DFLOP: A Data-driven Framework for Multimodal LLM Training Pipeline Optimization
Pith reviewed 2026-05-21 11:01 UTC · model grok-4.3
The pith
DFLOP makes multimodal LLM training up to 3.6 times faster by profiling how different inputs change computation costs and then predicting better schedules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DFLOP continuously profiles runtime behavior to capture data-induced computation variance and employs predictive scheduling to balance workloads across stages and microbatches, substantially improving GPU utilization and throughput with up to 3.6x faster training on large-scale multimodal benchmarks compared to state-of-the-art data-blind frameworks.
What carries the argument
Continuous runtime profiling that records per-input computation costs, combined with predictive scheduling that rebalances workloads across pipeline stages and microbatches based on observed variance.
If this is right
- GPU idle time from computation skew across heterogeneous inputs decreases.
- Synchronization waits between stages and microbatches shorten.
- Overall training throughput rises without changes to model architecture.
- Workload balance adapts automatically to new data distributions.
Where Pith is reading between the lines
- The same profiling approach could reduce waste in training pipelines that handle variable-length sequences or other non-uniform data.
- Similar runtime tracking might later improve inference efficiency on mixed workloads.
- Lower idle GPU time could translate into reduced energy use for large multimodal training runs.
Load-bearing premise
Runtime profiling can accurately and efficiently measure data-induced computation differences without adding large new overhead or prediction errors.
What would settle it
Experiments on the same multimodal benchmarks that show DFLOP training times equal to or slower than current frameworks would show the profiling and scheduling do not deliver the claimed gains.
Figures







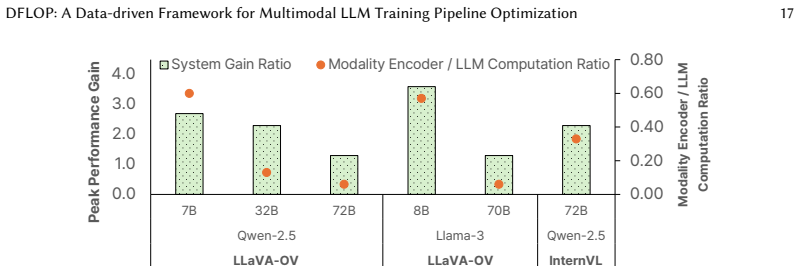




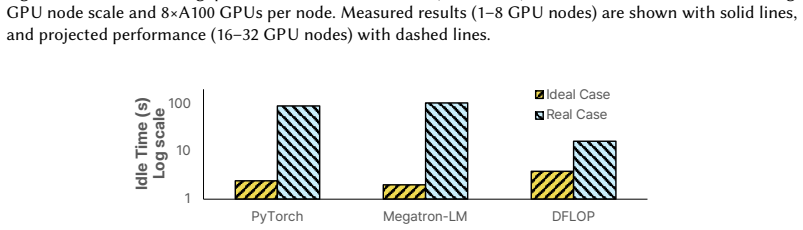



read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable advances by integrating text, image, and audio understanding within a unified architecture. However, existing distributed training frameworks remain fundamentally data-blind: they parallelize computation without accounting for variations in input data characteristics. This data unawareness leads to severe computation skew across stages and microbatches, where heterogeneous multimodal inputs incur different processing costs. Consequently, GPU resources are unevenly utilized, synchronization delays accumulate, and overall training efficiency degrades. To address this limitation, we present DFLOP, a data-driven framework for multimodal LLM training pipeline optimization. DFLOP continuously profiles runtime behavior to capture data-induced computation variance and employs predictive scheduling to balance workloads across stages and microbatches. By coupling data characteristics with execution planning, DFLOP substantially improves GPU utilization and throughput. Extensive experiments on large-scale multimodal benchmarks show that DFLOP achieves up to 3.6x faster training compared to state-of-the-art distributed training frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DFLOP, a data-driven framework for optimizing multimodal LLM training pipelines in distributed settings. It claims that standard frameworks ignore data-induced computation variance from heterogeneous multimodal inputs (text, image, audio), causing skew across pipeline stages and microbatches. DFLOP continuously profiles runtime behavior to capture this variance and applies predictive scheduling to balance workloads, yielding up to 3.6x faster training versus state-of-the-art baselines on large-scale multimodal benchmarks.
