Joint Model Parameter Scaling and Universal-Domain Data Integration for E-commerce Search Ranking
Pith reviewed 2026-05-25 06:49 UTC · model grok-4.3
The pith
UniScale jointly scales model parameters and integrates universal-domain data to improve e-commerce search ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
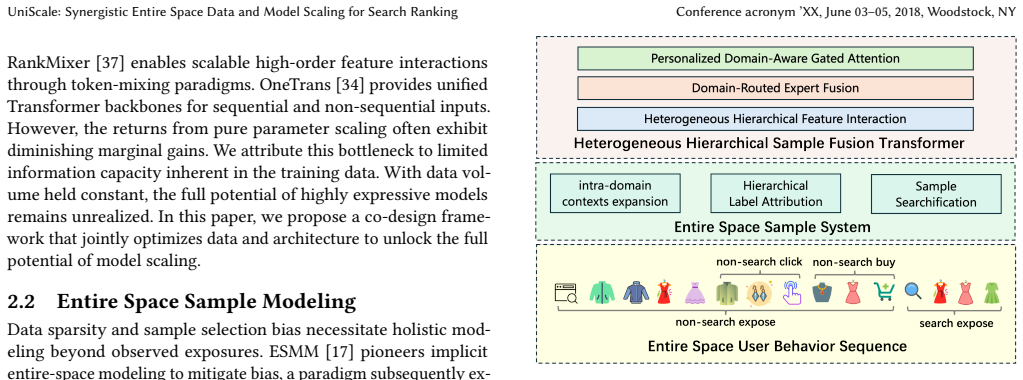
UniScale couples data scaling with model design through two components. ES³ constructs entire-space samples by enriching intra-domain search contexts with global supervisory signals and by adding cross-domain examples that reflect user decisions under comparable content exposure. HHSFT exploits the resulting heterogeneous data via hierarchical feature interaction and user-interest fusion across the full behavior space. This joint scaling produces stronger performance than structure-centric optimization alone.
What carries the argument
UniScale framework, whose two load-bearing pieces are the ES³ entire-space sample construction system and the HHSFT heterogeneous hierarchical fusion transformer.
If this is right
- Offline ranking metrics improve consistently when both data volume and model capacity grow together.
- Scaling behavior becomes more favorable than when model size is increased in isolation.
- Live traffic on a large e-commerce platform shows a 1.70 percent rise in purchases.
- The same traffic shows a 2.04 percent rise in GMV.
Where Pith is reading between the lines
- The same joint scaling pattern could be tested in advertising or recommendation surfaces that already collect cross-domain behavior logs.
- If the cross-domain samples prove stable, the method may reduce the need for domain-specific negative sampling strategies.
- The hierarchical fusion step inside HHSFT might be adapted to other transformer-based rankers that ingest mixed search and browse logs.
Load-bearing premise
Cross-domain examples added by ES³ reflect user decisions under comparable exposure conditions without introducing systematic bias or noise that would degrade the ranking model.
What would settle it
An A/B test that removes the cross-domain samples from training data while keeping model size fixed and measures whether the reported lifts in purchases and GMV disappear.
Figures



read the original abstract
Scaling studies for industrial search, advertising, and recommendation have largely emphasized enlarging model capacity or refining architectures. Yet in real-world systems, performance is constrained not only by model size but also by the quality and distribution of training data. Our empirical analysis shows two key bottlenecks: increasing parameters alone yields progressively smaller gains, and the challenges introduced by heterogeneous, large-scale behavior data cannot be fully resolved by architecture tuning in isolation. To address this issue, we present UniScale, a unified framework that couples data scaling with model design. UniScale consists of two components. First, ES$^3$, an entire-space sample construction system, broadens supervision beyond conventional sampled training data by enriching intra-domain search contexts with globally attributed supervisory signals and introducing cross-domain examples that reflect user decisions under comparable content exposure conditions. Second, HHSFT, a heterogeneous hierarchical fusion transformer, is tailored to exploit the resulting large-scale heterogeneous data through hierarchical feature interaction and user-interest fusion across the entire behavior space. Together, these components enable more effective scaling than structure-centric optimization alone. Experiments show that UniScale consistently improves offline performance and demonstrates favorable scaling behavior. In online A/B tests on a large e-commerce search platform, it delivers a 1.70% increase in purchases and a 2.04% lift in GMV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniScale, a framework for e-commerce search ranking that jointly addresses model parameter scaling and data integration. It introduces ES³, an entire-space sample construction system that enriches intra-domain data with globally attributed signals and cross-domain examples, paired with HHSFT, a heterogeneous hierarchical fusion transformer for feature interaction and user-interest fusion. The central claim is that this data-model co-scaling overcomes diminishing returns from model size alone, yielding consistent offline gains and online A/B lifts of 1.70% in purchases and 2.04% in GMV on a large platform.
