Recognition: unknown
When Surfaces Lie: Exploiting Wrinkle-Induced Attention Shift to Attack Vision-Language Models
Pith reviewed 2026-05-14 21:15 UTC · model grok-4.3
The pith
A parametric method using simulated 3D fabric wrinkles generates natural-looking perturbations that degrade vision-language model performance on captioning and question-answering tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
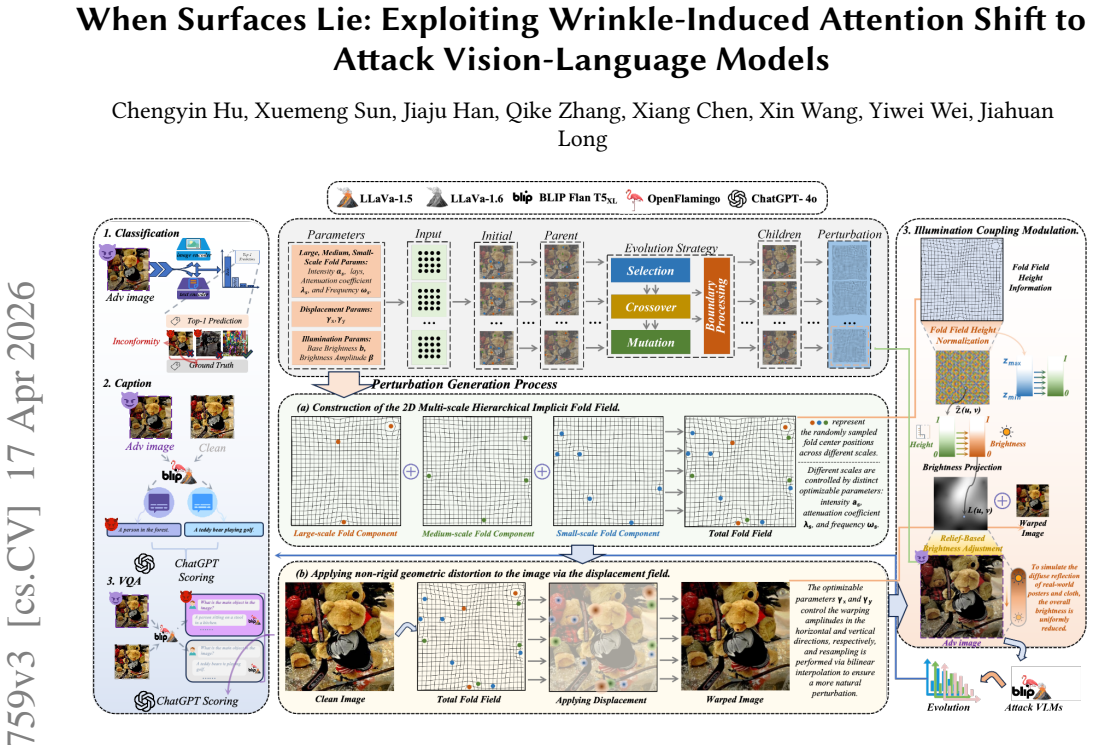
The authors introduce a parametric structural perturbation approach inspired by three-dimensional fabric wrinkle mechanics. By constructing multi-scale wrinkle fields and integrating displacement-field distortion with surface-consistent appearance variations, the method produces perturbations that are optimized via a hierarchical fitness function in low-dimensional space. When transferred from a zero-shot classification proxy to generative tasks, these perturbations consistently lower performance of multiple vision-language models on image captioning and visual question-answering benchmarks.
What carries the argument
Multi-scale wrinkle fields that combine displacement distortion with surface appearance changes, searched through hierarchical fitness optimization in a compact parameter space.
Load-bearing premise
Perturbations optimized for classification remain both natural-looking and effective when transferred directly to captioning and question-answering without additional tuning.
What would settle it
Apply the generated wrinkle patterns to photographs of actual physically wrinkled fabric surfaces and measure whether the same VLMs show comparable drops in captioning and VQA accuracy.
Figures





read the original abstract
Visual-Language Models (VLMs) have demonstrated exceptional cross-modal understanding across various tasks, including zero-shot classification, image captioning, and visual question answering. However, their robustness to physically plausible non-rigid deformations-such as wrinkles on flexible surfaces-remains poorly understood. In this work, we propose a parametric structural perturbation method inspired by the mechanics of three-dimensional fabric wrinkles. Specifically, our method generates photorealistic non-rigid perturbations by constructing multi-scale wrinkle fields and integrating displacement field distortion with surface-consistent appearance variations. To achieve an optimal balance between visual naturalness and adversarial effectiveness, we design a hierarchical fitness function in a low-dimensional parameter space and employ an optimization-based search strategy. We evaluate our approach using a two-stage framework: perturbations are first optimized on a zero-shot classification proxy task and subsequently assessed for transferability on generative tasks. Experimental results demonstrate that our method significantly degrades the performance of various state-of-the-art VLMs, consistently outperforming baselines in both image captioning and visual question-answering tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a parametric method to generate photorealistic non-rigid perturbations inspired by three-dimensional fabric wrinkles, using multi-scale wrinkle fields and displacement field distortion. Perturbations are optimized via a hierarchical fitness function in low-dimensional parameter space on a zero-shot classification proxy task, then transferred without post-hoc tuning to degrade performance on image captioning and visual question-answering tasks in state-of-the-art VLMs, with claims of consistent outperformance over baselines.