Significance. If the empirical results hold, the work addresses a practical bottleneck in scaling multimodal model training by making scheduling data-aware rather than purely static. Credit is due for including measured profiler overhead in the reported 3.6x speedup and for providing concrete throughput numbers on multimodal benchmarks; these elements make the central performance claim more credible than an unadjusted headline figure.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of DFLOP and the recommendation for minor revision. The significance section correctly credits the inclusion of measured profiler overhead within the 3.6x speedup figure and the provision of concrete throughput numbers on multimodal benchmarks, both of which strengthen the central claims.
Circularity Check
No significant circularity in DFLOP derivation or claims
full rationale
The paper presents DFLOP as an engineering framework that profiles runtime behavior to capture data-induced variance and applies predictive scheduling for workload balancing in multimodal LLM training. The abstract and context contain no equations, self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. Performance claims (up to 3.6x speedup) are tied to external benchmark experiments with measured overhead subtracted, providing independent empirical grounding rather than reduction to inputs by construction. No derivation chain reduces to self-definition or ansatz smuggling; the approach is self-contained via runtime observation and benchmarking.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, Ziyong Feng, Ziwei Liu, Bo Li, and Jiankang Deng. 2025. LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training. arX...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. 2025. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Agarwal, Chengkai Li, Jun Yang, and Cong Yu
Matthias Boehm, Shirish Tatikonda, Berthold Reinwald, Prithviraj Sen, Yuanyuan Tian, Douglas R. Burdick, and Shivakumar Vaithyanathan. 2014. Hybrid parallelization strategies for large-scale machine learning in SystemML. Proc. VLDB Endow.7, 7 (March 2014), 553–564. doi:10.14778/2732286.2732292
-
[5]
Andy Brock, Soham De, Samuel L Smith, and Karen Simonyan. 2021. High-Performance Large-Scale Image Recognition Without Normalization. InProceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, 1059–1071. https://proceedings.mlr.press/ v139/brock21a.html
work page 2021
- [6]
-
[7]
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, Wanxiang Che, Xiangzhan Yu, and Furu Wei. 2023. BEATs: audio pre-training with acoustic tokenizers. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 203, 16 pages. DFLOP: A Data-driven Framework for Multimodal...
work page 2023
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. 2024. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://lmsys.org/blog/2023-03-30-vicuna/
work page 2023
-
[10]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, et al. 2024. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
work page 2024
-
[12]
Can Cui, Yunsheng Ma, Xu Cao, Wenqian Ye, Yang Zhou, Kaizhao Liang, Jintai Chen, Juanwu Lu, Zichong Yang, Kuei-Da Liao, et al. 2024. A survey on multimodal large language models for autonomous driving. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 958–979
work page 2024
-
[13]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. InInternational Conference on Learning Representations (ICLR)
work page 2024
-
[14]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS)
work page 2022
-
[15]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929 [cs.CV] https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin Choi, et al. 2024. Agent ai: Surveying the horizons of multimodal interaction.arXiv preprint arXiv:2401.03568(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Shiqing Fan, Yi Rong, Chen Meng, Zongyan Cao, Siyu Wang, Zhen Zheng, Chuan Wu, Guoping Long, Jun Yang, Lixue Xia, Lansong Diao, Xiaoyong Liu, and Wei Lin. 2021. DAPPLE: a pipelined data parallel approach for training large models. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (Virtual Event, Republic of...
-
[18]
Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao
-
[19]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 19358–19369
-
[20]
Weiqi Feng, Yangrui Chen, Shaoyu Wang, Yanghua Peng, Haibin Lin, and Minlan Yu. 2025. Optimus: Accelerating {Large-Scale} {Multi-Modal} {LLM} Training by Bubble Exploitation. In2025 USENIX Annual Technical Conference (USENIX ATC 25). 161–177
work page 2025
-
[21]
R. L. Graham. 1969. Bounds on Multiprocessing Timing Anomalies.SIAM J. Appl. Math.17, 2 (1969), 416–429. arXiv:https://doi.org/10.1137/0117039 doi:10.1137/0117039
-
[22]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Gurobi Optimization, LLC. 2026. Gurobi Optimizer Reference Manual. https://www.gurobi.com
work page 2026
-
[24]
Dong He, Supun C Nakandala, Dalitso Banda, Rathijit Sen, Karla Saur, Kwanghyun Park, Carlo Curino, Jesús Camacho- Rodríguez, Konstantinos Karanasos, and Matteo Interlandi. 2022. Query processing on tensor computation runtimes. Proc. VLDB Endow.15, 11 (July 2022), 2811–2825. doi:10.14778/3551793.3551833
-
[25]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al . 2022. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Yuhan Dong, and Yu Wang
-
[27]
InProceedings of Machine Learning and Systems, P
FlashDecoding++: Faster Large Language Model Inference with Asynchronization, Flat GEMM Optimization, and Heuristics. InProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 148–161. https://proceedings.mlsys.org/paper_files/paper/2024/file/5321b1dabcd2be188d796c21b733e8c7-Paper- Conference.pdf
work page 2024
-
[28]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. 26 Hyeonjun An et al. IEEE/ACM Transactions on Audio, Speech, and Language Processing29 (2021), 3451–3460. doi:10.1109/TASLP.2021. 3122291
-
[29]
Jun Huang, Zhen Zhang, Shuai Zheng, Feng Qin, and Yida Wang. 2024. DISTMM: Accelerating Distributed Multimodal Model Training. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). USENIX Association, Santa Clara, CA, 1157–1171. https://www.usenix.org/conference/nsdi24/presentation/huang
work page 2024
-
[30]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. 2019.GPipe: efficient training of giant neural networks using pipeline parallelism. Curran Associates Inc., Red Hook, NY, USA
work page 2019
-
[31]
Yiren Jian, Chongyang Gao, and Soroush Vosoughi. 2023. Bootstrapping Vision-Language Learning with Decoupled Language Pre-training. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 57–72. https://proceedings.neurips.cc/ paper_files/paper/2023/...