Significance. If the cross-domain data construction in ES³ can be shown not to introduce unmeasured exposure or selection bias, the work would be significant for industrial IR systems by providing an empirical case for coupling data scaling with architecture design rather than optimizing either in isolation. The online A/B results, if reproducible with full protocol details, would offer a practical demonstration of improved scaling behavior in production search ranking.
major comments (3)
- [Abstract] Abstract: The reported 1.70% purchase and 2.04% GMV lifts are presented without any baselines, error bars, statistical significance tests, A/B test duration, or traffic allocation details; this absence makes the central performance claim unverifiable from the given text and is load-bearing for the soundness assessment.
- [ES³ component] ES³ description: The assumption that cross-domain examples 'reflect user decisions under comparable content exposure conditions' lacks any supporting quantitative check (distribution shift metrics, propensity-score matching, or ablation removing cross-domain samples); without this, attribution of the online lifts to UniScale versus data artifacts cannot be established.
- [Experiments] Experiments: No ablation studies isolating the contribution of ES³ versus HHSFT, nor comparisons against standard data-sampling or model-scaling baselines, are reported; these omissions prevent isolation of the joint-scaling benefit claimed in the abstract.
minor comments (2)
- [Abstract] The abstract refers to 'favorable scaling behavior' without defining the scaling regime, providing plots, or specifying the range of model sizes or data volumes tested.
- [Abstract] Notation for ES³ uses inconsistent superscript formatting in the abstract; ensure consistent LaTeX rendering throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, providing clarifications and committing to revisions where the manuscript can be strengthened without misrepresenting the current results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 1.70% purchase and 2.04% GMV lifts are presented without any baselines, error bars, statistical significance tests, A/B test duration, or traffic allocation details; this absence makes the central performance claim unverifiable from the given text and is load-bearing for the soundness assessment.
Authors: We agree that the abstract alone does not provide sufficient protocol details for independent verification. In the revised manuscript we will expand the abstract to reference the A/B test duration, traffic split, and statistical significance tests, and we will add explicit error bars, p-values, and baseline comparisons to the experiments section so that the lifts can be assessed against standard practice. revision: yes
-
Referee: [ES³ component] ES³ description: The assumption that cross-domain examples 'reflect user decisions under comparable content exposure conditions' lacks any supporting quantitative check (distribution shift metrics, propensity-score matching, or ablation removing cross-domain samples); without this, attribution of the online lifts to UniScale versus data artifacts cannot be established.
Authors: The current description of ES³ relies on the exposure-comparability criterion stated in the text. To strengthen the claim we will add, in the revised version, distribution-shift metrics between cross-domain and intra-domain samples together with an ablation that removes the cross-domain portion; these additions will allow readers to evaluate whether the observed gains are attributable to the data construction or to other factors. revision: yes
-
Referee: [Experiments] Experiments: No ablation studies isolating the contribution of ES³ versus HHSFT, nor comparisons against standard data-sampling or model-scaling baselines, are reported; these omissions prevent isolation of the joint-scaling benefit claimed in the abstract.
