affects the interpretation that alignment leaves encodings unchanged.
Authors: We acknowledge the importance of ruling out prompt-induced amplification for the reactivation interpretation. The adversarial prompts were constructed to preserve semantic neutrality while providing minimal triggering cues, as confirmed by pilot evaluations. In revision, we will add explicit controls in §5.2: applying identical adversarial prompts to an SFT model trained on non-gender data and reporting that no comparable gender bias reactivation occurs, thereby demonstrating that the effect relies on pre-existing encodings rather than the prompts alone. Quantitative results and prompt examples will be included. revision: yes
-
Referee: [§4] Results tables (e.g., correlation tables in §4): The reported consistent associations should include direct head-to-head comparisons with the specific methods and prompt sets from prior studies that found weak correlations, along with effect sizes and robustness across multiple random seeds, to substantiate the discrepancy.
Authors: We agree that head-to-head comparisons would better substantiate the discrepancy with prior inconsistent findings. We will add a new subsection and table in §4 that directly compares our unified-protocol correlations against those obtained by re-implementing key prior methods and prompt sets on the same model suite, reporting Pearson r values, effect sizes, and standard deviations across three random seeds. This analysis will highlight how the identical neutral-prompt design yields more stable associations. revision: yes
Circularity Check
Empirical measurement study with self-contained protocol
full rationale
The paper introduces a new unified protocol that applies identical neutral prompts to measure both latent gender information in internal representations and expressed bias in outputs. Central claims rest on direct empirical observations of associations and the effects of supervised fine-tuning, without any derivations, parameter fits renamed as predictions, or load-bearing self-citations. No step reduces by construction to its own inputs; results are presented as measurements under the stated protocol and are falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neutral prompts can reliably surface gender-related information from internal representations without themselves introducing or masking bias.
Reference graph
Works this paper leans on
-
[1]
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., Nanda, N.: Refusal in language models is mediated by a single direction. In: NeurIPS (2024)
work page 2024
-
[2]
Bolukbasi, T., Chang, K.W., Zou, J.Y., Saligrama, V., Kalai, A.T.: Man is to computer programmer as woman is to homemaker? debiasing word embeddings. In: NeurIPS (2016)
work page 2016
-
[3]
Caliskan, A., Bryson, J.J., Narayanan, A.: Semantics derived automatically from language corpora contain human-like biases. Science356, 183–186 (2017)
work page 2017
-
[4]
Cao, Y.T., Pruksachatkun, Y., Chang, K.W., Gupta, R., Kumar, V., Dhamala, J., Galstyan, A.: On the intrinsic and extrinsic fairness evaluation metrics for contex- tualized language representations. In: ACL (2022)
work page 2022
-
[5]
Psychology of sport and exercise 14, 136–144 (2013)
Chalabaev, A., Sarrazin, P., Fontayne, P., Boiché, J., Clément-Guillotin, C.: The influence of sex stereotypes and gender roles on participation and performance in sport and exercise: Review and future directions. Psychology of sport and exercise 14, 136–144 (2013)
work page 2013
-
[6]
Chen, H., Vondrick, C., Mao, C.: Selfie: self-interpretation of large language model embeddings. In: ICML (2024)
work page 2024
-
[7]
Dhamala, J., Sun, T., Kumar, V., Krishna, S., Pruksachatkun, Y., Chang, K.W., Gupta, R.: Bold: Dataset and metrics for measuring biases in open-ended language generation. In: ACM Conf. on FAccT (2021) 16 N. Bouchouchi et al
work page 2021
-
[8]
Women do not have heart attacks!