- [32]
-
[33]
Yizhang Jin, Jian Li, Yexin Liu, Tianjun Gu, Kai Wu, Zhengkai Jiang, Muyang He, Bo Zhao, Xin Tan, Zhenye Gan, et al
- [34]
-
[35]
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. 2016. A diagram is worth a dozen images. InEuropean conference on computer vision. Springer, 235–251
work page 2016
-
[36]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 814, 13 pages
work page 2023
-
[38]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala. 2020. PyTorch distributed: experiences on accelerating data parallel training. Proc. VLDB Endow.13, 12 (Aug. 2020), 3005–3018. doi:10.14778/3415478.3415530
-
[39]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved Baselines with Visual Instruction Tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 26296–26306
work page 2024
-
[40]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction Tuning. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 34892–34916. https://proceedings.neurips.cc/paper_files/paper/2023/file/ 6dcf277ea32ce3288914faf369fe6de...
work page 2023
-
[41]
Rui Liu, Kwanghyun Park, Fotis Psallidas, Xiaoyong Zhu, Jinghui Mo, Rathijit Sen, Matteo Interlandi, Konstantinos Karanasos, Yuanyuan Tian, and Jesús Camacho-Rodríguez. 2023. Optimizing Data Pipelines for Machine Learning in Feature Stores.Proceedings of the VLDB Endowment16, 13 (Sept. 2023), 4230–4239. doi:10.14778/3625054.3625060
-
[42]
Junyu Lu, Dixiang Zhang, Songxin Zhang, Zejian Xie, Zhuoyang Song, Cong Lin, Jiaxing Zhang, Bingyi Jing, and Pingjian Zhang. 2024. Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic- aware Visual Objects. arXiv:2312.05278 [cs.CL] https://arxiv.org/abs/2312.05278
-
[43]
Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. 2022. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 1697–1706
work page 2022
-
[44]
Meta AI. 2025. The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal AI Innovation. https: //ai.meta.com/blog/llama-4-multimodal-intelligence/. Accessed: 2025-12-04
work page 2025
-
[45]
Xupeng Miao, Yujie Wang, Youhe Jiang, Chunan Shi, Xiaonan Nie, Hailin Zhang, and Bin Cui. 2022. Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism.Proceedings of the VLDB Endowment 16, 3 (Nov. 2022), 470–479. doi:10.14778/3570690.3570697 arXiv:2211.13878 [cs]
-
[46]
Fast and secure global payments with Stellar
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R. Devanur, Gregory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. 2019. PipeDream: generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM Symposium on Operating Systems Principles. ACM, Huntsville Ontario Canada, 1–15. doi:10.1145/3341301. 3359646
-
[47]
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. InSC21: International Conference for High Performance Computing, Networking, Storage and Analysis. IEE...
work page 2021
-
[48]
NVIDIA. 2024.Sequence Packing. https://docs.nvidia.com/nemo-framework/user-guide/24.09/nemotoolkit/features/ optimizations/sequence_packing.html
work page 2024
-
[49]
Kwanghyun Park, Karla Saur, Dalitso Banda, Rathijit Sen, Matteo Interlandi, and Konstantinos Karanasos. 2022. End-to-end Optimization of Machine Learning Prediction Queries. InProceedings of the 2022 International Conference DFLOP: A Data-driven Framework for Multimodal LLM Training Pipeline Optimization 27 on Management of Data(Philadelphia, PA, USA)(SIG...
