Recognition: no theorem link
Large Vision Model-Guided Masked Low-Rank Approximation for Ground-Roll Attenuation
Pith reviewed 2026-05-13 22:42 UTC · model grok-4.3
The pith
A promptable large vision model generates fine-grained masks to guide masked low-rank approximation for targeted ground-roll attenuation in seismic records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The LVM-LRA method first uses a promptable large vision model to locate ground-roll-dominant regions via multimodal prompting and to output fine-grained masks; these masks are then embedded in a low-rank approximation model that imposes a global low-rank constraint on the reflection component to preserve event continuity and a mask-guided local low-rank constraint on the ground-roll component so separation occurs only inside the masked regions, with the whole problem solved by an ADMM-based iterative algorithm.
What carries the argument
Promptable large vision model for multimodal mask generation of ground-roll regions, combined with masked low-rank approximation that applies separate global and local low-rank constraints to reflections and noise.
If this is right
- Attenuation is restricted to masked zones, leaving uncontaminated regions untouched.
- Global low-rank constraint on reflections maintains lateral continuity of events.
- ADMM iteration yields a practical solver for large field volumes.
- Signal leakage is reduced relative to both global and non-masked local baselines.
Where Pith is reading between the lines
- The same mask-guided separation idea could apply to other coherent noises such as multiples or diffractions.
- Fine-tuning the vision model on seismic-specific prompts might raise mask accuracy under varied acquisition conditions.
- Hybrid pipelines that pair vision-model localization with physics-based low-rank models offer a route to consistent results without full end-to-end learning.
Load-bearing premise
The large vision model can reliably produce accurate fine-grained masks of ground-roll regions in real seismic data without significant errors from multimodal prompting.
What would settle it
A dataset where the vision model masks miss major ground-roll patches or incorrectly label clean reflection areas, resulting in either residual noise or new artifacts after the LRA step.
Figures









read the original abstract
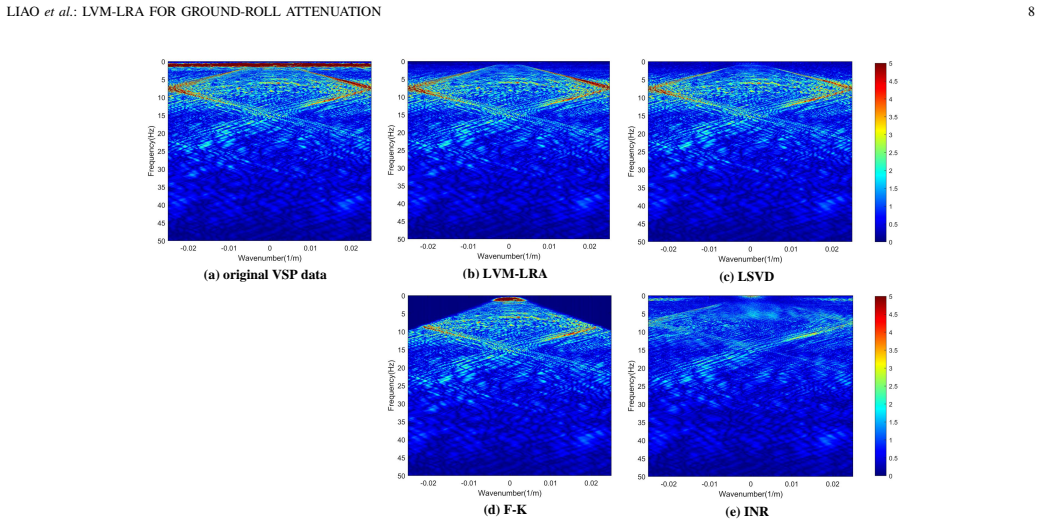
Ground roll is a common type of coherent noise in seismic records, and its attenuation remains challenging due to its substantial overlap with useful reflections in localized regions. Existing attenuation methods can be broadly classified into global and local categories according to whether ground-roll-contaminated regions are explicitly identified. Global methods, however, typically impose uniform attenuation on both contaminated and uncontaminated regions, which may result in signal leakage or distortion of reflections. By contrast, local methods restrict attenuation to contaminated regions and are therefore less prone to unnecessary modification of clean areas. However, their performance is often limited by manually designed or simplistic model-based mask estimation strategies. To address these limitations, we propose a large vision model-guided masked low-rank approximation (LVM-LRA) framework for ground-roll attenuation. Within this framework, a promptable LVM is first employed to identify ground-roll-dominant regions in seismic records through multimodal prompting and to generate accurate, fine-grained masks. The estimated masks are then incorporated into an LRA model for ground-roll attenuation. A global low-rank constraint is imposed on the reflection component to preserve event continuity, whereas a mask-guided local low-rank constraint is imposed on the ground-roll component so that its separation is confined to the masked regions. An iterative optimization algorithm based on the alternating direction method of multipliers (ADMM) is further developed to solve the resulting model efficiently. Experiments on synthetic and field datasets demonstrate that the proposed method achieves more effective ground-roll attenuation and better suppresses signal leakage than the baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the LVM-LRA framework for ground-roll attenuation in seismic records. A promptable large vision model (LVM) first identifies ground-roll-dominant regions via multimodal prompting and generates fine-grained masks. These masks are incorporated into a low-rank approximation (LRA) model that applies a global low-rank constraint to the reflection component to preserve event continuity and a mask-guided local low-rank constraint to the ground-roll component. The resulting optimization problem is solved iteratively via the alternating direction method of multipliers (ADMM). Experiments on synthetic and field datasets are stated to show more effective attenuation and reduced signal leakage relative to baseline methods.
