Recognition: unknown
KAIJU: An Executive Kernel for Intent-Gated Execution of LLM Agents
Pith reviewed 2026-05-08 02:22 UTC · model gemini-3-flash-preview
The pith
AI agents become more reliable and secure when reasoning is separated from execution by a dedicated system kernel.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that the standard 'ReAct' pattern—where a model thinks and acts in a single serial stream—is a fundamental bottleneck for agent performance and safety. They introduce KAIJU, an architecture that uses an Executive Kernel to manage tool execution independently of the model's reasoning. This allows for Intent-Gated Execution (IGX), a security framework that validates actions against four criteria—scope, intent, impact, and clearance—ensuring that even if a model is manipulated, it cannot execute unauthorized or harmful commands.
What carries the argument
The Executive Kernel, a management layer that converts model plans into parallelized dependency graphs and enforces security policies that are physically separate from the model's prompt space.
If this is right
- Parallel tool execution significantly reduces the time required for complex agents to complete data-heavy research tasks.
- Security vulnerabilities like prompt injection are mitigated because the execution layer enforces constraints the model cannot see or modify.
- Context window exhaustion is delayed because the model only processes the high-level plan and final results, while the kernel handles the intermediate data.
- Agent reliability improves through standardized error handling and dependency management that doesn't rely on the model's internal logic.
Where Pith is reading between the lines
- This architecture suggests a transition toward an 'Agent OS' where the LLM serves as a swappable user-space application while the kernel maintains system stability.
- The separation of concerns could allow smaller, specialized models to handle planning while a more robust model or a hard-coded system handles the high-stakes execution logic.
- Future agent benchmarks may need to measure 'security bypass resistance' as a primary metric alongside task completion.
Load-bearing premise
The system assumes that the AI can accurately predict all the information and tools it will need before it sees the results of its first few actions.
What would settle it
An experiment comparing KAIJU to standard agents on tasks where every step is entirely dependent on the specific text found in the previous step; if the kernel's planning overhead leads to constant 'replanning,' the efficiency benefits will vanish.
Figures
read the original abstract
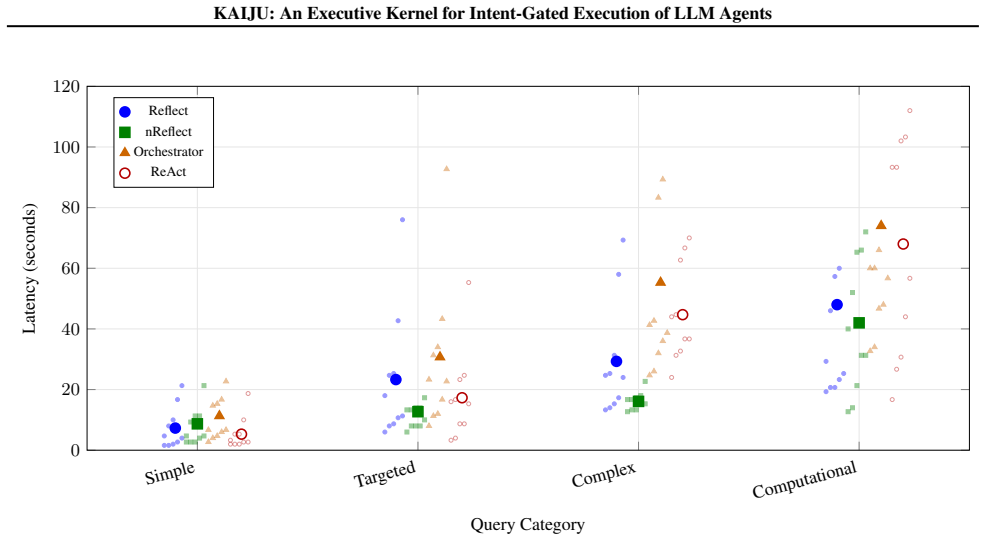
Tool-calling autonomous agents based on large language models using ReAct exhibit three limitations: serial latency, quadratic context growth, and vulnerability to prompt injection and hallucination. Recent work moves towards separating planning from execution but in each case the model remains coupled to the execution mechanics. We introduce a system-level abstraction for LLM agents which decouples the execution of agent workflows from the LLM reasoning layer. We define two first-class abstractions: (1) Intent-Gated Execution (IGX), a security paradigm that enforces intent at execution, and (2) an Executive Kernel that manages scheduling, tool dispatch, dependency resolution, failures and security. In KAIJU, the LLM plans upfront, optimistically scheduling tools in parallel with dependency-aware parameter injection. Tools are authorised via IGX based on four independent variables: scope, intent, impact, and clearance (external approval). KAIJU supports three adaptive execution modes (Reflect, nReflect, and Orchestrator), providing progressively finer-grained execution control apt for complex investigation and deep analysis or research. Empirical evaluation against a ReAct baseline shows that KAIJU has a latency penalty on simple queries due to planning overhead, convergence at moderate complexity, and a structural advantage on computational queries requiring parallel data gathering. Beyond latency, the separation enforces behavioural guarantees that ReAct cannot match through prompting alone. Code available at https://github.com/compdeep/kaiju
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents KAIJU, an architectural framework for LLM-based agents that decouples the planning (reasoning) phase from the execution phase through an 'Executive Kernel.' This kernel manages tool dispatch, parallelization, and security via a new paradigm called Intent-Gated Execution (IGX). By allowing the LLM to generate an upfront plan (DAG) rather than a serial 'thought-action-observation' loop (ReAct), KAIJU enables parallel execution and reduces context window inflation. The authors evaluate KAIJU against ReAct baselines, identifying a trade-off where KAIJU incurs higher overhead for simple tasks but offers superior performance for complex, parallelizable data-gathering workflows.