-
[50]
2019.PyTorch: an imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019.PyTorch: an imperative style, high-per...
work page 2019
-
[51]
Laurent Perron and Vincent Furnon. 2025.OR-Tools. Google. https://developers.google.com/optimization/
work page 2025
-
[52]
Arnab Phani, Lukas Erlbacher, and Matthias Boehm. 2022. UPLIFT: parallelization strategies for feature transformations in machine learning workloads.Proceedings of the VLDB Endowment15, 11 (2022), 2929–2938
work page 2022
-
[53]
PyTorch. 2024. PyTorch Performance Tuning Guide. https://docs.pytorch.org/tutorials/recipes/recipes/tuning_guide. html. Accessed: 2026-01-29
work page 2024
-
[54]
2024.PyTorch Scaled Dot Product Attention
PyTorch. 2024.PyTorch Scaled Dot Product Attention. https://pytorch.org/docs/stable/generated/torch.nn.functional. scaled_dot_product_attention
work page 2024
-
[55]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PMLR, 8748–8763
work page 2021
-
[56]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. ZeRO: memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis(Atlanta, Georgia)(SC ’20). IEEE Press, Article 20, 16 pages
work page 2020
-
[57]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’20). Association for Computing Machinery, New York, NY, USA, 3505–3506. doi:1...
-
[58]
Zineng Tang, Ziyi Yang, Mahmoud Khademi, Yang Liu, Chenguang Zhu, and Mohit Bansal. 2024. CoDi-2: In-Context Interleaved and Interactive Any-to-Any Generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 27425–27434
work page 2024
-
[59]
2009.Poincare’s Legacies, Part I: Pages from Year Two of a Mathematical Blog
Terence Tao. 2009.Poincare’s Legacies, Part I: Pages from Year Two of a Mathematical Blog. American Mathematical Soc
work page 2009
-
[60]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL] https://arxiv.org/ abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, and Furu Wei. 2023. Image as a Foreign Language: BEIT Pretraining for Vision and Vision-Language Tasks . In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, Los Alami...
-
[63]
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, and S Yu Philip. 2023. Multimodal large language models: A survey. In2023 IEEE International Conference on Big Data (BigData). IEEE, 2247–2256
work page 2023
-
[64]
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. 2024. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Peng Xu, Xiatian Zhu, and David A Clifton. 2023. Multimodal learning with transformers: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence45, 10 (2023), 12113–12132
work page 2023
-
[66]
Le Xue, Mingfei Gao, Chen Xing, Roberto Martin-Martin, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. 2023. ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding . In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer 28 Hyeonjun An et al. Socie...
-
[67]
Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, and Bin CUI. 2024. Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs. InForty-first International Conference on Machine Learning. https://openreview.net/forum?id=DgLFkAPwuZ
work page 2024
-
[68]
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou
-
[69]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality. arXiv:2304.14178 [cs.CL] https://arxiv.org/abs/2304.14178
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Nur Yildirim, Hannah Richardson, Maria Teodora Wetscherek, Junaid Bajwa, Joseph Jacob, Mark Ames Pinnock, Stephen Harris, Daniel Coelho De Castro, Shruthi Bannur, Stephanie Hyland, et al. 2024. Multimodal healthcare AI: identifying and designing clinically relevant vision-language applications for radiology. InProceedings of the CHI Conference on Human Fa...
work page 2024
-
[71]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid loss for language image pre- training. InProceedings of the IEEE/CVF international conference on computer vision. 11975–11986
work page 2023
-
[72]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Yansong Feng and Els Lefever (Eds.). Association for Computational Linguistics, Singapore, 543–553. doi:10.18653/v...
-
[73]
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li
-
[74]
PointCLIP: Point Cloud Understanding by CLIP. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 8542–8552. doi:10.1109/CVPR52688.2022.00836
-
[75]
Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. 2024. LLaVA-NeXT: A Strong Zero-shot Video Understanding Model. https://llava-vl.github.io/blog/2024-04-30-llava-next- video/
work page 2024
-
[76]
Zili Zhang, Yinmin Zhong, Yimin Jiang, Hanpeng Hu, Jianjian Sun, Zheng Ge, Yibo Zhu, Daxin Jiang, and Xin Jin
-
[77]
InProceedings of the ACM SIGCOMM 2025 Conference
Disttrain: Addressing model and data heterogeneity with disaggregated training for multimodal large language models. InProceedings of the ACM SIGCOMM 2025 Conference. 24–38
work page 2025
-
[78]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.Proc. VLDB Endow.16, 12 (Aug. 2023), 384...
-
[79]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Asso...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.