Significance. If the LVM-generated masks can be shown to be reliable on seismic data, the framework offers a principled way to localize low-rank constraints, potentially improving upon both global methods (which risk signal leakage) and existing local methods (limited by simplistic masks). The hybrid global-local constraint formulation and ADMM solver are technically sound extensions of prior LRA work and could be adopted in seismic processing pipelines once mask accuracy is quantified.
major comments (2)
- [Abstract] Abstract: The central claim that the method 'achieves more effective ground-roll attenuation and better suppresses signal leakage than the baseline methods' is unsupported by any quantitative metrics, tables of SNR/PSNR values, error bars, or ablation results; without these, the performance advantage cannot be verified.
- [Method and Experiments] Method and Experiments sections: The promptable LVM mask generation is load-bearing for the masked LRA formulation, yet the manuscript provides only qualitative mask visualizations and end-to-end attenuation results; no pixel-level agreement metrics (IoU, Dice, precision-recall) against expert annotations on field seismic data are reported, preventing isolation of gains due to the proposed constraints versus gains from any plausible mask.
minor comments (2)
- The multimodal prompting strategy used with the LVM is described at a high level; adding concrete prompt examples or a diagram of the prompting workflow would improve reproducibility.
- Consider including pseudocode for the ADMM iterations and a complexity analysis to clarify implementation details.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive suggestions. Below we provide point-by-point responses to the major comments and outline the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the method 'achieves more effective ground-roll attenuation and better suppresses signal leakage than the baseline methods' is unsupported by any quantitative metrics, tables of SNR/PSNR values, error bars, or ablation results; without these, the performance advantage cannot be verified.
Authors: We thank the referee for highlighting this issue. The current version of the manuscript does not include quantitative metrics like SNR or PSNR values, tables, error bars, or explicit ablation results in support of the abstract's claims. We will add these in the revised manuscript, including a table of quantitative results on synthetic and field data, along with ablation studies on the proposed constraints. revision: yes
-
Referee: [Method and Experiments] Method and Experiments sections: The promptable LVM mask generation is load-bearing for the masked LRA formulation, yet the manuscript provides only qualitative mask visualizations and end-to-end attenuation results; no pixel-level agreement metrics (IoU, Dice, precision-recall) against expert annotations on field seismic data are reported, preventing isolation of gains due to the proposed constraints versus gains from any plausible mask.