Ducel, F., Hiebel, N., Ferret, O., Fort, K., Névéol, A.: “Women do not have heart attacks!” Gender Biases in Automatically Generated Clinical Cases in French. In: Findings NAACL (2025)
work page 2025
-
[9]
The Counseling Psychologist37, 902–922 (2009)
Gadassi, R., Gati, I.: The effect of gender stereotypes on explicit and implicit career preferences. The Counseling Psychologist37, 902–922 (2009)
work page 2009
-
[10]
Computational Linguistics50, 1097–1179 (2024)
Gallegos, I.O., Rossi, R.A., Barrow, J., Tanjim, M.M., Kim, S., Dernoncourt, F., Yu, T., Zhang, R., Ahmed, N.K.: Bias and fairness in large language models: A survey. Computational Linguistics50, 1097–1179 (2024)
work page 2024
-
[11]
Goldfarb-Tarrant, S., Marchant, R., Sánchez, R.M., Pandya, M., Lopez, A.: Intrin- sic bias metrics do not correlate with application bias. In: ACL-IJCNLP (2021)
work page 2021
-
[12]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., et al.: The Llama 3 Herd of Models. In: arXiv (2024)
work page 2024
-
[13]
Journal of personality and social psychology74, 1464 (1998)
Greenwald, A.G., McGhee, D.E., Schwartz, J.L.: Measuring individual differences in implicit cognition: the implicit association test. Journal of personality and social psychology74, 1464 (1998)
work page 1998
-
[14]
Guo, W., Caliskan, A.: Detecting emergent intersectional biases: Contextualized word embeddings contain a distribution of human-like biases. In: AIES (2021)
work page 2021
-
[15]
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Measuring Massive Multitask Language Understanding. ICLR (2021)
work page 2021
-
[16]
Hu, E.J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: LoRA: Low-Rank Adaptation of Large Language Models. In: ICLR (2022)
work page 2022
-
[17]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., de las Casas, D., Bressand, F., Lengyel, G., et al.: Mistral 7B. In: arXiv (2023)
work page 2023
-
[18]
Jiang, Z., Xu, F.F., Araki, J., Neubig, G.: How can we know what language models know? TACL (2020)
work page 2020
-
[19]
Jonauskaite, D., Dael, N., Chèvre, L., Althaus, B., Tremea, A., Charalambides, L., Mohr, C.: Pink for girls, red for boys, and blue for both genders: Colour preferences in children and adults. Sex Roles80, 630–642 (2019)
work page 2019
- [20]
-
[21]
Lum, K., Anthis, J.R., Robinson, K., Nagpal, C., D’Amour, A.N.: Bias in language models: Beyond trick tests and towards RUTEd evaluation. In: ACL (2025)
work page 2025
-
[22]
May, C., Wang, A., Bordia, S., Bowman, S., Rudinger, R.: On measuring social biases in sentence encoders. In: NAACL (2019)
work page 2019
-
[23]
Nadeem, M., Bethke, A., Reddy, S.: StereoSet: Measuring stereotypical bias in pretrained language models. In: ACL-IJCNLP (2021)
work page 2021
-
[24]
Nangia, N., Vania, C., Bhalerao, R., Bowman, S.R.: CrowS-Pairs: A challenge dataset for measuring social biases in masked language models. In: EMNLP (2020)
work page 2020
-
[25]
Pan, W., Liu, Z., Chen, Q., Zhou, X., Haining, Y., Jia, X.: The hidden dimensions of LLM alignment: A multi-dimensional analysis of orthogonal safety directions. In: ICML (2025)
work page 2025
-
[26]
Park, K., Choe, Y.J., Jiang, Y., Veitch, V.: The Geometry of Categorical and Hierarchical Concepts in Large Language Models. In: ICLR (2025)
work page 2025
-
[27]
Park, K., Choe, Y.J., Veitch, V.: The Linear Representation Hypothesis and the Geometry of Large Language Models. In: ICML (2024)
work page 2024
-
[28]
Parrish, A., Chen, A., Nangia, N., Padmakumar, V., Phang, J., Thompson, J., Htut, P.M., Bowman, S.: BBQ: A hand-built bias benchmark for question answer- ing. In: Findings ACL (2022)
work page 2022
-
[29]
Rooein, D., Zouhar, V., Nozza, D., Hovy, D.: Biased tales: Cultural and topic bias in generating children’s stories. In: EMNLP (2025)
work page 2025
-
[30]
In: arXiv (2024) Alignment Reduces Expressed but Not Encoded Gender Bias 17
Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., et al.: Gemma: Open Models Based on Gemini Research and Technology. In: arXiv (2024) Alignment Reduces Expressed but Not Encoded Gender Bias 17
work page 2024
-
[31]
Kelly is a Warm Person, Joseph is a Role Model
Wan, Y., Pu, G., Sun, J., Garimella, A., Chang, K.W., Peng, N.: “Kelly is a Warm Person, Joseph is a Role Model”: Gender Biases in LLM-Generated Reference Let- ters. In: Findings EMNLP (2023)
work page 2023
-
[32]
Webster, K., Wang, X., Tenney, I., Beutel, A., Pitler, E., Pavlick, E., Chen, J., Chi, E., Petrov, S.: Measuring and reducing gendered correlations in pre-trained models. arXiv (2020)
work page 2020
-
[33]
Zhang, T., Zeng, Z., YuxiangXiao, Y., Zhuang, H., Chen, C., Foulds, J.R., Pan, S.: GenderAlign:AnAlignmentDatasetforMitigatingGenderBiasinLargeLanguage Models. In: ACL (2025)
work page 2025
-
[34]
Zhao, J., Wang, T., Yatskar, M., Ordonez, V., Chang, K.W.: Gender Bias in Coref- erence Resolution: Evaluation and Debiasing Methods. In: NAACL (2018)
work page 2018
-
[35]
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., Hou, L.: Instruction-Following Evaluation for Large Language Models. arXiv (2023)
work page 2023
-
[36]
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J.Z., Fredrikson, M.: Universal and transferable adversarial attacks on aligned language models. arXiv (2023) A Reproducibility Code will be made publicly available upon acceptance of the paper. A.1 Models and fine-tuning Models.The models used (Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.1, and gemma-7b...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.