Significance. The paper contributes a timely systems-level abstraction to the field of agentic LLMs. By moving execution logic out of the prompt and into a structured kernel, the work addresses two major pain points: latency in tool-heavy workflows and the fragility of security policies defined purely within reasoning traces. The provision of reproducible code and the honest reporting of the 'latency penalty' for simple queries are distinct strengths that ground the architectural claims in empirical reality.
major comments (3)
- [§3.2, Intent-Gated Execution (IGX)] The central claim that IGX provides 'formal security guarantees' (§1, §3.1) relies on the verification function V(I, A) that maps Intent to Action. However, the paper does not specify the implementation of this function. If the verification is performed by a secondary LLM, the system remains vulnerable to 'Intent Spoofing' (where a malicious LLM generates a benign intent to mask a harmful action), inheriting the same reasoning failures it seeks to mitigate. If V is a static mapping, it risks brittleness. The authors must define the conditions under which V is considered 'trusted' and independent of the planning LLM to justify the claim of structural security.
- [§3.3, Dependency-Aware Injection] The optimistic scheduling mechanism assumes a static DAG. It is unclear how the Executive Kernel handles high-entropy branching (e.g., if Tool A's output determines that Tool B is unnecessary and Tool C must be called instead). If the system defaults to a 'Reflect' mode that requires the LLM to re-plan the entire sequence upon every branch, the stated latency benefits over ReAct may be negated by frequent re-planning overhead. The manuscript needs a specific discussion or benchmark on 'branching density' to clarify the limits of the kernel's parallelization.
- [§5, Empirical Evaluation] In Figure 4 and Table 1, the crossover point where KAIJU's planning overhead is offset by parallel execution is not explicitly quantified. The authors should provide a 'complexity vs. latency' plot that identifies the specific number of parallelizable tool calls or the depth of the dependency graph required for KAIJU to consistently outperform the ReAct baseline.
minor comments (3)
- [Figure 2] The transition arrows between the 'Executive Kernel' and the 'IGX Gate' are ambiguous. It is unclear if the Gate is an internal module of the Kernel or a middleware layer. Adding a sequence diagram for a single tool call would improve clarity.
- [§4, Adaptive Execution Modes] The distinction between 'nReflect' and 'Orchestrator' modes is somewhat blurred in the text. Explicitly defining the state-machine transitions between these modes would help implementers.
- [General] There are minor typos in the bibliography (e.g., inconsistent capitalization in title 'ReAct').
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We are pleased that the referee recognized KAIJU’s potential to address latency and security pain points in LLM agent architectures. The feedback regarding the implementation of the verification function V(I, A), the handling of high-entropy branching, and the quantification of the performance crossover point is particularly valuable. We intend to address these points by providing more formal definitions for the IGX verification layer, introducing a more nuanced discussion of branching density, and providing the requested 'complexity vs. latency' analysis to ground the 'latency penalty' observed in our empirical evaluation.
read point-by-point responses
-
Referee: [§3.2, Intent-Gated Execution (IGX)] The central claim that IGX provides 'formal security guarantees' relies on the verification function V(I, A) that maps Intent to Action. However, the paper does not specify the implementation of this function. If the verification is performed by a secondary LLM, the system remains vulnerable to 'Intent Spoofing'... If V is a static mapping, it risks brittleness.
Authors: The referee correctly identifies a critical implementation detail. In our current implementation, V(I, A) is a hybrid system: it uses a deterministic schema/policy engine (like OPA/Rego) for 'Scope' and 'Impact' (e.g., preventing a 'READ' intent from performing a 'DELETE' action), while 'Intent' is validated against the action's semantic footprint using a smaller, constrained, non-generative classifier. We agree that if V were simply another LLM, 'Intent Spoofing' remains a threat. We will revise §3.2 to explicitly define the trust boundary: V must be external to the planning LLM and use a deterministic policy for high-impact actions. We will also add a 'Security Limitations' section discussing the specific trade-offs between policy brittleness and verification robustness. revision: yes
-
Referee: [§3.3, Dependency-Aware Injection] The optimistic scheduling mechanism assumes a static DAG. It is unclear how the Executive Kernel handles high-entropy branching (e.g., if Tool A's output determines that Tool B is unnecessary and Tool C must be called instead). If the system defaults to a 'Reflect' mode... the stated latency benefits over ReAct may be negated.