Authors: The present experiments report end-to-end results but do not contain the requested component-wise ablations or external baselines. We will insert, in the revised manuscript, ablation tables that isolate ES³ from HHSFT and that compare against conventional negative-sampling and parameter-scaling baselines, thereby making the joint-scaling benefit explicit. revision: yes
Circularity Check
No circularity: empirical framework validated by external A/B tests
full rationale
The paper presents UniScale as an empirical coupling of ES³ data construction and HHSFT architecture, with performance claims resting on offline metrics and online A/B tests rather than any closed mathematical derivation. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citations are shown that would reduce the reported lifts to inputs by construction. The A/B results constitute independent external validation outside the training data rules, satisfying the criteria for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jianxin Chang, Chenbin Zhang, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, and Kun Gai. 2023. Pepnet: Parameter and embedding personalized network for infusing with personalized prior information. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3795–3804
work page 2023
- [3]
-
[4]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[5]
InProceedings of the 1st workshop on deep learning for recommender systems
Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
-
[6]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. InProceedings of the 10th ACM conference on recommender systems. 191–198
work page 2016
-
[7]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
work page 2022
- [9]
-
[10]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction.arXiv preprint arXiv:1703.04247(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. 2022. Training compute-optimal large language models (2022).arXiv preprint arXiv:2203.15556(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. Embedding- based retrieval in facebook search. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2553–2561
work page 2020
-
[13]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Xiangru Lian, Binhang Yuan, Xuefeng Zhu, Yulong Wang, Yongjun He, Honghuan Wu, Lei Sun, Haodong Lyu, Chengjun Liu, Xing Dong, et al . 2022. Persia: An open, hybrid system scaling deep learning-based recommenders up to 100 trillion parameters. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3288–3298
work page 2022
-
[15]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, et al . 2025. How can recommender systems benefit from large language models: A survey.ACM Transactions on Information Systems43, 2 (2025), 1–47
work page 2025
- [16]
-
[17]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H Chi. 2018. Modeling task relationships in multi-task learning with multi-gate mixture-of- experts. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1930–1939
work page 2018
-
[18]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire space multi-task model: An effective approach for estimating post-click conversion rate. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 1137–1140
work page 2018
-
[19]
Shanlei Mu, Penghui Wei, Wayne Xin Zhao, Shaoguo Liu, Liang Wang, and Bo Zheng. 2023. Hybrid contrastive constraints for multi-scenario Ad ranking. InPro- ceedings of the 32nd ACM international conference on information and knowledge management. 1857–1866
work page 2023
-
[20]
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sundaraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole- Jean Wu, Alisson G Azzolini, et al. 2019. Deep learning recommendation model for personalization and recommendation systems.arXiv preprint arXiv:1906.00091 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[21]
Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. 2022. Pinner- former: Sequence modeling for user representation at pinterest. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 3702–3712
work page 2022
-
[22]
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al . 2025. Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free.arXiv preprint arXiv:2505.06708(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Noam Shazeer. 2020. Glu variants improve transformer.arXiv preprint arXiv:2002.05202(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[24]
Xiang-Rong Sheng, Liqin Zhao, Guorui Zhou, Xinyao Ding, Binding Dai, Qiang Luo, Siran Yang, Jingshan Lv, Chi Zhang, Hongbo Deng, et al. 2021. One model to serve all: Star topology adaptive recommender for multi-domain ctr prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 4104–4113
work page 2021
-
[25]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self- attentive neural networks. InProceedings of the 28th ACM international conference on information and knowledge management. 1161–1170
work page 2019
-
[26]
Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. InProceedings of the 14th ACM conference on recommender systems. 269–278
work page 2020
-
[27]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
-
[28]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the web conference 2021. 1785–1797
work page 2021
-
[29]
Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vishwas Joshi, Nazanin Farahpour, Zhiyuan Zhang, and An- drew Zhai. 2023. Transact: Transformer-based realtime user action model for recommendation at pinterest. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5249–5259
work page 2023
-
[30]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259– 1273
work page 2022
-
[31]
Ji Yang, Xinyang Yi, Derek Zhiyuan Cheng, Lichan Hong, Yang Li, Simon Xiaom- ing Wang, Taibai Xu, and Ed H Chi. 2020. Mixed negative sampling for learning two-tower neural networks in recommendations. InCompanion proceedings of the web conference 2020. 441–447
work page 2020
-
[32]
Liren Yu, Wenming Zhang, Silu Zhou, Tao Zhang, Zhixuan Zhang, and Dan Ou
- [33]
-
[34]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhao- jie Gong, Fangda Gu, Michael He, et al. 2024. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [35]
- [36]
-
[37]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
work page 2018
-
[38]
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, An- drew M Dai, Quoc V Le, James Laudon, et al . 2022. Mixture-of-experts with expert choice routing.Advances in Neural Information Processing Systems35 (2022), 7103–7114
work page 2022
- [39]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.