Authors: We agree that the absence of pixel-level metrics for the LVM-generated masks limits the ability to fully isolate their contribution. The manuscript currently provides only qualitative visualizations. We will include additional ablation experiments using controlled mask qualities on synthetic data to demonstrate the impact of mask accuracy. However, we are unable to report IoU, Dice, or precision-recall against expert annotations on field data because such detailed annotations are not available. revision: partial
- Reporting pixel-level agreement metrics (e.g., IoU, Dice, precision-recall) for LVM masks against expert annotations on field seismic data, due to the unavailability of such annotations.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a proposed framework that combines an external promptable large vision model for mask generation with a standard ADMM-based optimization for the masked low-rank approximation model. No equations or derivations are shown that reduce any result to fitted parameters by construction, and no self-citation load-bearing steps or ansatz smuggling appear in the provided description. The central claims rest on experimental comparisons rather than internal redefinitions, making the approach self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large vision models can produce accurate masks for ground-roll regions via multimodal prompting
- domain assumption Reflection component admits global low-rank structure while ground-roll admits local low-rank structure within masks
invented entities (1)
-
LVM-LRA framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep learning with fully convolutional and dense connection framework for ground roll attenuation,
L. Yang, S. Wang, X. Chen, O. M. Saad, W. Cheng, and Y . Chen, “Deep learning with fully convolutional and dense connection framework for ground roll attenuation,” Surv. Geophys., vol. 44, no. 6, pp. 1919–1952, Mar 2023
work page 1919
-
[2]
Unsupervised ground- roll attenuation via implicit neural representations,
J. Li, D. Liu, and M. D. Sacchi, “Unsupervised ground- roll attenuation via implicit neural representations,”Geo- physics, vol. 90, no. 2, pp. V111–V121, Feb. 2025
work page 2025
-
[3]
Coherent noise attenuation in the radial trace domain,
D. C. Henley, “Coherent noise attenuation in the radial trace domain,”Geophysics, vol. 68, no. 4, pp. 1408–1416, Jan. 2003
work page 2003
-
[4]
Seis- mic entangled patterns analyzed via multiresolution de- composition,
F. Leite, R. Montagne, G. Corso, and L. Lucena, “Seis- mic entangled patterns analyzed via multiresolution de- composition,”Nonlinear Processes Geophys., vol. 16, no. 2, pp. 211–217, May 2009
work page 2009
-
[5]
Deep learning for ground- roll noise attenuation,
H. Li, W. Yang, and X. Yong, “Deep learning for ground- roll noise attenuation,” inSEG Int. Expo. Annu. Meeting. SEG, Oct. 2018, pp. SEG–2018
work page 2018
-
[6]
Seismic wave field separation and noise attenuation in linear domain via svd,
H. Shen and Q. Li, “Seismic wave field separation and noise attenuation in linear domain via svd,” inSEG Int. Expo. Annu. Meeting. SEG, Oct. 2009, pp. SEG–2009
work page 2009
-
[7]
Ground roll attenuation with adaptive eigenimage filtering,
P. W. Cary and C. Zhang, “Ground roll attenuation with adaptive eigenimage filtering,” inSEG Tech. Program Expanded Abstr., Oct. 2009, pp. 3302–3306
work page 2009
-
[8]
R. A. Wiggins, “W-k filter design,”Geophysical Prospecting, vol. 14, pp. 427–440, May 1966
work page 1966
-
[9]
Ground roll attenuation using the s and x-f-k transforms,
R. Askari and H. R. Siahkoohi, “Ground roll attenuation using the s and x-f-k transforms,”Geophysical Prospect- ing, vol. 56, no. 1, pp. 105–114, Jan. 2008
work page 2008
-
[10]
J. K. Welford and Z. Rongfeng, “Ground-roll suppression from deep crustal seismic reflection data using a wavelet- based approach: A case study from western canada,” pp. 877–884, Jan. 2004
work page 2004
-
[11]
Ground roll attenuation by synchrosqueezed curvelet transform,