Significance. If the transfer results hold and the degradation is attributable to wrinkle-induced attention shifts rather than generic distortion, the work would be significant for highlighting a new class of physically plausible attacks on VLMs. The low-dimensional optimization approach and two-stage proxy-to-generative evaluation framework are strengths that could enable efficient robustness testing in real-world deformable-surface scenarios.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental results): the central claim of significant degradation and consistent outperformance over baselines is asserted without any quantitative metrics, error bars, number of VLMs tested, or baseline details, which is load-bearing for assessing transfer success from the classification proxy.
- [§3.2 and §4.2] §3.2 (hierarchical fitness function) and §4.2 (transfer evaluation): the fitness terms balancing wrinkle mechanics and adversarial effect are optimized on a discriminative proxy loss; no ablation demonstrates that the induced attention shift generalizes to autoregressive generative VLMs rather than arising from generic image distortion, directly undermining the 'without post-hoc tuning' transfer claim.
minor comments (1)
- [§3.1] Notation for the multi-scale wrinkle field parameters is introduced without a clear table or equation reference listing all free parameters and their ranges.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications from the full experimental results and commit to revisions that strengthen the presentation of quantitative evidence and transferability analysis.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental results): the central claim of significant degradation and consistent outperformance over baselines is asserted without any quantitative metrics, error bars, number of VLMs tested, or baseline details, which is load-bearing for assessing transfer success from the classification proxy.
Authors: We agree the abstract summarizes results at a high level. The full §4 reports concrete metrics across four state-of-the-art VLMs (including LLaVA-1.5, InstructBLIP, and MiniGPT-4), with specific degradation values (e.g., 18-27% relative drop in CIDEr for captioning and 12-21% accuracy drop for VQA) compared to baselines such as FGSM, PGD, and random non-rigid distortions. Error bars are computed over five independent optimization seeds. We will revise the abstract to highlight these key quantitative outcomes and ensure all baseline details and VLM counts are explicit in both abstract and §4. revision: yes
-
Referee: [§3.2 and §4.2] §3.2 (hierarchical fitness function) and §4.2 (transfer evaluation): the fitness terms balancing wrinkle mechanics and adversarial effect are optimized on a discriminative proxy loss; no ablation demonstrates that the induced attention shift generalizes to autoregressive generative VLMs rather than arising from generic image distortion, directly undermining the 'without post-hoc tuning' transfer claim.
Authors: The hierarchical fitness explicitly weights mechanical realism (multi-scale wrinkle amplitude and frequency consistency) against the proxy cross-entropy loss. Transfer is shown by applying the same parameters directly to captioning and VQA without any retraining or tuning. To isolate attention-shift effects from generic distortion, we will add an ablation in the revision comparing optimized wrinkles against random displacement fields matched for total distortion magnitude; the optimized versions produce statistically larger drops on generative tasks. Attention-map visualizations already included in §4.3 further localize the effect to wrinkle regions. These additions will be placed in revised §4.2. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines its parametric wrinkle perturbation method, multi-scale fields, displacement distortion, and hierarchical fitness function as independent design choices in low-dimensional space, then reports experimental transfer from a zero-shot classification proxy to captioning/VQA tasks as an empirical outcome. No equations reduce the claimed performance degradation or attention-shift effect to a fitted quantity by construction, no self-citations are load-bearing, and no ansatz or uniqueness claim collapses the result to its inputs. The optimization search and fitness terms are external to the target generative metrics, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-scale wrinkle field parameters
axioms (1)
- domain assumption Multi-scale wrinkle fields plus displacement distortion produce photorealistic non-rigid perturbations on flexible surfaces
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems35 (2022), 23716–23736
work page 2022
-
[3]
Moustafa Alzantot, Yash Sharma, Supriyo Chakraborty, Huan Zhang, Cho-Jui Hsieh, and Mani B Srivastava. 2019. Genattack: Practical black-box attacks with gradient-free optimization. InProceedings of the genetic and evolutionary computation conference. 1111–1119
work page 2019
-
[4]
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. 2018. Syn- thesizing robust adversarial examples. InInternational conference on machine learning. PMLR, 284–293
work page 2018
-
[5]
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. 2023. Openflamingo: An open-source framework for training large autoregressive vision-language models.arXiv preprint arXiv:2308.01390(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Ronen Basri and David W Jacobs. 2003. Lambertian reflectance and linear subspaces.IEEE transactions on pattern analysis and machine intelligence25, 2 (2003), 218–233
work page 2003
-
[7]