Authors: The referee is correct: KAIJU’s 'optimistic' parallelization is most effective in workflows with predictable dependencies. In 'Reflect' mode, a significant change in tool requirements (high-entropy branching) triggers a re-plan, which incurs an LLM invocation penalty. However, KAIJU mitigates this via 'Partial DAG Re-planning,' where the kernel only requests a plan update for the invalidated sub-graph rather than the entire sequence. We will revise §3.3 to detail the kernel’s state-management during plan invalidation and add a paragraph to the Discussion acknowledging that KAIJU's structural advantage diminishes as the ratio of conditional branches to parallelizable tasks increases. revision: partial
-
Referee: [§5, Empirical Evaluation] In Figure 4 and Table 1, the crossover point where KAIJU's planning overhead is offset by parallel execution is not explicitly quantified. The authors should provide a 'complexity vs. latency' plot that identifies the specific number of parallelizable tool calls or the depth of the dependency graph required.
Authors: This is a fair request that will improve the utility of the evaluation. Based on our existing data, the 'breakeven' point typically occurs at a width of 3 parallel tool calls or a total plan length of 5 tools (where the cost of the upfront plan is amortized by the reduction in serial RTTs). We will incorporate a new figure (Figure 5) into the revised manuscript that plots 'Total Latency' against 'Plan Width' (parallelism) and 'Plan Depth' (seriality) to clearly visualize the performance envelopes of KAIJU vs. ReAct. This will provide developers with a clear heuristic for when to deploy the Executive Kernel versus a simpler serial loop. revision: yes
Circularity Check
KAIJU's Intent-Gated Execution (IGX) presents a circular security guarantee where the 'gate' relies on an intent provided by the same untrusted source it seeks to monitor.
specific steps
-
self definitional
[Section 3.1 and Abstract]
"We define two first-class abstractions: (1) Intent-Gated Execution (IGX), a security paradigm that enforces intent at execution... IGX is defined by the verification of an action a ∈ A against a declared intent i ∈ I... In KAIJU, the LLM plans upfront, optimistically scheduling tools... providing progressively finer-grained execution control... behavioral guarantees that ReAct cannot match."
The paper claims IGX provides 'structural guarantees' against prompt injection. However, it defines the verification gate as a check between an Action and a declared Intent, both of which are generated by the 'Reasoning Layer' (LLM). If the LLM is compromised via prompt injection, it can generate a malicious intent that justifies a malicious action. The 'guarantee' thus reduces to the Kernel verifying that the agent is successfully executing its (potentially hijacked) intent, making the security of the mechanism dependent on the integrity of the very component it is designed to gate.
full rationale
The paper makes significant, non-circular contributions regarding the parallelization of tool-calling agents and the architectural separation of planning from execution. Its empirical findings on latency and complexity convergence are independent of any self-referential logic. However, the 'Security' claim regarding Intent-Gated Execution (IGX) is partially circular. The authors propose that IGX mitigates prompt injection by verifying actions against intents, but since both the intent and the action are outputs of the same untrusted LLM planner, the 'verification' is essentially a self-consistency check for the agent. While the inclusion of a 'Clearance' variable (external approval) provides a valid out-of-band security path, the paper's characterization of IGX itself as a 'structural guarantee' is circular because the reference point for the gate (the Intent) is defined by the entity being gated.gated.
Axiom & Free-Parameter Ledger
free parameters (1)
- Impact Threshold =
Varies by domain
axioms (1)
- domain assumption LLMs can accurately identify data dependencies between tool calls during the upfront planning phase.
invented entities (2)
-
Intent-Gated Execution (IGX)
independent evidence
-
Executive Kernel
independent evidence
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-03-31. Biju, S. M. Implementing multi-agent systems using langgraph: A comprehensive study. InICRAARI,
2026
- [3]
-
[5]
Defeating Prompt Injections by Design
URL https://arxiv.org/ abs/2503.18813. Kim, S., Moon, S., Tabrizi, R., Lee, N., Mahoney, M. W., Keutzer, K., and Gholami, A. An LLM compiler for parallel function calling. In Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., and Berkenkamp, F. (eds.),Proceedings of the 41st International Conference on Machine Learning, volum...
work page internal anchor Pith review arXiv
-
[6]
GAIA: a benchmark for General AI Assistants
Mialon, G., Fourrier, C., Swift, C., Wolf, T., LeCun, Y ., and Scialom, T. GAIA: A benchmark for general AI assistants. arXiv preprint arXiv:2311.12983,
work page internal anchor Pith review arXiv
-
[8]
URL https://arxiv. org/abs/2510.09023. Shi, T., He, J., Wang, Z., Li, H., Wu, L., Guo, W., and Song, D. Progent: Programmable privilege control for LLM agents.arXiv preprint arXiv:2504.11703,
-
[9]
Progent: Securing AI Agents with Privilege Control
URL https://arxiv. org/abs/2504.11703. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representa- tions (ICLR),
work page internal anchor Pith review arXiv
-
[10]
Accessed: 2026-03-31. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.