Z. Liu, Y . Chen, and J. Ma, “Ground roll attenuation by synchrosqueezed curvelet transform,”J. Appl. Geophy., vol. 151, pp. 246–262, Apr. 2018
work page 2018
-
[12]
Ground roll attenuation using non-stationary matching filtering,
S. Jiao, Y . Chen, M. Bai, W. Yang, E. Wang, and S. Gan, “Ground roll attenuation using non-stationary matching filtering,”J. Geophys. Eng., vol. 12, no. 6, pp. 922–933, Oct. 2015
work page 2015
-
[13]
Ground roll attenuation with singular value decomposition,
P. W. Cary* and C. Zhang, “Ground roll attenuation with singular value decomposition,” inGlobal Meeting Abstr. Society of Exploration Geophysicists, Aug. 2009, pp. 1627–1630
work page 2009
-
[14]
Ground roll suppression using the karhunen- loeve transform,
X. Liu, “Ground roll suppression using the karhunen- loeve transform,”Geophysics, vol. 64, no. 2, pp. 564– 566, Apr. 1999
work page 1999
-
[15]
Poststack seismic data denoising based on 3-d convolutional neural network,
D. Liu, W. Wang, X. Wang, C. Wang, J. Pei, and W. Chen, “Poststack seismic data denoising based on 3-d convolutional neural network,”IEEE Trans. Geosci. Remote Sens., vol. 58, no. 3, pp. 1598–1629, Nov. 2019
work page 2019
-
[16]
A deep learning method for denoising based on a fast and flexible convolutional neural network,
W. Li, H. Liu, and J. Wang, “A deep learning method for denoising based on a fast and flexible convolutional neural network,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, Apr. 2022
work page 2022
-
[17]
Ground-roll attenua- tion using generative adversarial networks,
Y . Yuan, X. Si, and Y . Zheng, “Ground-roll attenua- tion using generative adversarial networks,”Geophysics, vol. 85, no. 4, pp. W A255–W A267, Jul. 2020
work page 2020
-
[18]
The denoising of desert seismic data based on cycle-gan with unpaired data training,
Y . Li, H. Wang, and X. Dong, “The denoising of desert seismic data based on cycle-gan with unpaired data training,”IEEE Geosci. Remote Sens. Lett., vol. 18, no. 11, pp. 2016–2020, Jul. 2021
work page 2016
-
[19]
Unsuper- vised deep learning for ground roll and scattered noise attenuation,
D. Liu, M. D. Sacchi, X. Wang, and W. Chen, “Unsuper- vised deep learning for ground roll and scattered noise attenuation,”IEEE Trans. Geosci. Remote Sens., vol. 61, p. 5920613, Oct. 2023
work page 2023
-
[20]
Similarity-informed self-learning and its application on seismic image denoising,
N. Liu, J. Wang, J. Gao, S. Chang, and Y . Lou, “Similarity-informed self-learning and its application on seismic image denoising,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, Sep. 2022
work page 2022
-
[21]
Ns2ns: Self-learning for seismic image de- noising,
N. Liu, J. Wang, J. Gao, K. Yu, Y . Lou, Y . Pu, and S. Chang, “Ns2ns: Self-learning for seismic image de- noising,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, Sep. 2022
work page 2022
-
[22]
Deep nonlocal regularizer: A self-supervised learning method for 3-d seismic denoising,
Z. Xu, Y . Luo, B. Wu, D. Meng, and Y . Chen, “Deep nonlocal regularizer: A self-supervised learning method for 3-d seismic denoising,”IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–17, Nov. 2023
work page 2023
-
[23]
Local time-frequency transform and its application to ground-roll noise attenuation,
Y . Liu and S. Fomel, “Local time-frequency transform and its application to ground-roll noise attenuation,” in SEG Tech. Program Expanded Abstr., Oct. 2010, pp. 3320–3324
work page 2010
-
[24]
Y . Chen, S. Jiao, J. Ma, H. Chen, Y . Zhou, and S. Gan, “Ground-roll noise attenuation using a simple and effec- tive approach based on local band-limited orthogonaliza- tion,”IEEE Geosci. Remote Sens. Lett., vol. 12, no. 11, pp. 2316–2320, Sep. 2015
work page 2015
-
[25]
K. K. Ali, R. K. Ibraheem, and H. A. Thabit, “Coherent noise attenuation using agora filter on 2d seismic data in east diwaniya, south eastern ˆaC“iraq,”Iraqi J. Sci., vol. 60, no. 5, pp. 1049–1054, May 2019
work page 2019
-
[26]
Adaptive ground-roll atten- uation using local nonlinear filtering,