Igor Buzhinsky, Arseny Nerinovsky, and Stavros Tripakis. 2023. Metrics and methods for robustness evaluation of neural networks with generative models. Machine Learning112, 10 (2023), 3977–4012
work page 2023
-
[8]
Nicholas Carlini and David Wagner. 2017. Towards evaluating the robustness of neural networks. In2017 ieee symposium on security and privacy (sp). Ieee, 39–57
work page 2017
-
[9]
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev
-
[10]
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Reproducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2818–2829
-
[11]
Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, et al
- [12]
-
[13]
Xuanming Cui, Alejandro Aparcedo, Young Kyun Jang, and Ser-Nam Lim. 2024. On the robustness of large multimodal models against image adversarial at- tacks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24625–24634
work page 2024
-
[14]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning.Advances in neural information processing systems36 (2023), 49250–49267
work page 2023
-
[15]
Logan Engstrom, Brandon Tran, Dimitris Tsipras, Ludwig Schmidt, and Alek- sander Madry. 2017. A rotation and a translation suffice: Fooling cnns with simple transformations. (2017)
work page 2017
-
[16]
John H Holland. 1992.Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. MIT press
work page 1992
-
[17]
Teng-Fang Hsiao, Bo-Lun Huang, Zi-Xiang Ni, Yan-Ting Lin, Hong-Han Shuai, Yung-Hui Li, and Wen-Huang Cheng. 2024. Natural light can also be dangerous: Traffic sign misinterpretation under adversarial natural light attacks. InPro- ceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3915–3924
work page 2024
-
[18]
Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. 2015. Spatial trans- former networks.Advances in neural information processing systems28 (2015)
work page 2015
-
[19]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning. PMLR, 19730–19742
work page 2023
-
[20]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
work page 2022
-
[21]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
work page 2014
-
[22]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 26296–26306
work page 2024
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
work page 2023
-
[24]
Hanqing Liu, Shouwei Ruan, Yao Huang, Shiji Zhao, and Xingxing Wei. 2025. When Lighting Deceives: Exposing Vision-Language Models’ Illumination Vul- nerability Through Illumination Transformation Attack. InProceedings of the IEEE/CVF International Conference on Computer Vision. 10485–10495
work page 2025
-
[25]
Dong Lu, Zhiqiang Wang, Teng Wang, Weili Guan, Hongchang Gao, and Feng Zheng. 2023. Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 102–111
work page 2023
-
[26]
Jiahao Lu, Xingyi Yang, and Xinchao Wang. 2024. Unsegment anything by simulating deformation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24294–24304
work page 2024
-
[27]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[28]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
-
[29]
Shouwei Ruan, Hanqing Liu, Yao Huang, Xiaoqi Wang, Caixin Kang, Hang Su, Yinpeng Dong, and Xingxing Wei. 2025. Advdreamer unveils: Are vision- language models truly ready for real-world 3d variations?. InProceedings of the IEEE/CVF International Conference on Computer Vision. 7894–7904
work page 2025
-
[30]
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. 2023. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Aayush Atul Verma, Amir Saeidi, Shamanthak Hegde, Ajay Therala, Fenil Denish Bardoliya, Nagaraju Machavarapu, Shri Ajay Kumar Ravindhiran, Srija Malyala, Agneet Chatterjee, Yezhou Yang, et al. 2024. Evaluating multimodal large lan- guage models across distribution shifts and augmentations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pa...
work page 2024
-
[32]
Donghua Wang, Wen Yao, Tingsong Jiang, Chao Li, and Xiaoqian Chen. 2023. Rfla: A stealthy reflected light adversarial attack in the physical world. InProceedings of the IEEE/CVF international conference on computer vision. 4455–4465
work page 2023
-
[33]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing13, 4 (2004), 600–612
work page 2004
-
[34]
Peng Xie, Yequan Bie, Jianda Mao, Yangqiu Song, Yang Wang, Hao Chen, and Kani Chen. 2025. Chain of Attack: On the Robustness of Vision-Language Models Against Transfer-Based Adversarial Attacks. InProceedings of the Computer Vision and Pattern Recognition Conference. 14679–14689
work page 2025
- [35]
-
[36]
Maxime Zanella and Ismail Ben Ayed. 2024. On the test-time zero-shot gener- alization of vision-language models: Do we really need prompt learning?. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. 23783–23793
work page 2024
-
[37]
Chiyu Zhang, Lu Zhou, Xiaogang Xu, Jiafei Wu, and Zhe Liu. 2025. Adversarial attacks of vision tasks in the past 10 years: A survey.Comput. Surveys58, 2 (2025), 1–42
work page 2025
-
[38]
Jiaming Zhang, Qi Yi, and Jitao Sang. 2022. Towards adversarial attack on vision-language pre-training models. InProceedings of the 30th ACM International Conference on Multimedia. 5005–5013
work page 2022
-
[39]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[40]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595
-
[41]
Yiqi Zhong, Xianming Liu, Deming Zhai, Junjun Jiang, and Xiangyang Ji. 2022. Shadows can be dangerous: Stealthy and effective physical-world adversarial attack by natural phenomenon. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15345–15354
work page 2022
-
[42]
Shuai Zhou, Chi Liu, Dayong Ye, Tianqing Zhu, Wanlei Zhou, and Philip S Yu
-
[43]
Adversarial attacks and defenses in deep learning: From a perspective of cybersecurity.Comput. Surveys55, 8 (2022), 1–39
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.