Y . Yuan, Y . Li, and S. Liu, “Adaptive ground-roll atten- uation using local nonlinear filtering,”Comput. Geosci., vol. 26, pp. 1241–1254, Jul. 2022
work page 2022
-
[27]
Svd filtering applied to ground-roll attenua- tion,
M. J. Porsani, M. G. d. Silva, P. E. M. Melo, and B. Ursin, “Svd filtering applied to ground-roll attenua- tion,”J. Geophys. Eng., vol. 7, no. 3, pp. 284–289, Jun. 2010
work page 2010
-
[28]
Ground roll attenuation using lwd,
K. Kocon and M. Sacchi, “Ground roll attenuation using lwd,” inGeoConvention Expanded Abstr., 2011
work page 2011
-
[29]
Ground roll detection method based on an attribute constraint,
W. Sun, Q. Du, Q. Zhao, and L. Fu, “Ground roll detection method based on an attribute constraint,” in SEG Int. Expo. Annu. Meeting. SEG, Sep. 2019, p. D043S124R003
work page 2019
-
[30]
Clip- driven universal model for organ segmentation and tumor detection,
J. Liu, Y . Zhang, J.-N. Chen, J. Xiao, Y . Lu, B. A Land- man, Y . Yuan, A. Yuille, Y . Tang, and Z. Zhou, “Clip- driven universal model for organ segmentation and tumor detection,” inProc. IEEE/CVF Int. Conf. Comput. Vision, Oct. 2023, pp. 21 152–21 164
work page 2023
-
[31]
P. Wang, H. Zhang, and Y . Yuan, “Mcpl: multi-modal col- laborative prompt learning for medical vision-language LIAOet al.: LVM-LRA FOR GROUND-ROLL ATTENUATION 13 model,”IEEE Trans. Med. Imag., vol. 43, no. 12, pp. 4224–4235, Jun. 2024
work page 2024
-
[32]
Maple: Multi-modal prompt learning,
M. U. Khattak, H. Rasheed, M. Maaz, S. Khan, and F. S. Khan, “Maple: Multi-modal prompt learning,” inProc. IEEE/CVF Conf. Comput. Vision Pattern Recognit., Apr. 2023, pp. 19 113–19 122
work page 2023
-
[33]
Simultaneous seismic data denoising and reconstruction via multichannel singular spectrum analysis,
V . Oropeza and M. Sacchi, “Simultaneous seismic data denoising and reconstruction via multichannel singular spectrum analysis,”Geophysics, vol. 76, no. 3, pp. V25– V32, Apr. 2011
work page 2011
-
[34]
Personalizing vision-language models with hybrid prompts for zero-shot anomaly detection,
Y . Cao, X. Xu, Y . Cheng, C. Sun, Z. Du, L. Gao, and W. Shen, “Personalizing vision-language models with hybrid prompts for zero-shot anomaly detection,”IEEE Trans. Cybern., Feb. 2025
work page 2025
-
[35]
H. Li, R. Feng, L. Wang, Y . Zhong, and L. Zhang, “Superpixel-based reweighted low-rank and total varia- tion sparse unmixing for hyperspectral remote sensing imagery,”IEEE Trans. Geosci. Remote Sens., vol. 59, no. 1, pp. 629–647, May 2020
work page 2020
-
[36]
Vsp upgoing and downgoing wavefield separation: A hybrid model-data-driven approach,
Y . Wen, F. Qian, W. Guo, J. Zong, D. Peng, K. Chen, and G. Hu, “Vsp upgoing and downgoing wavefield separation: A hybrid model-data-driven approach,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–14, Mar. 2025
work page 2025
-
[37]
Mask-guided model for seismic data denoising,
Z. Fang, H. Lin, and X. Xu, “Mask-guided model for seismic data denoising,”IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, Mar. 2022
work page 2022
-
[38]
Self- supervised ground-roll noise attenuation using self- labeling and paired data synthesis,
D. A. Oliveira, D. G. Semin, and S. Zaytsev, “Self- supervised ground-roll noise attenuation using self- labeling and paired data synthesis,”IEEE Trans. Geosci. Remote Sens., vol. 59, no. 8, pp. 7147–7159, Oct. 2020
work page 2020
-
[39]
Joint-sparse-blocks and low-rank representation for hy- perspectral unmixing,
J. Huang, T.-Z. Huang, L.-J. Deng, and X.-L. Zhao, “Joint-sparse-blocks and low-rank representation for hy- perspectral unmixing,”IEEE Trans. Geosci. Remote Sens., vol. 57, no. 4, pp. 2419–2438, Oct. 2018
work page 2018
-
[40]
Promptad: Zero-shot anomaly detection using text prompts,
Y . Li, A. Goodge, F. Liu, and C.-S. Foo, “Promptad: Zero-shot anomaly detection using text prompts,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vision, Apr. 2024, pp. 1093–1102
work page 2024
-
[41]
Should we have labels for deep learning ground roll attenua- tion?
D. Liu, W. Chen, M. D. Sacchi, and H. Wang, “Should we have labels for deep learning ground roll attenua- tion?” inSEG Int. Expo. Annu. Meeting. SEG, Oct. 2020, p. D031S067R002
work page 2020
-
[42]
Seismic denoising using the redundant lifting scheme,
A. Aghayan, P. Jaiswal, and H. R. Siahkoohi, “Seismic denoising using the redundant lifting scheme,”Geo- physics, vol. 81, no. 3, pp. V249–V260, May 2016
work page 2016
-
[43]
Physics-constrained deep learning for ground roll attenuation,
N. Pham and W. Li, “Physics-constrained deep learning for ground roll attenuation,”Geophysics, vol. 87, no. 1, pp. V15–V27, Nov. 2022
work page 2022
-
[44]
J. Xia, “Estimation of near-surface shear-wave veloci- ties and quality factors using multichannel analysis of surface-wave methods,”J. Appl. Geophys., vol. 103, pp. 140–151, Apr. 2014
work page 2014
-
[45]
Learning to prompt with text only supervision for vision-language models,
M. U. Khattak, M. F. Naeem, M. Naseer, L. Van Gool, and F. Tombari, “Learning to prompt with text only supervision for vision-language models,” inProc. AAAI Conf. Artif. Intell., vol. 39, no. 4, Apr. 2025, pp. 4230– 4238
work page 2025
-
[46]
Visual textualization for image prompted object detection,
Y . Wu, Y . Zhou, J. Saiyin, B. Wei, and Y . Xu, “Visual textualization for image prompted object detection,” in Proc. IEEE/CVF Int. Conf. Comput. Vision, Jun. 2025, pp. 20 900–20 910
work page 2025
-
[47]
Image segmentation using text and image prompts,
T. L ¨uddecke and A. Ecker, “Image segmentation using text and image prompts,” inProc. IEEE/CVF Conf. Comput. Vision Pattern Recognit., Sep. 2022, pp. 7086– 7096
work page 2022
-
[48]
Proximal decomposition on the graph of a maximal monotone operator,
P. Mahey, S. Oualibouch, and P. D. Tao, “Proximal decomposition on the graph of a maximal monotone operator,”SIAM J. Optim., vol. 5, no. 2, pp. 454–466, May 1995
work page 1995
-
[49]
P. Neal, C. Eric, P. Borja, and E. Jonathan, “Distributed optimization and statistical learning via the alternating direction method of multipliers,”Found. Trends® Mach. Learn., vol. 3, no. 1, pp. 1–122, Jul. 2011
work page 2011
-
[50]
Seismic data interpolation and denois- ing in the frequency-wavenumber domain,
M. Naghizadeh, “Seismic data interpolation and denois- ing in the frequency-wavenumber domain,”Geophysics, vol. 77, no. 2, pp. V71–V80, Feb. 2012
work page 2012
-
[51]
Reinforcement learning- based denoising model for seismic random noise atten- uation,
C. Liang, H. Lin, and H. Ma, “Reinforcement learning- based denoising model for seismic random noise atten- uation,”IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–17, Apr. 2023
work page 2023
-
[52]
N. Shekhar, D. Tejaswi, A. James, L. Kuruguntla, V . C. Dodda, A. Mandpura, S. Chinnadurai, and K. Elumalai, “Seismic denoising based on dictionary learning with double regularization for random and erratic noise at- tenuation,”IEEE Trans. Geosci. Remote Sens., vol. PP, pp. 1–1, Feb. 2025
work page 2025
-
[53]
Random noise attenuation using local signal-and-noise orthogonalization,
Y . Chen and S. Fomel, “Random noise attenuation using local signal-and-noise orthogonalization,”Geophysics, vol. 80, no. 6, pp. WD1–WD9, Mar. 2015
work page 2015
-
[54]
S. Fomel, “Local seismic attributes,”Geophysics, vol. 72, no. 3, pp. A29–A33, May 2007
work page 2007
-
[55]
Z. Zhou, Y . Lu, J. Bai, V . M. Campello, F. Feng, and K. Lekadir, “Segment anything model for fetal head- pubic symphysis segmentation in intrapartum ultrasound image analysis,”Expert Syst. Appl., vol. 263, p. 125699, Mar. 2025
work page 2025
-
[56]
Large model guided semantic segment anything for underwater consumer electronics,
Q. Lin, H. Li, and Y . Jia, “Large model guided semantic segment anything for underwater consumer electronics,” IEEE Trans. Consum. Electron., Jul. 2025
work page 2025
-
[57]
Recurrent mask refinement for few-shot medical image segmenta- tion,
H. Tang, X. Liu, S. Sun, X. Yan, and X. Xie, “Recurrent mask refinement for few-shot medical image segmenta- tion,” inProc. IEEE/CVF Conf. Comput. Vision Pattern Recognit., Oct. 2021, pp. 3918–3928
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.